Антифрод — сервис по поиску и нивелированию случаев эксплуатации других, общедоступных сервисов Яндекса. Три года назад мы начали проектировать платформу, позволяющую быстро и легко развернуть антифрод где угодно в компании. Сложность задачи в том, что многим сервисам нужны максимально строгие гарантии по скорости, надежности и качеству; часть из них оперирует очень большими объемами данных. Команде антифрода, в свою очередь, важна гибкость системы, простота поддержки и выразительность факторов, на которых будет строиться машинное обучение.
Руководитель антифрода Андрей Попов Nox_andry выступил с докладом о том, как мы смогли выполнить все эти противоречивые требования. Центральная тема доклада — модель вычисления сложных факторов на потоке данных и обеспечение отказоустойчивости системы. Также Андрей кратко описал следующую, еще более быструю итерацию антифрода, которую мы сейчас разрабатываем. Команда антифрода, по сути, решает задачу бинарной классификации. Поэтому доклад может быть интересен не только специалистам по борьбе с фродом, но и тем, кто делает разнообразные системы, в которых нужны быстрые, надежные и гибкие факторы на больших объемах данных. — Привет, меня зовут Андрей. Я работаю в Яндексе, руковожу разработкой антифрода. Мне сказали, что люди предпочитают использовать слово «фичи», поэтому везде в докладе я буду упоминать его, но название и вступление остались старыми, со словом «факторы».
Что такое антифрод?
Что вообще такое антифрод? Это система, которая защищает пользователей от негативного влияния на сервис. Под негативным влиянием я имею в виду целенаправленные действия, которые могут ухудшить качество сервиса и, соответственно, ухудшить пользовательский опыт. Это могут быть достаточно простые парсеры и роботы, которые ухудшают наши статистики, либо целенаправленная сложная мошенническая деятельность. Второе, конечно, определять сложнее и интереснее.
С чем вообще борется антифрод? Пара примеров.
Например, имитация действий пользователя. Этим занимаются ребята, которых мы называем «черные SEO», — те, кто не хочет улучшать качество сайта и контент на сайте. Вместо этого они пишут роботов, которые ходят на поиск Яндекса, кликают по их сайту. Они расчитывают, что так их сайт поднимется выше. На всякий случай напоминаю, что такие действия противоречат пользовательскому соглашению и могут привести к серьезным санкциям со стороны Яндекса.
Или, например, накрутка отзывов. Такой отзыв можно увидеть у организации на Картах, которая ставит пластиковые окна. За этот отзыв она же сама и заплатила. Верхнеуровнево архитектура антифрода выглядит так: некоторый набор сырых событий попадают в саму система антифрод как в черный ящик. На выходе из него генерируются размеченные события.
У Яндекса много сервисов. Все они, особенно большие, так или иначе сталкиваются с разными видами фрода. Поиск, Маркет, Карты и десятки других.
Где мы были еще года два-три назад? Каждая команда выживала под натиском фрода как могла. Она генерировала свои команды антифрода, свои системы, которые не всегда работали хорошо, были не очень удобны для взаимодействия с аналитиками. И главное, они были слабо проинтегрированы между собой.
Я хочу рассказать, как мы это решили созданием единой платформы.
Зачем нам нужна единая платформа? Переиспользование опыта и данных. Централизация опыта и данных в одном месте позволяет быстрее и качественнее реагировать на крупные атаки — они обычно бывают кросс-сервисными. Единый инструментарий. У людей есть инструменты, к которым они привыкли. И, очевидно, скорость подключения. Если мы запустили новый сервис, на который сейчас происходит активная атака, то должны быстро подключить к нему качественный антифрод.
Можно сказать, что мы в этом плане не уникальны. Все крупные компании сталкиваются с подобными проблемами. И все, с кем мы коммуницируем, приходят к созданию своей единой платформы.
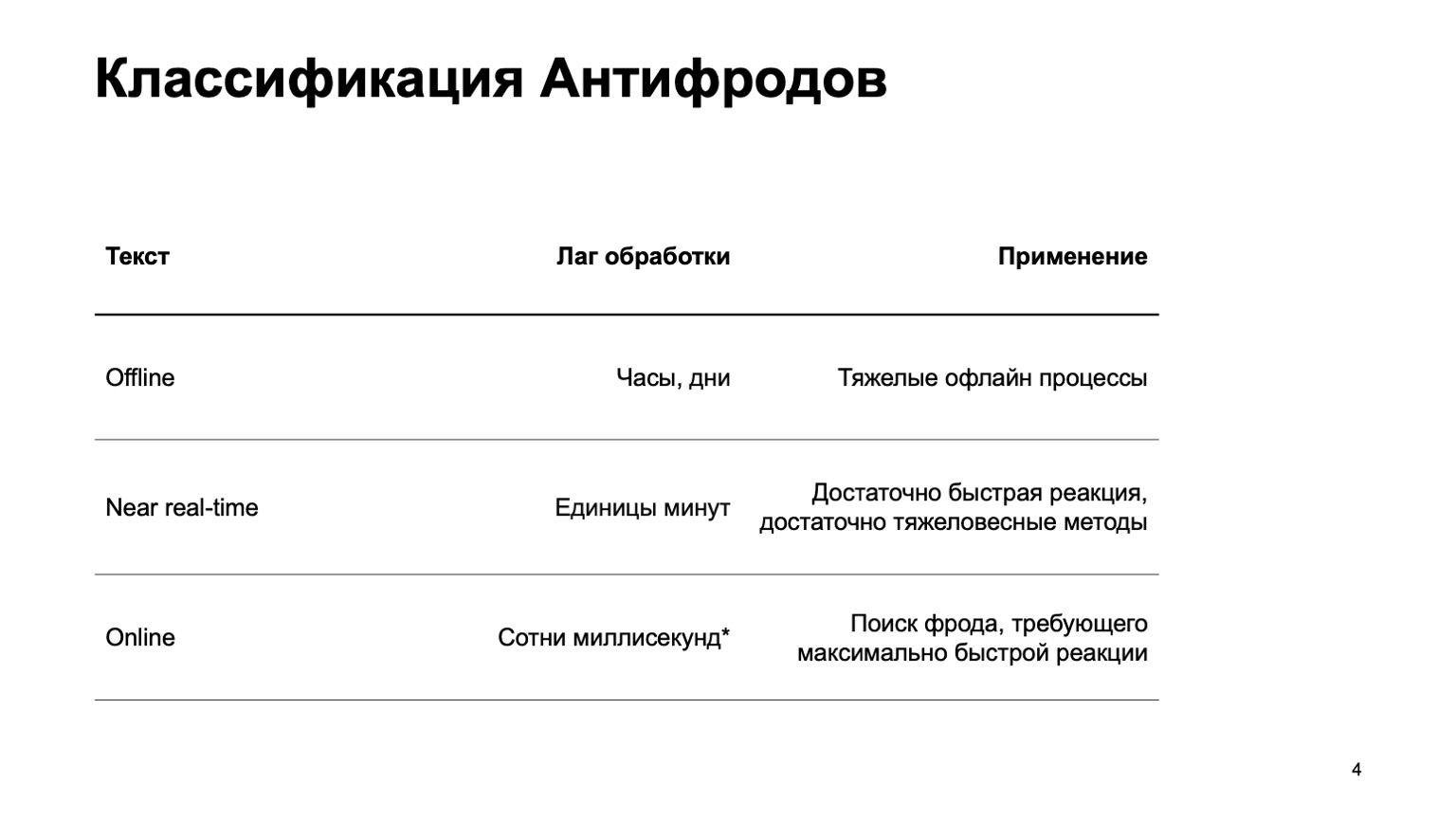
Расскажу немного про то, как мы классифицируем антифроды.
Это может быть офлайн-система, которая считает часы, дни и тяжелые офлайн-процессы: например, сложные кластеризации или сложное переобучение. Этой части я практически не буду касаться в докладе. Есть near real-time-часть, которая работает за единицы минут. Это некая золотая середина, у нее быстрая реакция и тяжеловесные методы. В первую очередь я остановлюсь на ней. Но не менее важно сказать, что на этом этапе мы используем данные с этапа уровнем выше. Есть и онлайн-части, необходимые в тех местах, где требуется быстрая реакция и критично отсеять фрод еще до того, как мы приняли событие и передали его пользователю. Здесь мы вновь переиспользуем данные и алгоритмы машинного обучения, посчитанного на более высоких уровнях.
Я расскажу о том, как устроена эта единая платформа, о языке описания фич и взаимодействия с системой, о нашем пути к увеличению скорости, то есть как раз о переходе со второго этапа к третьему.
Я практически не буду касаться самих ML-методов. В основном я буду рассказывать о платформах, создающих фичи, которые мы потом используем в обучении.
Кому это может быть интересно? Очевидно, тем, кто пишет антифрод или борется с мошенниками. Но также и тем, кто просто запускает поток данных и считает фичи, считает ML. Так как мы сделали достаточно общую систему, может быть, что-то из этого вам будет интересно.
Какие у системы требования? Их достаточно много, вот некоторые из них:
Большой поток данных. Мы обрабатываем сотни миллионов событий за пять минут.
Полностью конфигурируемые фичи.
Декларативный язык описания факторов.
Конечно же, кросс-ДЦ и exactly-once-обработка данных, которая нужна для некоторых сервисов. Удобная инфраструктура — как для аналитиков, которые подбирают итоговые фичи, обучают модели и подобное, так и для разработчиков, которые поддерживают систему.
И, конечно, скорость.
Дальше расскажу про каждый из этих пунктов в отдельности.
Так как я из соображений безопасности не могу рассказывать про реальные сервисы, давайте представлю новый сервис Яндекса. На самом деле нет, забудьте, это выдуманный сервис, который я придумал для показа примеров. Пусть это сервис, на котором у людей есть база всех существующих книг. Они заходят, ставят оценки от одного до десяти, и злоумышленники хотят влиять на итоговый рейтинг, чтобы их книги покупали.
Все совпадения с реальными сервисами, естественно, случайны. Рассмотрим в первую очередь near real-time-версию, так как онлайн конкретно здесь не нужен при первом приближении.
Большие данные
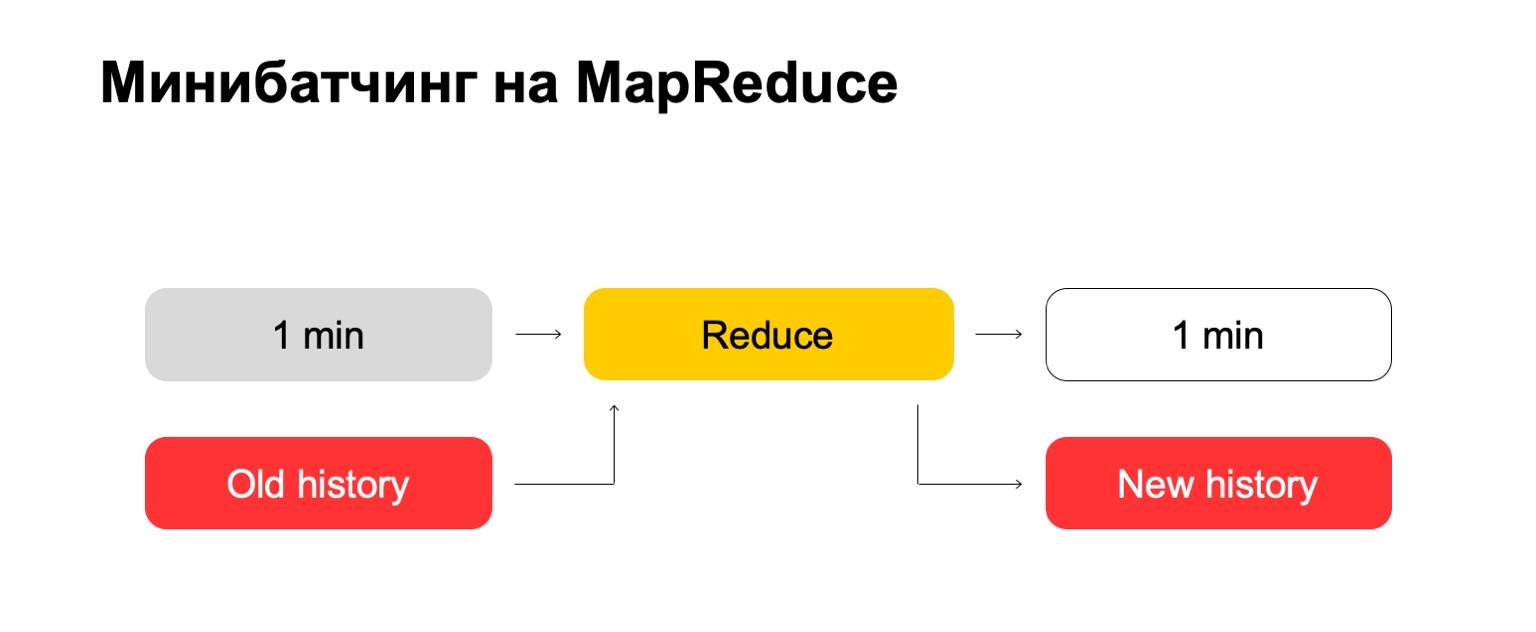
В Яндексе есть классический способ решения проблем с большими данными: использовать MapReduce. Мы используем нашу собственную реализацию MapReduce, называется YT. Кстати, у Максима Ахмедова сегодня вечером рассказ про нее. Вы можете использовать вашу реализацию либо опенсорсную реализацию вроде Hadoop. Почему мы сразу не используем онлайн-версию? Она не всегда нужна, может усложнять пересчеты в прошлое. Если мы добавили новый алгоритм, новые фичи, мы хотим часто пересчитать данные в прошлое, чтобы изменить вердикты по ней. Сложнее использовать тяжеловесные методы — думаю понятно, почему. И онлайн-версия по ряду причин может быть более требовательна по ресурсам. Если мы используем MapReduce, получается примерно такая схема. Мы используем некий минибатчинг, то есть делим на максимально маленькие куски батчей. В данном случае это одна минута. Но те, кто работает с MapReduce, знают, что меньше этого размера, наверное, уже возникают слишком большие оверхеды самой системы — накладные расходы. Условно, она не сможет справляться с обработкой за одну минуту.
