Я написал эту статью с оглядкой на Kubernetes для AWS, но она будет применима (почти) точно так же и для других облачных провайдеров. Я предполагаю, что ваш кластер(ы) уже имеет настроенное автоматическое масштабирование (cluster-autoscaler). Удаление ресурсов и уменьшение масштаба развертывания позволит сэкономить только в том случае, если это также сократит ваш парк рабочих узлов (EC2 инстансов). В этой статье будут рассмотрены:
- очистка неиспользуемых ресурсов (kube-janitor)
- уменьшение масштабирования в нерабочее время (kube-downscaler)
- использование горизонтального автомасштабирования (HPA),
- уменьшение избыточного резервирования ресурсов (kube-resource-report, VPA)
- использование Spot инстансов
Очистка неиспользуемых ресурсов
Работа в быстро меняющейся среде — это здорово. Мы хотим, чтобы технические организации ускорялись. Более быстрая доставка программного обеспечения также означает большее количество PR-развертываний, сред предварительного просмотра, прототипов и аналитических решений. Все разворачиваемое на Kubernetes. У кого есть время, чтобы чистить тестовые развертывания вручную? Легко забыть об удалении эксперимента недельной давности. Счет за облако в конечном итоге будет расти из-за того, что мы забыли закрыть:

(Хеннинг Джейкобс:
Жиза:
(цитирует) Кори Куинн:
Миф: Ваш AWS счет — это функция зависимости от количества ваших пользователей.
Факт: Ваш AWS счет — это функция зависимости от количества ваших инженеров.
Иван Курносов (в ответ):
Настоящий факт: Ваш AWS счет — это функция зависимости от количества вещей, которые вы забыли отключить/удалить.)
Kubernetes Janitor (kube-janitor) помогает очистить ваш кластер. Конфигурация janitor является гибкой как для глобального, так и для локального использования:
- Общие правила для всего кластера могут определять максимальное время жизни (TTL — time-to-live) для PR/тестовых развертываний.
- Отдельные ресурсы могут быть аннотированы с помощью janitor/ttl, например, для автоматического удаления spike/прототипа через 7 дней.
Общие правила определяются в YAML файле. Его путь передается через параметр
--rules-file в kube-janitor. Вот пример правила для удаления всех пространств имен с -pr- в имени через два дня:- id: cleanup-resources-from-pull-requests resources: - namespaces jmespath: "contains(metadata.name, '-pr-')" ttl: 2dСледующий пример регламентирует использования метки application на Deployment и StatefulSet подах для всех новых Deployments/StatefulSet в 2020 году, но в то же время позволяет выполнение тестов без этой метки в течении недели:
- id: require-application-label # удалить deployments и statefulsets без метки "application" resources: - deployments - statefulsets # см. http://jmespath.org/specification.html jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'" ttl: 7dЗапуск ограниченного по времени демо в течение 30 минут в кластере, где работает kube-janitor:
kubectl run nginx-demo --image=nginx kubectl annotate deploy nginx-demo janitor/ttl=30mЕще одним источником растущих затрат являются постоянные тома (AWS EBS). При удалении Kubernetes StatefulSet не удаляются его постоянные тома (PVC — PersistentVolumeClaim). Неиспользованные объемы EBS могут легко привести к затратам в сотни долларов в месяц. Kubernetes Janitor имеет функцию для очистки неиспользованных PVC. Например, это правило удалит все PVC, которые не смонтированы модулем и на которые не ссылается StatefulSet или CronJob:
# удалить все PVC, которые не смонтированы и на которые не ссылаются StatefulSets - id: remove-unused-pvcs resources: - persistentvolumeclaims jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced" ttl: 24hKubernetes Janitor может помочь вам сохранить ваш кластер в «чистоте» и предотвратить медленно накапливающиеся затраты на облачные вычисления. За инструкциями по развертыванию и настройке следуйте в README kube-janitor.
Уменьшение масштабирования в нерабочее время
Тестовые и промежуточные системы обычно требуются для работы только в рабочее время. Некоторые производственные приложения, такие как бэк-офис / инструменты администратора, также требуют лишь ограниченной доступности и могут быть отключены ночью.
