Реализация рекуррентной нейронной сети с использованием Numpy
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-10-16 20:33

Вступление
Рекуррентная нейронная сеть (РНН) - одна из самых ранних нейронных сетей, которая смогла обеспечить прорыв в области НЛП. Красота этой сети заключается в ее способности хранить память о предыдущих последовательностях, благодаря чему они также широко используются для задач временных рядов. Высокоуровневые фреймворки, такие как Tensorflow и PyTorch, абстрагируют математику, лежащую в основе этих нейронных сетей, что затрудняет любому энтузиасту искусственного интеллекта кодирование архитектуры глубокого обучения с правильным знанием параметров и слоев. Для устранения такого рода неэффективности необходимы математические знания, лежащие в основе этих сетей. Кодирование этих алгоритмов с нуля дает дополнительное преимущество, помогая энтузиастам ИИ понять различные обозначения в исследовательских работах и реализовать их на практике.
Если вы новичок в концепции RNN, пожалуйста, обратитесь к курсу MIT 6.S191, который является одной из лучших лекций, дающих хорошее интуитивное понимание того, как работает RNN. Эти знания помогут вам понять различные обозначения и реализации концепций, описанные в этом руководстве.
Конечная цель
Конечная цель этого блога-сделать энтузиастов искусственного интеллекта удобными в кодировании теоретических знаний, которые они получают из исследовательских работ в области глубокого обучения.
Инициализация Параметров
В отличие от традиционных нейронных сетей, RNN обладают 3 весовыми параметрами, а именно входными весами, весами внутреннего состояния (используемыми для хранения памяти) и выходными весами. Начнем с инициализации этих параметров случайными значениями. Мы инициализируем измерение word_embedding и выходное измерение как 100 и 80 соответственно. Выходное измерение-это общее количество уникальных слов, присутствующих в словаре.
Переменная prev_memory относится к internal_state (это память предыдущих последовательностей).Другие параметры, такие как градиенты для обновления весов, также были инициализированы. Градиенты input_weight, internal_state_weight и output_weight были названы как dU, dW и dV соответственно. Переменная bptt_truncate относится к числу временных меток, которые сеть должна оглянуться назад во время обратного распространения, это делается для преодоления проблемы исчезающего градиента.
Интуиция Прямого Распространения:
Входные и выходные векторы:
Подумайте, что у нас есть предложение, которое я люблю играть.БЂ« . В списке словарей предположим , что я сопоставлен с индексом 2, например с индексом 45, с индексом 10 и играю с индексом 64 и пунктуацией БЂњ.бђ« в индексе 1. Чтобы получить реальный жизненный сценарий, работающий от входа к выходу, давайте случайным образом инициализируем word_embedding для каждого слова.
Примечание: Вы также можете попробовать использовать один горячий кодированный вектор для каждого слова и передать его в качестве входных данных.
Теперь, когда мы закончили с вводом, нам нужно рассмотреть выходные данные для каждого входного слова. Ячейка RNN должна вывести следующее наиболее вероятное слово для текущего входного сигнала. Для обучения RNN мы предоставляем t+1 ' - е слово в качестве выходного для tБЂ ™ - го входного значения, например: ячейка RNN должна выводить слово like для данного входного слова I.
Примечание: выход для каждой отдельной временной метки определяется не только текущим входом, но и предыдущим набором входов вместе с ним, который определяется параметром внутреннего состояния.
Теперь, когда входные данные представлены в виде векторов вложения, формат выходных данных, необходимый для вычисления потерь, должен быть однократно закодированными векторами. Это делается для каждого слова, присутствующего во входной строке, за исключением первого слова, потому что мы рассматриваем только один пример предложения для этой нейронной сети, чтобы узнать, и начальный вход-это первое слово предложения.
Почему мы однократно кодируем выходные слова ?
Причина в том, что необработанный результат будет просто баллами для каждого уникального слова, и они не важны для нас. Вместо этого нам нужны вероятности каждого слова по отношению к предыдущему слову.
Как мы находим вероятности из исходных выходных значений ?
Для решения этой задачи используется функция активации softmax на векторе баллов таким образом, чтобы все эти вероятности складывались в единицу. Img 1 показывает конвейер ввода-вывода с одной временной меткой. Верхняя строка-это выход ground _truth, а вторая строка - прогнозируемый выход.
