Робот в лабиринте: обрабатываем в Python очереди с приоритетом
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-07-08 12:01

Данная статья является переводом публикации одного из разработчиков Twisted Моше ЗадкаThe Python heapq Module: Using Heaps and Priority Queues. Текст также адаптирован в виде блокнота Jupyter, с которым можно поиграть в интерактивном режиме в Colab.
***
Кучи и очереди с приоритетом– не самые популярные, но удивительно полезные структуры данных. Для многих проблем, связанных с поиском лучшего элемента в наборе данных, они предлагают простое в использовании высокоэффективное решение. Например, очередь с приоритетом – это мощный инструмент, помогающий решать такие задачи, как создание планировщика заданий, поиск кратчайшего пути или объединение логов. Реализующий соответствующие структуры данных модуль Python heapqявляется частью стандартной библиотеки.
Из этого туториала вы узнаете:
- Что такое кучи и очереди с приоритетом и как они связаны.
- Какие виды задач можно решить с помощью очереди с приоритетом.
- Как использовать модуль heapq.
Кому будет полезен материал: питонистам, уже хорошо знакомым со стандартными структурами данных и готовых познакомиться с более специализированными решениями.
Что такое кучи?
Очереди с приоритетом относятся касбтрактным типам данных, а кучи – к конкретным. Абстрактная структура данных определяет интерфейс, а конкретная структура данных – реализацию.
Конкретные структуры данных также определяют производительность, взаимосвязь между размером структуры и временем выполнения операций. Понимание этих гарантий позволяет предсказать, сколько времени займет программа при изменении размера входных данных.
Абстрактные структуры данных определяют операции и отношения между ними. Например, очередь с приоритетами поддерживает три операции:
is_emptyпроверяет, пуста ли очередь;add_elementдобавляет в очередь элемент;pop_elementвыталкивает элемент с наивысшим приоритетом.
После завершения задачи ее приоритет понижается и она возвращается в очередь. Приоритет очереди определяется соглашением. Самый высокий приоритет может иметь, к примеру, наибольший или наименьший элемент. Модуль Pythonheapqиспользует наиболее распространенное соглашение, согласно которому самый маленький элемент имеет самый высокий приоритет. Может звучать удивительно, но в реальных примерах, которые вы увидите позже, это соглашение существенно упрощает код.
Примечание. Модульheapqи структура данных кучи не предназначены для обычного поиска элементов. В таком деле больше пригодится двоичное дерево поиска. Соответствующие инструменты описаны в публикации Бартоша Зачински Как сделать бинарный поиск на Python(англ.).
Реализация кучи гарантирует, что операции добавления и удаления элементов имеют логарифмическую временную сложность. То есть время, необходимое для выполненияpushиpop, пропорционально логарифму по основанию 2 от числа элементов.
Логарифмические функции растут медленно. Двоичный логарифм из десяти составляет 3.3, а из миллиарда 29.9. Это означает, что если алгоритм достаточно быстр для десяти элементов, он будет лишь в десять раз медленнее для миллиарда элементов.
Однако при любом обсуждении производительности абстрактные соображения менее значимы, чем замеры времени выполнения на конкретной программе. Гарантии производительности важны для прогнозирования поведения программы, но должны быть подтверждены.
Примечание.О различных библиотеках работы со временем и интервалами времени в Python читайте в нашей публикации«Назад в будущее: практическое руководство по путешествию во времени с Python».
Реализация структуры данных
Куча реализует очередь с приоритетом в виде полного двоичного дерева. В двоичном дереве каждый узел имеет не более двух дочерних элементов. В полном бинарном дереве все уровни, кроме, возможно, самого глубокого, всегда заполнены. На одном уровне узлы заполняются слева направо. Свойство полноты означает, что глубина дерева – это двоичный логарифм числа элементов, округленный в большую сторону. Пример полного двоичного дерева:
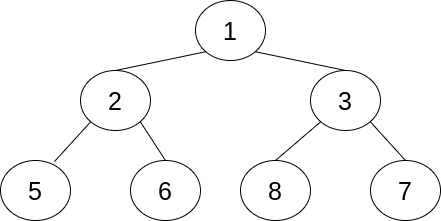
В этом частном примере заполнены все уровни. Каждый узел, кроме самых глубоких (нижних), имеет ровно по два потомка. Всего на трёх уровнях имеется 7 узлов. Единственный узел базового уровня называетсяroot. Гарантии производительности в куче зависят от того, как элементы перемещаются вверх и вниз по дереву. Число сравнений в куче является двоичным логарифмом от размера дерева.
