На Хабре практически нет информации про квантовое машинное обучение (Quantum Machine Learning), и в этой статье я постараюсь подробнее раскрыть тему. Сразу скажу, что промышленных квантовых компьютеров сегодня не существует, все основные разработки в этой области носят теоретический характер, а задачу, которую мы будем разбирать в статье можно решить «по классике» за доли секунд. Но ведь еще 30 лет назад была так называемая «зима искусственного интеллекта», а сегодня нейронные сети буквально окружают нас. Кто знает, может быть вскоре и квантовые компьютеры станут неотъемлемой частью нашей жизни? К тому же область квантовых вычислений, а тем более область QML, обладает особой притягательностью и таинственностью и, как минимум, стоит быть замеченной.

В статье я постарался рассказать о QML в целом, а также об основном строительном блоке QML — Variational Quantum Circuit. Большую часть статьи я постарался сделать практической, c примерами кода на Cirq, а в конце — добавил реализацию одного из базовых алгоритмов QML на Tensorflow Quantum.
Введение
Гипотетически QML имеет ряд существенных преимуществ, по сравнению с классическим машинным обучением. Variational Quantum Circuit, или VQC, которые можно назвать «аналогом» классических полносвязных слоев в обычных нейронных сетях, являются более «выразительными» и при этом содержат меньше обучаемых параметров. Ряд квантовых алгоритмов потенциально также дает существенное ускорение по сравнению с обычными аналогами:
| Метод | Ускорение |
|---|---|
| Bayesian Inference | |
| Online Perceptron | |
| Least Square Fitting | |
| Classical Boltzman Machine | |
| Quantum Boltzman Machine | |
| Quantum PCA | |
| Quantum SVM | |
| Quantum RL |
Для наиболее полного ознакомления с темой я рекомендую обзор 2017-го года в журнале Nature или препринт той же работы в arXiv. Именно из этой работы я взял данную таблицу. В ней указано ускорение по сравнению с классическим аналогом. Так, подразумевает, что квантовый алгоритм квадратично быстрее, чем его классический аналог, а означает экспоненциальное ускорение.
Я постарался писать эту статью с минимальным числом формул, но все же совсем без них нельзя. Также в квантовых вычислениях используется своя нотация линейной алгебры. Сложно сказать, хорошо это или плохо, но я буду использовать именно Дираковскую нотацию, так как во всех других источниках и научных работах будет именно она, — лучше привыкать к ней с самого начала. Сразу скажу, что ничего страшного в статье не будет, и все формулы я буду пытаться максимально пояснять словами.
- Вектор столбец
- Вектор строка
- Скалярное произведение это
- Умножение матрицы на вектор или действие оператора на состояние
- Ожидаемое значение оператора в состоянии
Основа QML
Как я уже говорил, основной «строительный блок» в QML — это Variational Quantum Circuit. Их мы детально рассмотрим чуть позже, но в целом любая статья или любой новый алгоритм по QML будет так или иначе содержать набор VQC или их вариаций. Такие блоки не являются чисто квантовыми схемами, и в этом они сильно отличаются, например, от широко известных квантовых алгоритмов Шора или Гровера. В основном QML строится по «гибридной» схеме, когда у нас есть параметризованные квантовые схемы, такие как VQC, и они составляют собой «квантовую» часть. «Классическая» часть обычно отвечает за оптимизацию параметров квантовых схем, например, градиентными методами, так, чтобы VQC, подобно слоям нейронных сетей, «выучивали» нужные нам преобразования входных данных. Именно так построена библиотека Tensorflow Quantum, где квантовые «слои» сочетаются с классическими, а обучение происходит как в обычных нейронных сетях.
Variational Quantum Circuit
VQC — это простейший элемент систем квантово-классического обучения. В минимальном варианте представляет собой квантовую схему, которая кодирует входным вектором данных квантовое состояние и далее применяет к этому состоянию параметризованные параметрами операторы. Если проводить аналогию с обычными нейронными сетями, то можно представить себе VQC как некий «черный ящик», или «слой», который выполняет преобразование входных данных в зависимости от параметров . И тогда, можно сказать, что — это аналог «весов» в классических нейронных сетях.
