
Что такое короткие и долгие метрики?
Модели ранжирования пытаются оценить вероятность того, что пользователь повзаимодействует с новостью (постом): задержит на ней внимание, поставит отметку «Нравится», напишет комментарий. Затем модель распределяет записи по убыванию этой вероятности. Поэтому, улучшая ранжирование, мы можем получить рост CTR (click-through rate) пользовательских действий: лайков, комментов и других. Эти метрики очень чувствительны к изменениям модели ранжирования. Я буду называть их короткими.
Но есть и другой тип метрик. Считается, например, что время, проведённое в приложении, или количество сессий пользователя намного лучше отражают его отношение к сервису. Будем называть такие метрики долгими.
Оптимизировать долгие метрики непосредственно через алгоритмы ранжирования — нетривиальная задача. С короткими метриками это делать намного проще: CTR лайков, например, напрямую связан с тем, насколько хорошо мы оцениваем их вероятность. Но если мы знаем причинно-следственные (или каузальные) связи между короткими и долгими метриками, то можем сфокусироваться на оптимизации лишь тех коротких метрик, которые должны предсказуемо влиять на долгие. Я попытался извлечь такие каузальные связи — и написал об этом в своей работе, которую выполнил в качестве диплома на бакалавриате ИТМО (КТ). Исследование мы проводили в лаборатории «Машинное обучение» ИТМО совместно с ВКонтакте.
Ссылки на код, датасет и песочницу
Весь код вы можете найти здесь: AnverK. Чтобы проанализировать связи между метриками, мы использовали датасет, включающий результаты более чем 6000 реальных A/B-тестов, которые в разное время проводила команда ВКонтакте. Датасет тоже доступен в репозитории. В песочнице можно посмотреть, как пользоваться предложенной обёрткой: на синтетических данных. А здесь — как применять алгоритмы к датасету: на предложенном датасете.
Боремся с ложными корреляциями
Может показаться, что для решения нашей задачи достаточно посчитать корреляции между метриками. Но это не совсем так: корреляция — это не всегда причинно-следственная связь. Допустим, мы измеряем всего четыре метрики и их причинно-следственные связи выглядят так:

Даже на таком простом примере становится очевидно, что простой анализ корреляций приведёт к множеству неверных выводов. Восстановить причинно-следственные связи из данных позволяет causal inference (методы вывода связей). Чтобы применить их в задаче, мы выбрали наиболее подходящие алгоритмы causal inference, реализовали для них python-интерфейсы, а также добавили модификации известных алгоритмов, которые лучше работают в наших условиях.
Классические алгоритмы вывода связей
Мы рассматривали несколько методов вывода связей (causal inference): PC (Peter and Clark), FCI (Fast Causal Inference) и FCI+ (похож на FCI с теоретической точки зрения, но намного быстрее). Почитать о них подробно можно в этих источниках:
- Causality (J. Pearl, 2009),
- Causation, Prediction and Search (P. Spirtes et al., 2000),
- Learning Sparse Causal Models is not NP-hard (T. Claassen et al., 2013).
Но важно понимать: первый метод (PC) предполагает, что мы наблюдаем все величины, влияющие на две метрики или более, — такая гипотеза называется Causal Sufficiency. Другие два алгоритма учитывают, что могут существовать ненаблюдаемые факторы, которые влияют на отслеживаемые метрики. То есть во втором случае каузальное представление считается более естественным и допускает наличие ненаблюдаемых факторов :