Примечание
При сравнении объектов обычно вызываются пользовательские методы.__ lt __ (). Вызов пользовательских методов в Python является относительно медленной операцией по сравнению с другими операциями, выполняемыми в куче, так что это узкое место.
В дереве кучи значение, хранящееся в узле всегда меньше, чем у обоих дочерних элементов. Это свойство, называемоесвойство кучиотличает его от бинарного дерева поиска, где лишь значение левого узла меньше значения его родителя.
Алгоритмы вставки и выдачи элементов основаны на временном нарушении свойства кучи и последующем его исправлении путем сравнения и замены вверх или вниз по одной ветви.
Чтобы поместить элемент в кучу, Python сначала выбирает, куда его вставить. Если нижний слой заполнен не до конца, узел добавляется в следующий открытый слот. Иначе создается новый уровень и элемент добавляется в него. Как только узел добавлен, Python сравнивает новый узел с его родителем. Если свойство кучи нарушено, узел и родительский объект обмениваются местами. Проверка продолжается до тех пор, пока не будет восстановлено свойство кучи или не будет достигнут корень.
Использование приоритетных очередей
Очередь с приоритетом и куча, как реализация такой очереди, полезны для программ, которые включают в себя поиск некоторого экстремального элемента. Очередь с приоритетом может понадобиться для эффективного решения следующих задач:
- Получить три самых популярных поста в блоге по данным о посещениях.
- Найти скорейший способ добраться из одной точки в другую.
- Спрогнозировать на основе частоты прибытия автобусов, какой из них прибудет первым.
Другой пример, на котором мы остановимся подробнее, – планирование отправки электронных писем. Представьте себе систему, работающую с несколькими видами электронных писем. Каждый вид необходимо отправлять с определенной частотой: один вид сообщений должен отправляться каждые 15 мин., другой — каждые 40 мин.
Планировщик добавляет оба типа писем в очередь с отметкой времени, указывающей, когда электронное письмо нужно отправить в следующий раз. Затем планировщик смотрит на элемент с ближайшей временной меткой и вычисляет, сколько времени нужно подождать перед отправкой.
По завершении ожидания планировщик отправляет соответствующее послание и берет следующее письмо из приоритетной очереди, вычисляет время до его отправки. Предыдущее письмо планировщик помещает обратно в очередь, как новый элемент.
Кучи в виде списков в модуле heapq
Напомним, что куча представляет собой полное двоичное дерево. Полнота означает, что на каждом слое (кроме последнего) известно число элементов. За счет этого кучи легко реализовать с помощью списков Python, что и сделано в модуле heapq.
Связи между элементом с индексомkи окружающими его элементами описывают три правила:
- Первый потомок k-го элемента имеет индекс
2*k + 1. - Второй потомок k-го элемента имеет индекс
2*k + 2. - Родитель k-го элемента имеет индекс
(k + 1) // 2.
Пояснение
Символ // соответствует операции целочисленного деления.
Приведенные правила помогают представить список, как полное двоичное дерево. Также нужно понимать, что у любого элемента есть родительский элемент, но необязательно присутствует дочерний. Если индекс2*kнаходится за пределами списка, то у элемента нет дочерних элементов. Если2*kявляется допустимым индексом, а2*k+1– нет, то у элемента есть лишь один потомок.
Свойство кучи подразумевает, что еслиhявляется кучей, то следующее выражение никогда не будет ложным:
h[k] <= h[2*k + 1] and h[k] <= h[2*k + 2] Выражение может вызвать исключениеIndexError, если индекс вышел за пределы списка, но вычисляемое логическое значение никогда не будетFalse.
То есть в терминах списков: k-й элемент всегда меньше, чем каждый из пары элементов, стоящих вслед за 2k-м элементом.