Вот так выглядит простейшая VQS, где вектор кодируется через вращения кубитов вокруг оси , а параметры кодируют вращения вокруг оси :
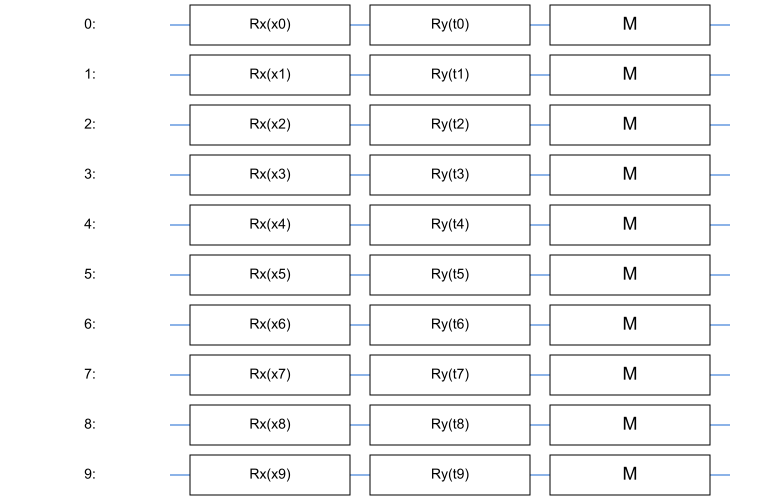
Разберем этот момент подробнее. Мы хотим закодировать входной вектор данных в состояние , по сути своей, выполнить операцию перевода «классических» входных данных в квантовые. Для этого мы берем кубитов, каждый из которых исходно находится в состоянии . Состояние каждого отдельного кубита мы можем представить как точку на поверхности сферы Блоха:
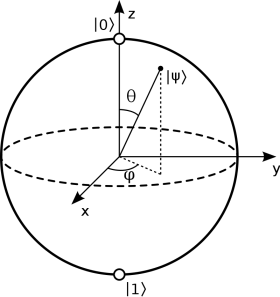
Мы можем «вращать» состояние нашего кубита, применяя специальные однокубитные операции, так называемые гейты , , , соответствующие поворотам относительно разных осей сферы Блоха. Мы будем поворачивать каждый кубит, например, по оси на угол, определяемый соответствующей компонентой входного вектора .
Получив квантовый входной вектор, мы хотим теперь применить к нему параметризованное преобразование. Для этого мы будем «вращать» соответствующие кубиты уже по другой оси, например, по на углы, определяемые параметрами схемы .
Это наиболее простой пример VQC, и, как мы увидим дальше, есть более сложные модификации, но суть у всех приблизительно одна.
В библиотеке для квантовых вычислений Cirq от компании Google, которой мы будем активно пользоваться, это можно реализовать, например, так:
import cirq import sympy qubits = cirq.LineQubit.range(10) x = sympy.symbols("x0:10") thetas = sympy.symbols("t0:10") circuit = cirq.Circuit() for i in range(10): circuit.append(cirq.rx(x[i])(qubits[i])) circuit.append(cirq.ry(thetas[i])(qubits[i]))cirq.LineQubit— это кубит на одномерной цепочке, а методrangeсоздает нам сразу нужное число кубитов;- В Cirq все кубиты изначально находятся в состоянии , так что нам не нужно специально их инициализировать;
cirq.Circuit— это как раз наша схема, объединенный набор квантовых гейтов (или по другому вентилей) — квантовых операций над кубитами;cirq.rx,cirq.ry— это наши «вращения фазы» на нужный угол в радианах.
Тут мы также воспользовались библиотекой символьной алгебры SymPy, просто Cirq позволяет параметризовывать схемы лишь через нее.
Таким образом, мы получаем квантовую ячейку — circuit, которая параметризируется классическими параметрами и применяет преобразование к классическому входному вектору. Именно на таких «блоках» и строятся алгоритмы квантово-классического обучения. Мы будем применять преобразования к классическим данным на квантовом компьютере (или симуляторе), измерять выход нашей VQC и далее использовать классические градиентные методы для обновления параметров VQC.
