Обучение с подкреплением (Reinforcement Learning) плохо, а точнее, совсем не работает с высокими размерностями. А также сталкивается с проблемой, что физические симуляторы довольно медленные. Поэтому в последнее время стал популярен способ обойти эти ограничения с помощью обучения отдельной нейросети, которая имитирует физический движок. Получается что-то вроде аналога воображения, в котором и происходит дальнейшее основное обучение.
Давайте посмотрим, какой прогресс достигнут в этой сфере и рассмотрим основные архитектуры.
Идея использовать нейросеть вместо физического симулятора не нова, так как простые симуляторы вроде MuJoCo или Bullet на современных CPU способны выдавать от силы 100-200 FPS (а чаще на уровне 60), а запуск нейросетевого симулятора в параллельных батчах легко выдает 2000-10000 FPS при сравнимом качестве. Правда, на небольших горизонтах в 10-100 шагов, но для обучения с подкреплением этого часто бывает достаточно.
Но что еще важнее, процесс обучения нейросети, которая должна имитировать физический движок, обычно подразумевает снижение размерности. Так как самый простой способ обучить такую нейросеть это использовать автоэнкодер, где это происходит автоматически.
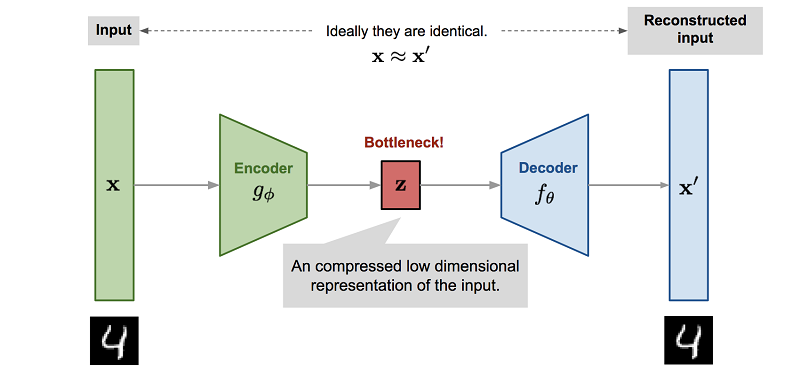
Если вы подадите в такой нейросети на вход, например, картинку с камеры. И будете требовать, чтобы на выходе она выдавала точно такую же картинку. То из-за того, что в ее центре намного меньше нейронов, она будет вынуждена сжать всю информацию, необходимую для такого восстановления, до уменьшенной размерности Z.
А уже к этой уменьшенной размерности Z можно применить любой классический алгоритм Reinforcement Learning. С маленькой размерностью он, возможно, уже будет способен справиться (ну да, ну да, надежда умирает последней). Кроме того, это также ускоряет расчеты.
Собственно, в этом и заключается весь секрет обучения в воображении — сначала создается быстрая нейросеть, имитирующая физический движок, а также уменьшающая размерность задачи. И уже на этой уменьшенной размерности работают обычные алгоритмы обучения с подкреплением. Дальнейший прогресс заключался в том, как заставить автоэнкодер сохранять в Z нужную для решения задачи информацию, как эффективнее делать планирование в model-based методах прямо в уменьшенной размерности, а не в полных данных, и тому подобное.
Причем этот подход можно применять не только для имитации физических движков, а вообще для любой задачи Reinforcement Learning. Где можно создать нейросеть для "воображения" что будет происходить дальше в этой задаче: компьютерные игры, обучение движения роботов, исследование и навигация в пространстве, и так далее.
Первой получившей широкую известность (хотя отдельные части встречались и раньше), стала появившаяся в 2018 году работа с одноименным названием World Models.
Она собрала в себя ставшие теперь классическими элементы обучения в воображении: автоэнкодер для обучения нейросети-симулятора и обучение "мозгов" в получившемся воображении, причем в уменьшенной размерности Z. Все это работало достаточно быстро и показало отличный результат (по тем временам).
В качестве автоэнкодера бесхитростно использовался классический VAE:
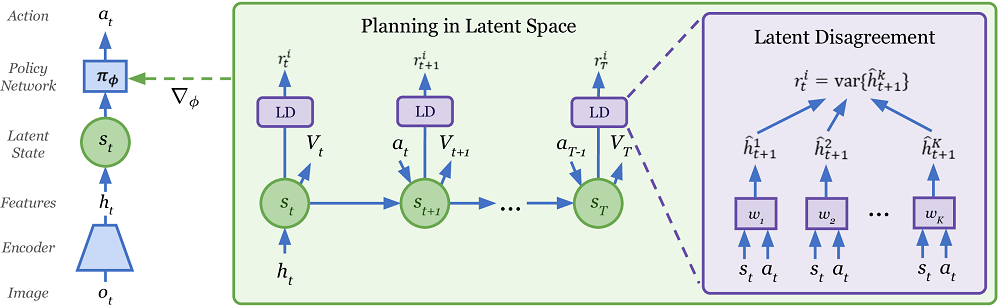
Важный нюанс, результат автоэнкодера VAE дальше пропускался через рекуррентную нейросеть (разновидность MDN-RNN), чтобы отслеживать динамику. Так как VAE работает только с одиночными статичными картинками, а для динамичных задач нужно понимать движение. Обратите внимание, что RNN предсказывает сразу сжатое представление Z для следующего шага. Это пригодится в следующих усовершенствованиях этого алгоритма.
