Советский кибернетик Михаил Моисеевич Бонгард одним из первых разработал теорию распознавания образов.
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-09-21 17:34
распознавание образов, ИИ теория, алгоритмы машинного обучения
Математик Константин Воронцов о машинном обучении, нейронных сетях и понятии предрассудка
Известный советский кибернетик Михаил Моисеевич Бонгард одним из первых разработал теорию распознавания образов. В 1967 году вышла его книга «Проблема узнавания», и в ней были приведены сто немного искусственных, но понятных картинок, на которых можно проиллюстрировать практически все характерные особенности того, что мы сейчас называем машинным обучением.
Машинное обучение
На первой картинке изображены шесть объектов одного класса и шесть объектов другого класса. Представьте себя на месте искусственного интеллекта, которому показывают это. Вы должны выработать правило, согласно которому можете отличить объекты слева от объектов справа. Каждый из нас по очень простому примеру за считаные секунды догадается, о чем идет речь: в данном случае мы отличаем большие фигуры от маленьких.
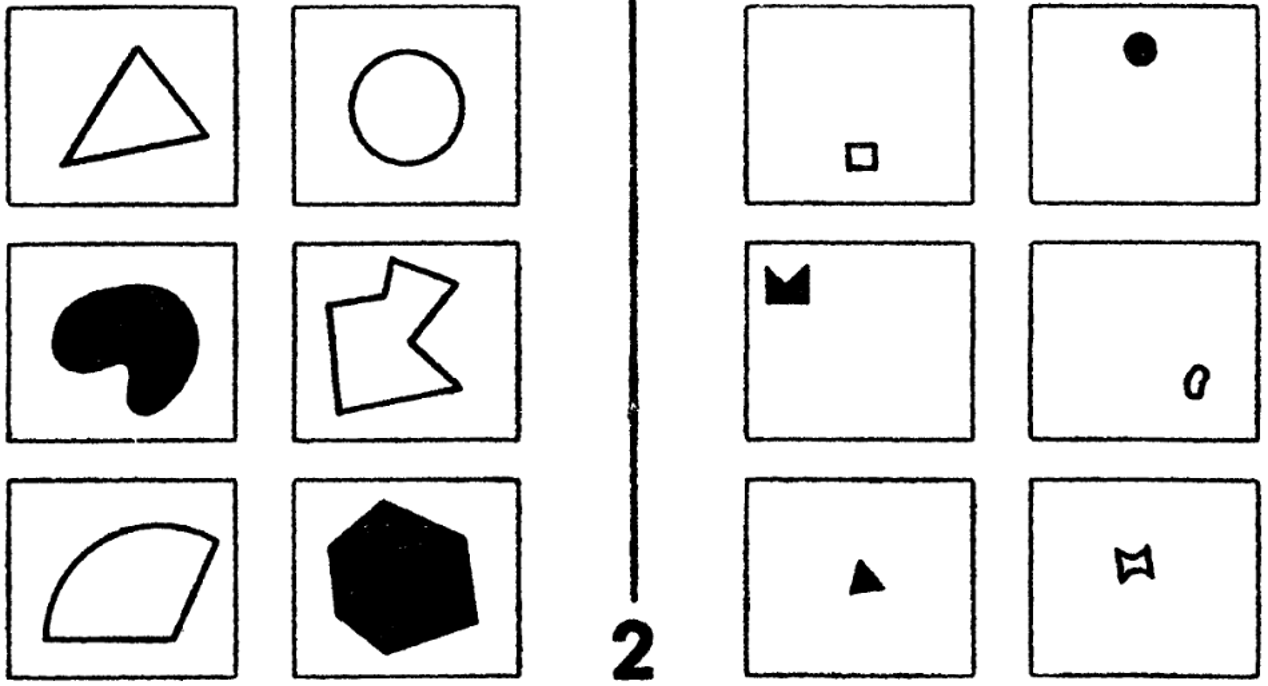
Рисунок 1
Глядя на вторую картинку, мы понимаем, что здесь различаются четырехугольники и треугольники. Почему вообще возможно автоматически отличить объекты одного класса от объектов другого класса и почему мы уверены в том, что-то правило, которое мы нашли, — о различии четырехугольников и треугольников — верное? Первое, что приходит в голову: благодаря этому правилу мы безошибочно распознаем двенадцать объектов.
