Руководство по искусственному интеллекту с Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-06-02 10:14
Искусственный интеллект существует уже более полувека, и его достижения растут в геометрической прогрессии. Спрос на ИИ находится на пике, и если вы хотите узнать об искусственном интеллекте, вы попали в нужное место. Эта статья по искусственному интеллекту с Python поможет вам понять все концепции искусственного интеллекта с практическими реализациями на Python.
Мы рассмотрим следующие темы:
- Почему Python лучше для AI?
- Спрос на ИИ
- Что такое искусственный интеллект?
- Типы Искусственного Интеллекта
- Основы машинного обучения
- Типы машинного обучения
- Типы проблем, решаемых с помощью машинного обучения
- Процесс машинного обучения
- Машинное обучение с Python
- Ограничения машинного обучения
- Почему Deep Learning?
- Как работает Deep Learning?
- Что такое Deep Learning?
- Случай использования Deep Learning
- Перцептроны
- Многослойные персептроны
- Deep Learning с Python
- Введение в обработку естественного языка (НЛП)
- Приложения НЛП
- Терминологии в НЛП
Почему Python лучше для AI?
Многие люди спрашивают: « Какой язык программирования лучше всего подходит для ИИ?» или « Почему Python для ИИ?»
Несмотря на то, что Python является языком общего назначения, он нашел применение в самых сложных технологиях, таких как искусственный интеллект, машинное обучение, глубокое обучение и так далее.
Почему Python приобрел такую большую популярность во всех этих областях?
Вот список причин, по которым Python является одним из лучших для разработчика, разработчика данных, инженера по машинному обучению и т. д.:
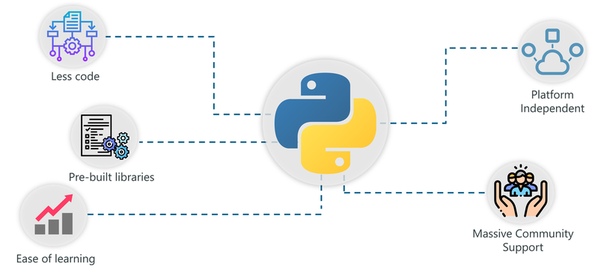
- Меньше кода: реализация ИИ требует множества алгоритмов. Благодаря поддержке Python для предопределенных пакетов нам не нужно кодировать алгоритмы. И чтобы упростить задачу, Python предоставляет методологию «check as you code», которая снижает нагрузку на тестирование кода.
- Готовые библиотеки: в Python есть сотни готовых библиотек для реализации различных алгоритмов машинного обучения и глубокого обучения. Поэтому каждый раз, когда вы хотите запустить алгоритм для набора данных, все, что вам нужно сделать, это установить и загрузить необходимые пакеты с помощью одной команды. Примеры готовых библиотек – NumPy, Keras, Tensorflow, Pytorch и так далее.
- Простота обучения: Python использует очень простой синтаксис, который можно использовать для реализации простых вычислений, таких как добавление двух строк к сложным процессам, таким как построение модели машинного обучения.
- Независимость от платформы : Python может работать на нескольких платформах, включая Windows, MacOS, Linux, Unix и т. д. При переносе кода с одной платформы на другую вы можете использовать такие пакеты, как PyInstaller, которые позаботятся о любых проблемах с зависимостями.
- Массовая поддержка сообщества: у Python огромное сообщество пользователей, которое всегда помогает, когда мы сталкиваемся с ошибками кодирования. Помимо огромного количества поклонников, в Python есть несколько сообществ, групп и форумов, где программисты публикуют свои ошибки и помогают друг другу.
Поскольку этот блог посвящен искусственному интеллекту с помощью Python, я познакомлю вас с наиболее эффективными и популярными библиотеками Python на основе AI.
- Tensorflo : эта библиотека, разработанная Google, широко используется при написании алгоритмов машинного обучения и выполнении сложных вычислений с использованием нейронных сетей.
- Scikit-Learn: Scikit-learn – это библиотека Python, связанная с NumPy и SciPy. Он считается одной из лучших библиотек для работы со сложными данными.
- NumPy: Numpy – это библиотека python, специально используемая для вычисления научных / математических данных.
- Theano: Theano – это функциональная библиотека, которая эффективно считает и вычисляет математические выражения с использованием многомерных массивов.
- Keras: Эта библиотека упрощает реализацию нейронных сетей. Он также обладает лучшими функциональными возможностями для вычислительных моделей, оценки наборов данных, визуализации графиков и многого другого.
- NLTK: NLTK или Natural Language ToolKit – это библиотека Python с открытым исходным кодом, специально созданная для обработки естественного языка, анализа текста и анализа текста.
Теперь, когда вы знаете важные библиотеки Python, которые используются для реализации методов искусственного интеллекта, давайте сосредоточимся на искусственном интеллекте. В следующем разделе мы охватим все основные концепции ИИ.
Во-первых, давайте начнем с понимания внезапного спроса на ИИ.
Спрос на ИИ
Со времени появления ИИ в 1950-х годах мы наблюдаем экспоненциальный рост его потенциала. Но если ИИ здесь уже более полувека, почему он вдруг приобрел такое большое значение? Почему мы говорим об искусственном интеллекте сейчас?
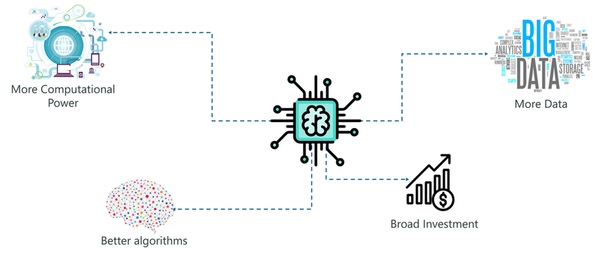
Основными причинами огромной популярности ИИ являются:
Большая вычислительная мощность: Реализация ИИ требует больших вычислительных мощностей, так как построение моделей ИИ требует сложных вычислений и использования сложных нейронных сетей. Изобретение графических процессоров сделало это возможным.. Наконец, мы можем выполнять высокоуровневые вычисления и реализовывать сложные алгоритмы.
Генерация данных: за последние годы мы генерировали неизмеримое количество данных. Такие данные необходимо анализировать и обрабатывать с использованием алгоритмов машинного обучения и других методов искусственного интеллекта.
Более эффективные алгоритмы. За последнее десятилетие мы успешно разработали современные алгоритмы, которые включают в себя реализацию глубоких нейронных сетей.
Широкие инвестиции. По мере того, как технологические гиганты, такие как Tesla, Netflix и Facebook, начали вкладывать средства в искусственный интеллект, они приобрели большую популярность, что привело к увеличению спроса на системы на основе искусственного интеллекта.