Пример списка, удовлетворяющего свойству кучи:
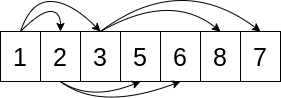
Стрелки проведены от элемента с индексомkк элементам с индексами2 * k + 1и2 * k + 2. Например, первый элемент в списке Python имеет индекс 0, поэтому две стрелки указывают на индексы 1 и 2.
Базовые операции
В отличие от многих других модулей Python,heapqне определяет пользовательский класс, а работает со списками напрямую.
Обычно, как в приведенном примере электронной почты, элементы вставляются в кучу один за другим, начиная с пустой кучи. Однако, если уже есть список элементов, их можно преобразовать с помощью функцииheapify():
>>> import heapq >>> a = [3, 5, 1, 2, 6, 8, 7] >>> heapq.heapify(a) >>> a [1, 2, 3, 5, 6, 8, 7] Хотя 7 идет после 8, легко проверить, что список подчиняется свойству кучи. Например, значениеa[2], равное 3, меньше значенияa[2*2 + 2], равного 7.
heapify()изменяет список на месте, но не сортирует его. Чтобы удовлетворять необходимому свойству куча не должна быть отсортирована. В то же время любой отсортированный список удовлетворяет свойству кучи и запускheapify()на отсортированном списке не изменит порядок элементов.
Другие основные операции в модуле Pythonheapqпредполагают, что список уже является кучей. Полезно отметить, что кучей всегда являются пустой список или список единичной длины.
Поскольку корень дерева является первым элементом, нам не требуется специальной функции для чтения наименьшего элемента – достаточно извлечь его по индексуa[0]. Чтобы вытолкнуть наименьший элемент при сохранении свойства кучи, используется функцияheappop():
>>> root = heapq.heappop(a) >>> print(root, a) 1 [2, 5, 3, 7, 6, 8] Функция возвращает первый элемент, 1. Сама куча изменяется, но сохраняется свойство кучи: например,a[1]равно 5,а[1*2 + 2]равно 6.
Модуль Pythonheapqтакже включает в себяheappush()для помещения элемента в кучу при сохранении свойства кучи.
>>> heapq.heappush(a, 4) >>> print(a) [2, 5, 3, 7, 6, 8, 4] >>> heapq.heappop(a) 2 >>> heapq.heappop(a) 3 >>> heapq.heappop(a) 4 Мы добавили в кучу 4, но затем вытолкнули из нее три элемента. Как можно видеть, всегда выталкивается наименьший элемент.
Модуль Pythonheapqопределяет еще две операции:
heapreplace()эквивалентноheappop()с последующимheappush().heappushpop()эквивалентноheappush()c последующимheappop().
Эта пара методов эффективнее, чем входящие в них функции, запущенные по отдельности.
Высокоуровневые операции
Поскольку очереди с приоритетом часто используются для объединения отсортированных последовательностей, модульheapqимеет готовую функциюmerge()для объединения нескольких очередей. Функцияmerge()предполагает, что входные итерируемые объекты уже упорядочены, и возвращает итератор, а не список.
В качестве примера использованияmerge()рассмотрим реализацию планировщика электронной почты:
import datetime def email(frequency, details): current = datetime.datetime.now() while True: current += frequency yield current, details fast_email = email(datetime.timedelta(minutes=15), "fast email") slow_email = email(datetime.timedelta(minutes=40), "slow email") unified = heapq.merge(fast_email, slow_email) Входные данные дляmerge()в этом примере являются бесконечными генераторами. Возвращаемое значение, присвоенное переменнойunifiedявляется бесконечным итератором. Этот итератор возвращает электронные письма, которые будут отправлены в порядке будущих временных меток.
Для отладки и подтверждения правильности слияния кода выведем на экран десять первых отправленных писем:
for _ in range(10): print(next(unified)) (datetime.datetime(2020, 7, 7, 11, 12, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 11, 27, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 11, 37, 17, 753587), 'slow email') (datetime.datetime(2020, 7, 7, 11, 42, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 11, 57, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 12, 12, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 12, 17, 17, 753587), 'slow email') (datetime.datetime(2020, 7, 7, 12, 27, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 12, 42, 17, 753580), 'fast email') (datetime.datetime(2020, 7, 7, 12, 57, 17, 753580), 'fast email') Обратите внимание, чтоfast emailидут каждые 15 минут, аlow emailкаждые 40 минут, при этом электронные письма правильно чередуются и идут в порядке их временных меток. При этом функцияmerge()не читает входные данные целиком, а работает динамически.