В итоге общая схема алгоритма получилась такой:

Здесь много стрелок, но суть очень простая: VAE(V) автоэнкодер выучивает модель мира и передает свое среднее значение с уменьшенной размерностью Z в нейросеть MDN-RNN(M) для отслеживания движения. Та выдает тоже сжатое Z, но уже для следующего шага в симуляции. Это позволяет этой рекуррентной нейросети MDN-RNN делать прогноз на несколько шагов вперед, передавая свой прогноз Z себе же на вход, и так несколько раз подряд.
Ну а раз у нас есть прогноз развития ситуации на несколько шагов вперед, полученный чисто в "воображении" (выдаваемый рекуррентной нейросетью-симулятором MDN-RNN), то можно прямо по этому прогнозу обучать основную нейросеть для решения задачи. Так как строить прогнозы в воображении можно параллельно в батче размером в тысячи и даже десятки тысяч (выбирая разные значения действий из вероятностей), то это равносильно запуску десятков тысяч параллельных обычных симуляторов.
В итоге получается, что основное обучение происходит в "воображении" (см. схему) по циклу между MDN-RNN и С (Controller — основной "мозг", принимающий решения). Но если посмотрите на схему, то видно что из контроллера С, стрелка также возвращается в environment. Это значит, что время от времени обученный контроллер C взимодействует не только со своим воображением, но и с реальным симулятором. Чтобы пополнить базу автоэнкодера VAE(V).
Что за Controller ©, спросите вы? И правильно сделаете! В этой работе нейросети использовались только для создания механизма воображения, а решения принимала не отдельная нейросеть-"мозг", а именно этот Controller. Это штука, обученная на прогнозах рекуррентной нейросети обычным эволюционным алгоритмом. Точнее, более эффективной его разновидностью CMA-ES. У них это сработало, потому что уменьшенная размерность Z была настолько мала, что классический эволюционный алгоритм с ней справился. Подключать нейросети для обучения с подкреплением даже не понадобилось. Так что к нейросетевому обучению с подкреплением эта работа, ставшая родоначальником целого направления, строго говоря, отношения вообще не имеет.
Позднее они применили этот подход к еще нескольким задачам, например управлению машинкой в симуляторе, и везде он показал свою эффективность и универсальность.
Следующим значимым шагом стало появление алгоритма PlaNet. Обучение в воображении уже использовали все кому не лень (заменив, разумеется, Controller на полноценную нейросеть с настоящими алгоритмами из reinforcement learning), но PlaNet сумел применить этот подход к Model-Based обучению.
Для тех кто не знает, Model-Based RL — это когда вы в симуляторе делаете очень много случайных прогонов и выбираете самый лучший вариант. С максимальной наградой. Да, вот так все просто. Тут и обучения никакого нет, это очень древний подход, имеющий к RL отношение лишь потому, что работает в схожих условиях и выдает решение с максимальной наградой.
И лучшие усовершенствования Model-Based алгоритма до сих пор заключались в том, чтобы проверять через симулятор не абсолютно случайные действия, а например распределенные по нормальному закону, чтобы проверять в первую очередь продолжавшееся движение робота. Или динамически адаптировать вероятности под текущую динамику системы (CEM или PDDM).
И здесь нейросети-симуляторы вместо настоящего симулятора для проверки гипотез, подошли как нельзя кстати! Более быстрые, способные понимать и запоминать более сложную динамику реального мира.
Но недостатком использования нейросетевых симуляторов вместо физических движков было то, что они были вынуждены предсказывать полное состояние системы. Скажем, получая на вход картинку с камеры и выдавая ожидаемую картинку для следующего шага. Потом эту свою спрогнозированную картинку подавали себе же на вход и прогнозировали картинку для еще одного следующего шага.
К сожалению, в реальных задачах такая система быстро вырождалась. Потому что генерировать картинки сложно и дорого. А небольшие случайные отклонения в пикселях уводили все это в разнос. Горизонт планирования на основе генерации картинок (т.е. полного state, если говорить в терминах Reinforcement Learning) заключался в единицах или, в лучшем случае, паре десятков шагов вперед. Для Model-Based это мало.