Рост Искусственного Интеллекта является экспоненциальным, он также ускоряет рост экономики. Так что сейчас самое подходящее время для вас, чтобы попасть в область искусственного интеллекта.
Что такое искусственный интеллект?
Термин «искусственный интеллект» был впервые введен десятилетием назад в 1956 году Джоном Маккарти на конференции в Дартмуте. Он определил ИИ как:
«Наука и техника – создания интеллектуальных машин».
Другими словами, искусственный интеллект – это наука о том, как заставить машины думать и принимать решения, как люди.
Недавно ИИ смог добиться этого, создав машины и роботов, которые использовались в самых разных областях, включая здравоохранение, робототехника, маркетинг, бизнес-аналитика и многое другое.
Теперь давайте обсудим различные типы искусственного интеллекта.
Типы Искусственного Интеллекта
ИИ строится на трех этапах эволюции:
- Искусственный узкий Интеллект
- Искусственный общий интеллект
- Искусственный супер Интеллект

Узкий искусственный интеллект
Обычно известный как узкий ИИ, искусственный узкий интеллект подразумевает применение ИИ только для выполнения определенных задач.
Существующие системы на основе ИИ, которые утверждают, что используют «искусственный интеллект», фактически работают как слабый ИИ. Алекса является хорошим примером узкого интеллекта. Он работает в ограниченном предопределенном диапазоне функций. Алекса не имеет подлинного интеллекта или самосознания.
Поисковая система Google Sophia, автомобили с автоматическим управлением и даже знаменитая AlphaGo подпадают под категорию слабого ИИ.
Общий искусственный интеллект
Обычно известный как общий ИИ, искусственный общий интеллект включает в себя машины, которые обладают способностью выполнять любые интеллектуальные задачи, которые может выполнять человек.
Видите ли, машины не обладают человеческими способностями, у них есть мощный процессор, который может выполнять высокоуровневые вычисления, но они еще не способны мыслить и рассуждать, как человек.
Есть много экспертов, которые сомневаются в том, что AGI когда-либо будет возможен, и есть также много людей, которые задаются вопросом, нужно ли это.
Стивен Хокинг, например, предупредил:
«Общий ИИ взлетит сам по себе, и его дизайн будет постоянно расти. Люди, которые ограничены медленной биологической эволюцией, не могут конкурировать и будут вытеснены».
Супер искусственный интеллект
Искусственный супер-интеллект – это термин, обозначающий время, когда возможности компьютеров превосходят людей.
ASI в настоящее время рассматривается как гипотетическая ситуация, как это показано в фильмах и научно-фантастических книгах, где машины захватили весь мир. Тем не менее, вдохновители технологий, такие как Элон Маск, считают, что ASI захватит мир к 2040 году!
Прежде чем идти дальше, позвольте мне прояснить очень распространенное заблуждение. Задаёт этот вопрос каждый новичок:
В чем разница между ИИ, машинным обучением и глубоким обучением?
ИИ такой же, как ML?
Давайте разберемся с этим:
AI, ML и DL (искусственный интеллект против машинного обучения против глубокого обучения)
Люди склонны считать, что искусственный интеллект, машинное обучение и глубокое обучение – это одно и то же, поскольку они имеют общие приложения. Например, Siri – это приложение ИИ, машинного обучения и глубокого обучения.
Так, как эти технологии связаны?
- Искусственный интеллект – это наука о том, как заставить машины имитировать поведение людей.
- Машинное обучение – это подмножество искусственного интеллекта (AI), которое фокусируется на том, чтобы заставить машины принимать решения, предоставляя им данные.
- Глубокое обучение – это подмножество машинного обучения, которое использует концепцию нейронных сетей для решения сложных задач.
Подводя итог, ИИ, машинное обучение и глубокое обучение являются взаимосвязанными областями. Машинное обучение и глубокое обучение помогают искусственному интеллекту, предоставляя набор алгоритмов и нейронных сетей для решения задач, управляемых данными.
Тем не менее, искусственный интеллект не ограничивается только машинным обучением и глубоким обучением. Он охватывает широкий спектр областей, включая обработку естественного языка (NLP), обнаружение объектов, компьютерное зрение, робототехнику, экспертные системы и так далее.
Теперь давайте начнём с машинного обучения.
Основы машинного обучения
Термин «машинное обучение» был впервые введен Артуром Самуэлем в 1959 году. Оглядываясь назад, этот год был, вероятно, самым значительным с точки зрения технического прогресса.
Проще говоря,
Машинное обучение – это подмножество искусственного интеллекта (ИИ), которое дает машинам возможность обучаться автоматически, снабжая его тоннами данных и позволяя улучшить его с помощью опыта. Таким образом, машинное обучение – это практика заставить машины решать проблемы, приобретая способность мыслить.
Но как машина может принимать решения?
Если вы передадите машине большое количество данных, она научится интерпретировать, обрабатывать и анализировать эти данные с помощью алгоритмов машинного обучения.
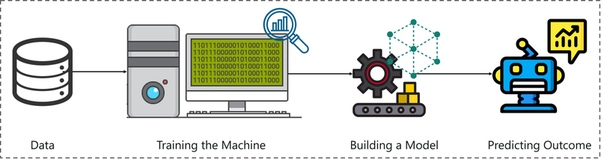
Подводя итог, взгляните на рисунок выше:
- Процесс машинного обучения начинается с подачи на машину большого количества данных.
- Затем машина обучается на этих данных, чтобы обнаружить скрытые идеи и закономерности.
- Эти идеи используются для построения модели машинного обучения с использованием алгоритма для решения проблемы.
Теперь, когда мы знаем, что такое Машинное обучение, давайте рассмотрим различные способы, с помощью которых машины могут учиться.
Типы машинного обучения
Машина может научиться решать проблему, используя любой из следующих трех подходов:
- Контролируемое обучение
- Обучение без учителя
- Усиленное обучение
Контролируемое обучение
Контролируемое обучение – это техника, в которой мы обучаем или обучаем машину, используя данные, которые хорошо обозначены.
Чтобы понять контролируемое обучение, давайте рассмотрим аналогию. В детстве мы все нуждались в руководстве для решения математических задач. Наши учителя помогли нам понять, что такое сложение и как оно делается.
Точно так же вы можете думать о контролируемом обучении как о типе машинного обучения, которое включает в себя руководство. Помеченный набор данных – это учитель, который научит вас понимать закономерности в данных. Помеченный набор данных – это не что иное, как набор обучающих данных.
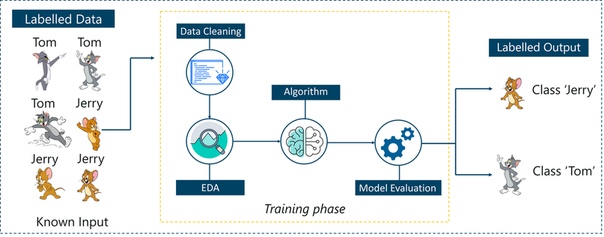
Рассмотрим приведенный выше рисунок. Здесь мы подаем компьютерные изображения Тома и Джерри, и цель состоит в том, чтобы машина идентифицировала и классифицировала изображения на две группы (изображения Тома и изображения Джерри).
