Техника незаметного искажения фотографий для нарушения работы систем распознавания лиц
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-07-23 13:55
слежка за людьми, кибербезопасность, алгоритмы машинного обучения
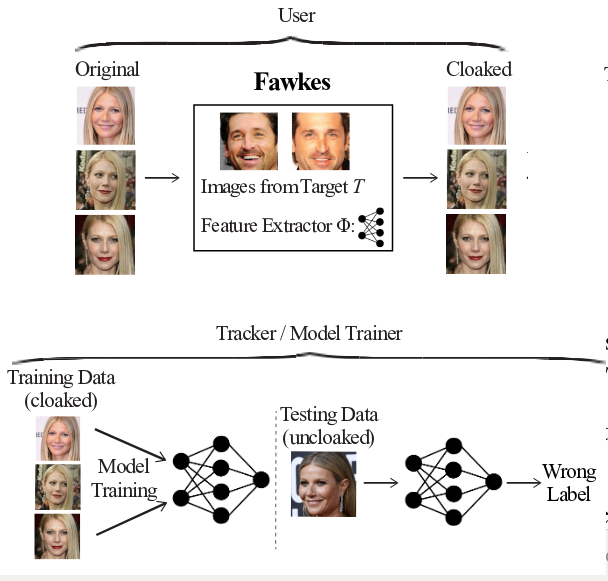
Исследователи из лаборатории SAND при Чикагском университете разработали инструментарий Fawkes с реализацией метода искажения фотографий, препятствующего их использованию для обучения систем распознавания лиц и идентификации пользователей. В изображение вносятся пиксельные изменения, которые незаметны при просмотре людьми, но приводят к формированию некорректных моделей при использовании для тренировки систем машинного обучения. Код инструментария написан на языке Python и опубликован под лицензией BSD. Сборки подготовлены для Linux, macOS и Windows.

Обработка фотографий предложенной утилитой перед публикацией в социальных сетях и других публичных площадках позволяет защитить пользователя от использования данных фотографий в качестве источника для обучения систем распознавания лиц. Предложенный алгоритм предоставляет защиту от 95% попыток распознавания лиц (для API распознавания Microsoft Azure, Amazon Rekognition и Face++ эффективность защиты составляет 100%). Более того, даже если в будущем оригинальные, необработанные утилитой, фотографии будут использованы в модели, при обучении которой уже применялись искажённые варианты фотографий, уровень сбоев при распознавании сохраняется и составляет не менее 80%.
Метод основывается на феномене "состязательных примеров", суть которого в том, что несущественные изменения входных данных могут привести к кардинальным изменениям логики классификации. В настоящее время феномен "состязательных примеров" является одной из главных нерешённых проблем в системах машинного обучения. В будущем ожидается появление систем машинного обучения нового поколения, лишённых рассматриваемого недостатка, но эти системы потребуют значительных изменений в архитектуре и подходе к построению моделей.
Обработка фотографий сводится к добавлению в изображение комбинации пикселей (кластеров), которые воспринимаются алгоритмами глубинного машинного обучения как характерные для изображаемого объекта шаблоны и приводят к искажению признаков, применяемых для классификации. Подобные изменения не выделяются из общего набора и их чрезвычайно трудно обнаружить и удалить. Даже имея оригинальное и модифицированное изображения, проблематично определить, где оригинал, а где изменённая версия.
Вносимые искажения демонстрируют высокую стойкость против создания контрмер, нацеленных на выявления фотографий, нарушающих корректное построения моделей машинного обучения. В том числе не эффективны методы на основе размытия, добавления шумов или наложения фильтров на изображение для подавления пиксельных комбинаций. Проблема в том, что при наложении фильтров точность классификации падает значительно быстрее, чем определимость пиксельных шаблонов, и на том уровне, когда искажения будут подавлены, уровень распознавания уже нельзя считать приемлемым.
Отмечается, что как и большинство других технологий для защиты конфиденциальности, предложенная техника может использоваться не только для борьбы с неавторизированным использованием публичных изображений в системах распознавания, но и как инструмент для скрытия злоумышленников. Исследователи полагают, что проблемы с распознаванием в основном могут коснуться сторонних сервисов, бесконтрольно и без разрешения собирающих информацию для обучения своих моделей (например, сервис Clearview.ai предлагает БД распознавания лиц, построенную на индексации около 3 миллиардов фотографий из социальных сетей). Если сейчас в коллекциях подобных сервисов находятся преимущественно достоверные изображения, то при активном использовании Fawkes, со временем, набор искажённых фотографий окажется больше и модель будет считать их более приоритетными для классификации. На системы распознавания спецслужб, модели которых строятся на основе достоверных источников, опубликованный инструментарий повлияет в меньшей степени.
Из близких по назначению практических разработок можно отметить проект Camera Adversaria, развивающий мобильное приложение для добавления на изображения шума Перлина, мешающего корректной классификации системами машинного обучения. Код Camera Adversaria доступен на GitHub под лицензией EPL. Другой проект Invisibility cloak нацелен на блокирование распознавания камерами наблюдения через создание специальных узорчатых плащей, футболок, свитеров, накидок, плакатов или шляп.
Телеграм: t.me/ainewsline
Источник: www.opennet.ru