Kubernetes Downscaler (kube-downscaler) позволяет пользователям и операторам уменьшать масштаб системы в нерабочее время. Deployments и StatefulSets можно масштабировать до нулевых реплик. CronJobs могут быть приостановлены. Kubernetes Downscaler настраивается для всего кластера, одного или нескольких пространств имен или отдельных ресурсов. Можно установить либо «время простоя», либо наоборт «время работы». Например, чтобы максимально уменьшить масштабирование в течение ночи и выходных:
image: hjacobs/kube-downscaler:20.4.3 args: - --interval=30 # не отключать компоненты инфраструктуры - --exclude-namespaces=kube-system,infra # не отключать kube-downscaler, а также оставить Postgres Operator, чтобы исключенными БД можно было управлять - --exclude-deployments=kube-downscaler,postgres-operator - --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin - --include-resources=deployments,statefulsets,stacks,cronjobs - --deployment-time-annotation=deployment-timeВот график масштабирования рабочих узлов кластера в выходные дни:

downscaler/force-uptime, например, путем запуска nginx болванки:kubectl run scale-up --image=nginx kubectl annotate deploy scale-up janitor/ttl=1h # удалить развертывание через час kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueСмотрите README kube-downscaler, если вас интересует инструкция по развертыванию и дополнительные опции.
Используйте горизонтальное автомасштабирование
Многие приложения/сервисы имеют дело с динамической схемой загрузки: иногда их модули простаивают, а иногда они работают на полную мощность. Работа с постоянным парком подов, чтобы справиться с максимальной пиковой нагрузкой, не экономична. Kubernetes поддерживает горизонтальное автоматическое масштабирование через ресурс HorizontalPodAutoscaler (HPA). Использование ЦП часто является хорошим показателем для масштабирования:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: my-app spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app minReplicas: 3 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: averageUtilization: 100 type: UtilizationZalando создал компонент для простого подключения пользовательских метрик для масштабирования: Kube Metrics Adapter (kube-metrics-adapter) — это универсальный адаптер метрик для Kubernetes, который может собирать и обслуживать пользовательские и внешние метрики для горизонтального автомасштабирования подов. Он поддерживает масштабирование на основе метрик Prometheus, очередей SQS и других настроек. Например, чтобы масштабировать развертывание для пользовательской метрики, представленной самим приложением в виде JSON в /metrics используйте:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: myapp-hpa annotations: # metric-config.<metricType>.<metricName>.<collectorName>/<configKey> metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps" metric-config.pods.requests-per-second.json-path/path: /metrics metric-config.pods.requests-per-second.json-path/port: "9090" spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: myapp minReplicas: 1 maxReplicas: 10 metrics: - type: Pods pods: metric: name: requests-per-second target: averageValue: 1k type: AverageValueНастройка горизонтального автомасштабирования с помощью HPA должна быть одним из действий по умолчанию для повышения эффективности для служб без учета состояния. У Spotify есть презентация с их опытом и рекомендациями для HPA: масштабируйте свои развертывания, а не свой кошелек.
Уменьшение избыточного резервирования ресурсов
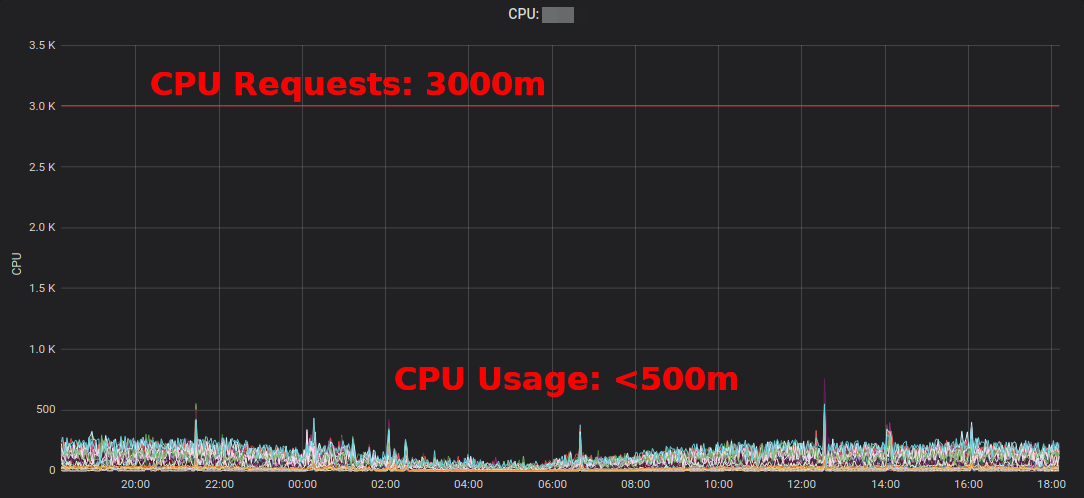