Дальше мы над этим набором батчей запускаем набор Reduce и получаем размеченный батч.
В наших задачах часто возникает необходимость считать точное значение фич. Например, если мы хотим посчитать точное количество книг, которые прочитал пользователь за последний месяц, то мы будем считать это значение за каждый батч и должны хранить всю собранную статистику в едином месте. И дальше удалять из нее старые значения и добавлять новые. Почему не использовать методы приблизительного подсчета? Короткий ответ: мы их тоже используем, но иногда в задачах антифрода важно иметь именно точное значение за какие-то интервалы. Например, разница между двумя и тремя прочитанными книгами может быть весьма существенна для тех или иных методов.
Как следствие, нам нужна большая история данных, в которой мы будем хранить эти статистики.
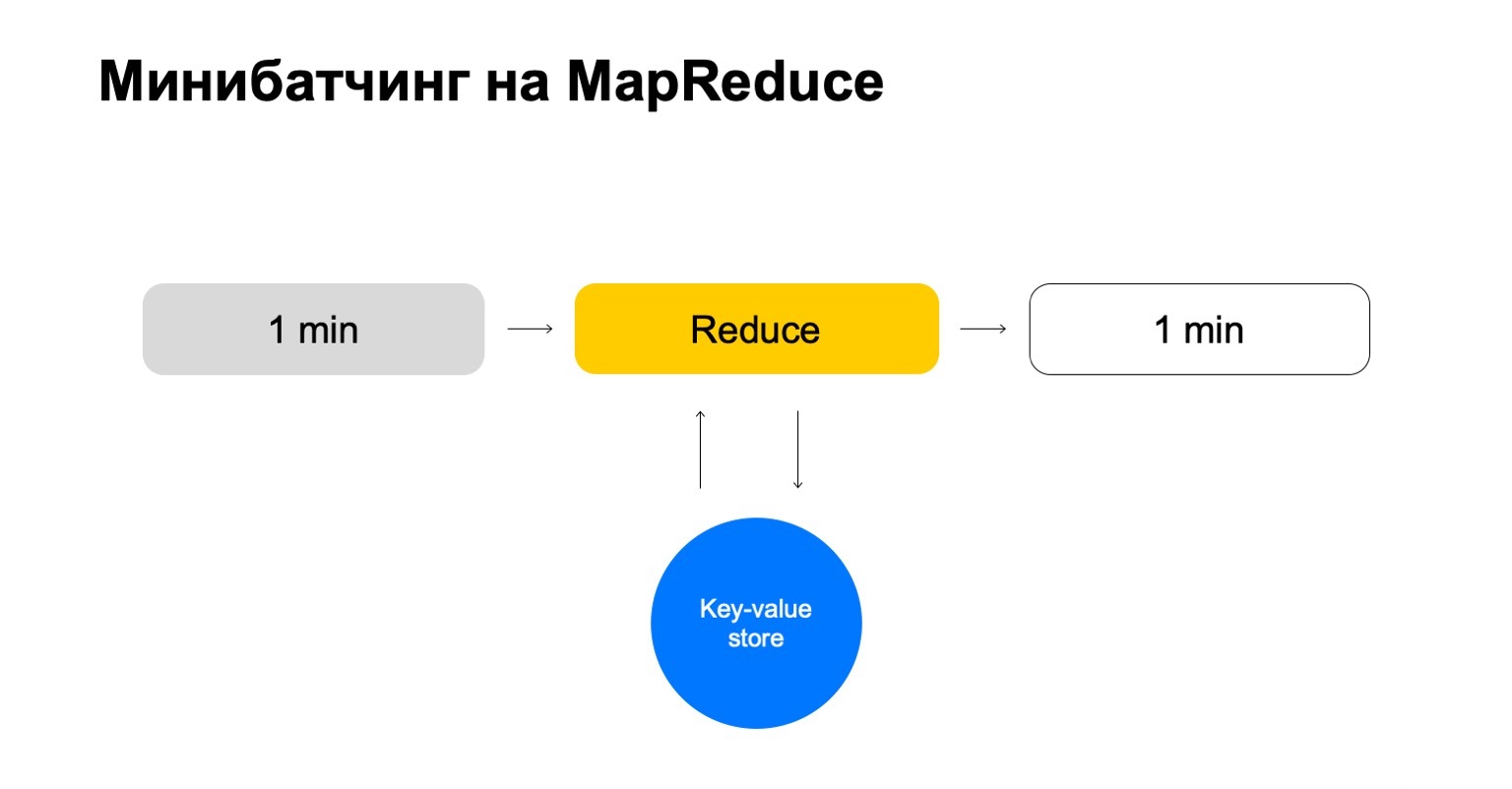
Давайте попробуем «в лоб». У нас есть одна минута и большая старая история. Мы пускаем ее на вход Reduce и на выход выдаем обновленную историю и размеченный лог, данные. Те из вас, кто работает с MapReduce, наверное, знают, что такое может работать достаточно плохо. Если история может быть в сотни, а то и в тысячи, в десятки тысяч раз больше, чем сам батч, то такой процессинг может работать пропорционально размеру истории, а не размеру батча.
Заменим это на некий key-value store. Это вновь наша собственная реализация, key-value-хранилище, но она хранит данные в памяти. Наверное, ближайший аналог — какой-нибудь Redis. Но у нас тут получается небольшое преимущество: наша реализация key-value store очень сильно проинтегрирована с MapReduce и кластером MapReduce, на котором это запускается. Получается удобная транзакционность, удобная передача данных между ними. Но общая схема — что мы в каждом джобе этого Reduce будем ходить в этот key-value storage, обновлять данные и записывать обратно после формирования вердикта по ним.
У нас получается история, которая позволяет обрабатывать только необходимые ключи и легко масштабируется.
Конфигурируемые фичи
Немного о том, как мы конфигурируем фичи. Простых счетчиков часто бывает недостаточно. Для поиска мошенников нужны достаточно разнообразные фичи, нужна умная и удобная система по их конфигурированию.
Давайте разобьем на три этапа:
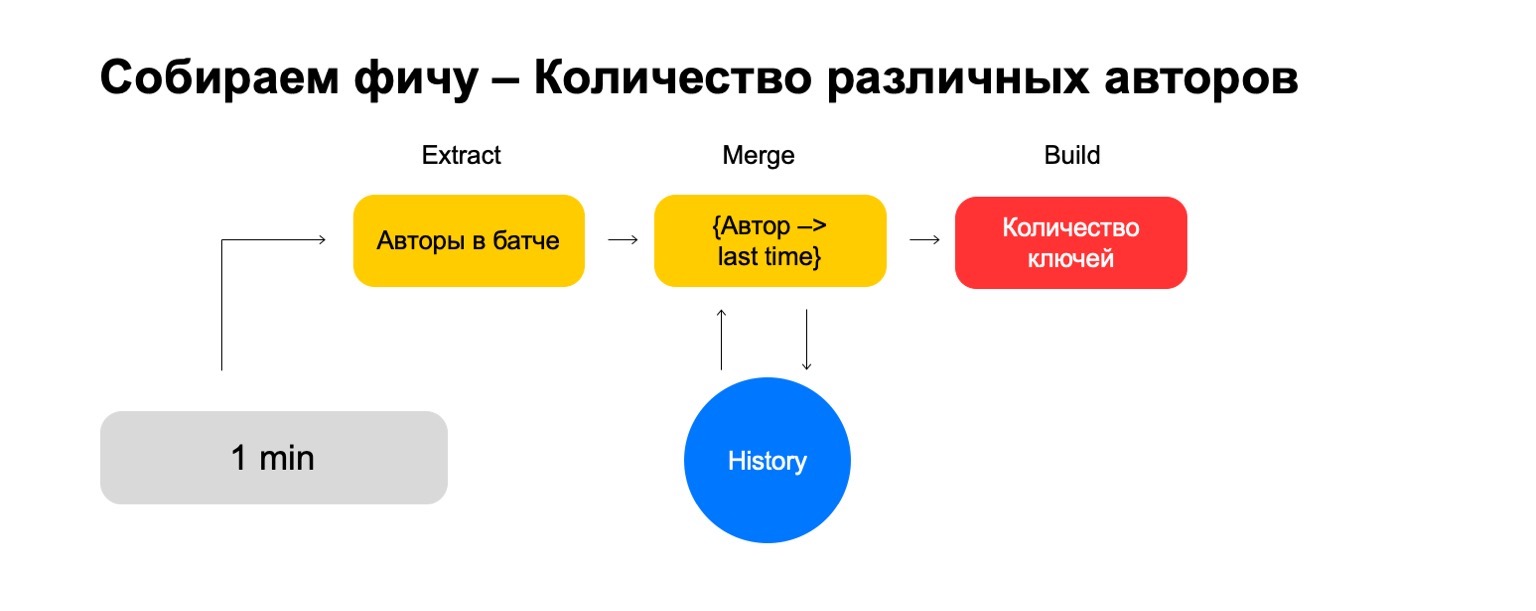
Extract, где мы изымаем данные для данного ключа и из лога.
Merge, где мы сливаем эти данные со статистикой, которая находится в истории.
Build, где мы формируем итоговое значение фичи.
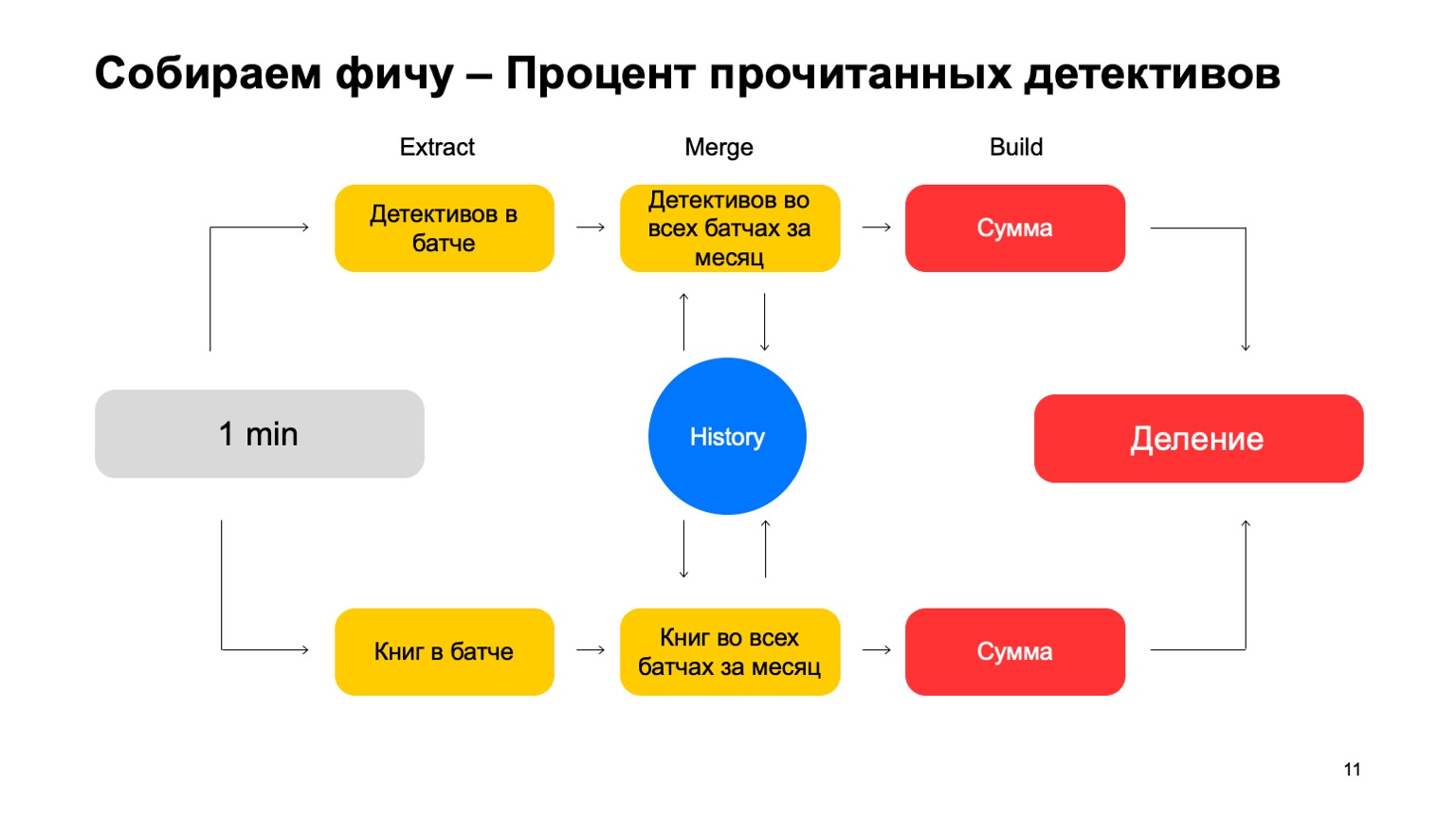
Давайте, например, посчитаем процент детективов, прочитанных пользователем.