Другой пример – объединение упорядоченных по времени последовательностей строк из разных файлов журналирования. Даже если файлы большие, операция занимает разумное количество времени. Рассмотрим также другие задачи.
Поиск нескольких наименьших (наибольших) элементов кучи
Как мы увидели выше, кучи хороши для объединения отсортированных последовательностей. Но они пригодны и для решения других задач. Например, кучи помогают идентифицировать верхние или нижниеnобъектов. Для подобных задач в модуль Python heapq есть функции высокого уровня.
Например, этот код получает в качестве входных данных результаты финального забега на 100 метров среди женщин на летних Олимпийских играх 2016 года и печатает список медалисток (трех лучших участниц):
results=""" Christania Williams 11.80 Marie-Josee Ta Lou 10.86 Elaine Thompson 10.71 Tori Bowie 10.83 Shelly-Ann Fraser-Pryce 10.86 English Gardner 10.94 Michelle-Lee Ahye 10.92 Dafne Schippers 10.90 """ top_3 = heapq.nsmallest( 3, results.splitlines(), key=lambda x: float(x.split()[-1]) ) print(" ".join(top_3)) Elaine Thompson 10.71 Tori Bowie 10.83 Marie-Josee Ta Lou 10.86 Этот код использует функциюnsmallest(), которая возвращаетnнаименьших элементов итерируемого объекта и принимает три аргумента:
n– количество возвращаемых элементов,iterable– итерируемый набор данных для сравнения,key– функция, определяющая как должны сравнваться элементы.
Здесь на местеkeyмы видим lambda-функцию, которая разбивает строку на пробелы, берет последний элемент и преобразует его в число с плавающей запятой. То есть код «сортирует» строки по времени забега и возвращает три строки с наименьшим временем. Они соответствуют трем самым быстрым бегуньям – золотой, серебряной и бронзовой медалистке.
Для поиска самых больших элементов есть аналогичная функцияnlargest(). Такая функция, например, была бы полезна, если бы мы хотели получить список медалистов на соревнованиях по метанию копья.
Когда использовать heapq
Куча является хорошим инструментом для решения задач с поиском экстремумов. Таким образом, проблемы, для которых подходят кучи, обычно содержат следующие слова:
- наибольший / наименьший
- лучший / худший
- верх / низ
- максимум / минимум
- оптимум
Всякий раз, когда формулировка проблемы указывает на то, что вы ищете какой-то экстремальный элемент, может пригодиться очередь с приоритетом. Также кучи более эффективны, если нужно проводить упорядочение на месте, когда в последовательность во время работы с ней могут добавляться новые элементы.
Иногда приоритетная очередь является лишь частью решения, а остальная часть лежит в областидинамического программирования. Это относится к примеру, который мы рассмотрим в следующих разделах.
Практический пример: поиск путей для робота в лабиринте
Следующий пример служит реалистичным вариантом использования модуля heapq. В примере будет использован классический алгоритм, важной составляющей которого является использование кучи.
Представим себе робота, которому нужно ориентироваться в двумерном лабиринте. Робот должен пройти от стартовой точки в верхнем левом углу к месту назначения в правом нижнем углу. Карта лабиринта хранится в памяти робота – путь можно спланировать заранее. Цель – преодолеть лабиринт как можно быстрее (робот движется с постоянной скоростью, по горизонтали, вертикали и диагонально).
Рассматриваемый алгоритм является вариацей алгоритма Дейкстры. В алгоритме сохраняются и обновляются три структуры данных:
tentative– карта предварительного пути от начальной точки до конечной позиции. Путь называетсяпредварительным, поскольку это самый короткий известный на данный момент путь, его можно улучшить.certain– множество точек, для которых путь, определяемый картойtentativeявляется кратчайшим из возможных.candidates– куча, составленная позициями-кандидатами, по которым может пройти путь. Ключ сортировки – длина пути.