Рабочие нагрузки Kubernetes определяют их потребности в ЦП/памяти через «запросы ресурсов» (resource requests). Ресурсы ЦП измеряются в виртуальных ядрах или чаще в «милликорах» (millicores), например, 500m подразумевает 50% vCPU. Ресурсы памяти измеряются в байтах, и можно использовать обычные суффиксы, например, 500Mi, что означает 500 мегабайт. Запросы ресурсов «блокируют» объем на рабочих узлах, то есть модуль с запросом ЦП в 1000m на узле с 4 виртуальными ЦП оставит только 3 виртуальных ЦП доступными для других модулей. [1] Slack (избыток резерва) — это разница между запрашиваемыми ресурсами и реальным использованием. Например, под, который запрашивает 2 GiB памяти, но использует только 200 MiB, имеет ~ 1,8 GiB “избыточной” памяти. Избыток стоит денег. Можно грубо оценить, что 1 GiB избыточной памяти стоит ~ 10 долларов в месяц. [2] Kubernetes Resource Report (kube-resource-report) отображает излишние резервы и может помочь вам определить потенциал экономии:



Использование EC2 Spot инстансов
Наконец, что не менее важно, затраты AWS EC2 можно снизить, используя Spot инстансы в качестве рабочих узлов Kubernetes [3]. Spot инстансы доступны со скидкой до 90% по сравнению с ценами по требованию. Запуск Kubernetes на EC2 Spot — хорошая комбинация: вам нужно указать несколько разных типов инстансов для более высокой доступности, то есть вы можете получить больший узел за ту же или более низкую цену, а увеличенная емкость может быть использована контейнерными рабочими нагрузками Kubernetes. Как запустить Kubernetes на EC2 Spot? Существует несколько вариантов: использовать сторонний сервис, такой как SpotInst (теперь он называется «Spot», не спрашивайте меня, почему), или просто добавить Spot AutoScalingGroup (ASG) в ваш кластер. Например, вот фрагмент CloudFormation для «оптимизированной по емкости» Spot ASG с несколькими типами экземпляров:
MySpotAutoScalingGroup: Properties: HealthCheckGracePeriod: 300 HealthCheckType: EC2 MixedInstancesPolicy: InstancesDistribution: OnDemandPercentageAboveBaseCapacity: 0 SpotAllocationStrategy: capacity-optimized LaunchTemplate: LaunchTemplateSpecification: LaunchTemplateId: !Ref LaunchTemplate Version: !GetAtt LaunchTemplate.LatestVersionNumber Overrides: - InstanceType: "m4.2xlarge" - InstanceType: "m4.4xlarge" - InstanceType: "m5.2xlarge" - InstanceType: "m5.4xlarge" - InstanceType: "r4.2xlarge" - InstanceType: "r4.4xlarge" LaunchTemplate: LaunchTemplateId: !Ref LaunchTemplate Version: !GetAtt LaunchTemplate.LatestVersionNumber MinSize: 0 MaxSize: 100 Tags: - Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot PropagateAtLaunch: true Value: "true"Некоторые замечания по использованию Spot с Kubernetes:
- Вам нужно обрабатывать завершения Spot, например путем слива узла на остановке инстанса
- Zalando использует форк официального автомасштабирования кластера с приоритетами пула узловl
- Узлы Spot можно заставить принимать “регистрации” рабочих нагрузок для запуска в Spot
Резюме
Я надеюсь, что вы найдете некоторые из представленных инструментов полезными для сокращения вашего счета за облачные вычисления. Вы можете найти большую часть содержимого статьи также в моем выступлении на DevOps Gathering 2019 на YouTube и в виде слайдов. Каковы ваши лучшие практики для экономии облачных затрат на Kubernetes? Пожалуйста, дайте знать в Twitter (@try_except_).
[1] Фактически менее 3 виртуальных ЦП останутся пригодными для использования, поскольку пропускная способность узла уменьшается за счет зарезервированных системных ресурсов. Kubernetes различает физическую емкость узла и «выделяемые» ресурсы (Node Allocatable). [2] Пример расчета: один экземпляр m5.large с 8 GiB памяти составляет ~84 доллара США в месяц (eu-central-1, On-Demand), т.е. блокировка 1/8 узла составляет примерно ~10 долларов США в месяц. [3] Есть еще много способов уменьшить ваш EC2 счет, например, зарезервированные экземпляры, план сбережений и т. д. — я не буду освещать эти темы здесь, но вы обязательно должны про них разузнать!