PlaNet, как World Models до этого, начал генерировать воображаемые последовательности не в виде картинок, а в виде сжатого состояния Z (здесь на схеме они обозначаются как S — state).

При этом из каждого Z (простите, теперь S) с помощью декодера все еще можно, при желании, восстановить картинку. Но важно, что нейросеть-симулятор строит траектории именно в сжатом состоянии.
Это позволяет в сжатых состояниях S (все, прощай Z) сохранять только важные абстрактные вещи для решения задачи. Например, скорости объектов, их положение и так далее. А в картинках все это хранилось в шумных пикселях, из которых приходилось потом выдирать обратно.
Хранение в S только важной информации для решения задачи позволило строить прогнозы не на десяток шагов вперед, а на сотни и даже тысячи. Что резко улучшило качество Model-Based прогонов в нейросетевом симуляторе (то есть в "воображении"). Да и маленькая размерность тоже помогает.
Обратите внимание на схеме выше, что на каждом промежуточном шаге в модель, т.е. на вход нейросети-"воображения", добавляется случайное действие A. Здесь все как в обычном Model-Based — прогоняем через симулятор случайные действия и выбираем лучший вариант. Отличие в том, что каждый промежуточный state S это сжатое представление. Поэтому чтобы получить из него награду R для расчета суммарной награды, из этого скрытого state S нужно предсказать награду, что делается отдельной небольшой нейросетью (синий прямоугольник на схеме). А вот генерировать из каждого промежуточного шага картинку декодером, что очень трудоемко в вычислительном плане, при работе совсем не нужно! (это делалось только при обучении автоэнкодера). Классическое Model-Based планирование, т.е. прогон случайных действий через симулятор и выбор лучшего, делается полностью в сжатых состояниях, лишь с небольшой помощью нейросети, получающей из S награду R. Это тоже значительно ускоряет расчеты по сравнению с предыдущими подходами, которые использовали идею World Models, но для генерации целых картинок.
Как и любой Model-Based алгоритм, PlaNet требует намного меньше примеров и времени для обучения. В 50 раз или около того. При этом способность делать прогнозы в сжатом представлении, хранящем только нужную информацию для решения задачи, и прогнозируя на порядки более длинные последовательности, позволили ему добиться качества, сравнимого с Model-Free методами.

Другим общим плюсом Model-Based подходов является то, что однажды выучив модель мира (нейросеть-воображение), можно решать разные задачи без переучивания. Через симулятор персонажа можно делать прогоны случайных траекторий для задачи бега, ходьбы и вообще любых действий. Достаточно только определиться как считать награду. Впрочем, по сравнению с обычным Model-Based, в этом плане PlaNet немного проигрывает. Так как его сжатое представление ориентировано на конкретную задачу (хранит важное для решения именно ее), плюс требуется специфический декодер для каждого вида награды из сжатого представления.
Дальнейшим развитием PlaNet стала архитектура Dreamer. Являющаяся сейчас фактически последним словом в этой области.
Как и PlaNet, Dreamer делает прогнозы в сжатом состоянии S, содержащем важные для решения задачи сведения, и может делать эффективные прогнозы на тысячи шагов вперед. Но преимуществом Dreamer является использование Value нейросети, используемой для предсказания награды за пределами горизонта планирования. Эта сеть почти целиком взята из обычного Reinforcement Learning. На основе большой статистики взаимодействия со средой она учится предсказывать насколько хороша текущая ситуация. Можно ли из нее хотя бы потенциально получить в далеком будущем награду, даже если текущий горизонт планирования не показывает хорошей награды. В обычных Model-Based алгоритмах (и в предыдущем PlaNet) суммарная награда рассчитывается исключительно в пределах горизонта планирования.

Но что еще важнее, вместо прогона и проверки через симулятор случайных действий, для выбора какие действия надо проверять Dreamer использует Actor нейросеть, выдающую сразу оптимальные действия. Это очень близко к концепциям в Model-Free обучении с подкреплением, например в архитектуре actor-critic.
Но в отличие от actor-critic архитектур в Model-Free подходах, где actor учится выдавать оптимальные действия по градиенту, с которым critic предсказывает награду (или value, или advantage), в Dreamer actor нейросеть учится оптимальным действиям через обратное распространение градиента награды через всю последовательность сжатых представлений. Что невозможно для Model-Free подходов.
Это позволяет Dreamer'у понимать, как маленькие изменения действий отразятся на награде в будущем. И эффективно дообучать свою Actor нейросеть, чтобы выдаваемые ею действия вели к максимальному увеличению награды на каждом шаге (см. анимацию ниже). Совместно с Value нейросетью, заглядывающей за горизонт планирования, так как value и reward обе распространяются назад по последовательности.