На каждом шаге мы выполняем от двух до четырех действий:
- Выталкиваем позицию-кандидата из кучи
candidates - Добавляем кандидата в множество
certain. Если кандидат уже является частью множестваcertain, пропускаем следующие два действия. - Находим кратчайший известный путь к текущему кандидату.
- Для каждого из ближайших соседей текущего кандидата рассматриваем, даёт ли проход через кандидата более короткий путь, чем текущий путь
tentative. Если это так, обновляем путьtentativeи кучуcandidatesэтим новым путем.
Перечисленные шаги выполняются в цикле до тех пор, пока в множествоcertainне попадет позиция пункта назначения. Результатом алгоритма является путь, состоящий из точек, перечисленных вcertain, который теперь точно является кратчайшим из возможных путей.
Робот в лабиринте: вспомогательный код
Теперь, когда мы в общих чертах понимаем алгоритм, напишем код для его реализации. Предварительно напишем несколько вспомогательных функций.
Определим простую карту:
m = """ ?????????? ?????????? ?????????? ?????????? ?????????? """ Карта представляет собой строку в тройных кавычках, отображающую область, в которой робот может двигаться, а также препятствия (в сравнении с оригинальной статьей для наглядности мы заменили точки и крестики на эмодзи — прим. пер.).
Хотя в более реалистичном сценарии карта считывается из файла, для целей обучения проще определить наглядную переменную в коде. Код будет работать на любой карте, но для отладки воспользуемся простым примером.
Определим функцию, которая преобразует карту так, чтобы ее было проще анализировать программно:
def parse_map(m): """Возвращает построчную карту, позиции начала координат и позицию места.""" lines = m.splitlines() # начало координат (точка отправления) origin = 0, 0 # координаты места назначения destination = len(lines[-1]) - 1, len(lines) - 1 return lines, origin, destination Списокlinesможно индексировать с помощью координат (x, y) – выражениеlines[y][x]возвращают значение позиции в виде одного из двух символов:
- ? – пустая позиция
- ? – позиция препятствия
Следующая функция определяет, может ли робот занять позицию (x, y) с учетом содержания карты и ее границ:
def is_valid(lines, position): """Проверяет, не выходит ли координата position за границы карты и доступна ли position для перемещения""" x, y = position if not (0 <= y < len(lines) and 0 <= x < len(lines[y])): return False if lines[y][x] != "?": return False return True Описанную функциюis_valid()применим в следующей функции для нахождения соседей текущей позиции:
def get_neighbors(lines, current): """Возвращает коордианты соседей текущей позиции""" x, y = current for dx in [-1, 0, 1]: for dy in [-1, 0, 1]: if dx == 0 and dy == 0: continue position = x + dx, y + dy if is_valid(lines, position): yield position Последняя вспомогательная функция будет использоваться для нахождения пути:
def get_shorter_paths(tentative, positions, through): """Возвращает позиции, при прохождении через которые путь короче текущего пути""" path = tentative[through] + [through] for position in positions: if position in tentative and len(tentative[position]) <= len(path): continue yield position, path У функцииget_shorter_paths()три параметра:
tentative— словарь, ставящий в соответствие ключу позиции наиболее короткий известный путьpositions— итерируемый объект позиций, до которых мы хотим сократить путьthrough– позиция, при прохождению через которую может быть найден более короткий путь доpositions
Предполагается, что все элементы вpositionsмогут быть достигнуты за один шаг.
Функцияget_shorter_paths()проверяет, приведет ли использование позицииthroughв качестве последнего шага текущего пути к лучшему пути для каждой позиции. Если путь к позиции отсутствует, то любой путь считается «более коротким». Если есть известный путь, то новый путь будет возвращен, только если его длина меньше. Чтобы упростить работу с интерфейсомget_shorter_paths(), инструкцияyieldвключает не только позицию, но и путь.
Все вспомогательные функции написаны какчистые функции, то есть они не изменяют структуры данных, а только возвращают значения. Все обновления структуры данных выполняет основной алгоритм.
Робот в лабиринте: код основного алгоритма
Итак, мы ищем кратчайший путь между началом координат и пунктом назначения, и у нас есть три структуры данных:
certain– множество позиций, являющихся частью пути (исходно пустое).candidates– куча, состоящая из позиций-кандидатов.tentative– словарь, ставящий в соответствие узлам промежуточные кратчайшие пути.