Набор обучающих данных, который подается на модель, помечен, как, например, мы говорим машине: «Так выглядит Том, а это Джерри». Тем самым вы тренируете машину, используя помеченные данные. В контролируемом обучении четко определенная фаза обучения выполняется с помощью помеченных данных.
Обучение без учителя
Обучение без учителя включает в себя обучение с использованием немаркированных данных и позволяет модели воздействовать на эту информацию без руководства.
Думайте о неконтролируемом обучении как о умном ребенке, который учится без какого-либо руководства. В этом типе машинного обучения модель не снабжается помеченными данными, поскольку в модели нет подсказки, что «это изображение – это Том, а это – Джерри», она самостоятельно выясняет закономерности и различия между Томом и Джерри. принимая тонны данных.
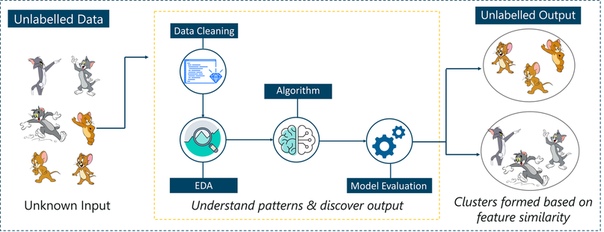
Например, он определяет характерные черты Тома, такие как заостренные уши, больший размер и т. Д., Чтобы понять, что это изображение относится к типу 1. Аналогично, он находит такие признаки в Джерри и знает, что это изображение относится к типу 2.
Поэтому он классифицирует изображения на два разных класса, не зная, кто такой Том или Джерри.
Усиленное обучения
Усиленное обучение является частью машинного обучения, когда объект помещается в среду, и он учится вести себя в этой среде, выполняя определенные действия и наблюдая за вознаграждениями, которые он получает от этих действий.
Представьте, что вас высадили на изолированном острове!
Что бы вы сделали?
Паника? Да, конечно. Но со временем вы научитесь жить на острове. Вы изучите окружающую среду, поймете климатические условия, тип пищи, которая там растет, опасности острова и т. Д.
Именно так работает Усиленное обучение, он включает в себя объекта (вы застряли на острове), который помещается в неизвестную среду (остров), где он должен учиться, наблюдая и выполняя действия, которые приводят к вознаграждениям.
Усиленное обучение в основном используется в таких областях, как машинное обучение, автомобили с самостоятельным вождением, AplhaGo и т. Д. Таким образом, подводятся итоги типов машинного обучения.
Теперь давайте посмотрим на тип проблем, которые решаются с помощью машинного обучения.
Какие проблемы может решить машинное обучение?
Существует три основных категории проблем, которые можно решить с помощью машинного обучения:
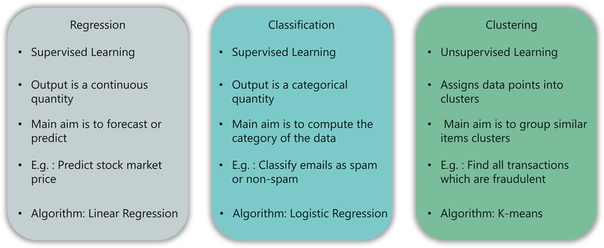
Что такое регрессия?
В этом типе проблемы результат является непрерывной величиной. Например, если вы хотите предсказать скорость автомобиля с учетом расстояния, это проблема регрессии. Проблемы регрессии могут быть решены с помощью алгоритмов контролируемого обучения, таких как линейная регрессия.
Что такое классификация?
В этом типе вывод является категориальным значением. Классификация электронных писем по двум классам: спам и не-спам – это проблема классификации, которую можно решить с помощью алгоритмов классификации Контролируемого обучения, таких как машины опорных векторов, наивный байесовский алгоритм, логистическая регрессия и т. Д.
Что такое кластеризация?
Этот тип проблемы включает в себя назначение входных данных в два или более кластеров на основе сходства функций. Например, кластеризация зрителей в схожие группы в зависимости от их интересов, возраста, географии и т. д. может быть выполнена с использованием алгоритмов неконтролируемого обучения, таких как K-Means Clustering.
Вот таблица, которая суммирует разницу между регрессией, классификацией и кластеризацией:
Теперь давайте посмотрим как работает процесс машинного обучения.
Этапы процесса машинного обучения
Процесс машинного обучения включает в себя построение прогнозирующей модели, которую можно использовать для поиска решения для постановки задачи.
Чтобы понять процесс машинного обучения, давайте предположим, что вы столкнулись с проблемой, которую необходимо решить с помощью машинного обучения.
Проблема состоит в том, чтобы предсказать появление дождя в вашем регионе с помощью машинного обучения.
Следующие шаги выполняются в процессе машинного обучения:
Шаг 1: Определите цель постановки задачи
На этом этапе мы должны понимать, что именно нужно прогнозировать. В нашем случае цель состоит в том, чтобы предсказать вероятность дождя, изучая погодные условия.
Также важно делать пометки о том, какие данные можно использовать для решения этой проблемы или какой подход вы должны использовать, чтобы найти решение.
Шаг 2: Сбор данных
На этом этапе вы должны задавать такие вопросы, как,
- Какие данные необходимы для решения этой проблемы?
- Доступны ли данные?
- Как я могу получить данные?
Как только вы узнаете, какие типы данных требуются, вы должны понять, как вы можете получить эти данные. Сбор данных может быть сделан вручную или с помощью веб-поиска.
Однако, если вы новичок и хотите изучать машинное обучение, вам не нужно беспокоиться о получении данных. В сети есть тысячи источников данных, вы можете просто загрузить набор данных и приступить к работе.
Возвращаясь к рассматриваемой проблеме, данные, необходимые для прогнозирования погоды, включают такие показатели, как уровень влажности, температура, давление, местность, независимо от того, живете ли вы на холмистой станции и т. Д.
Такие данные должны быть собраны и сохранены для анализа.
Шаг 3: Подготовка данных
Собранные вами данные почти никогда не имеют правильного формата. Вы столкнетесь со множеством несоответствий в наборе данных, таких как пропущенные значения, избыточные переменные, повторяющиеся значения и т. Д.
Устранение таких несоответствий очень важно, потому что они могут привести к ошибочным вычислениям и прогнозам. Поэтому на этом этапе вы сканируете набор данных на наличие несоответствий и тут же исправляете их.
Шаг 4: Исследовательский анализ данных
Хватайте свои детективные очки, потому что этот этап – это погружение в данные и поиск всех тайн скрытых данных.
