
Выбор библиотеки и типа алгоритма сортировки не всегда прост, а нововведения меняются в быстром темпе. На данный момент документация Pandas не соответствует коду (хотя лично мое PR-обновление сортировочных опций было самым последним).
В этой статье я разъясню вам, что к чему, дам пару советов, которые помогут с разобраться с методами, и поделюсь результатами теста скорости.
UPD 17 июля 2019: В результаты оценки теста скорости теперь входят реализации GPU PyTorch и TensorFlow. TensorFlow также включает в себя результаты CPU как при
tensorflow==2.0.0-beta1, так и при tensorflow-gpu==2.0.0-beta1. Интересные наблюдения: графический процессор PyTorch буквально летает, а GPU TensorFlow оказался медленнее CPU TensorFlow.Контекст
Базовых алгоритмов сортировки существует множество. Одни из них имеют высокую производительность и занимают меньше места, другие хорошо работают с большим числом данных. Для некоторых алгоритмов важно взаимное расположение элементов данных. На диаграмме в начале статьи можно увидеть ситуацию по времени и объему для самых распространенных алгоритмов.
На самом деле, не нужно быть экспертом в базовых внедрениях, чтобы решить большинство проблем сортировки. На деле, корнем зла порой считают преждевременную оптимизацию. Однако, при необходимости многократной сортировки большого числа данных может оказаться весьма полезным знать заранее, какую библиотеку и какие ключевые слова лучше использовать. Представляю вам мою шпаргалку.

python 3.6.8 numpy 1.16.4 pandas 0.24.2 tensorflow==2.0.0-beta1 #tensorflow-gpu==2.0.0-beta1 slows sorting pytorch 1.1Начнем с основ.
Python (vanilla)
Python содержит два встроенных метода сортировки.
my_list.sort()сортирует список на месте, при этом исходный список заменяется на сортированный.sort()возвращает None.- sorted(my_list) возвращает отсортированную копию для каждой итерации.
sorted()возвращает отсортированную итерацию.sort()не изменяет исходный список.
По идее,
sort() должен быть быстрее, так как сортировка происходит на месте. На удивление, особой разницы между ними нет. К тому же, sort() стоит использовать аккуратно, так как он изменяет исходные данные без сохранения.Все реализации для Vanilla Python, которые мы рассмотрим в этой статье, имеют восходящий порядок сортировки по умолчанию — от наименьшего до наибольшего. Однако, большинство иных методов сортировки используют нисходящий метод. Не слишком-то удобно для вас и вашей головы, но этот параметр разнится для каждой библиотеке.
Что касается нашего случая, чтобы изменить порядок сортировки на нисходящий в Vanilla Python, нужно задать
reverse=True.key может быть заявлен ключевым словом для вашего уникального критерия. Например, sort(key=len) отсортирует элементы списка по их длине.Единственный алгоритм сортировки, используемый в Vanilla Python — Timsort. Посредством данного алгоритма сортировка данных производится по их основным критериям. Например, если требуется сортировать короткий список, используется сортировка вставками. Дополнительную информацию о Timsort см. в большой статье Брэндона Скерритта.
Timsort и, соответственно, Vanilla Python, постоянны. То есть, если исходные значение одинаковы, то и обработанные значения будут аналогичны и расположены в том же порядке.
Чтобы напомнить разницу между sort() и sorted(), я лишь замечу, что sorted() — это более сложная команда, чем
sort(), и что sorted() займет объективно больше времени, ведь при этом сохраняются и исходные данные, и копия. И пусть результаты тестов неоднозначны, мнемоника — наше все.Теперь предлагаю рассмотреть использование Numpy.
Numpy
Numpy — это фундаментальная библиотека Python для научных вычислений. Как и у Vanilla Python, вариантов реализации у нее два: либо копирование, либо изменение массива исходных данных:
my_array.sort ()изменяет массив на месте и возвращает отсортированный массив;np.sort (my_array)возвращает копию отсортированного массива, при этом не изменяя исходные данные.
Аргументы, используемые дополнительно:
axis: int, optional — ось, по которой производится сортировка. По умолчанию -1 — сортировка по последней оси.kind: {‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’} — алгоритм сортировки. По умолчанию используется ‘quicksort’ — “быстрая сортировка”. Далее я расскажу об этом подробнее.order: str или list of str — когда a является массивом с определенными границами, этот аргумент указывает, в каком порядке эти границы сравниваются. Одно поле может быть задано в виде строки, дальнейшие поля можно не конкретизировать. Они в любом случе будут использоваться в dtype для перебивок.