Variational Quantum Eigensolver
Основой многих алгоритмов квантового машинного обучения является Harrow-Hasssidim-Loloyd алгоритм (есть препринт в arXiv) для поиска решения систем линейных уравнений. Именно на основе этого алгоритма построен, например, квантовый SVM — наиболее известный и многообещающий алгоритм QML. Однако HHL достаточно сложный и начинать рассказ с него было бы странно. Вместо этого, далее, мы посмотрим как устроен другой алгоритм — Variational Quantum Eigensolver, алгоритм поиска минимальных собственных значений эрмитовых матриц, который лежит в основе HHL.
Почему именно проблема собственных значений? Ответ прост:
- поиск минимальных собственных значений эрмитовых операторов — важная задача физики, именно для нее Р. Фейнман впервые предложил модель квантового компьютера;
- Variational Quantum Eigensolver является ключевой частью HHL-алгоритма, итерация HHL сводится к задаче о собственных значениях;
- Сам алгоритм достаточно прост как для понимания, так и для реализации.
Опишем задачу формально.
Дана эрмитова матрица , или, другими словами, самосопряженный эрмитив оператор. Требуется найти , которое является минимальным собственным значением оператора .
Для решения этой задачи мы воспользуемся так называемой «Вариационной теоремой» (Variational theorem), которая для оператора дает нам следующее:
где это минимальное собственное значение оператора. По сути тут сказано, что ожидаемый результат измерения оператора в состоянии всегда больше или равен минимальному собственному значению этого оператора. На этом и строится наш процесс:
- Готовим состояние , параметризованное вектором параметров
- Измеряем ожидаемое значение оператора в этом состоянии
- Оцениваем градиент , ожидаемого значения по весам
- Обновляем вектор :
Таким образом, наш параметризованный вектор каждый раз будет все ближе к первому собственному вектору оператора, а будет (с погрешностью на оценку ожидания) приближаться к минимальному собственному значению .
Надеюсь, больше понимания станет, когда мы посмотрим, как это выглядит в коде.
Реализация на Tensorflow Quantum
Для начала краткие обозначения импортов:
Код импортов
import tensorflow as tf import tensorflow-quantum as tfq Tensorflow Quantum — специальная библиотека, которая позволяет использовать схемы Cirq как тензоры Tensorflow, а также содержит специализированные варианты tf.keras.Layers для квантово-классического обучения. Библиотека совместима со стилем и другими слоями tf и позволяет задействовать систему автоматического диффиренцирования Tensorflow. Одним из таких tfq.layers мы и воспользуемся — это tfq.layers.SampledExpectation.
Этот слой, в том числе, позволяет оценивать ожидаемое значение оператора в каком-то состоянии, а потом еще и градиент по параметрам схемы, параметризировавшей это состояние. Сигнатура у него такая:
layer = tfq.layers.SampledExpectation() res = layer( circuit, symbol_names, symbol_values, operators, repetitions, )cicuit— схема (cirq.Circuit), параметризирующая состояниеsymbol_names— символыsympy, которые параметризируют состояниеsymbol_values— значения символов-параметров (обычноtf.Variable)operators— операторы (например,cirq.PauliSum)repetitions— число измерений, по которым оценивается значение оператора
Этот слой явно реализует нам для оператора оценку значения оператора в конкретном состоянии по определенному числу измерений:
А параметры в формуле связаны с сигнатурой метода call следующим образом:
| Формула | Сигнатура tfq.layers.SampledExpectation.call |
|---|---|
symbol_values — значения параметров | |
circuit — квантовая схема «готовит» нам состояние | |
symbol_names — связь параметры схемы с symbol_values | |
operators — оператор, например cirq.PauliSum |
Параметр repetition не имеет прямой связи с математическим формализмом, но именно он показывает нам насколько хорошо мы оцениваем значение оператора.
