
Основы разработки признаков
Разработка признаков означает создание дополнительных признаков из существующих данных, которые часто распределяются по нескольким связанным таблицам. Разработка признаков требует извлечения соответствующей информации из данных и помещения ее в единую таблицу, которую затем можно использовать для обучения модели машинного обучения. Процесс создания признаков очень трудоемкий, поскольку для создания каждой нового признака обычно требуется несколько шагов, особенно при использовании информации из нескольких таблиц. Мы можем сгруппировать операции создания признаков в две категории: преобразования и агрегации. Давайте рассмотрим несколько примеров, чтобы увидеть эти концепции в действии.
Преобразование действует на одну таблицу (в терминах Python, таблица представляет собой просто Pandas DataFrame), создавая новые признаки из одного или нескольких существующих столбцов. Например, если у нас есть таблица клиентов ниже,
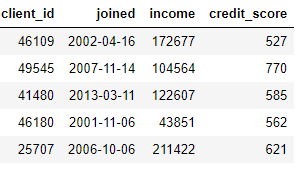
joined или взяв натуральный логарифм из столбца income. Это оба преобразования, потому что они используют информацию только из одной таблицы.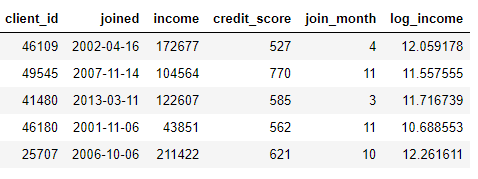
Этот процесс включает в себя группирование таблицы loans по клиенту, вычисление агрегации и последующее объединение полученных данных с данными клиента. Вот как мы могли бы сделать это в Python, используя язык Pandas.
import pandas as pd # Group loans by client id and calculate mean, max, min of loans stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min']) stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount'] # Merge with the clients dataframe stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left') stats.head(10)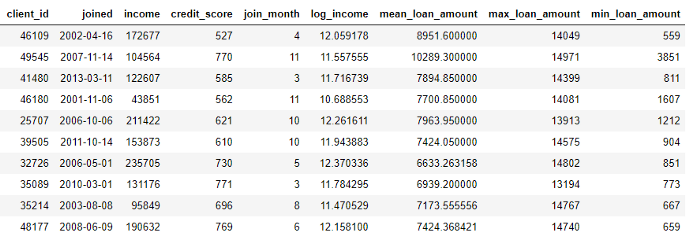
Featuretools
К счастью, featuretools — это именно то решение, которое мы ищем. Эта библиотека для Python с открытым исходным кодом автоматически создает множество признаков из набора связанных таблиц. Featuretools основан на методе, известном как «Deep Feature Synthesis», который звучит гораздо более впечатляюще, чем на самом деле (название происходит от объединения нескольких признаков, а не потому, что он использует глубокое обучение!). Глубокий синтез признаков объединяет несколько операций преобразования и агрегирования (которые называются примитивами признаков в словаре FeatureTools) для создания признаков из данных, распределенных по многим таблицам. Как и большинство идей в области машинного обучения, это сложный метод, основанный на простых понятиях. Изучая один строительный блок за один раз, мы можем сформировать хорошее понимание этого мощного метода. Во-первых, давайте посмотрим на данные из нашего примера. Мы уже видели что-то из набора данных выше, и полный набор таблиц выглядит следующим образом:
clients: базовая информация о клиентах в кредитном объединении. Каждый клиент имеет только одну строку в этом фрейме данных
loans: кредиты, предоставленные клиентам. Каждый кредит имеет только собственную строку в этом фрейме данных, но клиенты могут иметь несколько кредитов.
payments: платежи по кредитам. Каждый платеж имеет только одну строку, но каждый заем будет иметь несколько платежей.