Откровенно говоря, на данным момент алгоритмы сортировки фактически соответствуют их названиям. Команда
kind=quicksort буквально означает, что сортировка начинается с интроспективной сортировки. Подробнее здесь. В случае, если удовлетворительного результата нет, происходит переключение на алгоритм heapsort. В худшем случае сортировка происходит по быстрому циклу O(n* log (n)).Один из важнейших выводов: Numpy позволяет управлять параметрами сортировки более свободно, чем Vanilla Python. Второй вывод, не менее важный: ключевое слово kind совершенно не обязательно соответствует используемому типу сортировки. И наконец, финальный итог, если можно так сказать, заключается в том, что
stable автоматически выбирает наиболее приемлемый вариант сортировки. Данный параметр, наряду с сортировкой слиянием, на данный момент сопоставляется с сортировкой timsort или radix, в зависимости от типа данных. Прямая совместимость API в настоящее время ограничивает возможность выбора реализации, и она жестко привязана к различным типам данных.
Timsort применяется на предварительно подготовленных или близких к финальной сортировке данных. По случайным данным timsort практически идентичен mergesort. На данный момент он используется для конкретной сортировки, в то время как быстрая сортировка по-прежнему реализуется по умолчанию, и если конкретного выбора нет… «mergesort» и «stable» выполняются для целочисленных типов данных автоматически.
— Из документов Numpy — (после парочки моих правок)
mergesort и stable являются определенными сортировками, а quicksort и heapsort — нет.В нашем списке Numpy — единственный метод, не имеющий ключевого слова для изменения порядка сортировки. На наше счастье, сделать это можно своеобразным переворотом массива:
my_arr[::-1].Все функции Numpy также доступны в куда более удобном для использования Pandas.
Pandas
Проводить сортировку можно в Pandas DataFrame с df.sort_values (by=my_column). Для удобства здесь имеется несколько ключевых слов.
by: str или list of str — обязательное имя или список имен для сортировки. Если ось = 0 или конкретному значению, то она может содержать уровни значений/имена столбцов. Если ось приравнивается 1 или столбцу, то она может содержать уровни столбцов и/или метки значений.axis: {0 или индекс, 1 или столбец}, по умолчанию 0 — ось для сортировки.ascending: bool или список bool, значение по умолчанию True — сортировка по возрастанию или по убыванию. Укажите список для нескольких порядков сортировки. Если это список болтов, должен соответствовать длине аргумента by.inplace: bool, по умолчанию False — если назначить True, операция выполняется на месте.kind: {quicksort, mergesort, heapsort или stable}, по умолчанию quicksort — выбор алгоритма сортировки. Для получения дополнительной информации можно посмотретьndarray.np.sort. Для DataFrames этот параметр применяется только при сортировке по одному столбцу или метке.na_position: {«first», «last»}, по умолчанию «last» — first ставит NaNs в начале, last ставит NaNs в конце.
Pandas Series реализуется с таким же синтаксисом. В Series нет необходимости в ключевом слове
by, поскольку нет нескольких столбцов с данными.Поскольку “под капотом” у Pandas — Numpy, у вас под рукой есть те же оптимизированные параметры сортировки. Тем не менее, использование Pandas чуть более трудозатратно.
При сортировке по одному столбцу в Numpy по умолчанию используется
quicksort. Как вы помните, quicksort теперь фактически является вводной и переходит в пирамидальную, если процесс сортировки идет медленно. Pandas заявляют, что сортировка по нескольким столбцам использует mergesort Numpy. mergesort в Numpy фактически использует алгоритмы сортировки Timsort или Radix. Это стабильные алгоритмы сортировки, что необходимо при сортировке по нескольким столбцам.Для Pandas есть несколько ключевых моментов, которые стоит запомнить:
- Имя функции:
sort_values(). - Необходимо заявить
by=column_nameили список имен столбцов. ascending— ключевое слово для реверса.- Для стабильной сортировки используйте
mergesort.
При аналитической обработке данных я часто сталкиваюсь с суммированием и сортировкой значений в Pandas DataFrame с помощью
Series.value_counts(). Вот фрагмент кода для суммирования и сортировки наиболее частых значений для каждого столбца.for c in df.columns: print(f"---- {c} ---") print(df[c].value_counts().head())Dask, который Pandas предлагают для работы с большими данными, пока что не имеет реализации параллельной сортировки, но этот вопрос находится в обсуждении. Сортировка в Pandas — это хороший выбор для предварительной сортировки небольших объемов данных. Если же вы имеете большой объем данных и хотите параллельно работать с GPU, стоит обратить внимание на TensorFlow или PyTorch.