EDA или исследовательский анализ данных – это этап мозгового штурма машинного обучения. Исследование данных включает в себя понимание закономерностей и тенденций в данных. На этом этапе все полезные идеи прорисованы и корреляции между переменными понятны.
Например, в случае прогнозирования осадков, мы знаем, что существует большая вероятность дождя, если температура упала низко. Такие корреляции должны быть поняты и отображены на этом этапе.
Шаг 5: Построение модели машинного обучения
Все идеи и шаблоны, полученные в ходе исследования данных, используются для построения модели машинного обучения. Этот этап всегда начинается с разделения набора данных на две части: данные обучения и данные тестирования.
Данные обучения будут использованы для построения и анализа модели. Логика модели основана на внедряемом алгоритме машинного обучения.
В случае прогнозирования количества осадков, поскольку выходные данные будут в форме True (если завтра будет дождь) или False (завтра нет дождя), мы можем использовать алгоритм классификации, такой как логистическая регрессия или дерево решений.
Выбор правильного алгоритма зависит от типа проблемы, которую вы пытаетесь решить, набора данных и уровня сложности проблемы.
Шаг 6: Оценка и оптимизация модели
После построения модели с использованием набора обучающих данных, наконец, пришло время протестировать модель.
Набор данных тестирования используется для проверки эффективности модели и того, насколько точно она может предсказать результат.
Как только точность рассчитана, любые дальнейшие улучшения в модели могут быть реализованы на этом этапе. Такие методы, как настройка параметров и перекрестная проверка, могут быть использованы для повышения производительности модели.
Шаг 7: Предсказания
Как только модель оценена и улучшена, она, наконец, используется для прогнозирования. Конечным результатом может быть переменная категории (например, True или False) или непрерывное количество (например, прогнозируемая стоимость акции).
В нашем случае для прогнозирования выпадения осадков выходные данные будут категориальной переменной.
Вот и весь процесс машинного обучения.
В следующем разделе мы обсудим различные типы алгоритмов машинного обучения.
Алгоритмы машинного обучения
Алгоритмы машинного обучения являются основной логикой каждой модели машинного обучения. Эти алгоритмы основаны на простых понятиях, таких как статистика и вероятность.
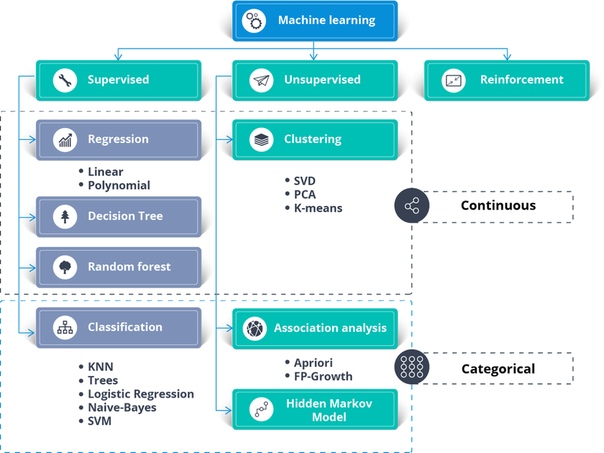
На рисунке выше показаны различные алгоритмы, используемые для решения проблемы с использованием машинного обучения.
Контролируемое обучение может использоваться для решения двух типов задач машинного обучения:
- регрессия
- классификация
Для решения задач регрессии вы можете использовать известный алгоритм линейной регрессии.
Проблемы классификации могут быть решены с использованием следующих алгоритмов классификации:
- Логистическая регрессия
- Древо решений
- Случайный Лес
- Наивный байесовский классификатор
- Метод опорных векторов
- k-ближайших соседей
Неуправляемое обучение может использоваться для решения проблем кластеризации и ассоциаций. Одним из известных алгоритмов кластеризации является алгоритм кластеризации k-средних.
Вы можете пров
Вы можете проверить это видео о кластеризации K-средних, чтобы узнать больше об этом.
K означает алгоритм кластеризации | Алгоритмы машинного обучения | Edureka
Это видео поможет вам изучить концепции кластеризации K-Means и ее реализации с использованием Python.
Укрепление обучения может быть использовано для решения проблем, основанных на вознаграждении. Известный алгоритм Q-обучения обычно используется для решения задач обучения подкреплению.
Вот видео об обучении с подкреплением, которое охватывает все важные концепции обучения с подкреплением наряду с практической реализацией Q-обучения с использованием Python.
Укрепление Учебное пособие | Пример обучения подкреплению с использованием Python | Edureka
В этом видео вы получите глубокое понимание того, как обучение с подкреплением используется в реальном мире.
Сейчас чтобы лучше понять весь процесс машинного обучения, давайте выполним практическую реализацию машинного обучения с использованием Python.
Машинное обучение с Python
В этом разделе мы реализуем машинное обучение с использованием Python. Итак, начнем.
Постановка задачи: Построить модель машинного обучения, которая будет предсказывать, будет ли завтра дождь, изучая прошлые данные.
Описание набора данных: Этот набор данных содержит около 145 тыс. Наблюдений за суточными погодными условиями, наблюдаемыми на многочисленных австралийских метеостанциях. Набор данных имеет около 24 функций, и мы будем использовать 23 функции (переменные Predictor), чтобы предсказать целевую переменную, а именно, «Дождь завтра».
Эта целевая переменная (RainT Saturday) будет хранить два значения:
- Да: означает, что завтра будет дождь
- Нет: обозначает, что завтра не будет дождя
Следовательно, это явно проблема классификации. Модель машинного обучения классифицирует результаты на 2 класса: ДА или НЕТ.
Логика: Построить классификационные модели, чтобы предсказать, будет ли завтра дождь в зависимости от погодных условий.
Теперь, когда цель ясна, давайте поработаем над мозгом и начнем кодировать.
Шаг 1: Импортируйте необходимые библиотеки
# For linear algebra import numpy as np # For data processing import pandas as pd
Шаг 2: Загрузите набор данных
#Load the data set df = pd.read_csv('. . . Desktop/weatherAUS.csv') #Display the shape of the data set print('Size of weather data frame is :',df.shape) #Display data print(df[0:5]) Size of weather data frame is : (145460, 24) Date Location MinTemp ... RainToday RISK_MM RainTomorrow 0 2008-12-01 Albury 13.4 ... No 0.0 No 1 2008-12-02 Albury 7.4 ... No 0.0 No 2 2008-12-03 Albury 12.9 ... No 0.0 No 3 2008-12-04 Albury 9.2 ... No 1.0 No 4 2008-12-05 Albury 17.5 ... No 0.2 No Шаг 3: Предварительная обработка данных
# Checking for null values print(df.count().sort_values()) [5 rows x 24 columns] Sunshine 75625 Evaporation 82670 Cloud3pm 86102 Cloud9am 89572 Pressure9am 130395 Pressure3pm 130432 WindDir9am 134894 WindGustDir 135134 WindGustSpeed 135197 Humidity3pm 140953 WindDir3pm 141232 Temp3pm 141851 RISK_MM 142193 RainTomorrow 142193 RainToday 142199 Rainfall 142199 WindSpeed3pm 142398 Humidity9am 142806 Temp9am 143693 WindSpeed9am 143693 MinTemp 143975 MaxTemp 144199 Location 145460 Date 145460 dtype: int64
Обратите внимание на вывод, он показывает, что первые четыре столбца имеют более 40% нулевых значений, поэтому лучше, если мы избавимся от этих столбцов.