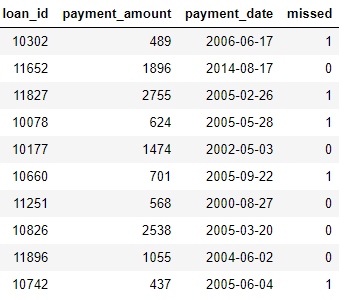
Если у нас есть задача для машинного обучения, такая как прогнозирование того, будет ли клиент погашать будущий кредит, мы захотим объединить всю информацию о клиентах в одну таблицу. Таблицы связаны (через переменные
client_id и loan_id), и мы могли бы использовать серию преобразований и агрегаций, чтобы выполнить этот процесс вручную. Однако вскоре мы увидим, что вместо этого мы можем использовать featuretools для автоматизации процесса.Entities и EntitySets (сущности и наборы сущностей)
Первые две концепции featuretools — это entities и entitysets. Entity — это просто таблица (или DataFrame, если вы думаете в Pandas). EntitySet — это набор таблиц и взаимосвязей между ними. Представьте, что entityset — это просто еще одна структура данных Python со своими собственными методами и атрибутами. Мы можем создать пустой набор сущностей в featuretools, используя следующее:
import featuretools as ft # Create new entityset es = ft.EntitySet(id = 'clients')Теперь мы должны добавить сущности. Каждая сущность должна иметь индекс, который является столбцом со всеми уникальными элементами. То есть каждое значение в индексе должно появляться в таблице только один раз. Индексом во фрейме данных
clients является client_id, потому что у каждого клиента есть только одна строка в этом фрейме данных. Мы добавляем сущность с существующим индексом в набор сущностей, используя следующий синтаксис:# Create an entity from the client dataframe # This dataframe already has an index and a time index es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients, index = 'client_id', time_index = 'joined')Фрейм данных
loans также имеет уникальный индекс loan_id, и синтаксис для добавления его к набору сущностей такой же, как и для clients. Однако для фрейма данных платежей нет уникального индекса. Когда мы добавляем эту сущность в набор сущностей, нам нужно передать параметр make_index = True и указать имя индекса. Кроме того, хотя featuretools будет автоматически выводить тип данных каждого столбца в сущносте, мы можем переопределить это, передав словарь типов столбцов параметру variable_types.# Create an entity from the payments dataframe # This does not yet have a unique index es = es.entity_from_dataframe(entity_id = 'payments', dataframe = payments, variable_types = {'missed': ft.variable_types.Categorical}, make_index = True, index = 'payment_id', time_index = 'payment_date')Для этого фрейма данных, несмотря на то, что
missed является целым числом, это не числовая переменная, так как она может принимать только 2 дискретных значения, поэтому мы говорим featuretools что следует рассматривать ее как категориальную переменную. После добавления фреймов данных в набор сущностей мы исследуем любую из них: 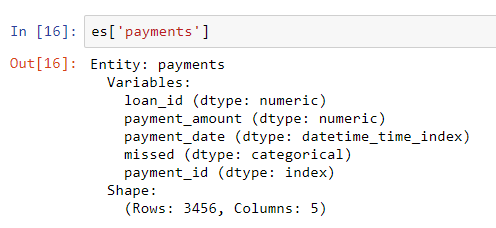
Связи между таблицами
Лучший способ представить отношение между двумя таблицами — это аналогия родителей и детей. Отношение один ко многим: у каждого родителя может быть несколько детей. В области таблиц родительская таблица имеет одну строку для каждого родителя, но дочерняя таблица может иметь несколько строк, соответствующих нескольким дочерним элементам одного и того же родителя. Например, в нашем наборе данных clients фрейм является родительским для loans фрейма. Каждый клиент имеет только одну строку в clients, но может иметь несколько строк в loans. Аналогично, loans являются родителями payments, потому что каждый заем будет иметь несколько платежей. Родители связаны со своими детьми общей переменной. Когда мы выполняем агрегирование, мы группируем дочернюю таблицу по родительской переменной и вычисляем статистику по дочерним элементам каждого родителя.
Чтобы формализовать отношения в featuretools, нам нужно только указать переменную, которая связывает две таблицы вместе. clients и таблица loans связаны с помощью переменной client_id, а loans и payments — с помощью loan_id. Синтаксис для создания отношения и добавления его в набор сущностей показан ниже:
# Relationship between clients and previous loans r_client_previous = ft.Relationship(es['clients']['client_id'], es['loans']['client_id']) # Add the relationship to the entity set es = es.add_relationship(r_client_previous) # Relationship between previous loans and previous payments r_payments = ft.Relationship(es['loans']['loan_id'], es['payments']['loan_id']) # Add the relationship to the entity set es = es.add_relationship(r_payments) es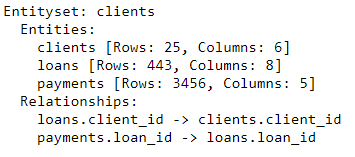
Примитивы признаков
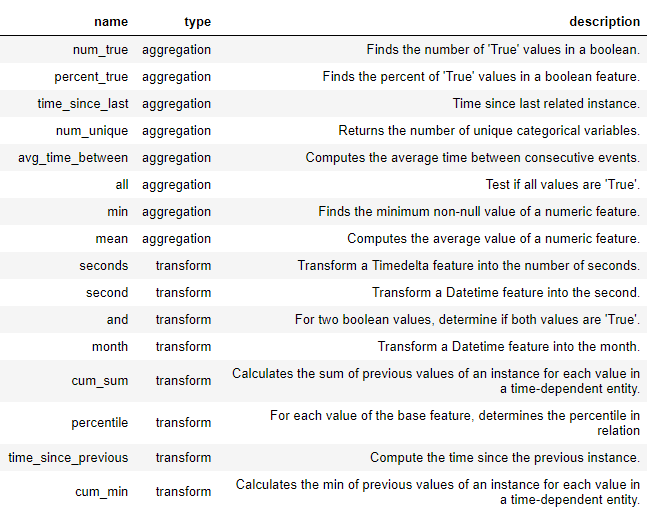
Прежде чем мы сможем полностью перейти к глубокому синтезу признаков, нам нужно понять примитивы признаков. Мы уже знаем, что это такое, но мы просто называем их разными именами! Это просто основные операции, которые мы используем для формирования новых признаков:
- Агрегации: операции, выполненные в отношении «родитель-ребенок» (один-ко-многим), которые группируются по родителям и рассчитывают статистику по детям. Примером является группировка таблицы
loansпоclient_idи определение максимальной суммы кредита для каждого клиента. - Преобразования: операции, выполняемые с одной таблицы в один или несколько столбцов. В качестве примера берется разница между двумя столбцами в одной таблице или абсолютное значение столбца.