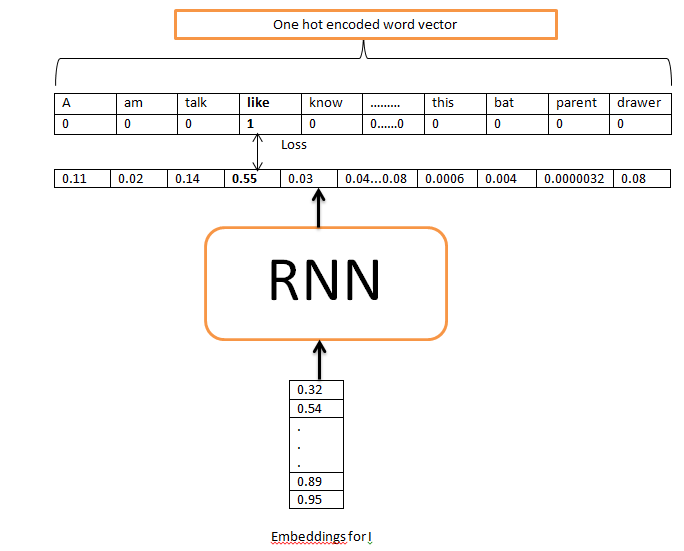
Примечание: во время реализации нам нужно позаботиться о ключевом значении output_mapper. Нам нужно сбросить Ключевые значения с его значениями временных меток, чтобы алгоритм знал, какое слово истинности должно быть использовано в этой конкретной временной метке, чтобы вычислить потерю .
Теперь, когда у нас есть веса, и мы также знаем, как мы передаем наши входные данные, и мы знаем, что ожидается в качестве выходных данных, мы начнем с расчета прямого распространения. Ниже приведены расчеты, необходимые для обучения нейронной сети.
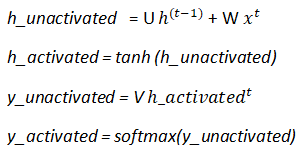
Здесь у представляют input_weights, W соответствуют internal_state_weights и V представляют собой выход весами. Входные веса умножаются на вход(x) , внутренние статические веса умножаются на предыдущую активацию, которая в нашей нотации является prev_memory. Функция активации, используемая между слоями, - Tanh. Она обеспечивает нелинейность и в конечном итоге помогает в обучении.
Примечание: термин смещения для расчетов RNN не используется, так как это привело бы к более сложному пониманию в этом учебнике.
Поскольку приведенный выше код будет просто вычислять выходные данные для одной конкретной временной метки, нам теперь придется кодировать прямое распространение для всей последовательности слов.
В приведенном ниже коде выходная строка содержит список выходных векторов для каждой временной метки. Память-это словарь, содержащий параметры для каждой временной метки, которые будут необходимы при обратном распространении.
Расчет Убытков:
Мы также определили нашу потерю или ошибку как кросс-энтропийную потерю, заданную:

Самое главное, что нам нужно посмотреть в приведенном выше коде, - это строка 5. Поскольку мы знаем,что выход ground_truth(y) имеет вид [0,0,БЂ¦., 1,..0], а predicted_output(y^hat) имеет вид [0,34,0,03, бђ¦БЂ¦, 0,45], нам нужно, чтобы потеря была единственным значением, чтобы вывести из нее общую потерю. По этой причине мы используем функцию sum, чтобы получить сумму разностей/ошибок для каждого значения в векторах y и y^hat для этой конкретной временной метки. Total_loss - это потеря для всей модели, включая все временные метки.
Обратное распространение
Если вы слышали о обратном распространении, то вы, должно быть, слышали о цепном правиле, и оно является жизненно важным аспектом вычисления градиента.
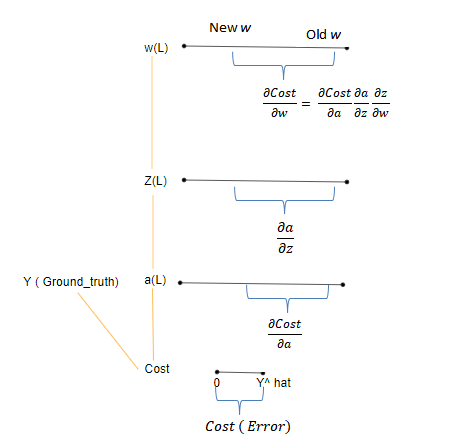
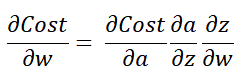
Основываясь на Img 4 выше, стоимость C представляет собой ошибку, которая является изменением, необходимым для того, чтобы y^hat достиг y. Поскольку стоимость является функцией выхода активации a, изменение, отраженное активацией, представлено в виде dCost/da. Практически это означает изменение (ошибку) значения, видимого с точки зрения узла активации. Аналогично изменение активации по отношению к z представлено da/dz, а z по отношению к w-dw/dz. Нас интересует, насколько сильно изменение (ошибка) по отношению к весам. Поскольку нет прямой связи между Весами и стоимостью, промежуточные значения изменения от стоимости до весов умножаются(как видно из приведенного выше уравнения).
Поскольку в RNN есть три веса, нам требуются три градиента. Градиент input_weights(dLoss/ду), internal_state_weights(dLoss/ДГ) и output_weights(dLoss/дв).