TensorFlow
TensorFlow — самая популярная среда для deep learning. Больше о глубоком изучении можно узнать в моей статье по ссылке здесь. Приведенная ниже информация актуальна для GPU TensorFlow 2.0. tf.sort(my_tensor) возвращает отсортированную копию тензора. Опциональные аргументы:
axis: {int} Ось, по которой производится сортировка. По умолчанию равянется -1 и сортирует последнюю ось.direction: {ascending или descending} — направление сортировки значений.name: {str} — имя для операции.
tf.sort по сути использует top_k(). Для top_k() используется библиотека CUB для CUDA GPU, что упрощает параллельную реализацию. В документации говорится, что «CUB предоставляет современные и повторяемые программные компоненты для каждого уровня модели программирования CUDA». TensorFlow использует основную сортировку на GPU через CUB (обсуждение). Информацию по TensorFlow GPU можно найти здесь. Чтобы активировать возможности графического процессора с TensorFlow 2.0, вам необходимо прописать !pip3 install tensorflow-gpu==2.0.0-beta1. Ниже будет видно, что вы можете следовать по пути tensorflow==2.0.0-beta1, если вы только лишь сортируете данные (что маловероятно).Для проверки кода на CPU и GPU используйте следующую строку:
tf.debugging.set_log_device_placement(True)Чтобы указать, что вы хотите использовать GPU, нужно воспользоваться таким блоком:
with tf.device('/GPU:0'): %time tf.sort(my_tf_tensor)Для использования CPU:
with tf.device('/CPU:0').tf.sort() это интуитивно понятный метод при работе в TensorFlow. Просто запомните, что direction=descending нужен для изменения порядки сортировки.PyTorch
torch.sort(my_tensor) возвращает отсортированную копию тензора. Необязательные аргументы:
dim: {int} — объем сортировки.descending: {bool} — управляет порядком сортировки (по возрастанию или по убыванию).out: {tuple} — выходное сопровождение (Tensor, LongTensor), которое может использоваться в качестве выходных буферов.
Если вы хотите использовать GPU для сортировки, прикрепите
.cuda () к концу вашего тензора. gpu_tensor=my_pytorch_tensor.cuda() %time torch.sort(gpu_tensor) Исследования показали, что PyTorch использует сегментированную параллельную сортировку через Thrust, если сортируется набор данных размером более 1 миллиона строк на 100 000 столбцов. К сожалению, у меня не хватило памяти, когда я пытался создать произвольные данные размером 1.1 миллиона на 100 тысяч через Numpy в Google Colab. После этого я попробовал GCP с 416 МБ ОЗУ, и мне вновь не хватило памяти.
Сегментированная сортировка и сортировка по местоположению — это высокопроизводительные варианты сортировки слиянием, которые работают с неоднородными случайными данными. Сегментированная сортировка позволяет сортировать множество массивов переменной длины параллельно. — https://moderngpu.github.io/segsort.htmlThrust — это библиотека параллельных алгоритмов, которая обеспечивает совместимость производительности GPU и многояденых CPU. Она предоставляет сортировочную основу, которая автоматически выбирает наиболее эффективный метод реализации. Библиотека CUB, используемая TensorFlow, облегчает нагрузку. PyTorch и TensorFlow используют аналогичные алгоритмы для сортировки GPU — независимо от того, какой применяется подход. Как и TensorFlow, метод сортировки в PyTorch довольно прост для запоминания:
torch.sort(). Единственное, что нужно запомнить, это направление отсортированных значений: TensorFlow использует direction, а PyTorch — descending. И не забудьте использовать .cuda(), чтобы максимально увеличить скорость при работе с большим объемом данных.Хотя сортировка с использованием GPU может выступать хорошим вариантом для очень больших наборов данных, также имеет смысл сортировать данные непосредственно в SQL.
SQL
Сортировка в SQL обычно выполняется очень быстро, особенно если сортировка происходит непосредственно в памяти.