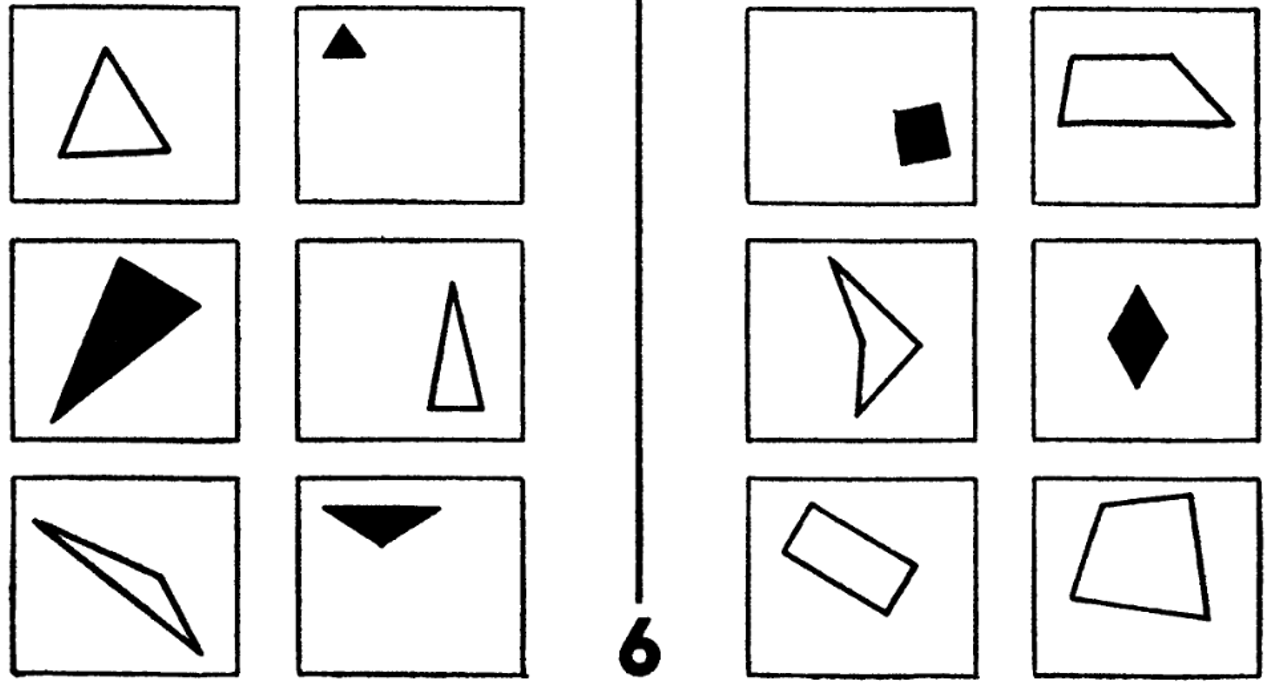
Рисунок 2
Третья картинка сложнее, не все сразу догадываются, о чем идет речь. В данном случае можно выработать следующее общее правило: фигуры слева вытянутые, а у фигур справа выпуклая оболочка имеет примерно одинаковую длину и ширину. Но здесь мы уже начинаем апеллировать к геометрическим понятиям. И опять же мы считаем, что найден правильный принцип классификации этих объектов, потому что удалось сформулировать это в виде короткого правила.