Цепочку этих трех градиентов можно представить следующим образом:

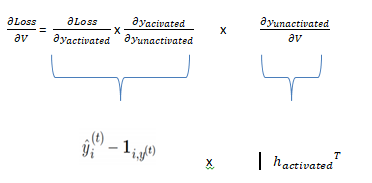
Примечание: здесь t обозначает транспонирование.
DLoss/dy_unactivated кодируется следующим образом:
Чтобы узнать больше о деривативах потерь, пожалуйста, обратитесь к этому блогу. Есть две градиентные функции, которые мы будем вычислять: одна-multiplication_backward, а другая-addition_backward. В случае умножения _backward мы возвращаем 2 параметра, один из которых является градиентом по отношению к весам (dLoss/dV), а другой-цепным градиентом, который будет частью цепочки для вычисления другого весового градиента. В случае сложения назад при вычислении производной мы обнаруживаем, что производная отдельных компонентов в функции add(ht_unactivated) равна 1. Например: dh_unactivated/dU_frd= 1 as (h_unactivated = U_frd + W_frd_) и производная от dU_frd/dU_frd= 1. Но число единиц относится к размерности U_frd. Чтобы узнать больше о градиентах, вы можете обратиться к этому источнику. Вот и все, это единственные две функции, необходимые для вычисления градиентов. Функция multiplication_backward используется для уравнений, содержащих точечное произведение векторов, и addition_backward для уравнений, содержащих сложение двух векторов.
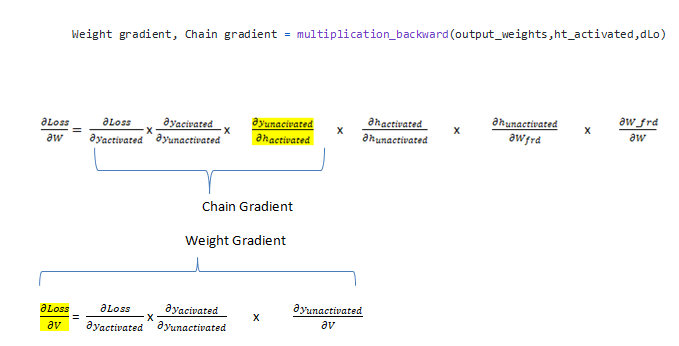
Теперь, когда вы проанализировали и поняли обратное распространение для RNN, пришло время реализовать его для одной единственной временной метки, которая позже будет использоваться для вычисления градиентов по всем временным меткам . Как видно из приведенного ниже кода , forward_params_t-это список, содержащий прямые параметры сети на определенном временном шаге. Переменная ds является жизненно важной частью, поскольку эта строка кода учитывает скрытое состояние предыдущих временных меток, что поможет извлечь адекватную полезную информацию, необходимую при обратном распространении.
Для RNN вместо использования ванильного обратного распространения мы будем использовать усеченное обратное распространение из-за проблемы исчезающего градиента. В этом методе вместо того, чтобы смотреть только на одну временную метку назад , текущая ячейка будет смотреть на k временных меток назад, где k представляет количество предыдущих ячеек, чтобы посмотреть назад, чтобы получить больше знаний.
Обновление Весов:
После того, как мы рассчитали градиенты с помощью обратного распространения, мы должны обновить веса, что делается с использованием под

Вывод:
Теперь, когда вы внедрили рекуррентную нейронную сеть, пришло время сделать шаг вперед с помощью передовых архитектур, таких как LSTM и GRU, которые используют скрытые состояния гораздо эффективнее, чтобы сохранить смысл более длинных последовательностей. Впереди еще долгий путь. С большим количеством достижений в области НЛП существуют очень сложные алгоритмы, такие как Элмо и Берт. Поймите их и постарайтесь реализовать самостоятельно. Он следует той же концепции памяти, но вносит элемент взвешенных слов. Поскольку эти модели очень сложны, использование Numpy было бы недостаточно, скорее привить навыки PyTorch или TensorFlow для их реализации и создания удивительных систем искусственного интеллекта, которые могут служить сообществу.
Вдохновение для создания этого учебника было получено из этого блога github.
Вы можете получить доступ к записной книжке для этого урока здесь.
Надеюсь, вам всем понравился этот урок!
Рекомендации:
[1] Sargur Srihari, RNN-Gradients, https://cedar.buffalo.edu/~srihari/CSE676/10.2.2%20RNN-Gradients.pdf
[2] Yu Gong, RNN-from-scratch, https://github.com/pangolulu/rnn-from-scratch
Hands-on real-world examples, research, tutorials, and cutting-edge techniques delivered Monday to Thursday. Make learning your daily ritual.б Take a look
Телеграм: t.me/ainewsline
Источник: towardsdatascience.com