Если пользователь читает слишком много детективов, он слишком подозрительный. Никогда непонятно, чего от него ждать. Тогда Extract — изъятие количества детективов, которые прочел пользователь в этом батче. Merge — взятие всех детективов, всех этих данных из батчей за месяц. И Build — это какая-то сумма. Затем мы то же самое делаем для значения всех книг, которые он прочитал, и в итоге получаем деление.
А если мы хотим посчитать разные значения, например, количество различных авторов, которых читает пользователь?
Тогда мы можем взять количество различных авторов, которые прочитал пользователь в этом батче. Дальше хранить некую структуру, где мы делаем ассоциацию из авторов в последнее время, когда пользователь их читал. Таким образом, если мы снова встречаем этого автора у пользователя, то обновляем это время. Если нам нужно удалять старые события, мы знаем, что удалять. Для подсчета итоговой фичи мы просто считаем количество ключей в ней. Но в шумном сигнале таких фич по одному разрезу бывает недостаточно, нам нужна система по склеиванию их джойнов, склеивания этих фич из разных разрезов. Давайте, например, введем вот такие разрезы — пользователь, автор и жанр.
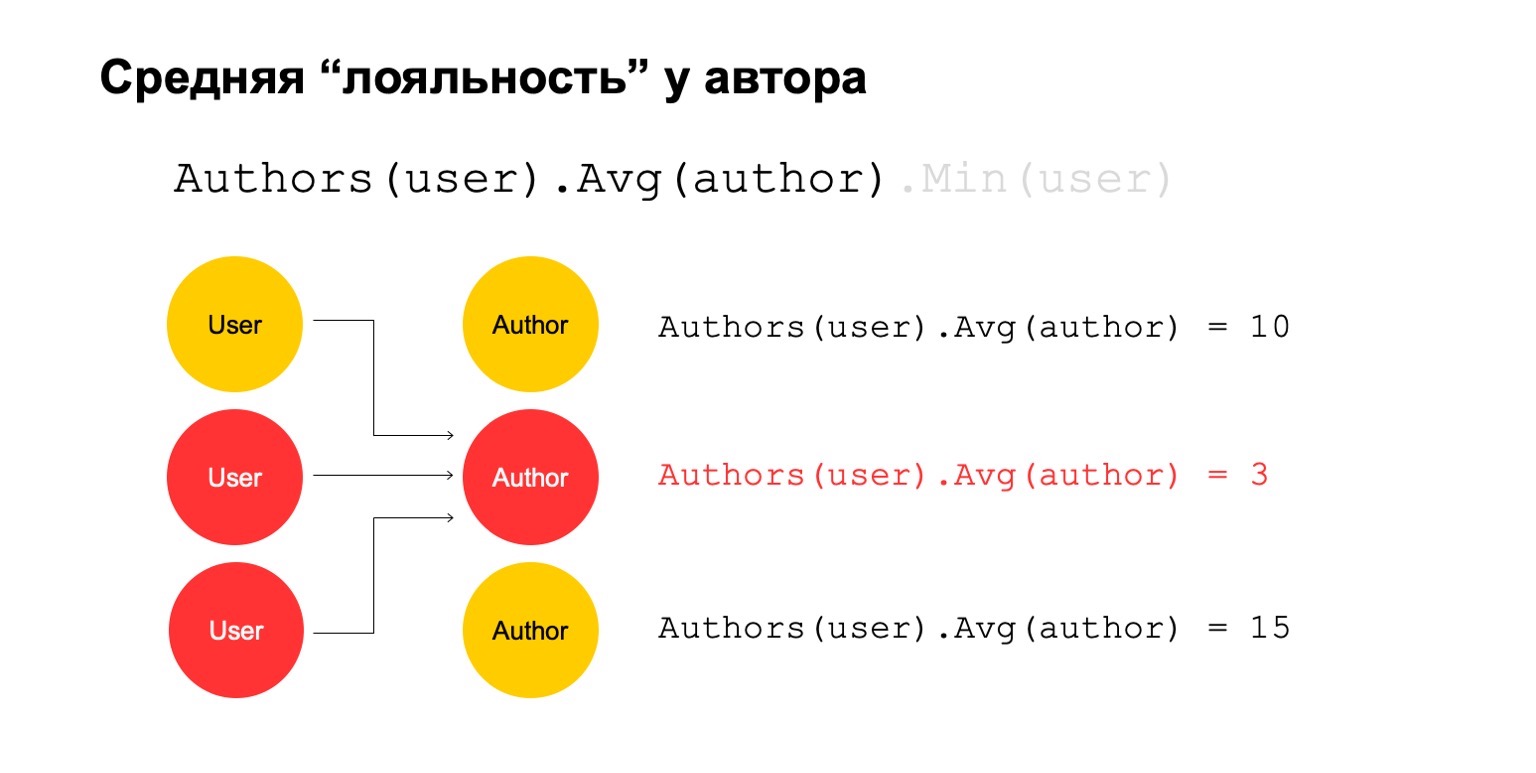
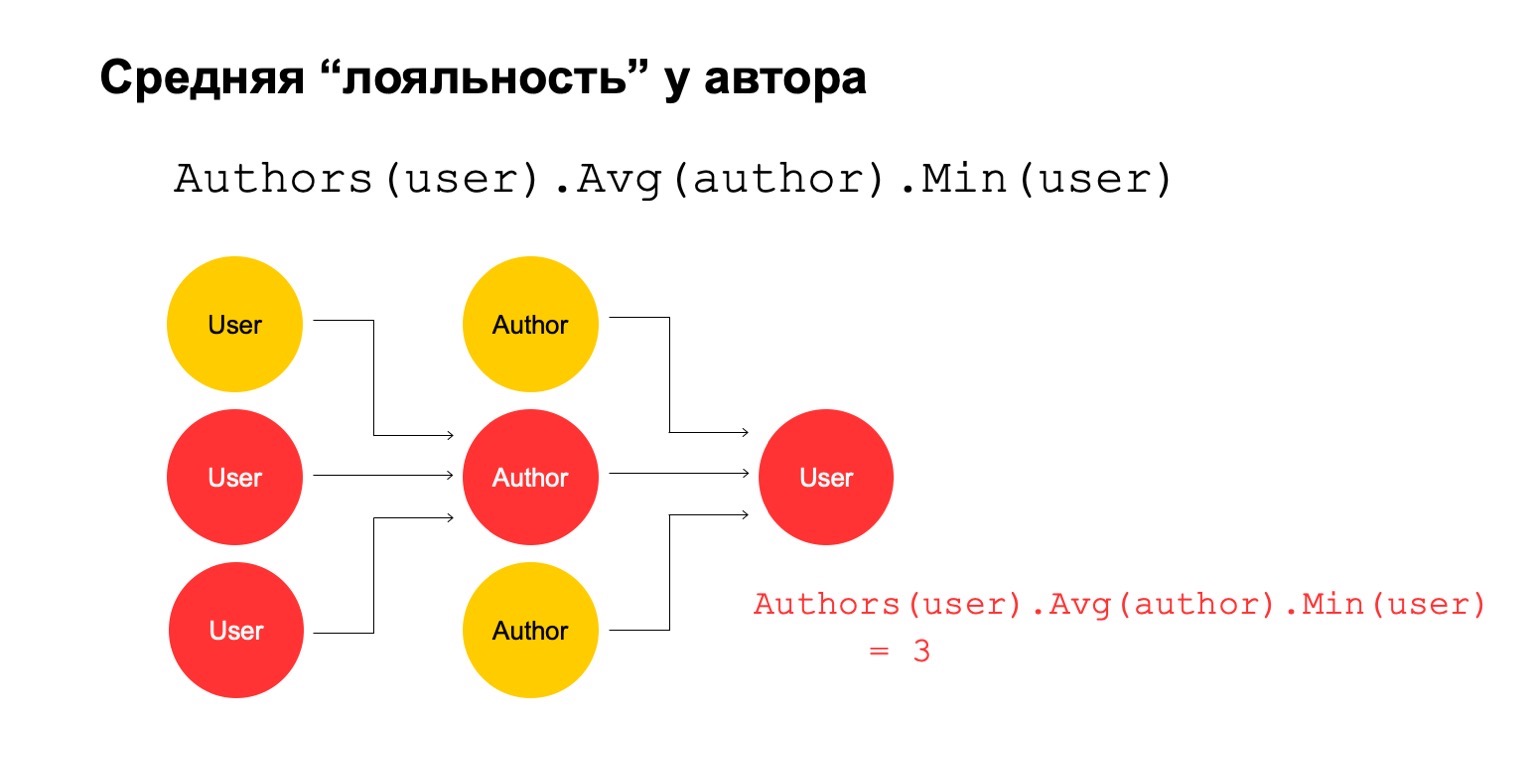
Посчитаем что-нибудь сложное. Например, среднюю лояльность у автора. Под лояльностью я имею в виду, что пользователи, которые читают автора, — они читают практически только его. Причем это среднее значение достаточно низкое для прочитанных в среднем авторов у пользователей, которые его читают. Это может быть потенциальный сигнал. Он, конечно, может означать, что автор просто такой: вокруг него одни фанаты, все, кто его читают, читают только его. Но также это может значить, что сам автор пытается накручивать систему и создает этих фейковых пользователей, которые якобы его читают.
Давайте попробуем это посчитать. Посчитаем фичу, которая считает количество различных авторов за большой интервал. Например, здесь второе и третье значение кажутся нам подозрительными, их слишком мало.
Тогда посчитаем среднее значение по авторам, которые связаны за большой интервал. И тогда здесь среднее значение опять же достаточно низкое: 3. Этот автор нам почему-то кажется подозрительным. И мы можем обратно это вернуть пользователю, чтобы понять, что конкретно этот пользователь имеет связь с автором, который нам кажется подозрительным. Понятно, что само по себе это не может являться явным критерием, что пользователя надо фильтровать или что-то такое. Но это может быть один из сигналов, который мы можем использовать.
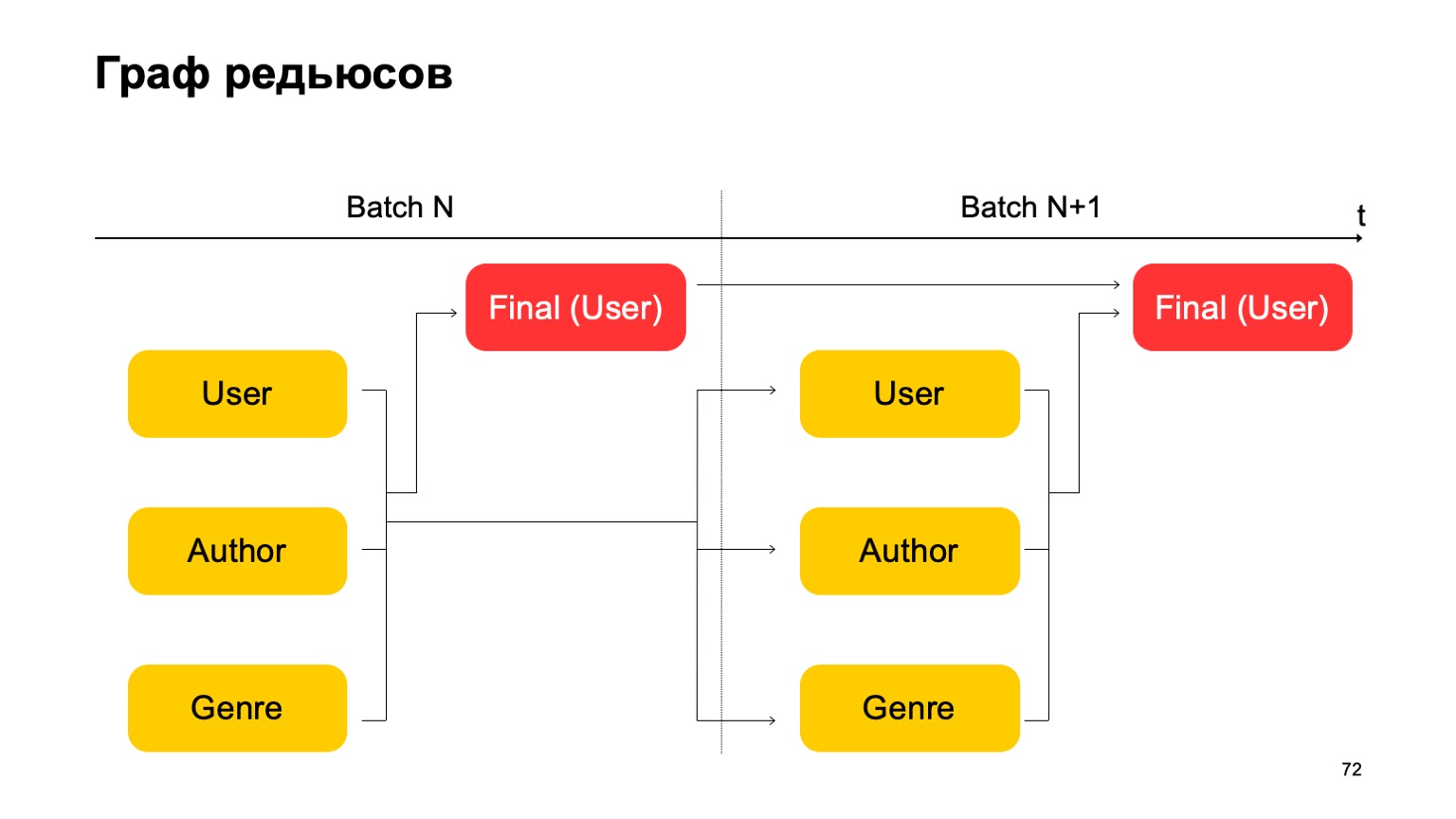
Как это сделать в парадигме MapReduce? Давайте сделаем несколько последовательных редьюсов и зависимости между ними.
