Чем питался Иоанн Креститель: анализ расхождений в Новом Завете
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-08-09 18:30

Для того чтобы интерпретировать любой текст, необходимо установить его оригинальную формулировку. К текстологии Нового Завета ученые сравнили различные рукописные варианты по несовпадениям отдельных слов, вычисляя расстояние Левенштейна. Этот метод позволяет установить, что комбинация одних букв перепутана с комбинацией других, и выяснить, какая из формулировок скорее всего была первоначальной.
Впоследствии результаты переводятся в евклидово пространство с использованием классического многомерного масштабирования, которое обеспечивает нужное представление данных для пространственного анализа. Так расстояния между текстами оказываются вычислимы в буквальном (географическом) смысле. В этом исследовании авторы даже применили геоинформационную систему для визуализации результатов.
Ошибки писцов при переписывании рукописей
Первые основные части Новозаветных текстов датируются третьим и четвертым веками нашей эры. Хотя тексты передавались из поколения в поколение с большой осторожностью, между разными рукописями неизбежно появляются различия.
Можно предположить, что ошибки при переводе текстов возникали во время чтения (или слушания), запоминания и написания содержимого оригинальной рукописи. Кроме того, они могли быть допущены из-за плохого зрения, путаницы в письмах, небрежного почерка, неправильного толкования и сокращений. Так возникали варианты текстов с различиями в пунктуации и орфографии, измененными словами и даже с пропущенными абзацами. А еще переписчики иногда намеренно изменяли содержание одного и того же текста по своим догматическим убеждениям.
Чем занимается текстология
Текстология как наука разрабатывает методы для систематической оценки древних текстов. Помимо выявленных различий, существуют тексты, рукописные варианты которых схожи, однако содержание озадачивает исследователей. В этом случае некоторые ученые строят предположения об искажении текста и вносят в него поправки. Учитывая существование разных текстовых вариантов и отсутствие комментариев, целью текстологии является восстановление оригинального текста из имеющихся рукописей.
Традиционно текстология занималась изучением существующих текстовых вариантов Нового Завета, которые известны из рукописей, словарей и лекций; однако сейчас она расширила сферу деятельности, чтобы получить представление об истории передачи текстов и, следовательно, об убеждениях и руководящих принципах переписывающих сообществ.
Как выбрать правильный вариант?
Иногда выбрать корректный текст между существующими вариантами не так просто. Ученые сталкиваются с такими трудностями, как логические противоречия и несоответствия в тексте, и поэтому не берутся утверждать, что среди существующих вариантов сохранился оригинальный. В таком случае единственный оставшийся выход — предположить, каким должно было быть первоначальное прочтение. Эти так называемые гипотетические поправки (умозрительные изменения текстов, для которых не существует никаких рукописных доказательств) также становятся объектом интереса для текстологии.
Откуда брать данные?
Важным инструментом критического изучения гипотез является Амстердамская база данных гипотетической поправки к Новому Завету (ADNTCE). Эта база содержит приблизительно 6500 предположений о правках для текстов Нового Завета, собранных из комментариев богословской литературы. Сюда также включены данные по обсуждению конкретных гипотез.
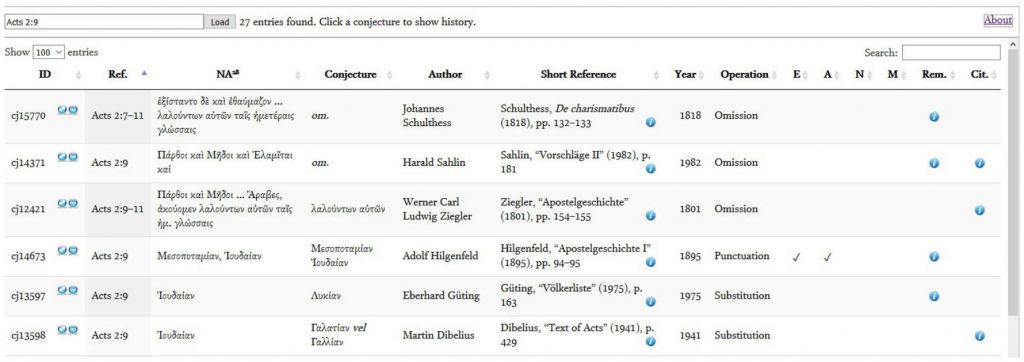
В базе зафиксирован только сам факт поправки, но нет информации о ее происхождении. Появилась ли поправка из-за опечатки или кто-то внес изменения в текст из-за своих убеждений? Исследователи решили оценить каждую поправку количественно.