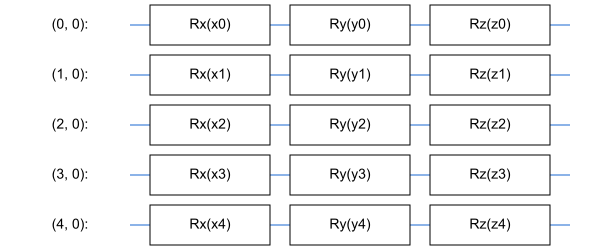
Но перед началом всего обучения необходимо решить, как именно мы будем параметризовать состояние. В вышеописанных терминах нам надо определить , который мы будем передавать в качестве параметра circuit в tfq.layers.SampledExpectation. В данном случае воспользуемся более сложной параметризацией, где на каждый спин у нас будет три параметра: , а не один:
Код VQC для Eigensolver-а
qubits = cirq.GridQubit.rect(dim, 1) params_x = sympy.symbols(f"x0:{dim}") params_y = sympy.symbols(f"y0:{dim}") params_z = sympy.symbols(f"z0:{dim}") cirquit = cirq.Circuit() for i in range(dim): cirquit.append(cirq.rx(params_x[i])(qubits[i])) cirquit.append(cirq.ry(params_y[i])(qubits[i])) cirquit.append(cirq.rz(params_z[i])(qubits[i]))Выглядит наша схема так:
Для примера, найдем минимальное собственное значение оператора Transverse-field Ising, так называемой «квантовой модели Изинга». Этот оператор строится применением операторов Паули (в нашем варианте это будут и ) и имеет два «классических» параметра . Параметры на самом деле имеют физический смысл, а сам оператор часто применяют для описания Гамильтонианов реальных физических систем, то есть это не просто абстрактная задача. Но сейчас аспекты физики нас интересуют в меньшей степени. На самом деле любой эрмитов оператор можно определить в терминах матриц Паули, так что выбрав Изинга мы не теряем общности рассуждений.
Это оператор размерности , где это число кубитов, на которое он действует. Так как квантовые симуляторы достаточно «прожорливы», а доступ к реальным кубитам в Google Cloud Platform стоит денег, то не будем брать большую размерность . Сейчас нам интересно просто посмотреть, как оно работает, о каком-то превосходстве квантовых алгоритмов на реальных задачах речи не идет. Запишем реализацию этого оператора в коде Cirq.
TFI оператор (матрица) в коде Cirq
def get_ising_operator( qubits: List[cirq.GridQubit], j: float, h: float ) -> cirq.PauliSum: op = h * cirq.X(qubits[-1]) for i, _ in enumerate(qubits[:-1]): op -= j * cirq.Z(qubits[i]) * cirq.Z(qubits[i + 1]) op += h * cirq.X(qubits[i]) return opХотелось бы еще раз обратить внимание на тот факт, что для кубитов оператор TFI это матрица размера (а не , как можно было бы подумать!) Чтобы убедится в этом, ниже, под спойлером, будет код определения такого же оператора на чистом NumPy в виде разреженной комплексной матрицы:
Рассмотрим, например, оператор Паули . Согласно определению, это матрица :
Но, как можно было заметить, у нас система из кубит, а оператор, который действует на такую систему, это оператор размерности . Чтобы понять, как мы от матрицы переходим к матрице , рассмотрим оператор , который действует на -й кубит в системе. Это эквивалентно тому, что мы действуем оператором на -й кубит, а на остальные мы действуем единичными операторами . Запишем это явно, используя произведение Кронекера :
Определив схожим образом другие матрицы Паули, мы можем определить наш TFI оператор просто через операции привычной линейной алгебры:
import numpy as np from scipy import sparse def sigmaz_k(k, N) -> sparse.csr_matrix: res = 1 for i in range(N): if i == k: res = sparse.kron( res, sparse.csr_matrix( np.array([[1, 0], [0, -1]], dtype=np.complex) ) ) else: res = sparse.kron(res, sparse.eye(2, dtype=np.complex)) return res def sigmax_k(k, N) -> sparse.csr_matrix: res = 1 for i in range(N): if i == k: res = sparse.kron( res, sparse.csr_matrix( np.array([[0, 1], [1, 0]], dtype=np.complex) ) ) else: res = sparse.kron(res, sparse.eye(2, dtype=np.complex)) return res def tfi_op(N, j, h) -> sparse.csr_matrix: res = sparse.csr_matrix((2 ** N, 2 ** N), dtype=np.complex) for i in range(N - 1): res += -j * sigmaz_k(i, N) * sigmaz_k(i + 1, N) res += h * sigmax_k(i, N) res += h * sigmax_k(N - 1, N) return resЭто как раз и будет наша матрица . В лоб перемножать матрицы не самый эффективный метод, моя реализация наивная, но идейно это то же самое, что происходит в Cirq.