У нас получается граф редьюсов. Он влияет на то, по каким срезам мы считаем фичи, какие джойны вообще допустимы, на количество потребляемы ресурсов: очевидно, чем больше редьюсов, тем больше ресурсов. И Latency, throughput. Построим, например, такой граф.
То есть разобьем на два этапа редьюсы, которые у нас есть. На первом этапе мы посчитаем параллельно разные редьюсы по разным разрезам — наши пользователи, авторы и жанр. И нам нужен какой-то второй этап, где мы соберем фичи из этих разных редьюсов и примем итоговый вердикт. Для батча следующего мы делаем аналогичные действия. При этом у нас имеется зависимость первого этапа каждого батча от первого этапа прошлого и второго этапа от второго этапа прошлого.
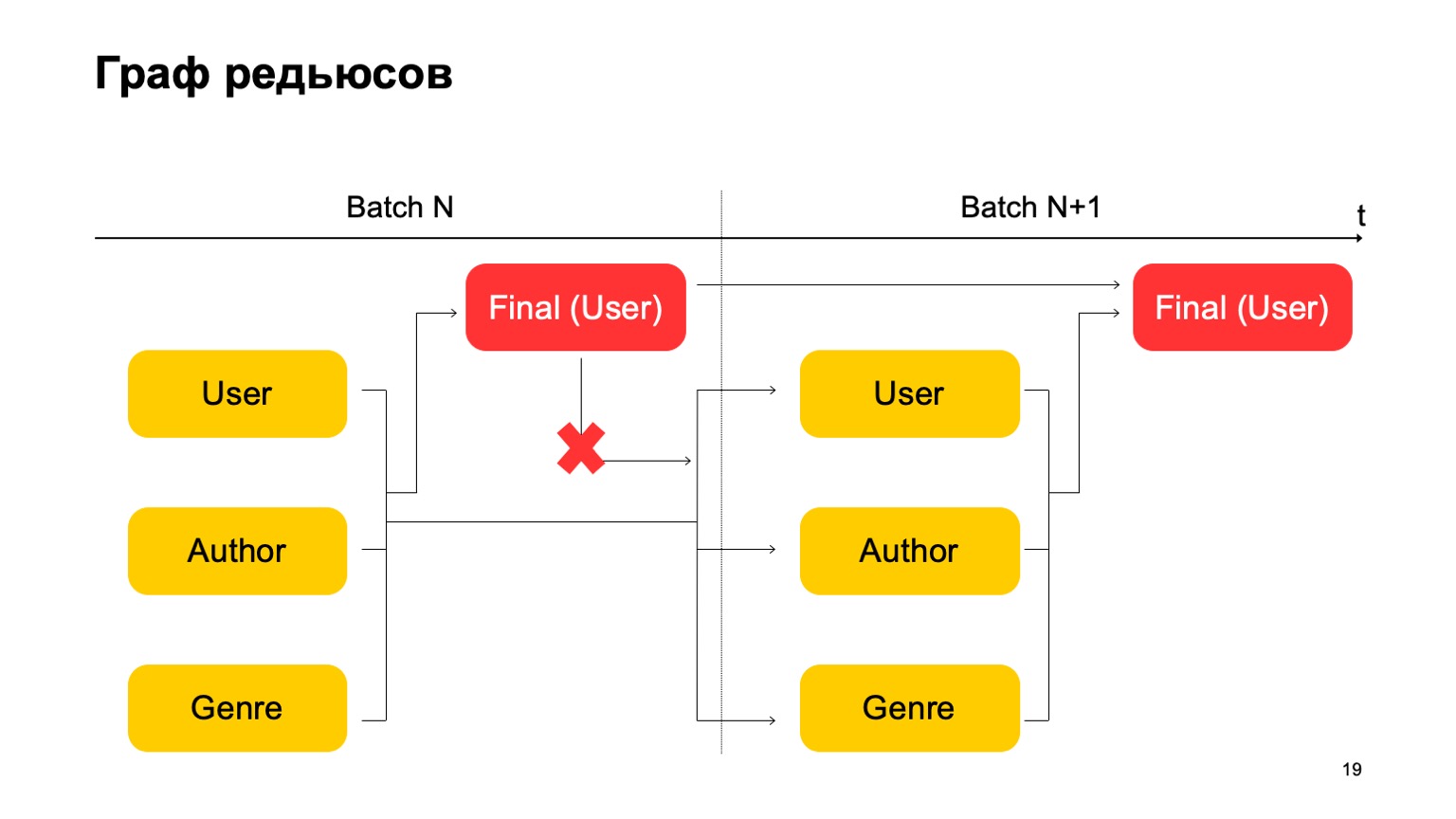
Здесь важно, что у нас нет вот такой зависимости:
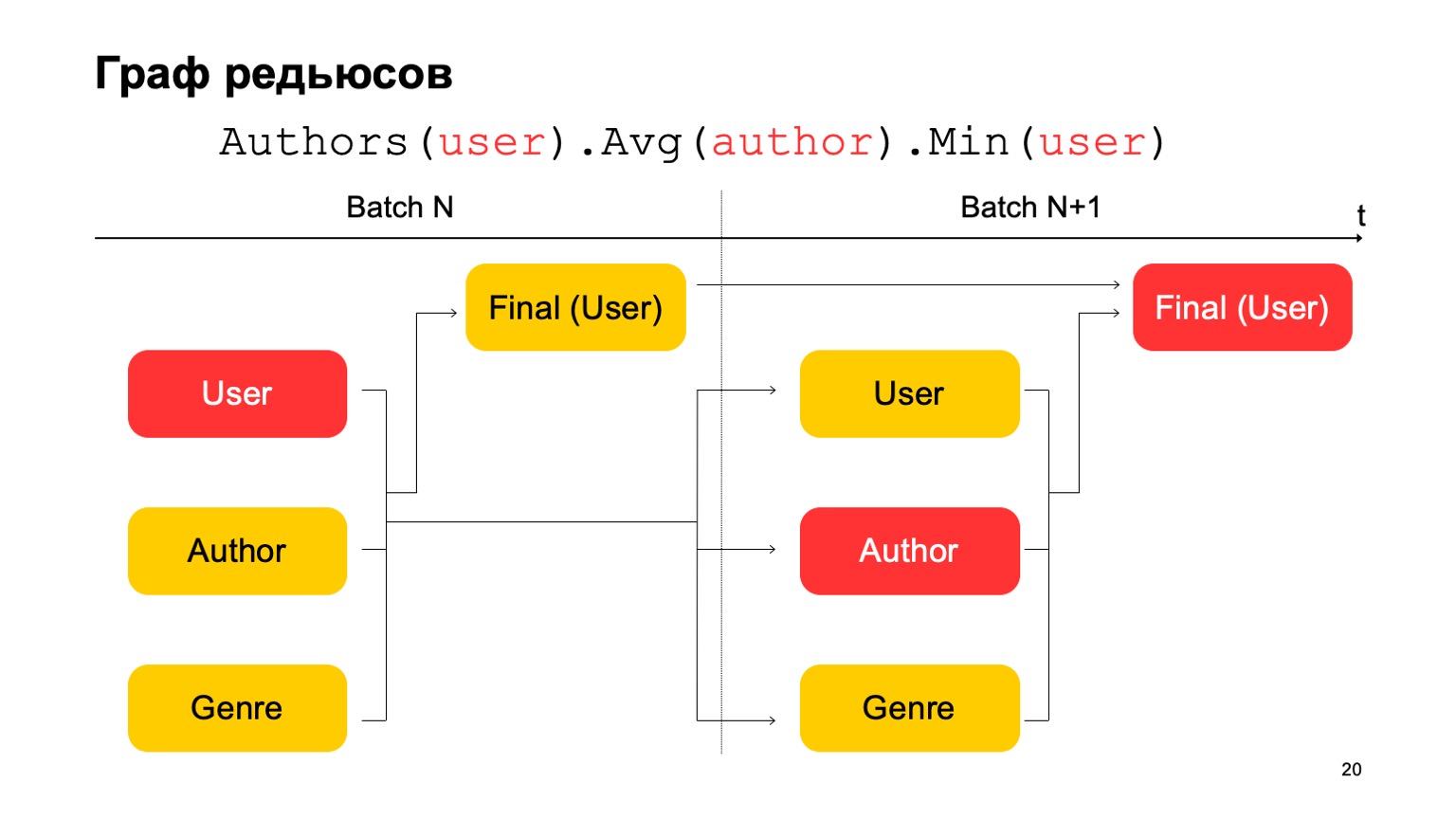
То есть у нас фактически получается конвейер. То есть первый этап следующего батча может работать параллельно со вторым этапом первого батча. А как в этом сделать трехстадийную статистику, которую я приводил выше, если у нас всего два этапа? Очень просто. Мы можем считать первое значение на первом этапе батча N.
Второе значение на первом этапе батча — N+1, и итоговое значение нужно считать на втором этапе батча N+1. Таким образом, при переходе между первым этапом и вторым будут, может быть, не совсем точные статистики для батча N+1. Но обычно этого достаточно для подобных расчетов. Имея все эти вещи, можно построить более сложные фичи из кубиков. Например, отклонение текущей оценки книги от средней оценки пользователя. Или долю пользователей, которые ставят очень позитивные или очень негативные оценки книге. Тоже подозрительно. Или среднюю оценку книг по пользователям, у которых больше N оценок за различные книги. Это, может быть, более точная и справедливая оценка с какой-то точки зрения. К этому добавляется то, что мы называем отношениями между событиями. Часто у нас в логах или в данных, которые нам посылаются, появляются дубликаты. Это могут быть либо технические события, либо роботное поведение. Мы такие дубликаты также обнаруживаем. Или, например, какие-то связанные события. Скажем, у вас в системе показываются рекомендации книг, и пользователи кликают по этим рекомендациям. Чтобы итоговые статистики, которые влияют на ранжирование, не портились, нам нужно следить, что если мы отфильтруем показ, то должны отфильтровать и клик по текущей рекомендации. Но так как поток у нас может приходить неравномерно, сначала клик, то мы должны его отложить до момента, пока мы не увидим показ и не примем вердикт на его основе.
Язык описания фич
Расскажу немного про язык описания всего этого.
Можно не вчитываться, это для примера. Начинали с трех основных компонент. Первое — описание единиц данных в истории, вообще говоря, произвольного типа. Это какая-то фича, nullable-число. И какое-то правило. Что мы называем правилом? Это набор условий на этих фичах и что-то еще. Было у нас три отдельных файла. Проблема в том, что тут одна цепочка действий разнесена по разным файлам. С нашей системой нужно работать большому количеству аналитиков. Им было неудобно.
Язык получается императивный: мы описываем, как посчитать данные, а не декларативный, когда мы бы описывали бы, что нам нужно посчитать. Это тоже не очень удобно, достаточно легко допустить ошибку и высокий порог входа. Новые люди приходят, но не совсем понимают, как с этим вообще работать.
Решение — давайте сделаем свой DSL. Он более понятно описывает наш сценарий, он проще для новых людей, он более высокоуровневый. Вдохновение мы брали у SQLAlchemy, C# Linq и подобного.
Приведу пару примеров, аналогичных тем, которые я приводил выше.
Процент прочитанных детективов. Мы считаем количество прочитанных книг, то есть группируем по пользователю. К этому условию мы добавляем фильтрацию и, если мы хотим посчитать итоговый процент, просто считаем рейтинг. Все просто, понятно и интуитивно. Если мы считаем количество различных авторов, то делаем группировку по пользователю, задаем distinct авторов. К этому можем добавить какие-нибудь условия, например окно расчета или лимит на количество значений, которые мы храним из-за ограничения памяти. В итоге считаем count, количество ключей в нем. Или средняя лояльность, про которую я говорил. То есть опять же, у нас посчитано сверху какое-то выражение. Мы группируем по автору и задаем какое-то среднее значение среди этих выражений. Потом сужаем это обратно к пользователю. К этому мы потом можем добавить условие фильтрации. То есть фильтр у нас может быть, например, таким: лояльность не слишком высокая и количество процентов детективов — между 80 из 100. Что мы для этого используем под капотом?
