DeText: фреймворк для ранжирования документов с помощью BERT
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-08-14 20:12
DeText — это фреймворк для обучения моделей обработки естественного языка. DeText позволяет решать задачи ранжирования, классификации и генерации с помощью state-of-the-art нейросетевых архитектур.
Функционал библиотеки
Среди функционала библиотеки:
- Автоматическое извлечение признаков из текста с помощью нейросетей;
- End-to-end обучение;
- Набор функций потерь;
- Конфигурируемая архитектура сети: возможность задавать размер и количество слоёв и тюнить гиперпараметры;
- Гибкий фреймворк, позволяющий кастомизировать пайплайн обучения и модели под своё приложение
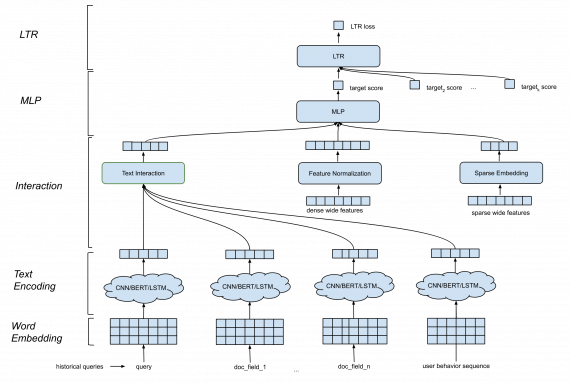
Структура фреймворка
Фреймворк DeText состоит из следующих компонентов:
- Слой эмбеддинга слов. На этом этапе последовательность слов конвертируется в последовательность N-мерных векторов;
- /BERT/ для слоя кодирования текста. Этот слой принимает на вход матрицу эмбеддингов слов и соотносит текстовые данные с эмбеддингами фиксированного размера;
- Слой взаимодействия, в котором на основе эмбеддингов текстов генерируются признаки. Для этого слоя доступно несколько опций: конкатенация, косинусное расстояние и т.п.;
- Обработка признаков;
- Многослойный перцептрон
Модель обучается end-to-end, и ее параметры совместно обновляются так, что бы максимизировать вероятность клика на документ.
Телеграм: t.me/ainewsline
Источник: neurohive.io