BAAAN: бэкдор атаки на автоэнкодеры и GAN модели
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-10-29 14:31
распознавание образов, алгоритмы машинного обучения, реализация нейронной сети

Исследователи из CISPA и Cyber-Defence Campus проверили автоэнкодер-модели и GAN-модели на устойчивость к бэкдор атакам. Исследователи обучили модели, для которых можно контролировать сгенерированные изображения через скрытые триггеры в входных данных.
Атаки на ML-модели
Прогресс в автоэнкодерах и генеративно-состязательных моделях привел к тому, что такие модели применяются для задач распознавания мошенничества и генерации чистых данных. Рост популярности привел к необходимости исследования рисков безопасности и приватности у моделей. Прошлые работы, в основном, фокусировались на инференс атаках (membership inference). Исследователи, в свою очередь, тестировали модели на устойчивость к бэкдор атакам. Бэкдор атака — это атака на этапе обучения модели, когда злоумышленник помещает лазейку в обучающую выборку модели, которая может быть активирована специальным триггером. State-of-the-art бэкдор атаки проводили для задачи классификации. Исследователи предлагают способ проведения бэкдор атак на генеративные модели. В предложенных атаках злоумышленник может контролировать изображения, которая модель декодирует или генерирует. Необходимым условием является активированный триггер.
Как работают атаки
Для автоэнкодеров
В бэкдор атаке против автоэнкодера злоумышленник может контролировать выход для любого изображения со скрытым триггером. Скрытым триггером может быть специфический паттерн на изображении. Например, белый квадрат. Выходом для такого изображения можно задать какое-то фиксированное изображение или обратное входному изображение. На изображениях без триггера модель работает, как стандартный автоэнкодер.
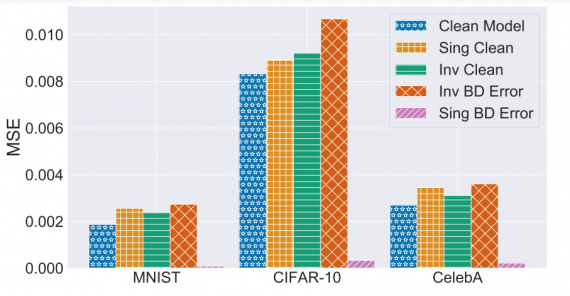
По результатам тестов на датасете CelebA, атакованная модель выдавала предсказания для изображений с триггером с MSE в 0.0036. На чистых данных MSE было равно 0.0031. Метрика ошибок атакованной модели была на 0.00042 выше, чем у чистой модели.
Для GAN моделей
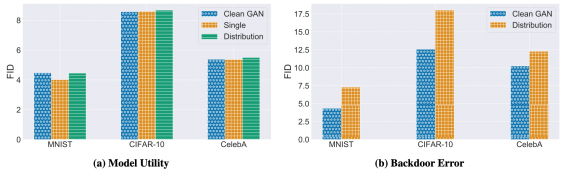
В случае с бэкдор атакой для GAN триггеры помещаются во входной вектор с шумом. Злоумышленник может настроить триггер так, что бы модель генерировала константное изображение или генерировала изображения из другого распределения.
Эксперименты показали, что атакованная GAN достигает 4.4, 8.7 и 5.5 по метрике Frechet Inception Distance (FID). Это на 0.8% хуже, на 1.25% и на 2.2% лучше, чем чистая GAN. Сравнивали на датасетах MNIST, CIFAR-10 и CelebA соответственно.
Телеграм: t.me/ainewsline
Источник: neurohive.io