Как я уже писал, минимальное собственное значение этого оператора мы легко найдем «классическими» методами (например, алгоритм Арнольди) в пару строчек кода, используя готовые рутины:
Для определенного выше оператора Cirq op мы можем явно получить его матрицу, вызвав метод op.matrix(). Ну и рутины из scipy.sparse.linalg.
from scipy import sparse from scipy.sparse import linalg exact_sol = linalg.eigs( sparse.csc_matrix(op.matrix()), k=1, which="SR", return_eigenvectors=False )[0] print(f"Exact solution: {np.real(exact_sol):.4f}")Мы тут берем реальную часть, потому что из квантовой физики мы точно знаем, что собственные значения квантовых операторов реальные, так как они являются еще и потенциальными результатами измерений. Например, в физике, собственное значение оператора TFI соответствует энергии в эВ, то есть реальной физической величине.
Это значение нам потом пригодится для оценки того, куда и как сходится наш квантовый алгоритм.
Ну и наконец самое интересное, код для обучения нашей VQC на Tensorflow Quantum.
# Оператор op = get_ising_operator(qubits, j, h) # Модель model = tfq.layers.SampledExpectation() # Вектор обучаемых параметров thetas = tf.Variable(np.random.random((1, 3 * dim)), dtype=tf.float32) log_writer = tf.summary.create_file_writer("train") for epoch in tqdm(range(epochs)): with tf.GradientTape() as