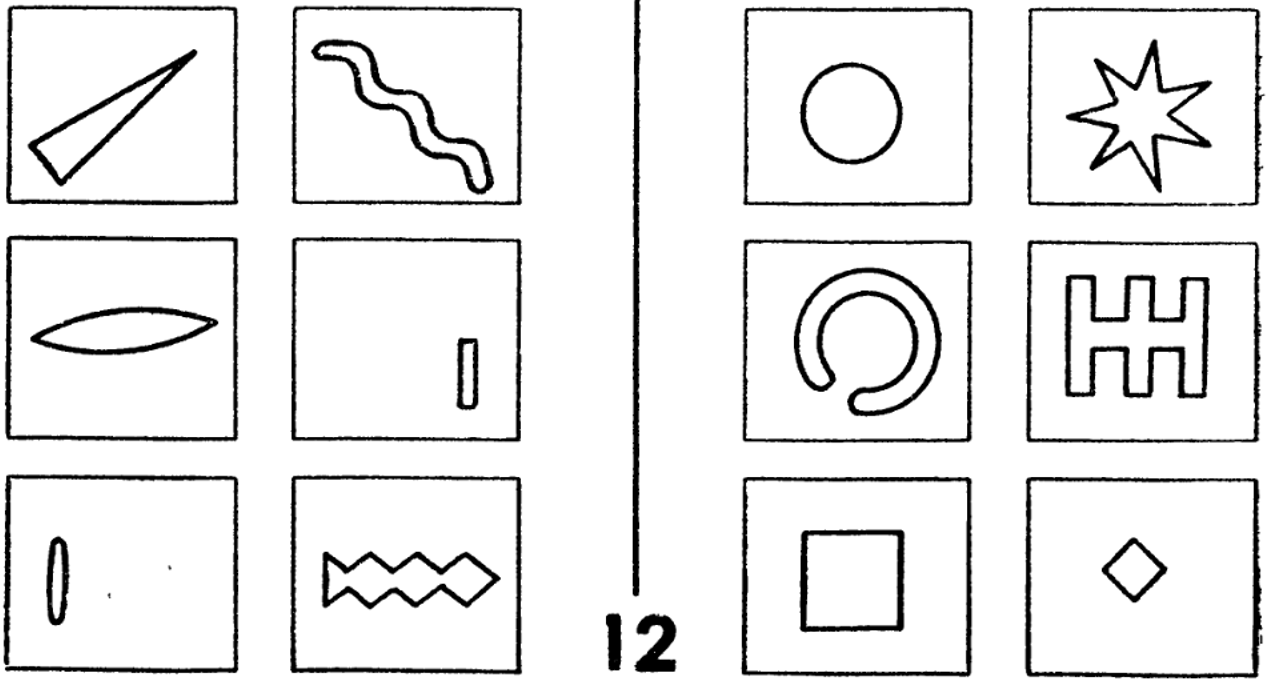
Рисунок 3
Итак, можно сформулировать общий ответ на вопрос «Почему работает машинное обучение?». Во-первых, мы совершаем мало ошибок на обучающей выборке. Во-вторых, мы выработали правило, которое, с одной стороны, достаточно простое, а с другой — объясняет всю обучающую выборку.
Работая с четвертой картинкой, мы быстро распознаем, что спирали различаются направлением закручивания. Представьте, как этот принцип классификации мог бы выработать компьютер. Сейчас мы видим битмапы, то есть фотографии картинок, чертежей, и фотография может быть размером 100 на 100 или 1000 на 1000 пикселей. Компьютерная программа должна каким-то образом обработать отсканированную картинку, а потом понять, что на ней является спиралью.

Рисунок 4
Определить направление, в котором спираль закручена, — это еще более тонкая задача. Как можно научить компьютер различать столь тонкие геометрические объекты? Придется каким-то образом закладывать в него те понятия, которые мы уже давно считаем очевидными: мы живем в трехмерном мире, где встречаются спирали, а кроме того, на уроках в школе изучали геометрические фигуры, поэтому подобные задачи мы решаем очень легко и интуитивно. Но для компьютерной программы, у которой не было уроков по геометрии, эта задача будет безумно трудной.
На пятой картинке с одной стороны больше темных фигур, а на другой — светлых, и мы это буквально за секунду интуитивно понимаем. Компьютеру будет трудно это определить: для начала ему надо объяснить, что такое геометрическая фигура — окружность, квадрат, треугольник — и что она бывает закрашенной или незакрашенной. Встает вопрос: чтобы научить компьютер решать подобные задачи, каков должен быть объем знаний в области геометрии, которые мы должны в него заложить?