Во время предварительной обработки данных всегда необходимо удалять несущественные переменные. Ненужные данные только усложнят наши вычисления. Поэтому мы удалим переменную ‘location’ и переменную ‘date’, так как они не важны для прогнозирования погоды.
Мы также удалим переменную ‘RISK_MM’, потому что мы хотим предсказать ‘RainTestival’, а RISK_MM (количество осадков на следующий день) может привести к утечке некоторой информации в нашу модель.
df = df.drop(columns=['Sunshine','Evaporation','Cloud3pm','Cloud9am','Location','RISK_MM','Date'],axis=1) print(df.shape) (145460, 17)
Далее мы удалим все нулевые значения в нашем фрейме данных.
#Removing null values df = df.dropna(how='any') print(df.shape) (112925, 17)
После удаления нулевых значений мы также должны проверить наш набор данных на наличие выбросов. Выброс – это точка данных, которая значительно отличается от других наблюдений. Выбросы обычно возникают из-за просчетов при сборе данных.
В следующем фрагменте кода мы избавляемся от выбросов:
from scipy import stats z = np.abs(stats.zscore(df._get_numeric_data())) print(z) df= df[(z < 3).all(axis=1)] print(df.shape) [[0.11756741 0.10822071 0.20666127 ... 1.14245477 0.08843526 0.04787026] [0.84180219 0.20684494 0.27640495 ... 1.04184813 0.04122846 0.31776848] [0.03761995 0.29277194 0.27640495 ... 0.91249673 0.55672435 0.15688743] ... [1.44940294 0.23548728 0.27640495 ... 0.58223051 1.03257127 0.34701958] [1.16159206 0.46462594 0.27640495 ... 0.25166583 0.78080166 0.58102838] [0.77784422 0.4789471 0.27640495 ... 0.2085487 0.37167606 0.56640283]] (107868, 17)
Далее мы будем присваивать «0» и «1» вместо «ДА» и «НЕТ».
#Change yes and no to 1 and 0 respectvely for RainToday and RainTomorrow variable df['RainToday'].replace({'No': 0, 'Yes': 1},inplace = True) df['RainTomorrow'].replace({'No': 0, 'Yes': 1},inplace = True) Теперь пришло время нормализовать данные, чтобы избежать каких-либо ошибок при прогнозировании результата. Для этого мы можем использовать функцию MinMaxScaler, которая присутствует в библиотеке sklearn.
from sklearn import preprocessing scaler = preprocessing.MinMaxScaler() scaler.fit(df) df = pd.DataFrame(scaler.transform(df), index=df.index, columns=df.columns) df.iloc[4:10] MinTemp MaxTemp Rainfall ... WindDir9am_W WindDir9am_WNW WindDir9am_WSW 4 0.628342 0.696296 0.035714 ... 0.0 0.0 0.0 5 0.550802 0.632099 0.007143 ... 1.0 0.0 0.0 6 0.542781 0.516049 0.000000 ... 0.0 0.0 0.0 7 0.366310 0.558025 0.000000 ... 0.0 0.0 0.0 8 0.419786 0.686420 0.000000 ... 0.0 0.0 0.0 9 0.510695 0.641975 0.050000 ... 0.0 0.0 0.0 [6 rows x 62 columns]
Шаг 4: Исследовательский анализ данных (EDA)
Теперь, когда мы закончили предварительную обработку набора данных, пришло время проверить выполнение анализа и определить значимые переменные, которые помогут нам предсказать результат. Для этого мы будем использовать функцию SelectKBest, присутствующую в библиотеке sklearn:
#Using SelectKBest to get the top features! from sklearn.feature_selection import SelectKBest, chi2 X = df.loc[:,df.columns!='RainTomorrow'] y = df[['RainTomorrow']] selector = SelectKBest(chi2, k=3) selector.fit(X, y) X_new = selector.transform(X) print(X.columns[selector.get_support(indices=True)]) Index(['Rainfall', 'Humidity3pm', 'RainToday'], dtype='object')
Вывод дает нам три наиболее значимых предикторных переменных:
- Rainfall
- Humidity3pm
- RainToday
Основная цель этой демонстрации – дать вам понять, как работает машинное обучение, поэтому, чтобы упростить вычисления, мы назначим в качестве входных данных только одну из этих значимых переменных.
#The important features are put in a data frame df = df[['Humidity3pm','Rainfall','RainToday','RainTomorrow']] #To simplify computations we will use only one feature (Humidity3pm) to build the model X = df[['Humidity3pm']] y = df[['RainTomorrow']]
В приведенном выше фрагменте кода «X» и «y» обозначают вход и выход соответственно.
Шаг 5: Построение модели машинного обучения
На этом этапе мы создадим модель машинного обучения, используя набор данных обучения, и оценим эффективность модели, используя набор данных тестирования.