gt: out = model( cirquit, symbol_names=params_x + params_y + params_z, symbol_values=thetas, operators=op, repetitions=5000, ) grad = gt.gradient(out, thetas) thetas.assign_sub(lr * grad) with log_writer.as_default(): tf.summary.scalar("Eigen Val", out[0, 0], step=epoch) tf.summary.histogram("Gradients", grad, step=epoch) lr тут это параметр, отвещающий за скорость градиентного спуска и являющийся гиперпараметром.
Это простейший стандартный цикл обучения в Tensorflow, а model — это объект класса tf.keras.layers.Layer, для которого можно применять все наши привычные оптимизаторы, логгеры и приемы из «классического» глубокого обучения. Параметры VQC хранятся в переменной типа tf.Variable и обновляются по простому правилу , это минимальная реализация градиентного спуска со скоростью . Каждый раз мы используем 5000 измерений для максимально точной оценки ожидаемого значения нашего оператора в состояниии . Все это в течение 350 эпох. На моем ноутбуке для , и процесс занял порядка 40 секунд.
Визуализируем графики обучения (scipy дал точное решение ): tensoboard --logdir train/
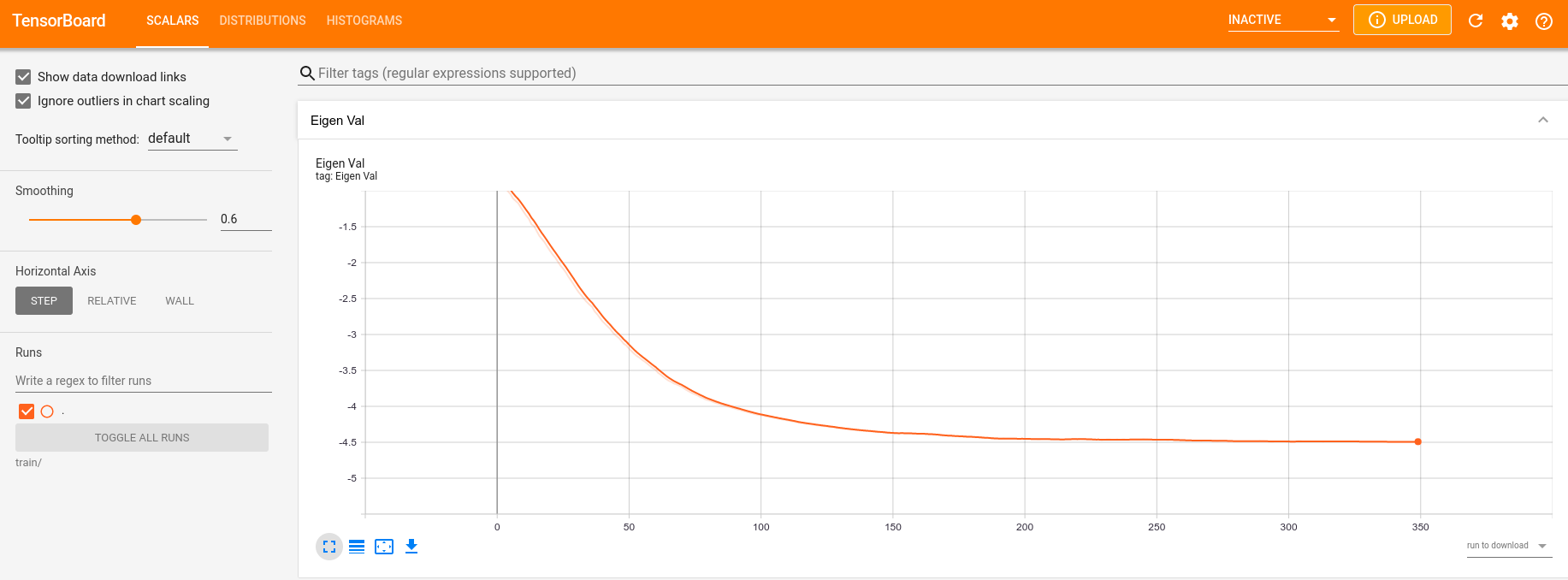
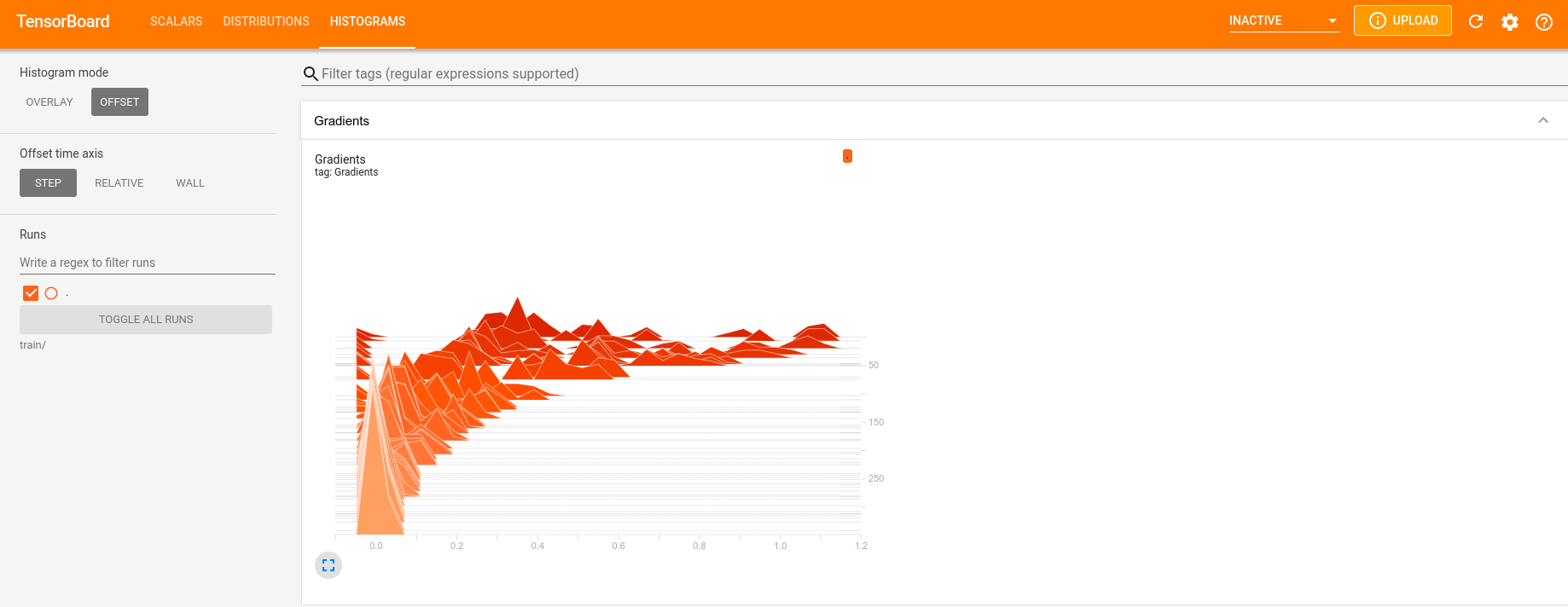
Это уже «привычные» всем специалистам по машинному обучению картинки Tensorboard. Можно видеть, как собственное значение хорошо сходится к точному, а градиенты идут к нулю.