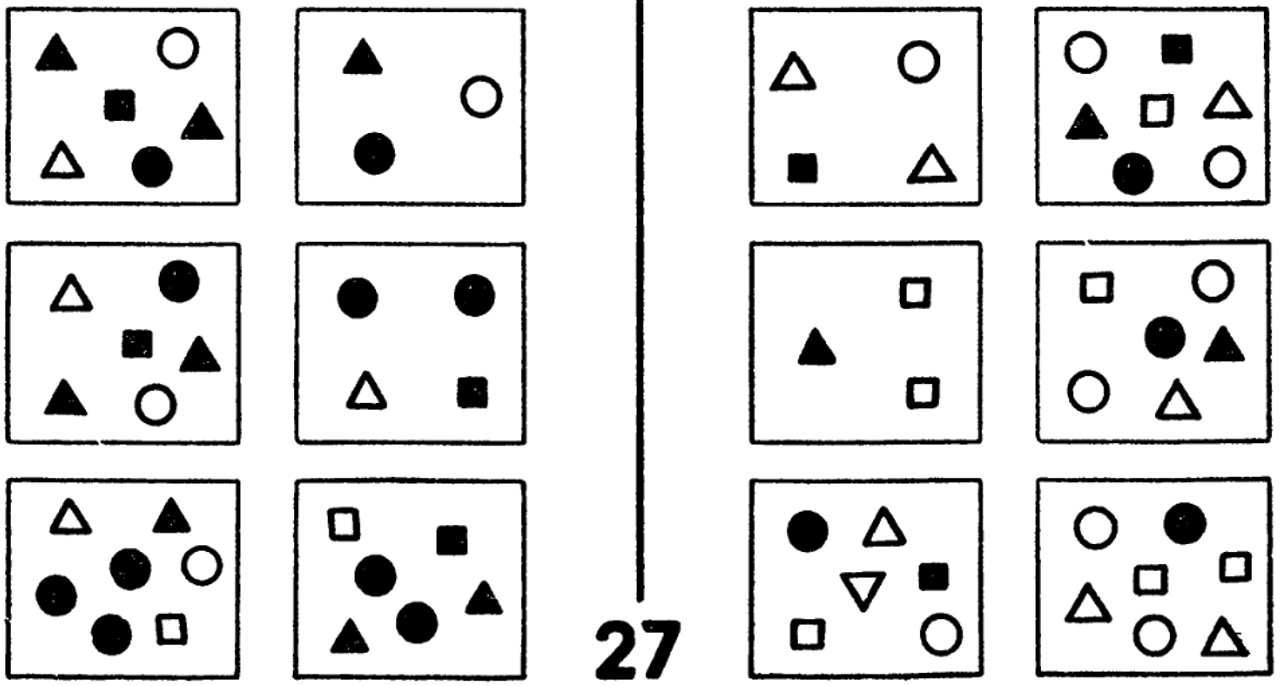
Рисунок 5
На шестой картинке задача для компьютера усложняется еще больше. Здесь необходимо заложить в него понятие непрерывной кривой: что такое точка излома, касательная и как определить, что две фигуры касаются друг друга. Это большой пласт понятий из геометрии, которые нужно вкладывать в компьютер либо как априорные знания о мире, либо с помощью большой обучающей выборки из подобных картинок, чтобы компьютер сам выработал какие-то понятия из геометрии.