Мы будем строить классификационные модели, используя следующие алгоритмы:
- Логистическая регрессия
- Случайный Лес
- Древо решений
- Машина опорных векторов
Ниже приведен фрагмент кода для каждой из этих моделей классификации:
Логистическая регрессия
#Logistic Regression from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import time #Calculating the accuracy and the time taken by the classifier t0=time.time() #Data Splicing X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25) clf_logreg = LogisticRegression(random_state=0) #Building the model using the training data set clf_logreg.fit(X_train,y_train) #Evaluating the model using testing data set y_pred = clf_logreg.predict(X_test) score = accuracy_score(y_test,y_pred) #Printing the accuracy and the time taken by the classifier print('Accuracy using Logistic Regression:',score) print('Time taken using Logistic Regression:' , time.time()-t0) Accuracy using Logistic Regression: 0.8330181332740015 Time taken using Logistic Regression: 0.1741015911102295Random Forest Classifier
#Random Forest Classifier from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split #Calculating the accuracy and the time taken by the classifier t0=time.time() #Data Splicing X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25) clf_rf = RandomForestClassifier(n_estimators=100, max_depth=4,random_state=0) #Building the model using the training data set clf_rf.fit(X_train,y_train) #Evaluating the model using testing data set y_pred = clf_rf.predict(X_test) score = accuracy_score(y_test,y_pred) #Printing the accuracy and the time taken by the classifier print('Accuracy using Random Forest Classifier:',score) print('Time taken using Random Forest Classifier:' , time.time()-t0) Accuracy using Random Forest Classifier: 0.8358363926280269 Time taken using Random Forest Classifier: 3.7179694175720215Классификатор дерева решений
#Decision Tree Classifier from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split #Calculating the accuracy and the time taken by the classifier t0=time.time() #Data Splicing X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25) clf_dt = DecisionTreeClassifier(random_state=0) #Building the model using the training data set clf_dt.fit(X_train,y_train) #Evaluating the model using testing data set y_pred = clf_dt.predict(X_test) score = accuracy_score(y_test,y_pred) #Printing the accuracy and the time taken by the classifier print('Accuracy using Decision Tree Classifier:',score) print('Time taken using Decision Tree Classifier:' , time.time()-t0) Accuracy using Decision Tree Classifier: 0.831423591797382 Time taken using Decision Tree Classifier: 0.0849456787109375Машина опорных векторов
#Support Vector Machine from sklearn import svm from sklearn.model_selection import train_test_split #Calculating the accuracy and the time taken by the classifier t0=time.time() #Data Splicing X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25) clf_svc = svm.SVC(kernel='linear') #Building the model using the training data set clf_svc.fit(X_train,y_train) #Evaluating the model using testing data set y_pred = clf_svc.predict(X_test) score = accuracy_score(y_test,y_pred) #Printing the accuracy and the time taken by the classifier print('Accuracy using Support Vector Machine:',score) print('Time taken using Support Vector Machine:' , time.time()-t0) Accuracy using Support Vector Machine: 0.7886676308080246 Time taken using Support Vector Machine: 88.42247271537781Все модели классификации дают нам оценку точности приблизительно 83-84%, за исключением машин опорных векторов. Учитывая размер нашего набора данных, точность довольно хорошая.
Поэтому похлопайте себя по спине, потому что теперь вы знаете, как решать проблемы с помощью машинного обучения.
Теперь давайте посмотрим на более продвинутую концепцию, называемую Deep Learning.
Прежде чем мы понять, что такое глубокое обучение, давайте разберемся с ограничениями машинного обучения. Эти ограничения породили концепцию глубокого обучения.
Ограничения машинного обучения
Ниже приведены ограничения машинного обучения:
- Машинное обучение не способно обрабатывать и обрабатывать объемные данные.
- Его нельзя использовать при распознавании изображений и обнаружении объектов, поскольку они требуют реализации многомерных данных.
- Еще одна важная задача в машинном обучении состоит в том, чтобы сообщить машине, какие важные функции следует искать, чтобы точно предсказать результат. Этот самый процесс называется извлечением признаков . Извлечение функций – это ручной процесс в машинном обучении.
Вышеуказанные ограничения могут быть устранены с помощью Deep Learning.
Почему глубокое обучение?
- Глубокое обучение – это единственный метод, с помощью которого мы можем преодолеть трудности извлечения характеристик. Это связано с тем, что модели глубокого обучения способны самостоятельно сосредоточиться на правильных особенностях, что требует минимального вмешательства человека.
- Глубокое обучение в основном используется для работы с многомерными данными. Он основан на концепции нейронных сетей и часто используется для обнаружения объектов и изображенийобработка.
Теперь давайте разберемся, как работает Deep Learning.
Как работает глубокое обучение?
Глубокое обучение имитирует основной компонент человеческого мозга, называемый мозговой клеткой или нейроном. Вдохновленно нейроном, был создан искусственный нейрон.
Глубокое обучение основано на функциональности биологического нейрона, поэтому давайте разберемся, как мы подражаем этой функциональности в искусственном нейроне (также известном как перцептрон):
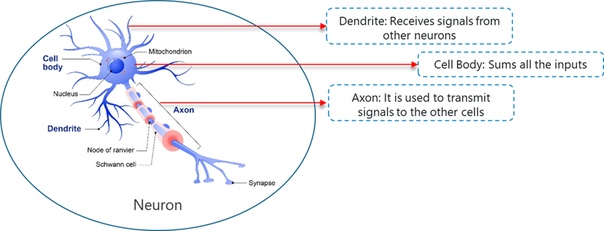
- В биологическом нейроне дендриты используются для получения входных данных. Эти входные данные суммируются в теле клетки и через аксон передаются следующему нейрону.
- Подобно биологическому нейрону, перцептрон получает несколько входов, применяет различные преобразования и функции и обеспечивает выход.
- Человеческий мозг состоит из множества связанных нейронов, называемых нейронной сетью, аналогично, благодаря объединению нескольких перцептронов, мы разработали так называемую Глубокую нейронную сеть.
Теперь давайте разберемся, что же такое Deep Learning.
Что такое глубокое обучение?
«Глубокое обучение – это набор статистических методов машинного обучения, используемых для изучения иерархий функций, основанных
на концепции искусственных нейронных сетей».
Глубокая нейронная сеть состоит из следующих слоев:
- Входной слой
- Скрытый слой
- Выходной слой
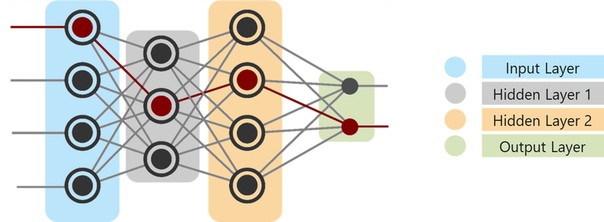
На приведенном выше рисунке
- Первый слой – это входной слой, который получает все входные данные.
- Последний слой является выходным слоем, который обеспечивает желаемый результат
- Все слои между этими слоями называются скрытыми слоями.
- Может быть n количество скрытых слоев, а количество скрытых слоев и количество перцептронов в каждом слое будет полностью зависеть от варианта использования, который вы пытаетесь решить.
Глубокое обучение используется в высокоуровневые сценарии использования, такие как проверка лица, автомобили с автоматическим управлением и т. д. Давайте поймем важность глубокого обучения, взглянув на реальный пример использования.
Случаи использования глубокого обучения
Подумайте, как PayPal использует Deep Learning для выявления возможных мошеннических действий. PayPal обработал более 235 миллиардов долларов в платежах от четырех миллиардов транзакций более чем 170 миллионов клиентов.
PayPal использовал алгоритмы машинного обучения и глубокого обучения для извлечения данных из истории покупок клиента в дополнение к проверке моделей вероятного мошенничества, хранящихся в его базах данных, чтобы предсказать, является ли конкретная транзакция мошеннической или нет.
