WebDataset: библиотека для работы с большими датасетами
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-08-21 18:21

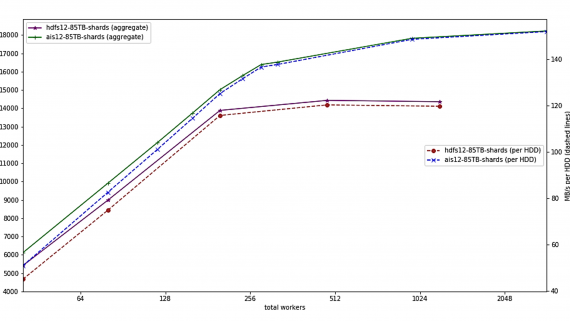
WebDataset — это открытая библиотека для PyTorch, которая упрощает работу с крупными датасетами для машинного обучения. В WebDataset датасет представляется в формате POSIX tar архивов. Библиотека напрямую использует эти архивы для обучения модели. При этом архив не нужно распаковывать или хранить локально. WebDataset позволяет масштабировать код для локального обучения на обучение с использованием сотен GPU.
Описание проблемы
Многие датасеты для исследования состоят из миллионов объектов или весят несколько сотен терабайтов. Это затрудняет обработку данных и обучение моделей, потому что требует значительные ресурсы для хранения и эффективного вычисления. Потенциальные сложности, которые провоцирует работа с большими датасетами, включают в себя:
- Размер датасета: часто данные не помещаются на локальный диск и требуют использование систем распределенного хранения;
- Количество файлов: датасеты могут состоять из миллиардов файлов;
- Обработка данных может требовать использование систем параллельного вычисления;
- Шафлинг и аугментация данных перед обучением;
- Масштабируемость: пользователи часто хотят обучать и тестировать модель на маленьких датасетах, а затем генерализовать модель на датасеты больших размеров
Традиционные локальные и сетевые файловые системы не разрабатывались для таких применений. WebDataset библиотека для PyTorch позволяет обойти вышеупомянутые ограничения.
Подробнее про библиотеку
На данный момент WebDataset доступна как отдельная библиотека в репозитории на GitHub. Однако разработчики планируют внедрить библиотеку в PyTorch. Имплементация библиотеки занимает 1500 строк кода и не имеет внешних зависимостей.
Вместо изобретения нового формата в библиотеке используется формат POSIX tar архивов, которые состоят из оригинальных файлов с данными. WebDataset использует IterableDataset интерфейс PyTorch. Данные могут подгружаться с помощью DataLoader.
Телеграм: t.me/ainewsline
Источник: neurohive.io