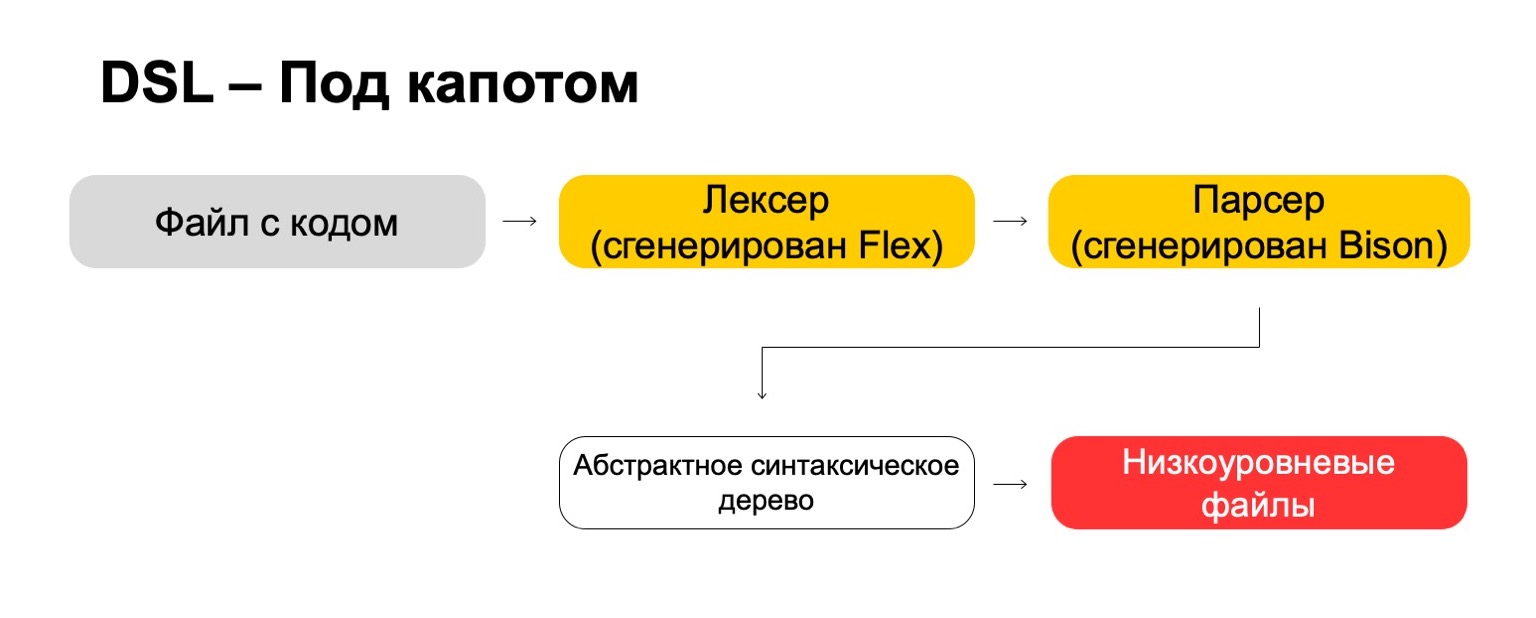
Под капотом мы используем самые современные технологии, напрямую из 70-х годов, такие как Flex, Bison. Может быть, слышали. Они генерируют код. У нас файл с кодом проходит через наш лексер, который сгенерирован во Flex, и через парсер, который сгенерирован в Bison. Лексер генерирует терминальные символы или слова в языке, парсер генерирует синтаксические выражения. Из этого мы получаем абстрактное синтаксическое дерево, с которым уже можем делать преобразования. И в итоге превращаем это в низкоуровневые файлы, которые понимает система.
Что в итоге? Это сложнее, чем может показаться с первого взгляда. Нужно потратить много ресурсов, продумать такие мелочи, как приоритеты операций, крайние случаи и подобное. Нужно изучить редкие технологии, которые вряд ли вам пригодятся в реальной жизни, если вы не пишете компиляторы, конечно. Но в итоге это того стоит. То есть если у вас, как и у нас, большое количество аналитиков, которые часто приходят их других команд, то в итоге это дает существенное преимущество, потому что им становится проще работать.
Надежность
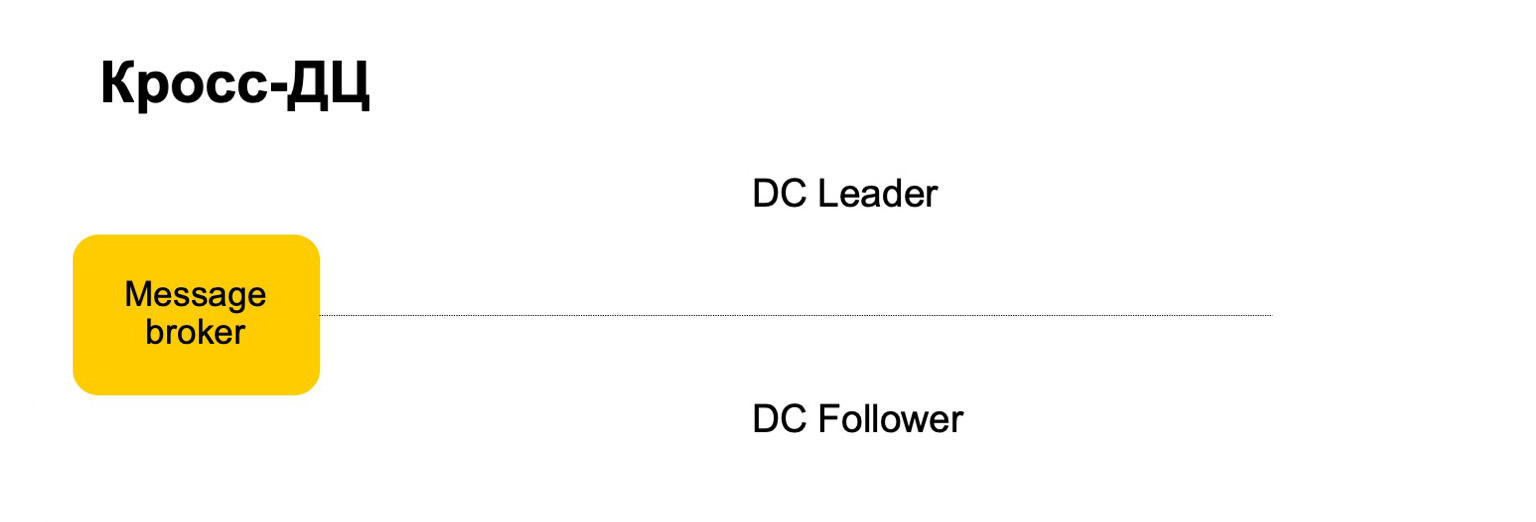
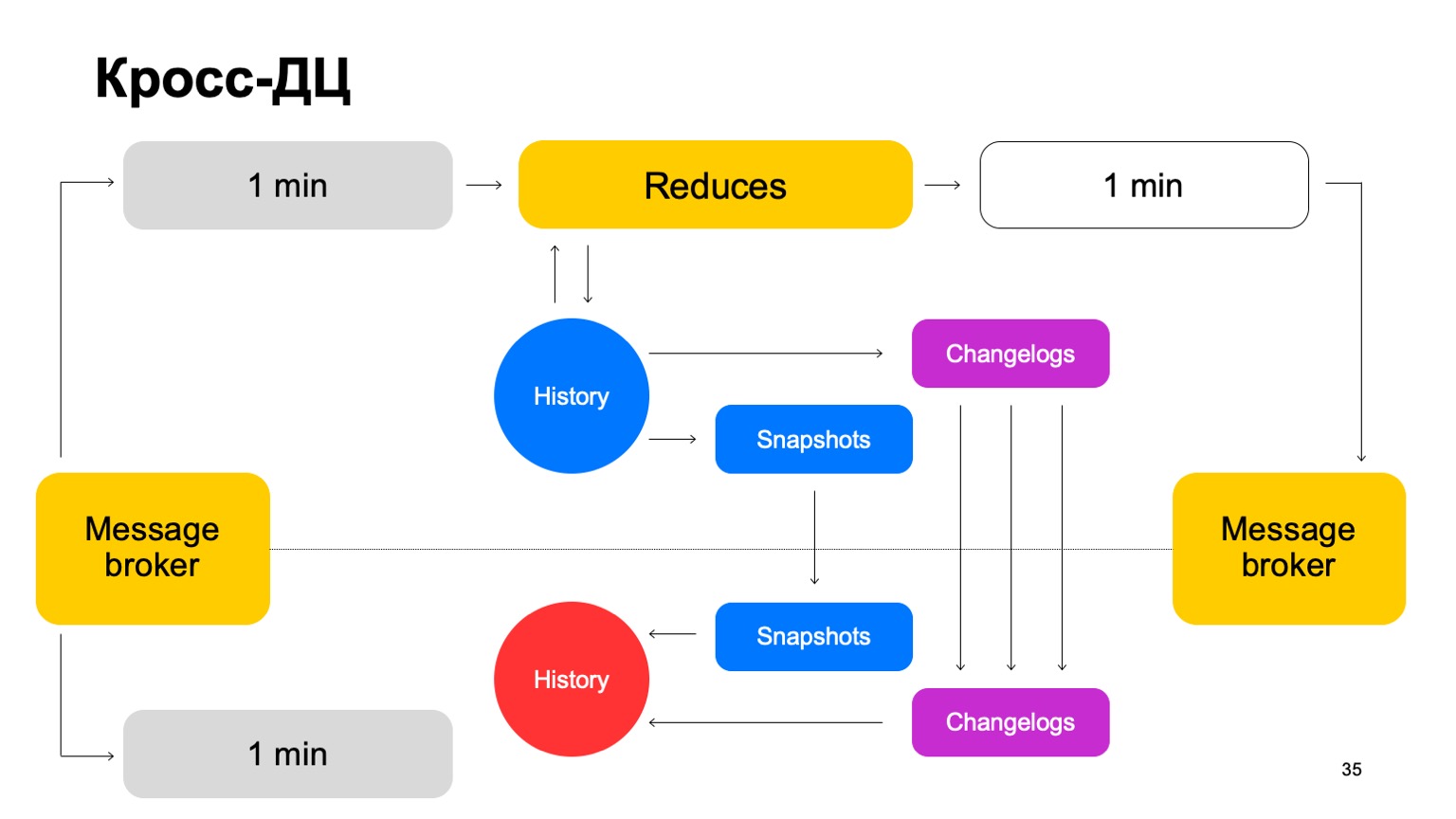
Некоторые сервисы требуют отказоустойчивости: кросс-ДЦ и exactly-once-обработку. Нарушение может вызывать расхождение статистик и потери, в том числе денежные. Наше решение для MapReduce такое, что мы считаем данные в каждый момент времени только на одном кластере и синхронизируем их на второй.
Например, как бы мы вели себя здесь? Есть лидер, follower и message broker. Можно считать, что это условная кафка, хотя тут, конечно, собственная реализация. Мы доставляем наши батчи на оба кластера, запускаем на одном в лидере набор редьюсов, принимаем итоговые вердикты, обновляем историю и передаем результаты обратно сервису в message broker. Раз в какое-то время мы, естественно, должны сделать репликацию. То есть мы собираем снапшоты, собираем ченжлоги — изменения за каждый батч. И то, и то синхронизируем на второй кластер follower. И также поднимаем историю, которая находится в таком горячем состоянии. Напомню, что история здесь хранится в памяти.
Таким образом, если один ДЦ почему-то становится недоступен, мы можем достаточно быстро, с минимальным лагом, переключиться на второй кластер.
Почему бы вообще не считать на двух кластерах параллельно? Внешние данные могут отличаться на двух кластерах, поставлять их могут внешние сервисы. Что вообще такое внешние данные? Это что-то, что с вот этого более высокого уровня поднимается. То есть сложные кластеризации и подобное. Либо просто вспомогательные для расчетов данные.
Нам нужно согласованное решение. Если мы будем параллельно считать вердикты с использованием разных данных и периодически переключаться между результатами из двух разных кластеров, согласованность между ними будет сильно падать. И, конечно же, экономия ресурсов. Так как мы в каждый момент времени используем ресурсы CPU только на одном кластере.
А что со вторым кластером? Когда мы работаем, он практически простаивает. Давайте использовать его ресурсы для полноценного препрода. Под полноценным препродом я тут подразумеваю полноценную инсталляцию, которая принимает тот же поток данных, работает с теми же объемами данных и т. д.
В случае недоступности кластера мы меняем эти инсталляции с прода на препрод. Таким образом, препрод у нас какое-то время лежит, но ничего страшного. Преимущество — мы можем на препроде считать больше фичей. Почему это вообще нужно? Потому что понятно, что если мы хотим большой объем фич считать, то нам часто не нужно все их считать на проде. Там мы считаем только то, что нужно для получения итоговых вердиктов.
(00:25:12)
Но при этом на препроде у нас как бы горячий кэш, большой, с самыми разнообразными фичами. В случае атаки мы можем его использовать для закрытия проблемы и переноса этих фич на прод.
К этому добавляются преимущества B2B-тестирования. То есть мы все выкатываем, естественно, сначала на препрод. Полностью сравниваем любые отличия, и, таким образом, не ошибемся, минимизируем вероятность, что мы можем ошибиться при выкатке на прод.