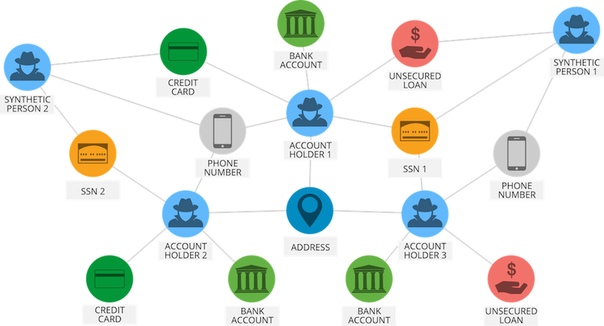
Компания использует технологии глубокого обучения и машинного обучения уже около 10 лет. Первоначально команда по мониторингу мошенничества использовала простые линейные модели. Но с годами компания перешла на более продвинутую технологию машинного обучения под названием Deep Learning.
«Что нам нравится от более современного, продвинутого машинного обучения, так это его способность потреблять намного больше данных, обрабатывать слои и слои абстракции и иметь возможность« видеть »вещи, которые не сможет увидеть более простая технология, даже люди могут не сможет видеть.
Менеджер по рискам мошенничества и специалист по данным в PayPal Ке Ван
Простая линейная модель способна потреблять около 20 переменных. Однако с технологией Deep Learning можно управлять тысячами точек данных.
«Разница велика – вы сможете анализировать гораздо больше информации и выявлять более сложные модели»
Ке Ван.
Поэтому, благодаря технологии глубокого обучения, PayPal может проанализировать миллионы транзакций для выявления любых мошеннических действий.
Чтобы лучше понять Deep Learning, давайте разберемся, как работает Perceptron.
Что такое перцептрон?
Перцептрон – это однослойная нейронная сеть, которая используется для классификации линейных данных. Перцептрон имеет 4 важных компонента:
- Вход
- Вес и уклон
- Функция суммирования
- Функция активации или преобразования
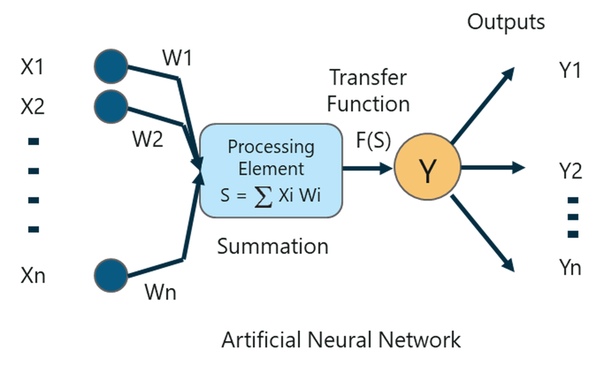
Основная логика перцептрона заключается в следующем:
Входы (x), полученные от входного слоя, умножаются на присвоенные им веса w. Умноженные значения затем добавляются для формирования взвешенной суммы. Взвешенная сумма входов и их соответствующие веса затем применяются к соответствующей функции активации. Функция активации отображает вход на соответствующий выход.
Вес и уклон в глубоком обучении
Почему мы должны присваивать вес каждому входу?
Как только входная переменная подается в сеть, в качестве веса этого входа назначается случайно выбранное значение. Вес каждой точки входных данных указывает, насколько важен этот вход для прогнозирования результата.
С другой стороны, параметр смещения позволяет настроить кривую функции активации таким образом, чтобы получить точный выходной сигнал.
Функция суммирования
Как только входам назначен некоторый вес, берется произведение соответствующего входа и веса. Добавление всех этих продуктов дает нам взвешенную сумму. Это делается с помощью функции суммирования.
Функция активации
Основная цель функций активации – отобразить взвешенную сумму на выход. Функции активации, такие как tanh, ReLU, sigmoid и т. д., Являются примерами функций преобразования.
Чтобы узнать больше о функциях Перцептронов, вы можете пройти посмотреть статью Deep Learning: Perceptron Learning Algorithm .
Теперь давайте разберемся в концепции многослойных персептронов.
Почему используется многослойный персептрон?
Одиночный слой Перцептроны не способны обрабатывать данные больших размеров, и их нельзя использовать для классификации нелинейно разделимых данных.
Поэтому сложные проблемы, которые включают большое количество параметров, могут быть решены с помощью многослойных персептронов.
Что такое многослойный персептрон?
Многослойный персептрон – это классификатор, который содержит один или несколько скрытых слоев и основан на искусственной нейронной сети Feedforward. В сетях с прямой связью каждый уровень нейронной сети полностью связан со следующим уровнем.
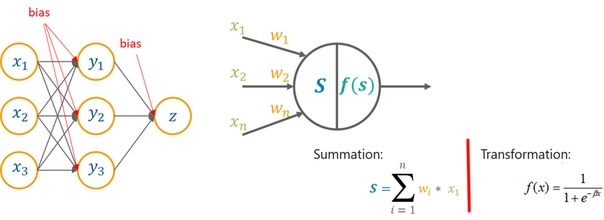
Как работает многослойный персептрон?
В многослойном персептроне веса, назначенные каждому входу в начале, обновляются, чтобы минимизировать результирующую ошибку в вычислениях.
Это сделано потому, что изначально мы произвольно назначаем значения веса для каждого входа, эти значения веса, очевидно, не дают нам желаемого результата, поэтому необходимо обновить веса таким образом, чтобы результат был точным.
Этот процесс обновления весов и обучения сетей известен как Backpropagation .
Обратное распространение – логика многослойных персептронов. Этот метод используется для обновления весов таким образом, что наиболее значимая входная переменная получает максимальный вес, тем самым уменьшая ошибку при вычислении выходных данных.
Глубокое обучение с Python
Чтобы подвести итог, как работает Deep Learning, давайте рассмотрим реализацию Deep Learning с Python.
Постановка задачи: изучить набор данных банковского кредита и определить, является ли транзакция мошеннической или нет на основании прошлых данных.
Описание набора данных: набор данных описывает транзакции, совершенные европейскими держателями карт в 2013 году. Он содержит подробности транзакций за два дня, когда из 284 807 транзакций было совершено 492 мошеннических действия.
Логика: для построения нейронной сети, которая может классифицировать транзакцию как мошенническую или не основанную на прошлых транзакциях.
Теперь, когда вы знаете цель этой демонстрации, давайте приступим к демонстрации.