SQL — это спецификация, которая при этом не обязывает использовать определенный алгоритм. Postgres использует сортировку слиянием дисков, пирамидальную или быструю сортировку в зависимости от обстоятельств. Если у вас достаточно памяти, сортировки можно провести в ней, причем намного быстрее. Увеличить доступную память для сортировок можно с помощью настройки work_mem. Другие варианты SQL используют разные алгоритмы сортировки. Например, Google BigQuery использует внутреннюю сортировку с некоторыми приемами, вроде тех, что представлены в ответе на Stack Overflow. Сортировка в SQL выполняется командой ORDER BY. Этот синтаксис отличается от Python, где предпочитают использовать ту или иную форму слова sort. Лично мне запомнилось, что ORDER BY используется в синтаксисе SQL, так как это довольно необычно.
Чтобы отсортировать данные по убыванию, используйте ключевое слово DESC. Таким образом, запрос на возврат данных в алфавитном порядке от последнего к первому будет выглядеть так:
SELECT Names FROM Customers ORDER BY Names DESC; Сравнение
Для каждой из вышеперечисленных библиотек Python я провел анализ, сортируя 1 000 000 точек данных в одном столбце, массиве или списке. Я использовал ноутбук Google Colab Jupyter с GPU K80 и Intel Xeon CPU с тактовой частотой 2,30 ГГц.
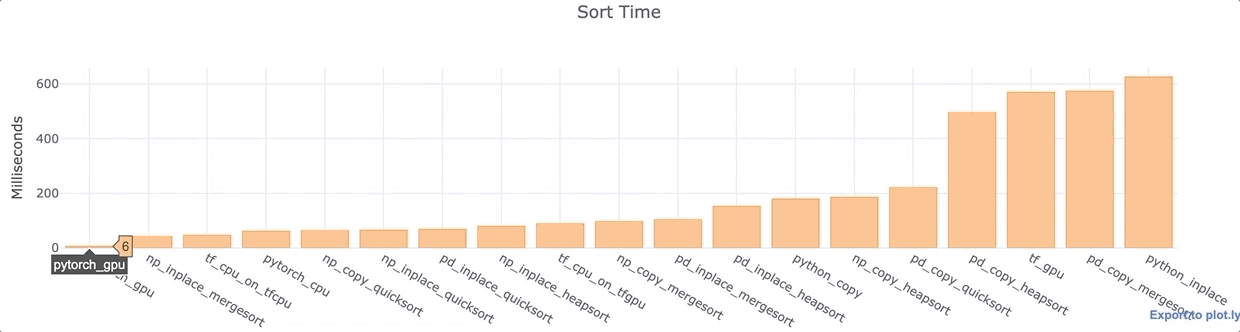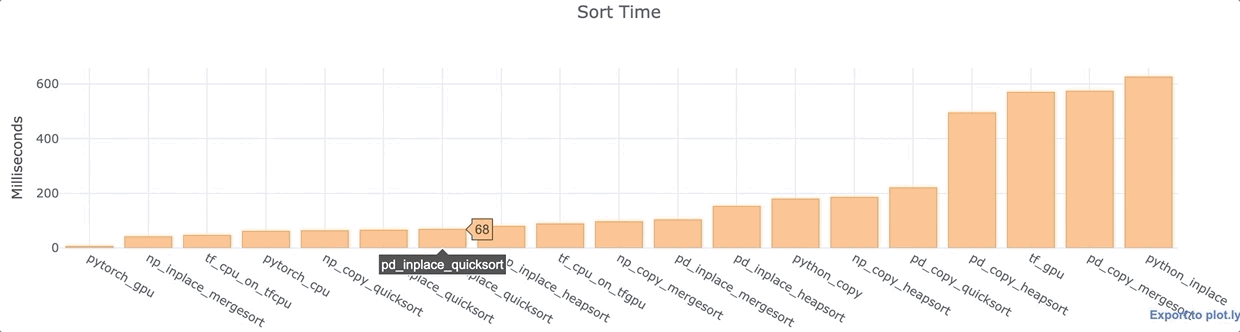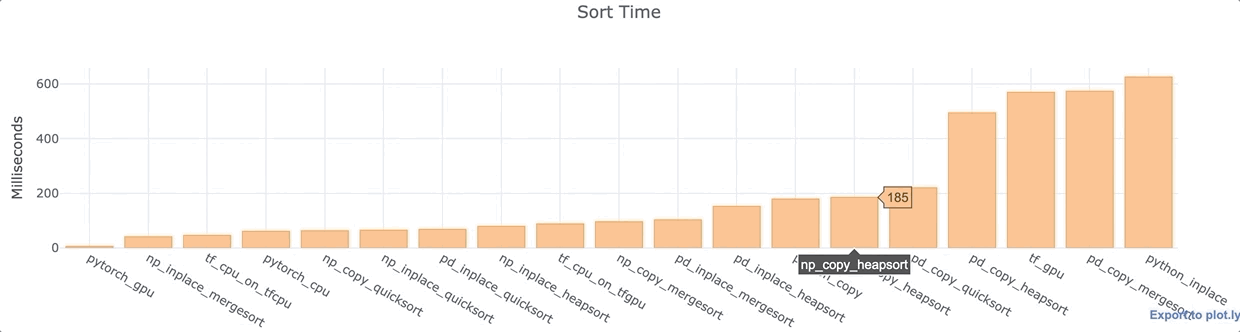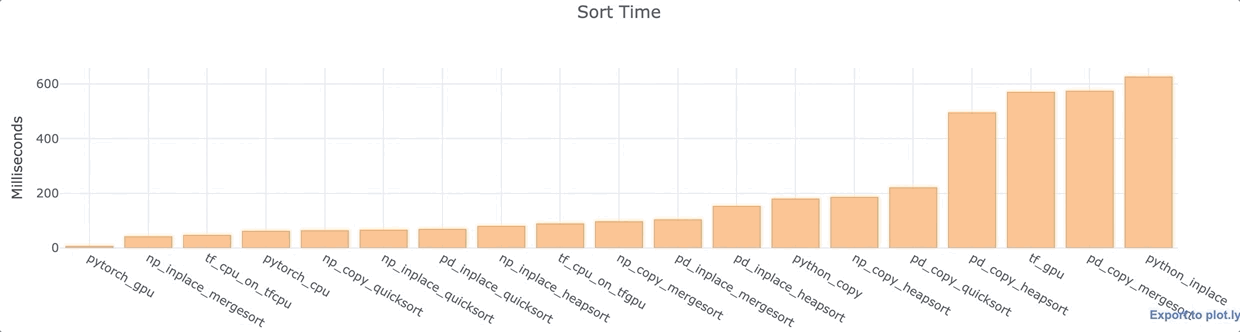
Наблюдения
- PyTorch с GPU максимально быстрый.
- Как для Numpy, так и для Pandas, сортировка на месте, как правило, быстрее, чем с копированием данных.
- Быстрая сортировка Pandas по умолчанию довольно быстрая.
- Большинство функций Pandas сравнительно медленнее, чем их аналоги в Numpy.