Сопоставление строк и вычисление расстояний
Исследователи предложили метод оценки вероятности палеографической [1] (т.е. исторической) путаницы для объяснения происхождения предположительных поправок. Метод состоит в том, что исследователи сравнивают варианты путаницы, используя метрику, которая основана на расстоянии Левенштейна.
Расстояние Левенштейна (редакционное расстояние, дистанция редактирования) — метрика, измеряющая различие между двумя последовательностями символов. Расстояние определяется как минимальное количество односимвольных операций (замена, вставка и удаление символа), нужное для того, чтобы из одной последовательности получить другую.

Исследователи усовершенствовали исходный алгоритм Левенштейна в двух направлениях. Во-первых, учитывалась вероятность спутать буквы, похожие друг на друга внешне. Оценка вероятности основана на опыте текстологии при работе с рукописями. Исследователи пользовались готовой таблицей, фрагмент которой мы приводим ниже:

«s» (substitution/замена) в последней колонке значит, что автор варианта Нового завета перепутал две похожие буквы и заменил одну другой. При подсчете расстояния стоимость такой операции учитывалась как 1/p, где p — значение вероятности из таблицы.
Во-вторых, усовершенствованный алгоритм учитывает три дополнительные операции: «сжатие» (contraction), «разрыв» (explosion) и сложная замена (complex substitution).
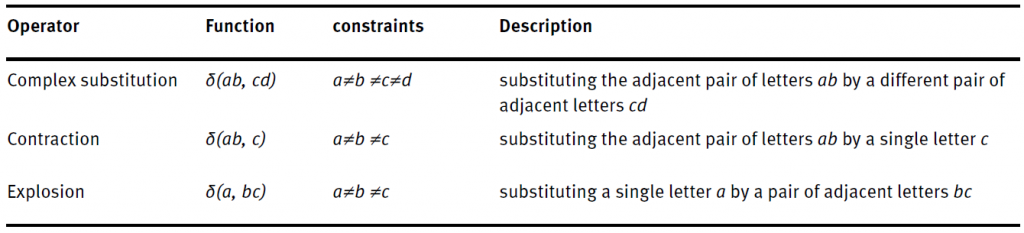
Полученная метрика показывает близость в орфографии альтернативных чтений. То есть, если расстояние между одним вариантом чтения и предположительным оригиналом маленькое, то схожесть высокая. Чем больше вариант похож на оригинал, тем выше вероятность, что переписчик просто ошибся, а не внес в текст намеренную правку.
Чем питался Иоанн Креститель? Пример использования метода пространственного анализа
Исследователи применили свой метод, чтобы проанализировать разные варианты описания пищи Иоанна Крестителя. В качестве замены «саранчи» и «дикого меда» (??????? ??? ????) в рационе Иоанна Крестителя были предложены несколько гипотетических вариантов: кокосы и дикий мед (??????? ??? ????), пирог и дикий мед (?????????? ????), креветки и дикий мед (??????? ??? ????), дикие груши и дикий мед (??????? ??? ????), зерно и дикий мед (????????? ??? ????), а также корень и фрукты (????? ????).Затем было вычислено расстояние Левенштейна от каждого варианта до каждого, результаты можно представить в виде таблицы:
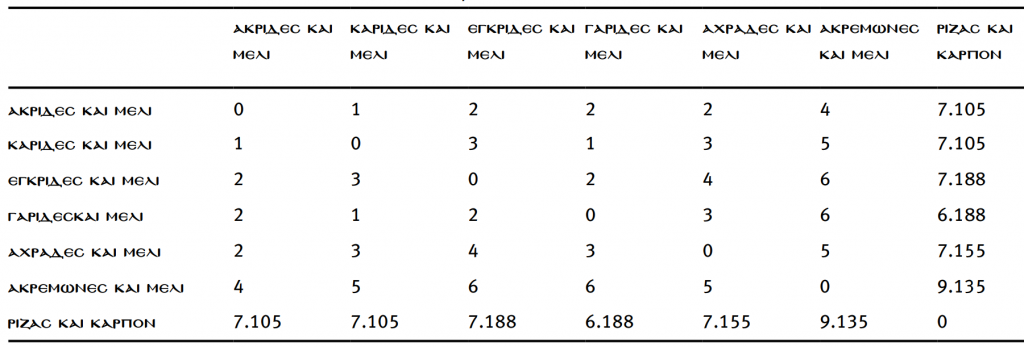
Например, мы можем понять, какой вариант наиболее близок к ??????? (саранча), это ??????? (кокосовые орехи); но здесь также возникает ряд предположений. Например, нужно ли проводить прямую связь между ??????? и ???????? Точно так же, можно предположить, что ??????? (креветки) должны были быть оригиналом, который сначала был превращен в ??????? (кокосовые орехи), который в свою очередь обратился в ??????? (саранчу). Другие варианты настолько не похожи на оригинал, что, скорее всего, здесь могли иметь место более серьезные ошибки писцов, чем описки.