По итогам работы всех алгоритмов строится PAG (partial ancestral graph) в виде списка рёбер. При алгоритме PC его стоит интерпретировать как каузальный граф в классическом понимании (или байесовскую сеть): ребро, ориентированное из в , означает влияние на . Если ребро ненаправленное или двунаправленное, то мы не можем однозначно его ориентировать, а значит:
- или имеющихся данных недостаточно, чтобы установить направление,
- или это невозможно, потому что истинный каузальный граф, используя только наблюдаемые данные, можно установить лишь с точностью до класса эквивалентности.
Результатом работы FCI-алгоритмов будет тоже PAG, но в нём появится новый тип рёбер — с «о» на конце. Это означает, что стрелка там может как быть, так и отсутствовать. При этом важнейшее отличие FCI-алгоритмов от PC в том, что двунаправленное (с двумя стрелками) ребро даёт понять, что связываемые им вершины — следствия некой ненаблюдаемой вершины. Соответственно, двойное ребро в PC-алгоритме теперь выглядит как ребро с двумя «о» на концах. Иллюстрация для такого случая есть в песочнице с синтетическими примерами.
Модифицируем алгоритм ориентации рёбер
У классических методов есть один существенный недостаток. Они допускают, что могут быть неизвестные факторы, но при этом опираются на ещё одно слишком серьёзное предположение. Его суть в том, что функция тестирования на условную независимость должна быть идеальной. Иначе алгоритм за себя не отвечает и не гарантирует ни корректность, ни полноту графа (то, что больше рёбер сориентировать нельзя, не нарушая корректность). Много ли вы знаете идеальных тестов на условную независимость при конечной выборке? Я нет.
Несмотря на этот недостаток, скелеты графов строятся довольно убедительно, но ориентируются слишком агрессивно. Поэтому я предложил модификацию к алгоритму ориентации рёбер. Бонус: она позволяет неявным образом регулировать количество ориентированных рёбер. Чтобы понятно объяснить её суть, пришлось бы подробно говорить здесь о самих алгоритмах вывода каузальных связей. Поэтому теорию по этому алгоритму и предложенной модификации я приложу отдельно — ссылка на материал будет в конце поста.
Сравниваем модели — 1: оценка правдоподобия графа
Одну из серьёзных трудностей при выводе каузальных связей представляет, как ни странно, сравнение и оценка моделей. Как так вышло? Дело в том, что обычно истинное каузальное представление реальных данных неизвестно. И тем более мы не можем знать его с точки зрения распределения настолько точно, чтобы генерировать из него реальные данные. То есть неизвестен ground truth для большинства наборов данных. Поэтому возникает дилемма: использовать (полу-) синтетические данные с известным ground truth или пытаться обходиться без ground truth, но тестировать на реальных данных. В своей работе я попробовал реализовать два подхода к тестированию.
Первый из них — оценка правдоподобия графа:

Важно понимать, что такая оценка работает только для сравнения байесовских сетей (выхода алгоритма PC), потому что в настоящих PAG (выход алгоритмов FCI, FCI+) у двойных рёбер совсем иная семантика.
Поэтому я сравнил ориентацию рёбер моим алгоритмом и классическим PC:
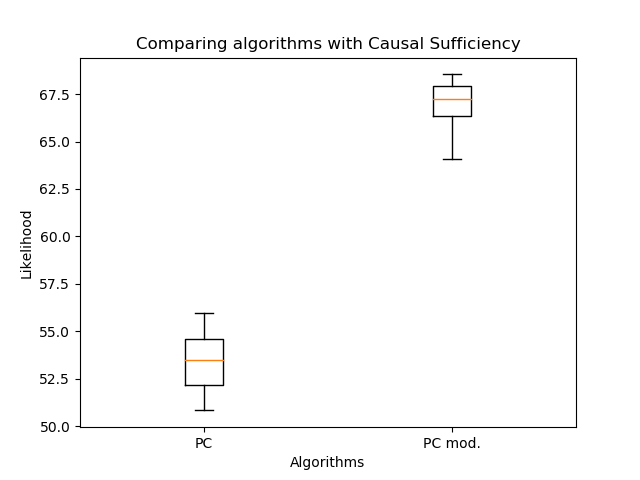
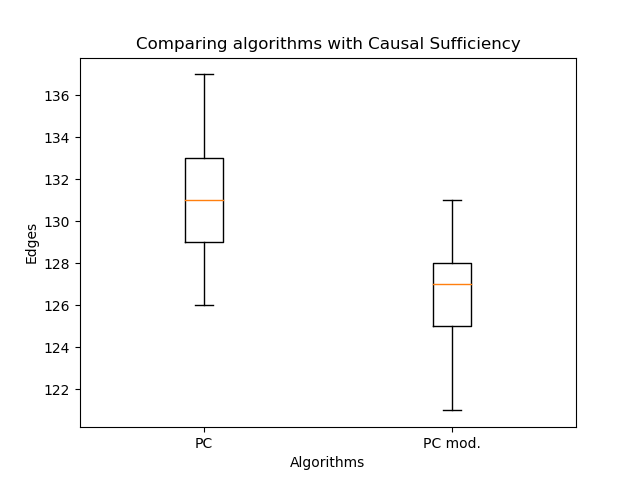
Сравниваем модели — 2: используем подход из классификации
Перейдём ко второму способу сравнения. Будем строить PC-алгоритмом каузальный граф и выбирать из него случайный ациклический граф. После этого сгенерируем данные в каждой вершине как линейную комбинацию значений в родительских вершинах с коэффициентами с добавлением гауссова шума. Идею для такой генерации я взял из статьи «Towards Robust and Versatile Causal Discovery for Business Applications» (Borboudakis et al., 2016). Вершины, которые не имеют родителей, генерировались из нормального распределения — с параметрами, как в наборе данных для соответствующей вершины.
Когда данные получены, применяем к ним алгоритмы, которые хотим оценить. При этом у нас уже есть истинный каузальный граф. Осталось только понять, как сравнивать полученные графы с истинным. В «Robust reconstruction of causal graphical models based on conditional 2-point and 3-point information» (Affeldt et al., 2015) предложили использовать терминологию классификации. Будем считать, что проведённое ребро — это Positive-класс, а непроведённое — Negative. Тогда True Positive () — это когда мы провели то же ребро, что и в истинном каузальном графе, а False Positive () — если провели ребро, которого в истинном каузальном графе нет. Оценивать эти величины будем с точки зрения скелета.
Чтобы учитывать направления, введём для рёбер, которые выведены верно, но с неправильно выбранным направлением. После этого будем считать так:
Наконец, сравним алгоритмы:

Сравниваем модели — 3: выключаем Causal Sufficiency
Теперь «закроем» некоторые переменные в истинном графе и в синтетических данных после генерации. Так мы «выключим» Causal Sufficiency. Но сравнивать результаты надо будет уже не с истинным графом, а с полученным следующим образом:
- рёбра от родителей скрытой вершины будем проводить к её детям,
- всех детей скрытой вершины соединим двойным ребром.
Сравнивать уже будем алгоритмы FCI+ (с модифицированной ориентацией рёбер и с классической):

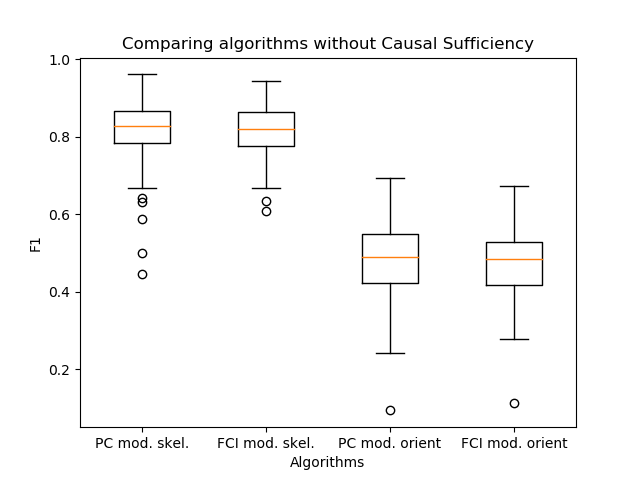
Вывод
Сформулирую кратко, о чём мы поговорили в этой статье:
- Как задача вывода каузальных связей может возникнуть в крупной IT-компании.
- Что такое ложные корреляции и как они могут мешать Feature Selection.
- Какие алгоритмы вывода связей существуют и используются наиболее часто.
- Какие трудности могут возникать при выводе каузальных графов.
- Что такое сравнение каузальных графов и как с этим бороться.
Если вас заинтересовала тема вывода каузальных связей, загляните и в другую мою статью — в ней больше теории. Там я подробно пишу о базовых терминах, которые используются в выводе связей, а также о том, как работают классические алгоритмы и предложенная мной ориентация рёбер.