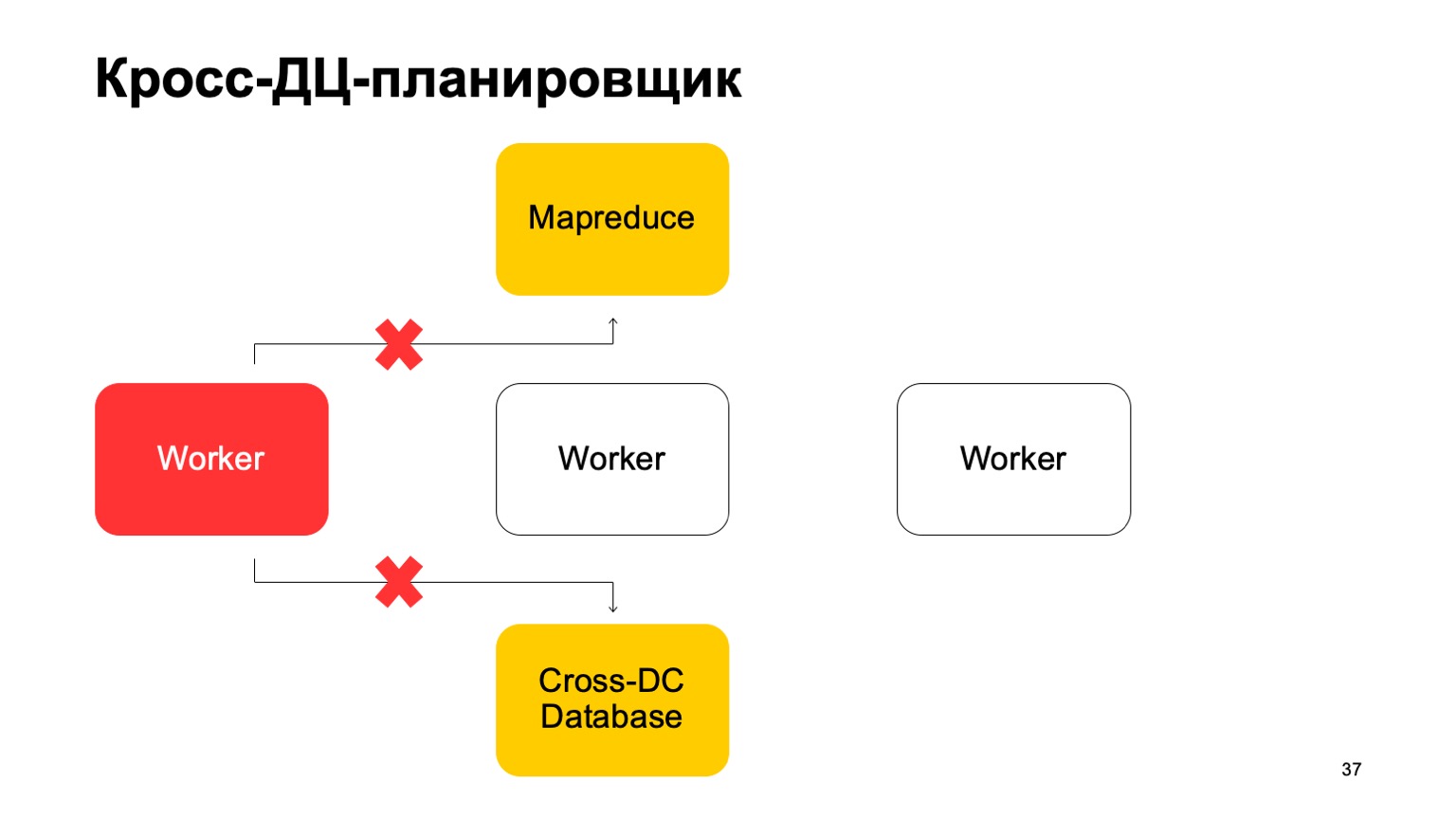
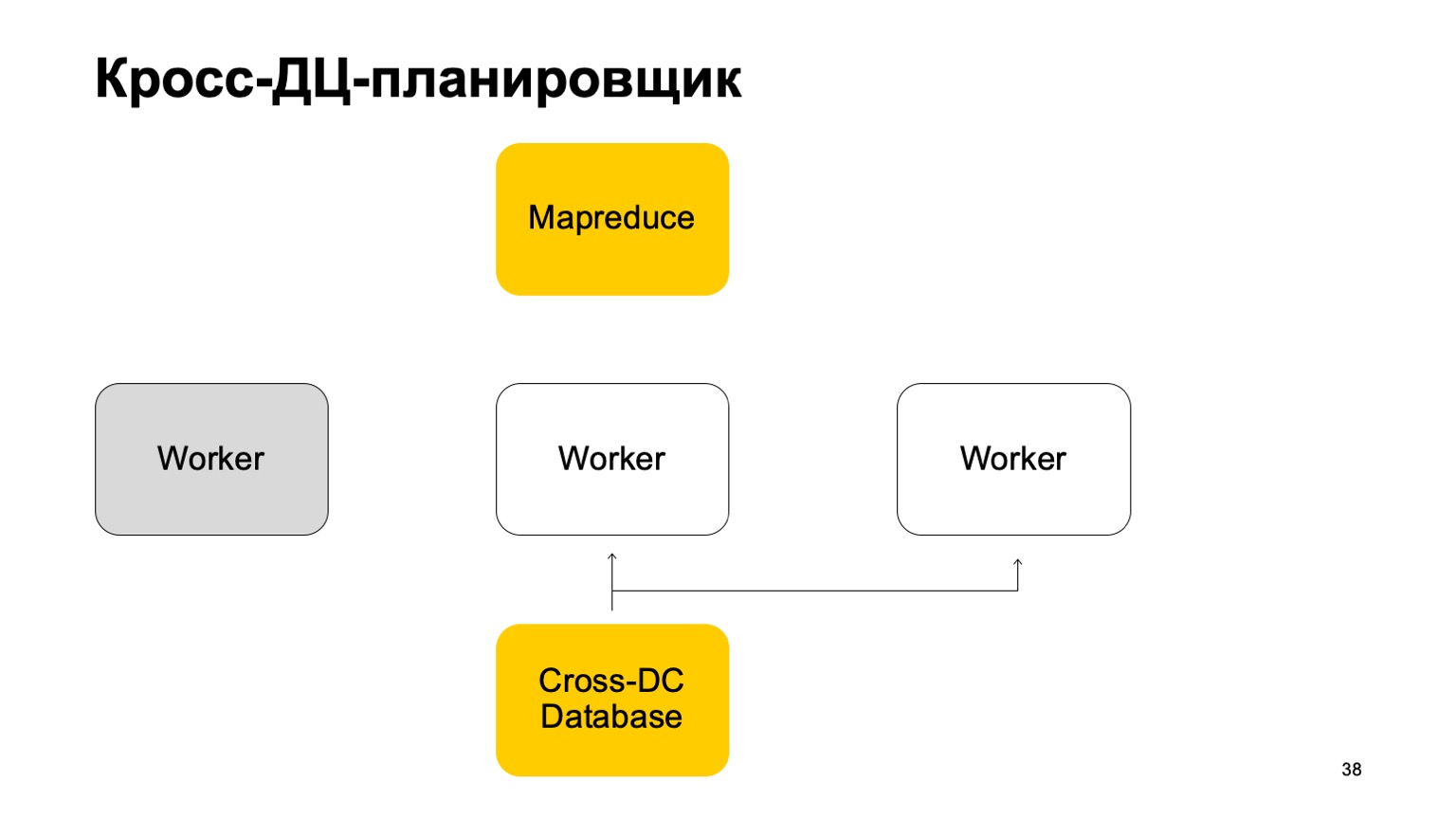
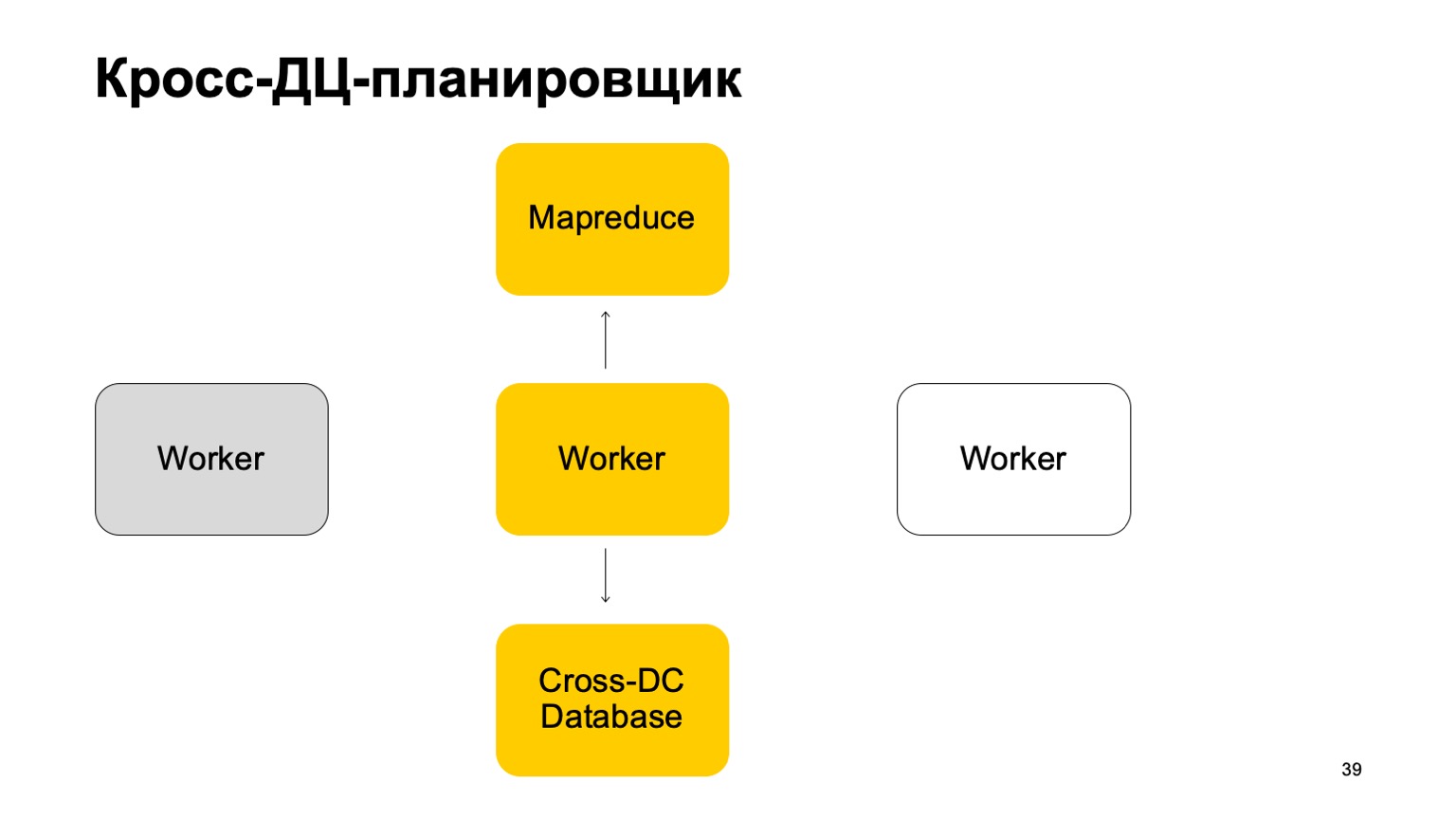
Немного про планировщик. Понятно, что у нас есть какие-то машины, которые запускают задачу в MapReduce. Это некие воркеры. Они регулярно синхронизируют свои данные в Cross-DC Database. Это просто состояние того, что они успели посчитать на данный момент.
Если воркер становится недоступен, то другой воркер пытается захватить лог, забрать состояние. Переподняться с него и продолжить работу. Продолжить ставить задачи на этом MapReduce. Понятно, что в случае переподнятия этих задач, некоторое множество из них может перезапуститься. Поэтому здесь есть очень важное свойство для нас: идемпотентность, возможность перезапускать каждую операцию без последствий. То есть весь код должен быть написан так, чтобы это нормально работало.
Немножко расскажу про exactly-once. Мы выносим вердикт согласованно, это очень важно. Используем технологии, которые дают нам такие гарантии, и мониторим, естественно, все расхождения, сводим их к нулю. Даже когда кажется, что это уже сведено, периодически возникает очень хитрая проблема, которую мы не учли.
Инструменты
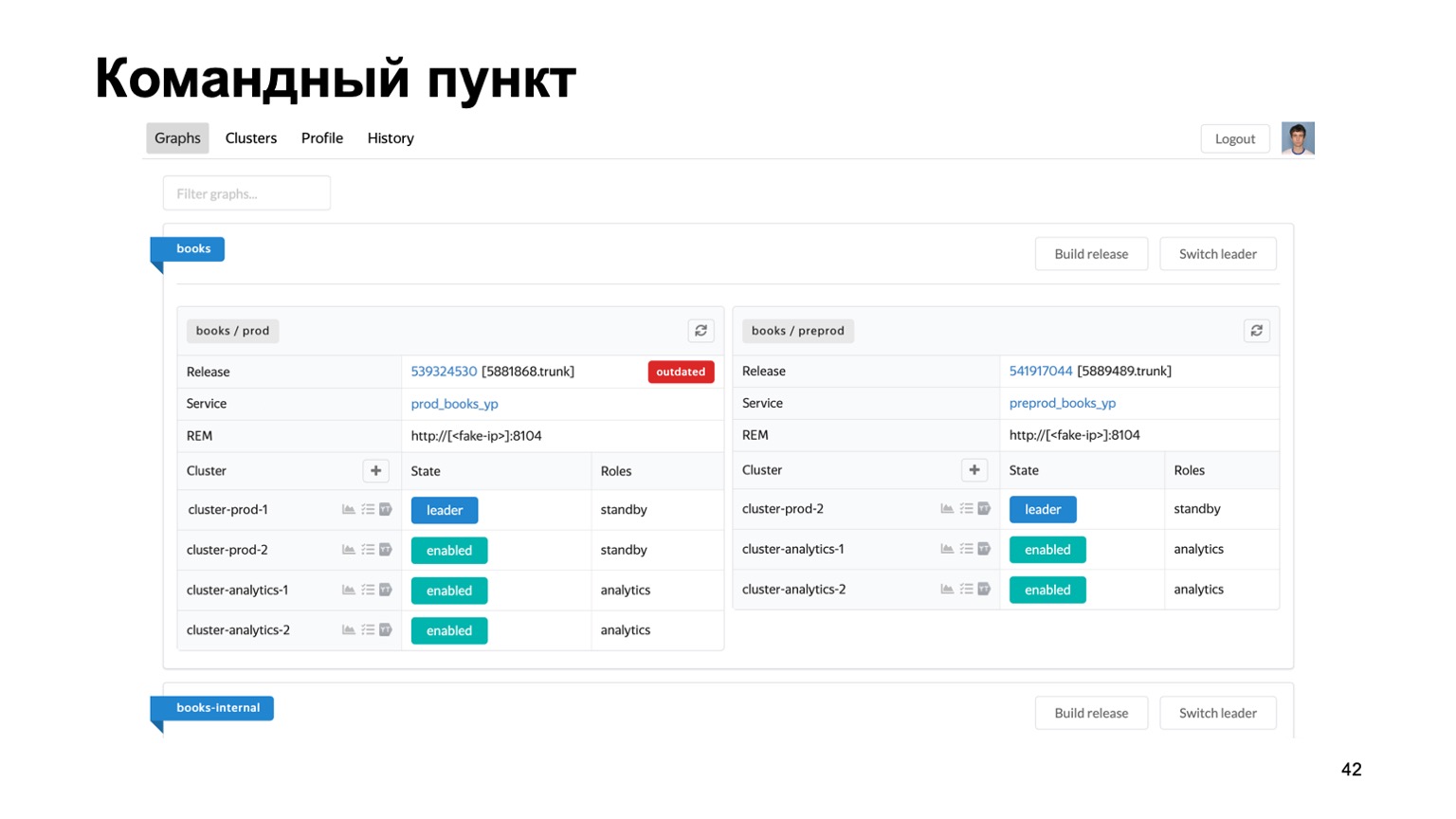
Очень кратко про инструменты, которые мы используем. Поддержка множества антифродов для разных систем — сложная задача. У нас буквально десятки разных сервисов, нужно какое-то единое место, где видно состояние их работы в данный момент.