При помощи многомерного масштабирования [2] мы можем отобразить взаимное расположение вариантов на плоскости. Визуализация поддерживает рассуждения, которые мы привели выше.
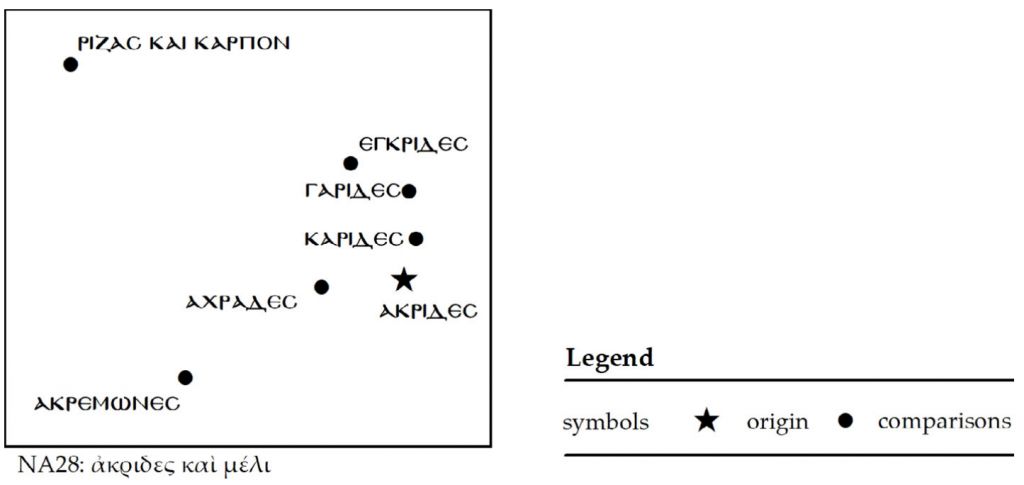
Можно одновременно визуализировать все расстояния для каждого варианта (т. е. одновременно визуализировать все строки или столбцы таблицы).
Для этого исследователи применили инструмент Natural Neighbor в ArcGIS 10.5, который раскрашивает плоскость на основе взвешенных расстояний от определенного варианта до всех остальных. В зеленую область попадают варианты, наиболее похожие на рассматриваемый, а в красную — совсем непохожие. Исследователи повторили это 7 раз по числу вариантов:
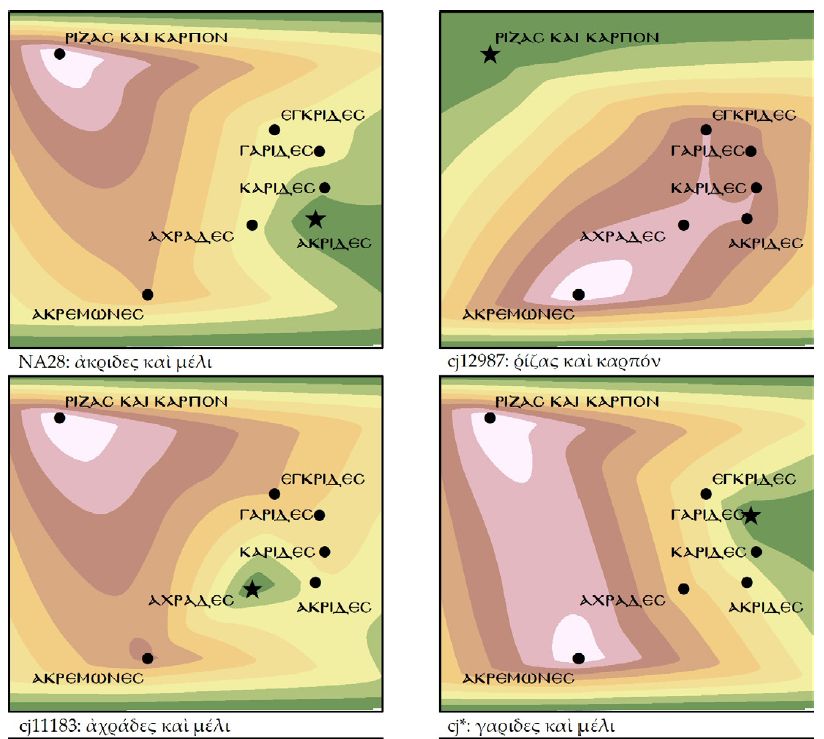
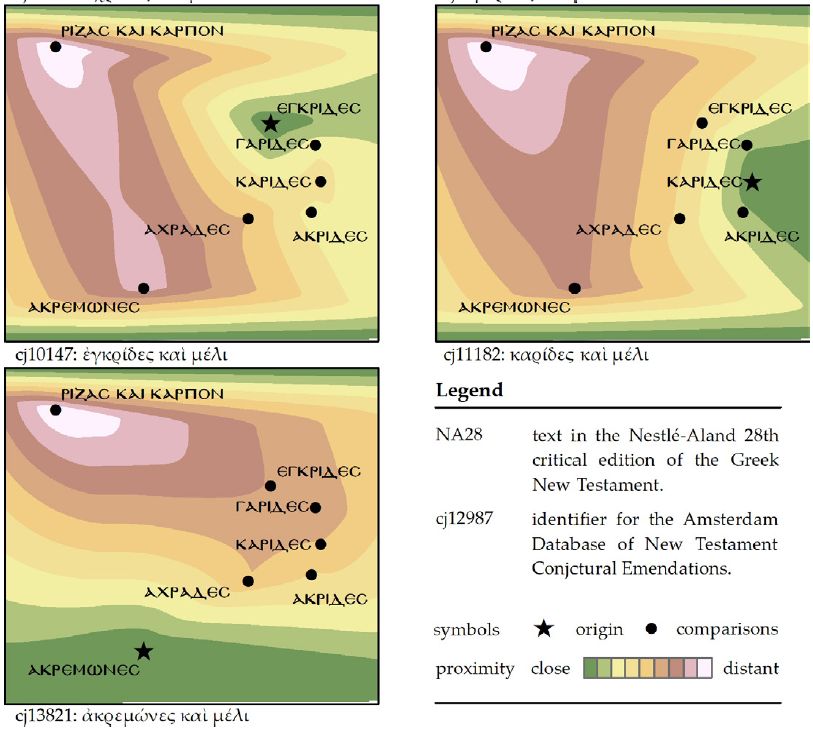
На рисунках можно наблюдать следующее:
Палеографическое смешение ????? ??? ?????? (корень и плод) с любым из других гипотетических вариантов маловероятно. Этот вариант всегда находится вдали от других (в левом верхнем углу плоскости) и попадает в зеленую область только с самим собой.
Аналогичный вывод можно сделать для ????????? (зерна, ниже всех на плоскости), но следует отметить, что вариант ????? ??? ?????? (корень и плод) все равно более удален от других. Судя по всему, эти варианты с наибольшей вероятностью не являются первоначальными, а появились из-за вольности конкретного писца.
Полученные данные необходимо интерпретировать с осторожностью (так как результаты многомерного масштабирования остаются приблизительными). Правдивость конкретной гипотезы доказать, принимая во внимание другие соображения и аргументы, такие как учет семантики, грамматики, фонетики и даже географии региона.
Источники
- The Amsterdam Database of New Testament Conjectural Emendation
- Vincent van Altena et. al. Spatial Analysis of New Testament Textual Emendations Utilizing Confusion Distances
Примечания:
[1] Палеография – вспомогательная историческая дисциплина (специальная историко-филологическая дисциплина), изучающая историю письма, закономерности развития его графических форм, а также памятники древней письменности в целях их прочтения, определения автора, времени и места создания.
[2] Многомерноемасштабирование (MM)– метод анализа и визуализации данных с помощью расположения точек, соответствующих изучаемым объектам, в пространстве меньшей размерности чем пространство признаков объектов. Целью ММ является обнаружение структуры в наборе значений некоторой меры расстояния между объектами.
Камила Абдукаримова
Телеграм: t.me/ainewsline
Источник: sysblok.ru