Нейросеть редактирует изображение по текстовому описанию
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-08-03 18:24

Исследователи из ETH Zurich разработали нейросеть, которая позволяет контролировать генерируемое изображение с помощью высокоуровневых атрибутов и текстовых описаний. На вход модели можно подать маску сегментации объектов с их классами. Нейросеть выдаст аналогичное по структуре изображение. Кроме того, можно редактировать содержание изображения с помощью текстовых запросов. В список возможных действий входят перемещение, удаление или добавление объектов. Модель выучивается разделять передний и задний планы изображения.

Динамическая генерация изображений по описанию, поиск игровых мод getmod.app
Проблема существующих моделей
Предыдущие подходы имеют три ограничения:
- При удалении объекта фон заполняется с артефактами;
- В реальных задачах часто нет доступа к размеченным маскам сегментации всех объектов на изображении
Предложенная модель обходит эти ограничения. Для генерации изображения используется разреженные сегментационная маска и карта объектов.
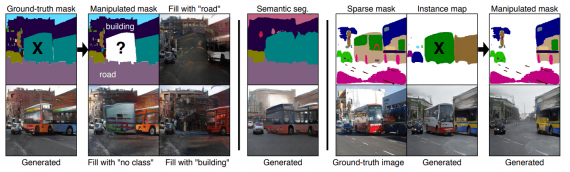
Визуализация ограничений текущих подходов
Архитектура модели
Итоговая модель состоит из двух объединенных генераторов. Исследователи называют подход двухступенчатым. Первый генератор отвечает за генерацию заднего фона изображения. Второй генератор синтезирует передний план изображения, учитывая при этом результат первого генератора.
В качестве базы модели используется SPADE, для модулей условий. Предобученную VGG используют в генераторе.
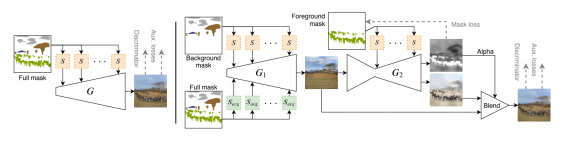 Слева: базовая одноступенчатая версия модели; справа: полная двухступенчатая версия модели
Слева: базовая одноступенчатая версия модели; справа: полная двухступенчатая версия модели
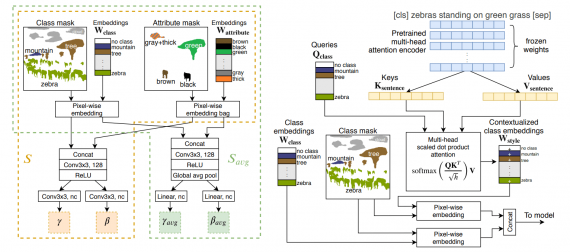 Слева: модуль для условий на основе атрибутов; справа: механизм внимания для редактирования по тексту
Слева: модуль для условий на основе атрибутов; справа: механизм внимания для редактирования по тексту
Оценка работы модели
Исследователи сравнили двухступенчатую модель с базовой одноступенчатой. Для сравнения модели предобучали на разных датасетах: COCO2017, Visual Genome (VG), Visual Genome augmented (VG+).
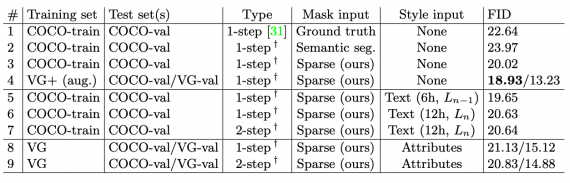 Сравнение FID для базовой (1-step) и итоговой моделей (2-step), обученных на разных датасетах. Датасет для тестирования — валидационный сет COCO-Stuff
Сравнение FID для базовой (1-step) и итоговой моделей (2-step), обученных на разных датасетах. Датасет для тестирования — валидационный сет COCO-Stuff
Телеграм: t.me/ainewsline
Источник: neurohive.io