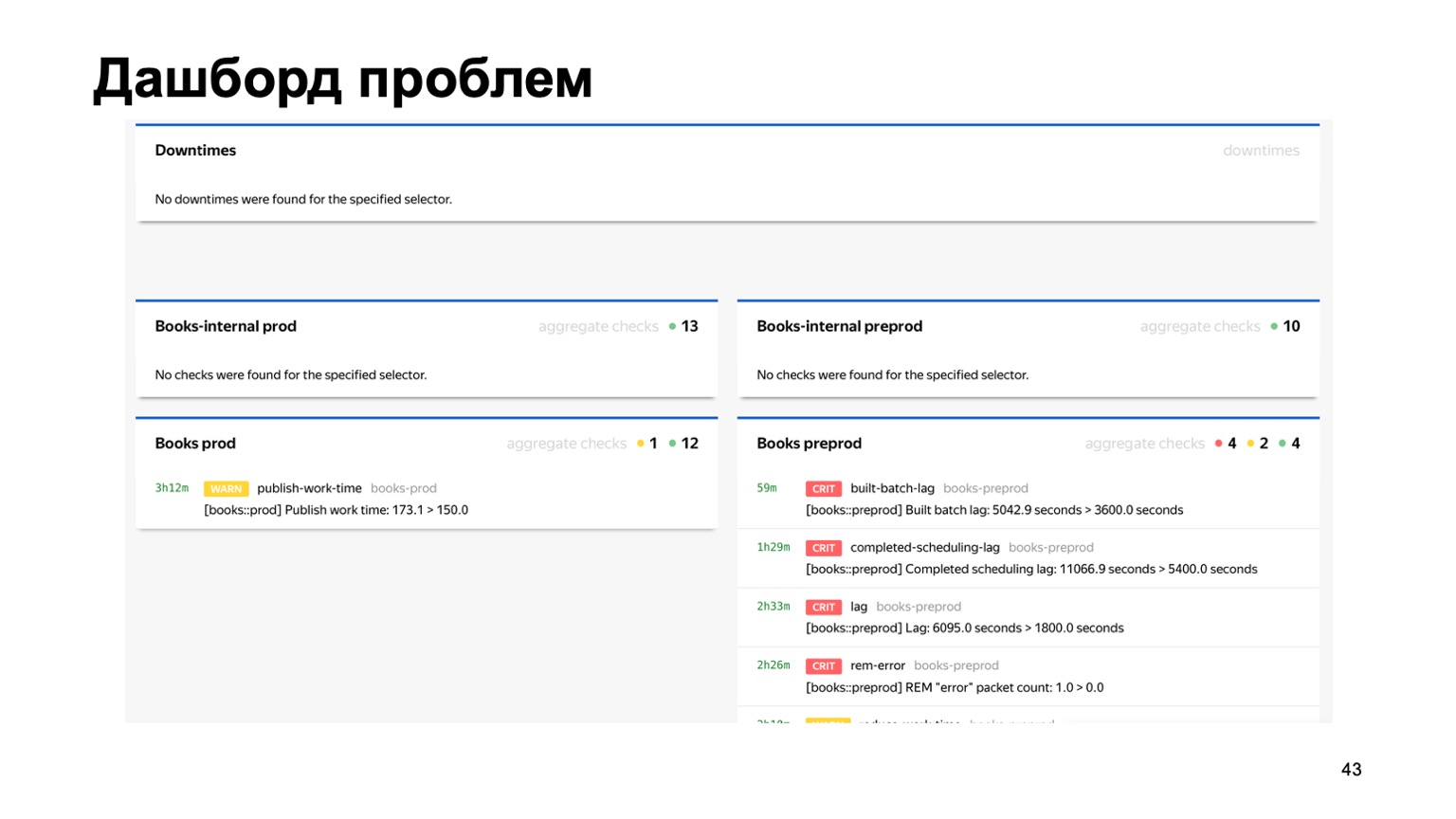
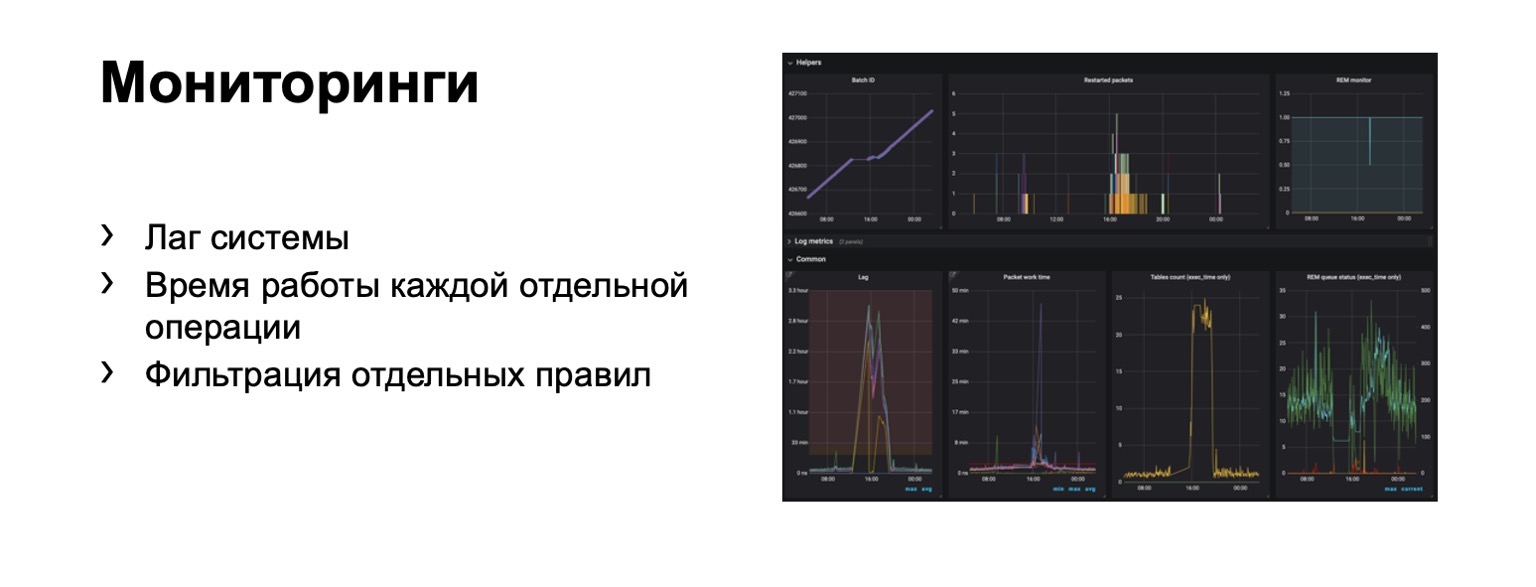
Вот наш командный пункт, где можно видеть состояние кластеров, с которыми мы сейчас работаем. Можно переключить их между собой, выкатить релиз и т. д. Или, например, дашборд проблем, где мы сразу на одной странице видим все проблемы всех антифродов разных сервисов, которые к нам подключены. Здесь видно, что на препроде у нашего сервиса Книги сейчас явно что-то не так. Но сработает мониторинг, и дежурный будет на это смотреть. Что мы вообще мониторим? Очевидно, лаг системы крайне важен. Очевидно, время работы каждой отдельной стадии и, конечно же, фильтрация отдельных правил. Это бизнесовое требование. Возникают сотни графиков, дашборды. Например, на этом дашборде видно, что контуру сейчас было достаточно плохо, что мы набрали существенный лаг.
Скорость
Расскажу про переход в онлайн-часть. Тут проблема в том, что лаг в полноценном контуре может достигать единиц минут. Это в контуре на MapReduce. В некоторых случаях нам нужно банить, обнаруживать мошенников быстрее.
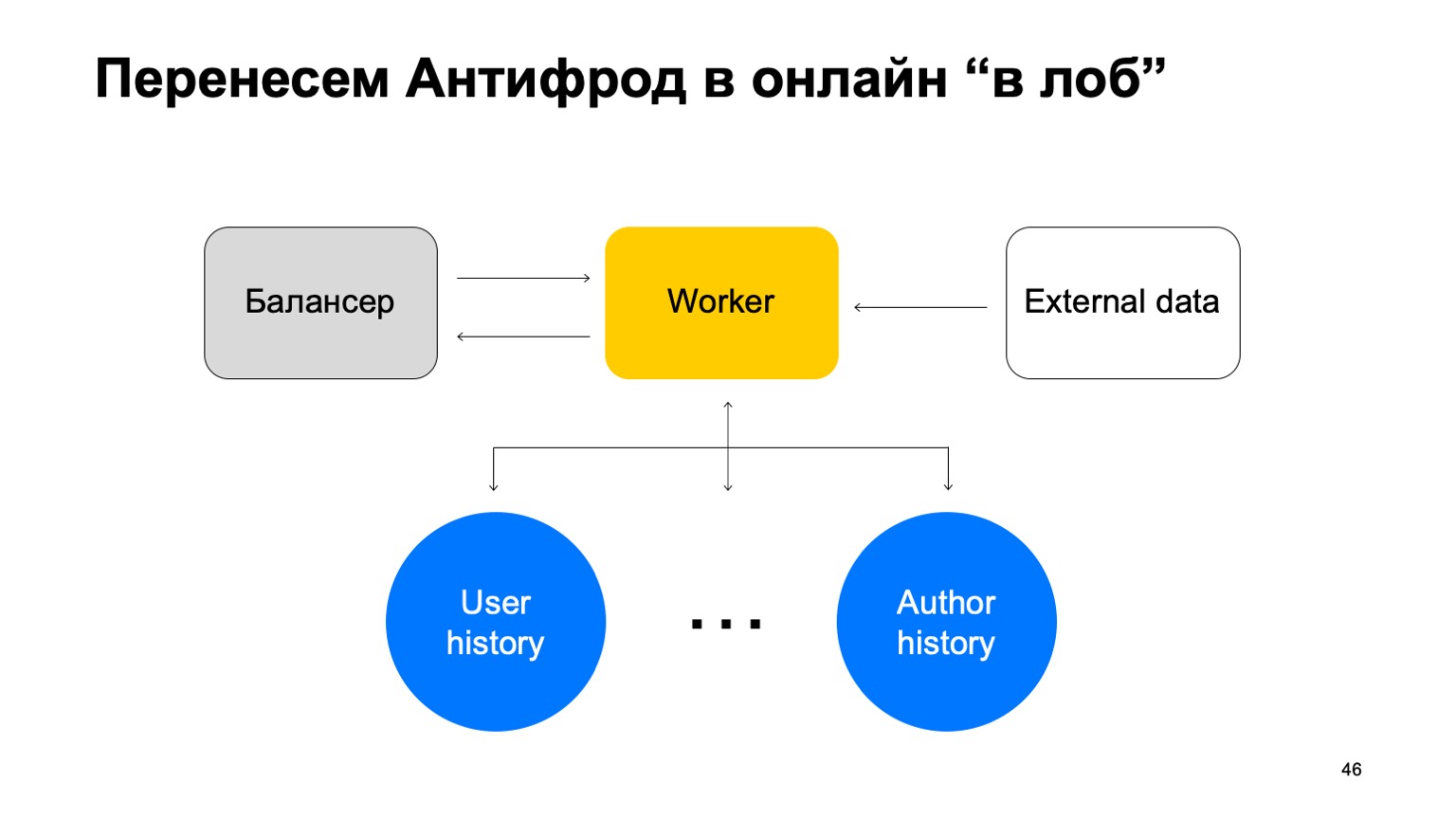
Что это может быть? Например, в нашем сервисе появилась возможность покупать книги. И вместе с тем появился новый вид платежного фрода. На него нужно реагировать быстрее. Возникает вопрос — как перенести всю эту схему, в идеале максимально сохраняя привычный для аналитиков язык взаимодействия? Попробуем перенести его «в лоб».
