Альтернативные методы анализа данных при Process Mining. Кластеризация.
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-10-05 10:00

Можно ли выявить аномалии процесса при анализе его логов? Конечно же, да! Любой софт, который анализирует логи легко это делает. Но можно ли сопоставить аномалии в логах процесса и аномалии в самих данных? При проведении проверки командировочного процесса мы провели анализ аномалий не только с применением традиционных методов Process Mining, но и применяя методы кластерного анализа и программный пакет Statistica.
После обработки логов мы получили следующий датасет из 122937 событий для последующей обработки (дополнительно провели LabelEncoder нечисловых данных):
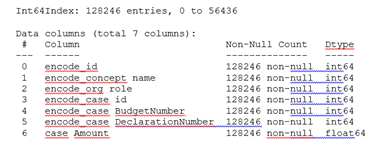
В результате получилось 16103 уникальных case id, представляющих собой упорядоченную во времени последовательность событий (id).
При проведении анализа мы взяли в качестве отдельного случая (строк) «case id». В качестве столбцов использовались значения поля «concept name». При наличии шага в кейсе проставляется 1, при отсутствии — 0, если шаг повторяется, то значение суммируется.
В программном пакете для статистического анализа Statistica мы провели анализ, в качестве показателей взяты соответствующие значениям поля «concept name» столбцы, при этом из анализа были исключены показатели, по которым доля пропущенных значений более 95%. Описательные статистики выглядят следующим образом:
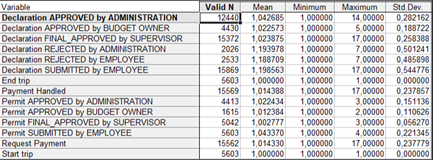
На основании таблицы можно сделать вывод, что в совокупности присутствует 5603 полных кейсов, при этом каждый из них имеет как начало, так и конец. Количество шагов Declaration APPROVED by ADMINISTRATION, Declaration FINAL_APPROVED by SUPERVISOR, Declaration SUBMITTED by EMPLOYEE, Payment Handled, Request Payment значительно превосходит количество командировок, в среднем, примерно в 3 раза. Учитывая, что данные шаги происходят после шага End trip, можно предположить, что в рамках каждой командировки расчет и оплата происходят в несколько этапов, что может увеличивать трудозатраты и говорит о неоптимальности данного процесса.
Мы провели кластерный анализ на этих данных. Для того чтобы определиться с количеством кластеров, для начала был проведен кластерный анализ с помощью метода ближайшего соседа на основе матрицы квадратов Евклидова расстояния. Метрика расстояния выбрана для придания большего веса более отдаленным друг от друга объектам. По результатам построенного дендрита было решено разбить совокупность на 5 кластеров.
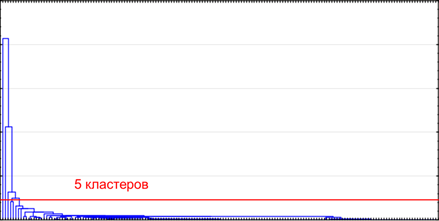
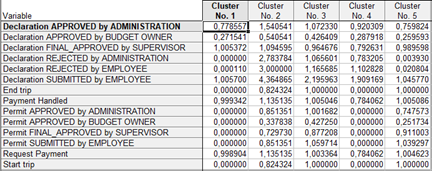
Далее с помощью метода k-means совокупность была разделена на 5 кластеров по принципу максимизации начальных расстояний между кластерами. Средние значения по кластерам:
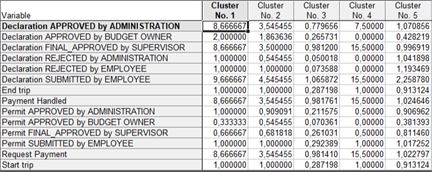
Кластеры 3 и 5 включили в себя практически всю совокупность (14255 и 1623 случаев соответственно), при этом случаи, попавшие в кластер 5 можно охарактеризовать как случаи, по которым имело место событие Declaration rejected, в отличие от кластера 3, где таких событий практически не было. Соответственно, событие Declaration rejected связано с увеличением шагов события и его длительности.
Кластеры 1, 2 и 4 можно назвать аномалиями, они содержат 3, 22 и 2 случая соответственно, при этом они характеризуется большим количеством Declaration APPROVED by ADMINISTRATION, Declaration FINAL_APPROVED by SUPERVISOR, Declaration SUBMITTED by EMPLOYEE, Payment Handled, Request Payment. Можно предположить, что именно эти события объясняют значительное превышение количества данных шагов над количеством командировок. При этом кластер 4 содержит 2 события, количество шагов по которым максимальное — travel permit 53343 и travel permit 73562. Если исключить данные аномалии из совокупности, то результаты кластерного анализа получаются следующие:
Можно обратить внимание на то, что после исключения выбросов отсутствуют явно выделяющиеся кластеры. Результаты говорят о том, что полученные на предыдущем шаге кластеры действительно являются аномалиями или выбросами в данной совокупности и требуют более детального анализа внутри организации, возможно, они содержат нарушения и показывают уязвимость/неоптимальность процесса.
Итак, мы можем видеть, что проведение кластерного анализа и без применения традиционного инструментария Process Mining тем не менее позволяет провести оценку оптимальности процесса и выявить процессные аномалии или нарушения.
Телеграм: t.me/ainewsline
Источник: newtechaudit.ru