Новые признаки создаются в featuretools, используя эти примитивы, либо сами по себе, либо в виде нескольких примитивов. Ниже приведен список некоторых примитивов в featuretools (мы также можем определить кастомные примитивы):
ft.dfs (расшифровывается как глубокий синтез признаков). Мы передаем набор сущностей target_entity, который представляет собой таблицу, в которую мы хотим добавить признаки, выбранные trans_primitives (преобразования) и agg_primitives (агрегаты):# Create new features using specified primitives features, feature_names = ft.dfs(entityset = es, target_entity = 'clients', agg_primitives = ['mean', 'max', 'percent_true', 'last'], trans_primitives = ['years', 'month', 'subtract', 'divide'])Результатом является датафрейм новых признаков для каждого клиента (потому что мы сделали клиентов
target_entity). Например, у нас есть месяц, в котором присоединился каждый клиент, который является примитивом преобразования: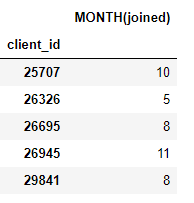
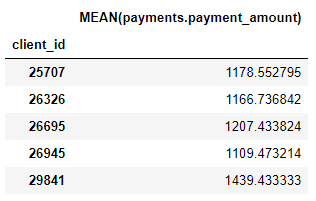
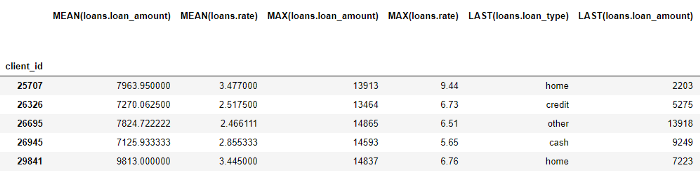
Глубокий Синтез Признаков
Теперь у нас есть все для понимания глубокого синтеза признаков (dfs). Фактически, мы уже выполняли dfs в предыдущем вызове функции! Глубокий признак — это просто признак, состоящий из объединения нескольких примитивов, а dfs — это имя процесса, который создает эти признаки. Глубина глубокого признака — это количество примитивов, необходимых для создания признака.
Например, столбец MEAN (payment.payment_amount) представляет собой глубокий признак с глубиной 1, поскольку он был создан с использованием одной агрегации. Элемент с глубиной два — это LAST(loans(MEAN(payment.payment_amount)). Это делается путем объединения двух агрегаций: LAST (самая последняя) поверх MEAN. Это представляет средний размер платежа по самому последнему кредиту для каждого клиента.
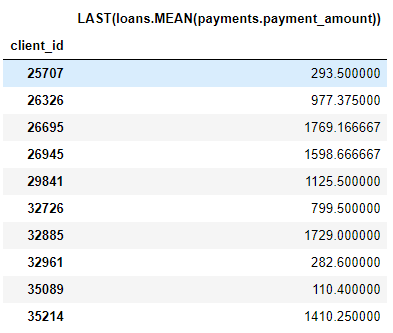
ft.dfs, но не передаем никакие примитивы:# Perform deep feature synthesis without specifying primitives features, feature_names = ft.dfs(entityset=es, target_entity='clients', max_depth = 2) features.head()
Следующие шаги
Автоматизированное проектирование признаков решило одну проблему, но создало другую: слишком много признаков. Хотя до подбора модели сложно сказать, какие из этих признаков будут важны, скорее всего, не все из них будут иметь отношение к задаче, на которой мы хотим обучать нашу модель. Более того, слишком большое количество признаков может привести к снижению производительности модели, поскольку менее полезные признаки вытесняют те, которые являются более важными. Проблема слишком многих признаков известна как проклятие размерности. По мере увеличения числа признаков (размерность данных) модели становится все труднее изучать соответствие между признаками и целями. Фактически, объем данных, необходимых для хорошей работы модели, масштабируется экспоненциально с количеством признаков. Проклятие размерности сочетается с сокращением признаков (также известным как выбор признаков): процессом удаления ненужных признаков. Это может принимать различные формы: Principal Component Analysis (PCA), SelectKBest, использование значений признаков из модели или автоматическое кодирование с использованием глубоких нейронных сетей. Однако сокращение признаков — это отдельная тема для другой статьи. На данный момент мы знаем, что мы можем использовать featuretools для создания множества признаков из множества таблиц с минимальными усилиями!
Вывод
Как и многие темы в машинном обучении, автоматизированное проектирование признаков с помощью featuretools — сложная концепция, основанная на простых идеях. Используя понятия наборов сущностей, сущностей и отношений, featuretools может выполнять глубокий синтез признаков для создания новых признаков. Глубокий синтез признаков, в свою очередь, объединяет примитивы — агрегаты, которые действуют через отношения «один ко многим» между таблицами, и преобразования, функции, применяемые к одному или нескольким столбцам в одной таблице, — для создания новых признаков из нескольких таблиц.