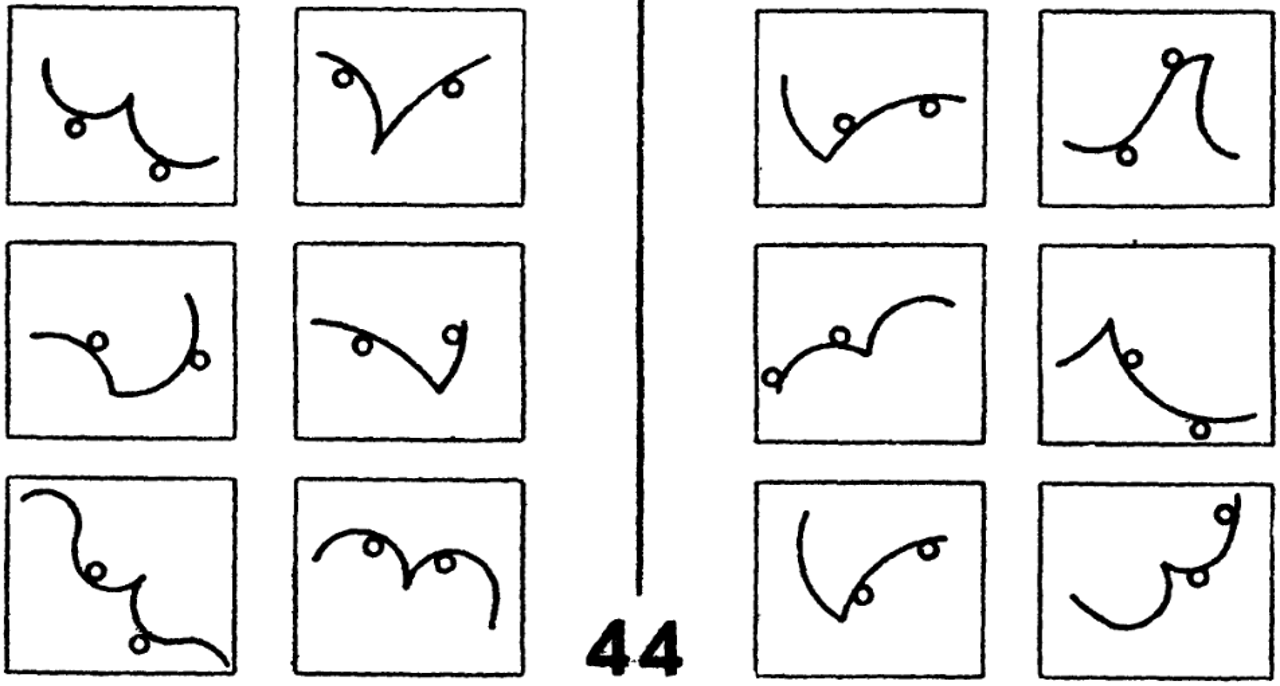
Рисунок 6
Здесь мы сталкиваемся с дилеммой, которую искусственный интеллект уже прошел: либо идем по пути развития экспертных систем и систем, основанных на непосредственном вкладывании знаний экспертов в компьютерную программу, либо накапливаем огромные объемы обучающих выборок и заставляем компьютерную программу саму выработать все необходимые понятия для решения задачи. Во втором случае необходимо подать на вход компьютеру не один миллион подобных тестов Бонгарда — тогда можно надеяться, что компьютер научится с легкостью решать такие задачи.
Понятие предрассудка
Бонгард ввел также понятие предрассудка — сегодня мы называем это переобучением. По обучающей выборке мы видим какое-то правило и задаемся вопросом: не ошиблись ли мы? В повседневной жизни это явление постоянно нам встречается. Люди наблюдают происходящее вокруг, но могут делать неправильные выводы: либо не хватило количества прецедентов, либо слишком разнообразно множество моделей, которые можно построить, или решений, которые можно принять. Человек имеет дело с небольшим количеством примеров, под которые вроде бы подходит то или иное объяснение, но оно оказывается ошибочным, то есть предрассудком.
Седьмая картинка иллюстрирует еще одну возможную ситуацию. Здесь рисунок Бонгарда специально покрашен в черный цвет, чтобы стало видно, что эту выборку могут объяснить два правила. Бонгард всегда старался, чтобы правило было одно-единственное, но в этом случае нам сложно выбрать что-то одно: мы понимаем, что две выборки различаются тем, что одна симметрична, а другая нет, но эти же выборки различаются и тем, что одна черная, а другая белая. Какое правило предпочесть? С подобной ситуацией постоянно сталкиваются методы машинного обучения: всегда приходится выбирать модель из огромного количества возможных вариантов, при этом выбор приходится делать в условиях ограниченной информации, конечной обучающей выборки. Как сделать этот выбор надежным — это тоже фундаментальная проблема, которая стоит перед машинным обучением.