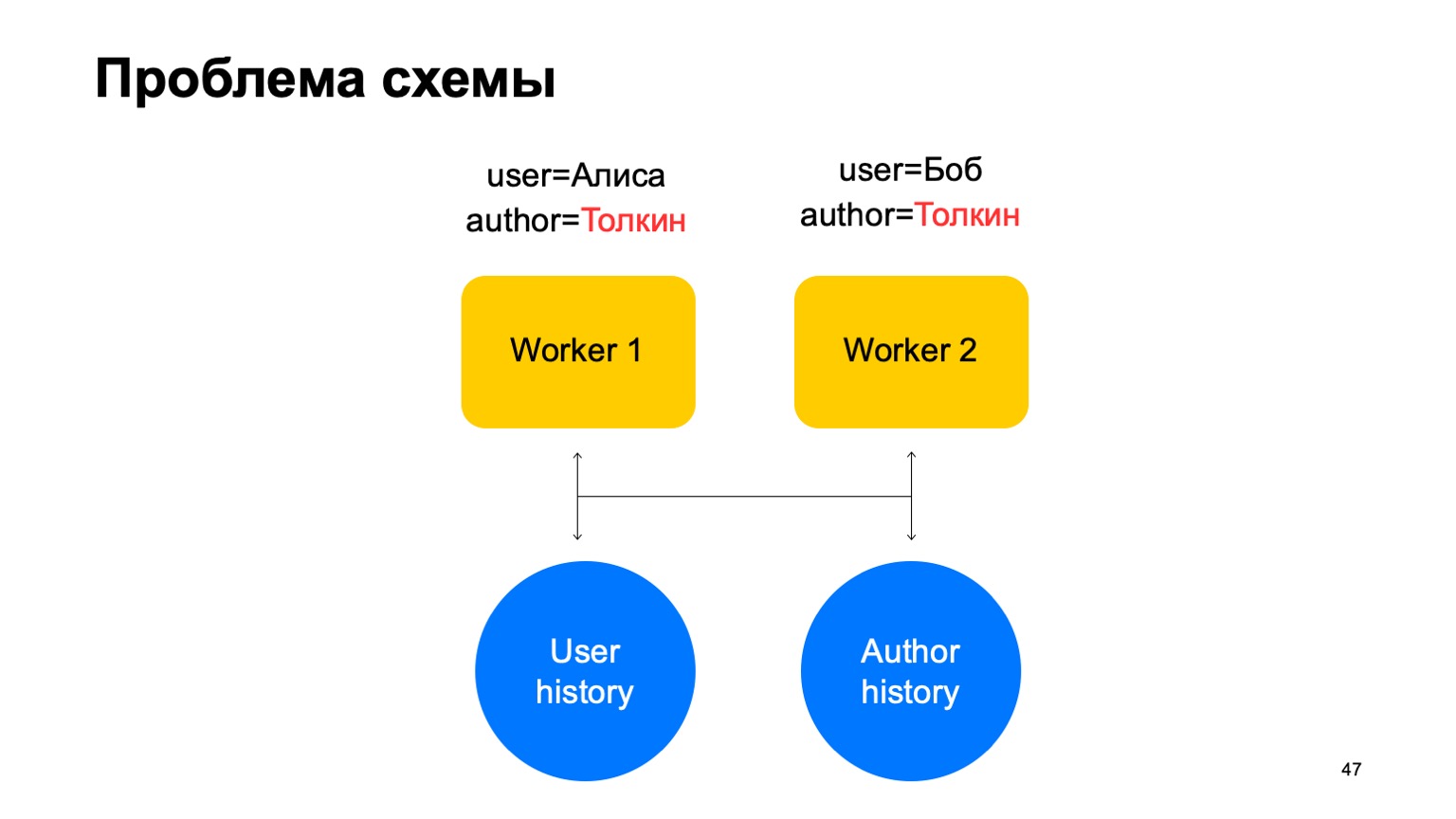
Допустим, у нас есть балансер с данными от сервиса и какое-то количество воркеров, на которые мы шардируем данные от балансера. Есть внешние данные, которые мы здесь используем, они очень важны, и набор вот этих историй. Напомню, что каждая такая история у нас разная для разных редьюсов, потому что в ней разные ключи. В такой схеме может возникнуть следующая проблема.
Допустим, у нас на воркер пришло два события. В таком случае у нас при любом шардировании этих воркеров может возникнуть ситуация, когда один ключ попадет на разные воркеры. В данном случае это автор Толкин, он попал на два воркера. Тогда мы из этого key-value storage считаем данные на оба воркера из истории, мы его обновим по-разному и возникнет гонка при попытке записать обратно.
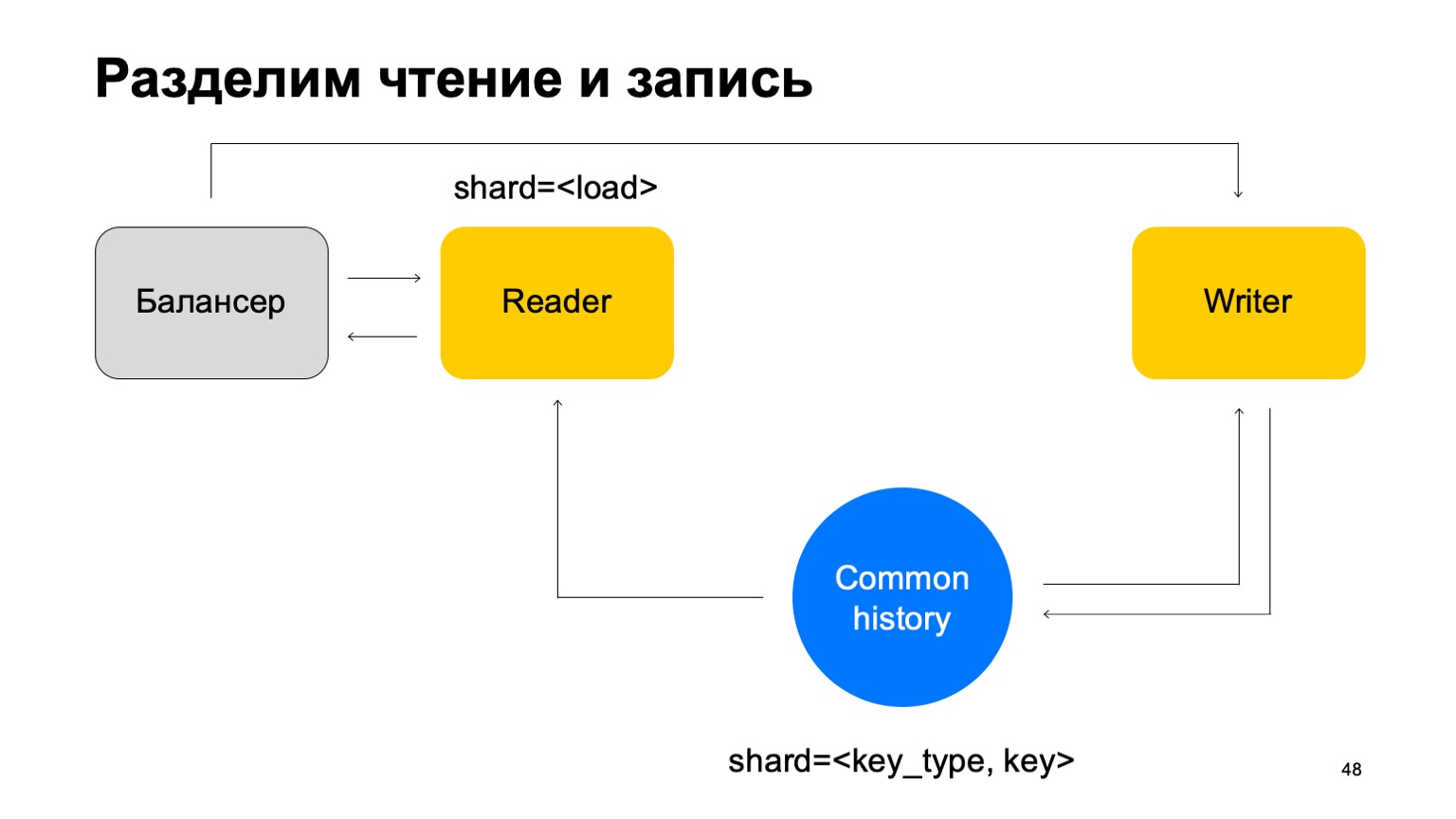
Решение: давайте сделаем предположение, что можно разделить чтение и запись, что запись может происходить с небольшой задержкой. Обычно это не сильно важно. Под небольшой задержкой я здесь подразумеваю единицы секунд. Это важно, в частности, по той причине, что наша реализация этой key-value store занимает больше времени на запись данных, чем на чтение.
Будем обновлять статистики с отставанием. В среднем это работает более-менее хорошо, с учетом того, что мы будем хранить на машинах кэшированное состояние.
И другая вещь. Для простоты сольем вот эти истории в одну и пошардируем ее по типу и по ключу разреза. У нас есть какая-то единая история. Тогда мы вновь добавим балансер, добавим машины читателей, которые могут быть пошардированы как угодно — например, просто по нагрузке. Они будут просто читать эти данные, принимать итоговые вердикты и возвращать их балансеру.
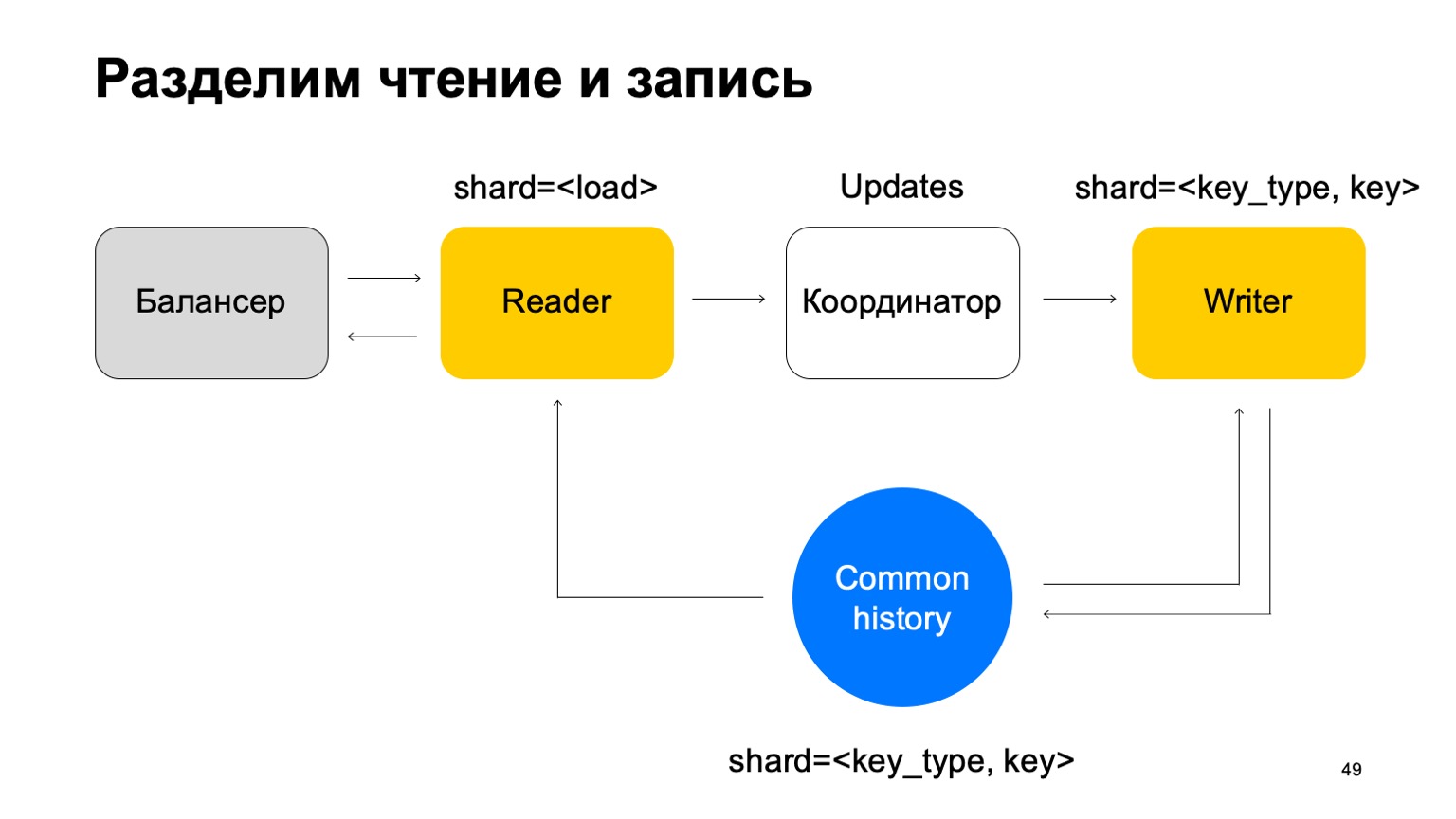
В таком случае нам нужен набор машин писателей, которым напрямую будут отправляться эти данные. Писатели будут, соответственно, обновлять историю. Но тут все еще возникает проблема, о которой я писал выше. Давайте тогда немного изменим структуру писателя.
Сделаем так, чтобы он был пошардирован одинаково с историей — по типу и значению ключа. В таком случае, когда его шардирование такое же, как история, у нас не возникнет проблемы, о которой я говорил выше. Здесь у него меняется его предназначение. Он больше не принимает вердикты. Вместо этого он просто принимает updates из Reader, смешивает их и правильно применяет к истории.
Понятно, что здесь нужна компонента, координатор, которая распределяет эти updates между ридерами и райтерами.
К этому, конечно, добавляется то, что в воркере нужно поддерживать актуальный кэш. В итоге получается, что мы отвечаем за сотни миллисекунд, иногда меньше, и обновляем статистики за секунду. В целом это работает хорошо, для сервисов этого достаточно.
Что мы вообще получили? Аналитики стали делать работу быстрее и одинаково для всех сервисов. Это повысило качество и связанность всех систем. Можно переиспользовать данные между антифродами разных сервисов, а новые сервисы получают качественный антифрод быстро. Пара мыслей в конце. Если вы будете писать нечто подобное, сразу подумайте про удобство аналитиков в части поддержки и расширяемости данных систем. Делайте конфигурируемым все что можно, это вам понадобится. Иногда свойств кросс-ДЦ и exactly-once бывает сложно достичь, но можно. Если вам кажется, что уже достигли, — перепроверьте. Спасибо за внимание.