- Процессор TensorFlow довольно быстрый. Установка GPU замедляет работу TensorFlow даже при использовании CPU. Сортировка GPU довольно медленная. Этот вариант не слишком эффективен
- В Vanilla Python сортировка на месте происходит на удивление медленно — почти в 100 раз медленнее, чем сортировка с поддержкой графического процессора PyTorch. Я посторил опыт несколько раз (с разными данными), чтобы перепроверить, что это не аномалия.
Опять же, это всего лишь один небольшой тест. Определенно, это не конечный результат.
Подведем итоги
Как правило, вам не нужны собственные разработки вариантов сортировки. Готовые варианты вполне удовлетворительны, и зачастую используют не один метод сортировки. Вместо этого они сначала оценивают данные, а затем используют проверенный алгоритм сортировки. Некоторые версии даже модифицируют алгоритмы, если сортировка подтормаживает.
В этой статье вы поняли, как сортировать каждый фрагмент данных в Python и SQL. Я надеюсь, вам это поможет в будущем. Если у вас есть такая возможность, пожалуйста, поделитесь статьей в ваших любимых социальных сетях, чтобы помочь другим людям найти ее.
Вам все лишь нужно запомнить, какой вариант выбрать и его вызвать. Используйте мою шпаргалку, чтобы сэкономить время. Мои общие рекомендации звучат так:
- Используйте Pandas
sort_values()по умолчанию для исследования относительно небольших наборов данных. - Для больших наборов данных или когда скорость достаточно высока, попробуйте встроенную сортировку Numpy на месте, параллельную реализацию GPU PyTorch или TensorFlow, или SQL.
Я не слишком много писал о сортировке с GPU. Эта область, которая созрела для новых исследований и учебных пособий. Вот статья 2017 года research, чтобы дать вам представление о последних исследованиях. Более подробную информацию об алгоритмах сортировки GPU можно найти здесь.