Рисунок 7
Глядя на следующую картинку, мы понимаем, что здесь действует простое правило: ягодка находится либо на центральной ветви дерева, либо на боковой. Но для того, чтобы компьютер смог решить эту задачу, мы должны заложить в него и основы теории графов, и понятие непрерывной кривой ветки, а также что значит, когда ягодка или кружочек находится на кончике ветки. Мы снова сталкиваемся с необходимостью каким-то образом закладывать в компьютер знания.
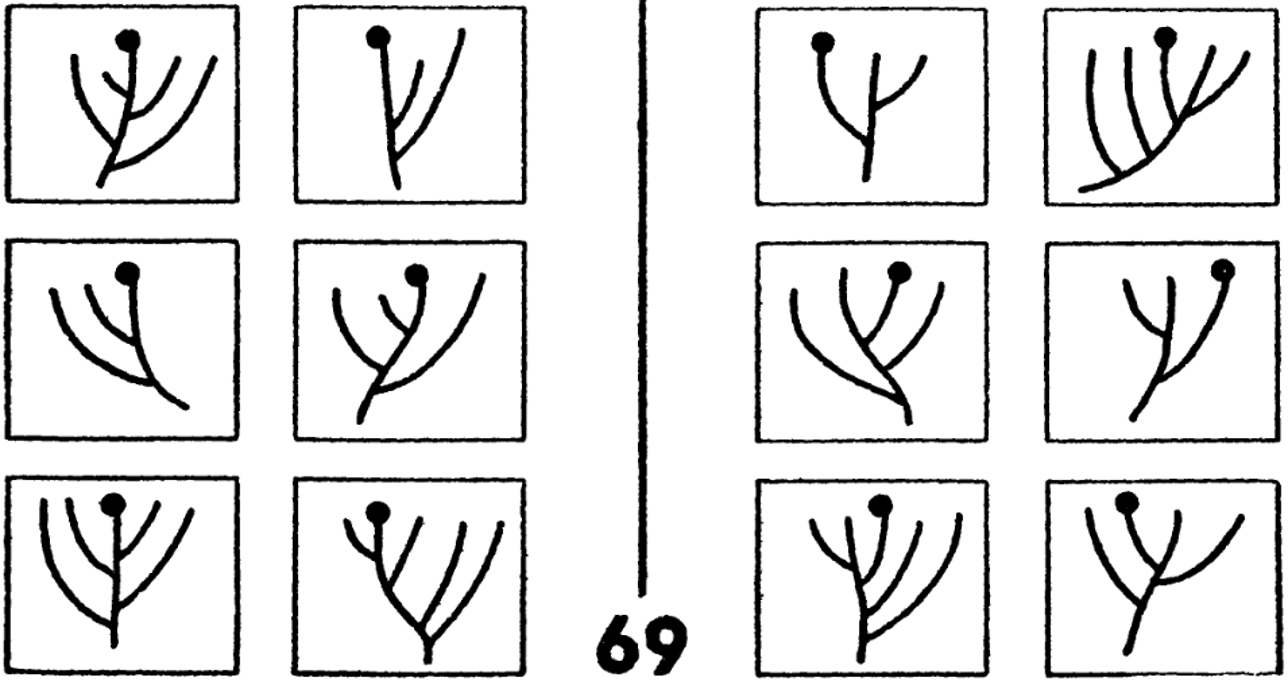
Рисунок 8
Что самое удивительное, проблемы предварительной обработки сложно устроенного объекта, такого как изображение, а также вопросы переобучения (предрассудков) и достаточности объема обучающей выборки обсуждались в книге Бонгарда, которая была написана в 1967 году, и до сих пор эти проблемы остаются основополагающими в теории машинного обучения.
Телеграм: t.me/ainewsline
Источник: postnauka.ru