По большому счету, Dreamer не является Model-Based подходом. Это скорее гибрид с Model-Free. Потому что технологию model-based с последовательностью предсказаний (в воображении, а не на реальном симуляторе) этот метод использует только для эффективного обучения Actor нейросети. А так Dreamer при работе сразу предсказывает оптимальные действия. Вместо долгого поиска, как делал PlaNet и все остальные Model-Based методы.
Благодаря этой комбинации, Dreamer обучается в 20 раз быстрее, чем другие методы, и при этом по качеству равен или превосходит лучшие Model-Free методы. Точнее, Dreamer требует в 20 раз меньше взаимодействий со средой, а по чистому времени обучения (без учета времени работы физического симулятора) примерно в два раза быстрее.

Dreamer на текущий момент один из самых лучших и быстрых методов Reinforcement Learning для длинных горизонтов планирования. Особенно он хорош для динамики движений персонажей в окружениях вроде MuJoCo, используя на входе данные высокой размерности, такие как картинки с камер.
Предыдущие методы касались только самого процесса обучения в воображении. Но в Reinforcement Learning существует также большая проблема как правильно исследовать мир, чтобы потом найти в нем оптимальные действия.
Что если можно было бы изучить мир, причем как-нибудь более эффективно, чем просто случайно блуждая по нему. А потом, когда потребуется выполнить какую-то задачу, можно было в своем воображении представить эту последовательность и обучиться чисто в воображении, не взаимодействия снова со средой. Ведь это позволило бы, после изучения мира, выполнять практически любые задачи! Работа Plan2Explore отвечает именно на эти вопросы.
Обычно исследование мира в Reinforcement Learning выполняется либо полностью случайно, либо с помощью различных внутренних мотиваций, например любопытства. Чтобы давать приоритет малоизученным областям, у которых высокая новизна для агента.
Проблемой обычных методов является то, что новизна в них оценивается ретроспективно. Когда агент уже попал в новое место. Но, во-первых, не так уж часто агент случайно оказывается в новом месте. А во-вторых, при повторном попадании в это место, из-за такой оценки оно уже утрачивает для него новизну, хотя эта область все еще плохо изучена.
Было бы неплохо оценивать перспективные с точки зрения новизны места заранее, чтобы потом двигаться туда. И, вы уже наверно догадались, Plan2Explore делает это с помощью механизма воображения, аналогичного предыдущим методам. И точно так же, использует последовательности из сжатых представлений.
Работа Plan2Explore состоит из двух частей: сначала исследуется мир, используя обучение в воображении для планирования куда двигаться. А после изучения мира, когда нужно выполнить какую-то конкретную задачу, обучение этой задаче тоже делается полностью в воображении. Используя обученную модель мира и не взаимодействуя больше со средой. Ведь все возможные типы взаимодействия были изучены в период исследования мира. Это zero-shot вариант обучения новым задачам. А если все же немного повзаимодействовать (совместно с обучением в воображении, см. как это было в World Models в самом начале статьи), то получается несколько улучшенный few-shot вариант.
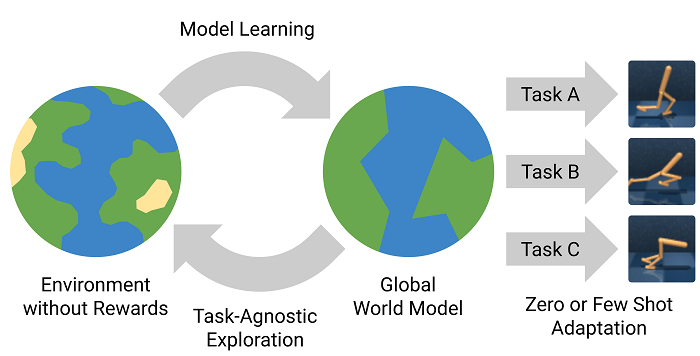
Plan2Explore показывает качество, сравнимое с Dreamer и Model-Free методами, но при этом может использовать одну обученную модель мира в период исследования, чтобы выполнять разные действия. Для этого требуется лишь минимальное и очень быстрое дообучение в воображении, не взаимодействуя с реальной средой.
Интересно, что в Plan2Explore используется необычный способ оценки новизны новых мест в период изучения мира. Для этого тренируется ансамбль моделей, обученных только на модели мира, и предсказывающих только один шаг вперед. Утверждается, что их предсказания отличаются для состояний с высокой новизной, но по мере набора данных (частого посещения этого места), их предсказания начинают согласовываться даже в случайных стохастических окружениях. Так как одношаговые предсказания в итоге сходятся к неким средним значениям в этом стохастическом окружении. Если вы ничего не поняли, то вы не одиноки. Там в статье не очень понятно это описано. Но как-то оно, похоже, работает.