Позиция находится вcertain, если мы уверены, что самый короткий из известных путей – самый короткий из возможных. Если вcertainоказался пункт назначения, значит, найден искомый путь.
Кучаcandidatesупорядочена по длине самого короткого известного пути и управляется с помощью функций модуля heapq.
На каждом шаге мы смотрим на позицию-кандидата и кратчайший известный путь. Из кучиcandidatesвыталкивается элемент с помощьюheappop(). До этой позиции-кандидата не существует более короткого пути – все остальные пути проходят через другие узлы, и все они длиннее. Из-за этого текущий кандидат может быть отмечен какcertain.
Затем мы просматриваем всех непосещённых соседей и, если проход через текущую позицию является улучшением, мы добавляем их в кучуcandidates, используяheappush().
Описанный алгоритм реализует функцияfind_path():
def find_path(m): lines, origin, destination = parse_map(m) tentative = {origin: []} candidates = [(0, origin)] certain = set() while destination not in certain and len(candidates) > 0: _ignored, current = heapq.heappop(candidates) if current in certain: continue certain.add(current) neighbors = set(get_neighbors(lines, current)) - certain shorter = get_shorter_paths(tentative, neighbors, current) for neighbor, path in shorter: tentative[neighbor] = path heapq.heappush(candidates, (len(path), neighbor)) if destination in tentative: return tentative[destination] + [destination] else: raise ValueError("no path") Функцияfind_path()получает карту в виде строки и возвращает путь от начала координат к пункту назначения в виде списка позиций. Эта функция немного длиннее и сложнее тех, что мы писали раньше – давайте пробежимся построчно:
- В первых трех строчках после объявления функции мы объявляем переменные, которые будет просматривать и обновлять цикл
while. Исходный путь имеет длину 0 – это путь от начала координат в него же. - Далее идйт цикл
while. Если позиций-кандидатов нет, то и путь сократить нельзя. Если пункт назначения находится вcertain, путь найден. - Первые четыре строки после объявления цикла получают позицию-кандидата с помощью
heappop(), пропускают итерацию, если позиция-кандидат уже находится вcertainили, в противном случае, добавляют её вcertain. Это гарантирует, что каждая позиция-кандидат обрабатываеся циклом не более одного раза. - Следующие строки цикла ищут более короткие пути к соседним позициям и обновляют словарь
tentativeи кучуcandidates, используяget_neighbors()иget_shorter_paths(). - Условная конструкция после цикла возвращает необходимый результат. Хотя вычисление путей без конечной позиции сделало реализацию алгоритма более простой, в самом интерфейсе логично вернуть путь целиком вместе с пунктом назначения. Если путь не найден, вызываем исключение.
Код для демонстрации алгоритма
Итак, роботу уже всё понятно. Но чтобы сделать результат нагляднее для людей, хорошо бы визуализировать алгоритм. Напишем для этого функцию, отображающую путь робота.
def show_path(path, m): lines = m.splitlines() for x, y in path: lines[y] = lines[y][:x] + "?" + lines[y][x+1:] return " ".join(lines) + " " path = find_path(m) print(show_path(path, m)) ?????????? ?????????? ?????????? ?????????? ?????????? Здесь всё просто: сначала получили кратчайший путь с помощьюfind_path(), затем передали его вshow_path()для рендеринга карты с отмеченным на ней путём робота. Наконец, вывели карту. Как и ожидалось, робот, успешно преодолел все препятствия.
Подобные проблемы с поиском пути, которые можно решить с помощью комбинации динамического программирования и очередей с приоритетами, нередко встречаются на собеседованиях и соревнованиях по программированию. Например, на Advent of Code 2019 года соответствующую задачу было можно решить с помощью описанных здесь методов.
Заключение
Теперь вы знаете о том, как реализуются структуры данных кучи в модуле Python heapq и для каких задач программирования они полезны. Главное понимать, что эффективность этого инструмента проявляется не в непосредственной сортировке значений, а в поиске экстремальных и приоритетных значений за минимальное время и корректной обработке очередей с приоритетом. Функций в модуле немного, а вся необходимая дополнительная информация и примеры доступны вдокументации.
Телеграм: t.me/ainewsline
Источник: proglib.io