Внимательный читатель мог заметить, что решение VQC оказалось «ниже» решения прямой диагонализации. Я думаю причин тут две:
tfq.layers.SampledExpectation, скорее всего, производит «измерения» и , после чего вычисляет ожидание прямым перемножением восстановленных волновых функций. Я думаю, основная погрешность живет именно в вероятностном характере квантовых измерений и их симуляций, потому что обычно мы измеряем все по оси , а «фазу» определяем, решая задачу квантовой томографии. Ну, по крайней мере, я бы делал такой «слой» именно так, хотя не берусь утверждать, что именно «под капотом» у Tensorflow Quantum.- Итеративные алгоритмы дают нам ответ с мнимой частью отличной от нуля, что говорит о том, что они тоже не до конца точны (на то они и итеративные), так как из физики мы знаем, что наблюдаемые — это все же реальные числа. В свою очередь, это тоже может давать некий «сдвиг», так как в сигнатуре вызова
scipy.linalg.eigsмы явно просили алгоритм найти собственные числа с минимальной действительной частью (which="SR"), а, возможно, надо было просить что-то другое.
Думаю, что основной фактор — это все же первый пункт, но не берусь утверждать точно. Возможно, кто-то в комментариях подскажет версию лучше.
Еще пара слов о потенциале такого Eigensolver-а
Несмотря на «игрушечность» примера с 5-ю кубитами, я бы хотел еще раз напомнить, что мы работаем с матрицей . Более того, в сравнении с классическими методами глубокого обучения, сама идея о том, что мы параметризуем преобразование при помощи всего лишь параметров (в нашем случае ровно ) выглядит очень перспективно. Для сравнения — в классическом глубоком обучении такое преобразование кодировалось бы квадратной матрицей весов , то есть экспоненциально большим числом параметров. При этом в ряде работ было показано, что в сравнении с обычными полносвязными слоями нейронных сетей VQC даже более «выразительны» при столь меньшем числе параметров! Именно этим, как мне кажется, обусловлен такой живой интерес к этой области: если бы имели бы реальный квантовый компьютер, QML на основе таких VQC, вероятно, были бы гораздо круче классических нейронных сетей во многих задачах.
Заключение
Несомненно, сейчас не идет речи о каком-то реальном применении QML. Для сравнения — наша VQC обучалась около 45 секунд на моем ноутбуке, а scipy.sparse.eigs потребовались доли секунд, чтобы найти минимальное собственное значение. К тому же, даже на симуляторе, где нет шума, оценка tfq.layers.SampledExpectation явно «хромает», что уж говорить о реальных квантовых компьютерах. Но сейчас очень многие частные компании, такие как Google, IBM, Microsoft и другие, а также правительства и институты тратят огромные ресурсы на исследования в данном направлении. Квантовые компьютеры уже сегодня доступны для тестирования в облачных серверах IBM и AWS. Многие ученые высказывают уверенность в скором достижении квантового превосходства на практических задачах (напомню, превосходство на специально выбранной «удобной» для квантового компьютера задаче было достигнуто Google в прошлом году). Все это, а также таинственность и красота квантового мира, делает эту область такой привлекательной. Надеюсь, эта статья поможет и вам погрузиться в дивный квантовый мир!
Весь используемый код можно посмотреть в моем GitHub.