Шаг 1: Импортируйте необходимые пакеты
#Import requires packages import numpy as np import pandas as pd import os os.environ["TF_CPP_MIN_LOG_LEVEL"]="3" from sklearn.utils import shuffle import matplotlib.pyplot as plt # Import Keras, Dense, Dropout from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout import matplotlib.pyplot as plt import seaborn as sns from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score , fbeta_score, classification_report, confusion_matrix, precision_recall_curve, roc_auc_score , roc_curve
Шаг 2: Загрузите набор данных
# Import the dataset df_full = pd.read_csv('C://Users//NeelTemp//Desktop//ai with python//creditcard.csv') # Print out first 5 row of the data set print(df_full.head(5)) Time V1 V2 V3 ... V27 V28 Amount Class 0 0.0 -1.359807 -0.072781 2.536347 ... 0.133558 -0.021053 149.62 0 1 0.0 1.191857 0.266151 0.166480 ... -0.008983 0.014724 2.69 0 2 1.0 -1.358354 -1.340163 1.773209 ... -0.055353 -0.059752 378.66 0 3 1.0 -0.966272 -0.185226 1.792993 ... 0.062723 0.061458 123.50 0 4 2.0 -1.158233 0.877737 1.548718 ... 0.219422 0.215153 69.99 0IВ приведенном выше описании целевой переменной является переменная «Class». Может содержать два значения:
- Class 0: обозначает, что транзакция не является мошеннической
- Class 1: обозначает, что транзакция является мошеннической
Остальные переменные являются переменными предикторами, которые помогут нам понять, является ли транзакция мошеннической или нет.
# Count the number of samples for each class (Class 0 and Class 1) print(df_full.Class.value_counts()) 0 284315 1 492 Name: Class, dtype: int64
Приведенный выше вывод показывает, что у нас около 284 тыс не мошеннических транзакций и «492» мошеннических транзакций. Разница между этими двумя классами огромна, и это делает наш набор данных очень несбалансированным. Поэтому мы должны выбрать наш набор данных таким образом, чтобы количество мошеннических и не мошеннических транзакций было сбалансированным.
Для этого мы можем использовать метод статистической выборки, называемый стратифицированной выборкой .
Шаг 3: Подготовка данных
#Sort the dataset by "class" to apply stratified sampling df_full.sort_values(by='Class', ascending=False, inplace=True)
Далее мы удалим столбец времени, поскольку он не нужен для прогнозирования выходных данных.
# Remove the "Time" coloumn df_full.drop('Time', axis=1, inplace=True) # Create a new data frame with the first "3000" samples df_sample = df_full.iloc[:3000, :] # Now count the number of samples for each class print(df_sample.Class.value_counts()) 0 2508 1 492 Name: Class, dtype: int64Наш набор данных выглядит хорошо сбалансированным.
#Randomly shuffle the data set shuffle_df = shuffle(df_sample, random_state=42)
Шаг 4: Сплайсинг данных
Сплайсинг данных – это процесс разделения набора данных на данные обучения и тестирования.
# Spilt the dataset into train and test data frame df_train = shuffle_df[0:2400] df_test = shuffle_df[2400:] # Spilt each dataframe into feature and label train_feature = np.array(df_train.values[:, 0:29]) train_label = np.array(df_train.values[:, -1]) test_feature = np.array(df_test.values[:, 0:29]) test_label = np.array(df_test.values[:, -1]) # Display the size of the train dataframe print(train_feature.shape) (2400, 29) # Display the size of test dataframe print(train_label.shape) (2400,)
Шаг 5: Нормализация данных
# Standardize the features coloumns to increase the training speed scaler = MinMaxScaler() scaler.fit(train_feature) train_feature_trans = scaler.transform(train_feature) test_feature_trans = scaler.transform(test_feature) # A function to plot the learning curves def show_train_history(train_history, train, validation): plt.plot(train_history.history[train]) plt.plot(train_history.history[validation]) plt.title('Train History') plt.ylabel(train) plt.xlabel('Epoch') plt.legend(['train', 'validation'], loc='best') plt.show()Шаг 6: Построение нейронной сети
В этой демонстрации мы создадим нейронную сеть, содержащую 3 полностью связанных слоя с Dropout. Первый и второй уровни имеют 200 нейронных блоков с ReLU в качестве функции активации, а третий уровень, то есть выходной слой, имеет один нейронный блок.
Для построения нейронной сети мы будем использовать пакет Keras, который мы обсуждали ранее. Тип модели будет последовательным, что является самым простым способом построения модели в Керасе. В последовательной модели каждому слою присваиваются веса таким образом, что веса в следующем слое соответствуют предыдущему слою.
#Select model type model = Sequential()
Далее мы будем использовать функцию add() для добавления плотных слоев. «Плотный»(Dense) – это самый базовый тип слоя, который подходит для большинства случаев. Все узлы в плотном слое спроектированы так, что узлы в предыдущем слое соединяются с узлами в текущем слое.
# Adding a Dense layer with 200 neuron units and ReLu activation function model.add(Dense(units=200, input_dim=29, kernel_initializer='uniform', activation='relu')) # Add Dropout model.add(Dropout(0.5))
Выпадение(Dropout) – это метод регуляризации, используемый для избежания перегрузки в нейронной сети. В этой технике, где случайно выбранные нейроны сбрасываются во время тренировки.
# Second Dense layer with 200 neuron units and ReLu activation function model.add(Dense(units=200, kernel_initializer='uniform', activation='relu')) # Add Dropout model.add(Dropout(0.5)) # The output layer with 1 neuron unit and Sigmoid activation function model.add(Dense(units=1, kernel_initializer='uniform', activation='sigmoid')) # Display the model summary print(model.summary()) Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 200) 6000 _________________________________________________________________ dropout_1 (Dropout) (None, 200) 0 _________________________________________________________________ dense_2 (Dense) (None, 200) 40200 _________________________________________________________________ dropout_2 (Dropout) (None, 200) 0 _________________________________________________________________ dense_3 (Dense) (None, 1) 201 ================================================================= Total params: 46,401 Trainable params: 46,401 Non-trainable params: 0
Для оптимизации мы будем использовать оптимизатор Adam (встроенный в Keras). Оптимизаторы используются для обновления значений веса и параметров байса во время тренировки модели.
# Using 'Adam' to optimize the Accuracy matrix model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Fit the model # number of epochs = 200 and batch size = 500 train_history = model.fit(x=train_feature_trans, y=train_label, validation_split=0.8, epochs=200, batch_size=500, verbose=2) Train on 479 samples, validate on 1921 samples Epoch 1/200 - 1s - loss: 0.6916 - acc: 0.5908 - val_loss: 0.6825 - val_acc: 0.8360 Epoch 2/200 - 0s - loss: 0.6837 - acc: 0.7933 - val_loss: 0.6717 - val_acc: 0.8360 Epoch 3/200 - 0s - loss: 0.6746 - acc: 0.7996 - val_loss: 0.6576 - val_acc: 0.8360 Epoch 4/200 - 0s - loss: 0.6628 - acc: 0.7996 - val_loss: 0.6419 - val_acc: 0.8360 Epoch 5/200 - 0s - loss: 0.6459 - acc: 0.7996 - val_loss: 0.6248 - val_acc: 0.8360 # Display the accuracy curves for training and validation sets show_train_history(train_history, 'acc', 'val_acc')
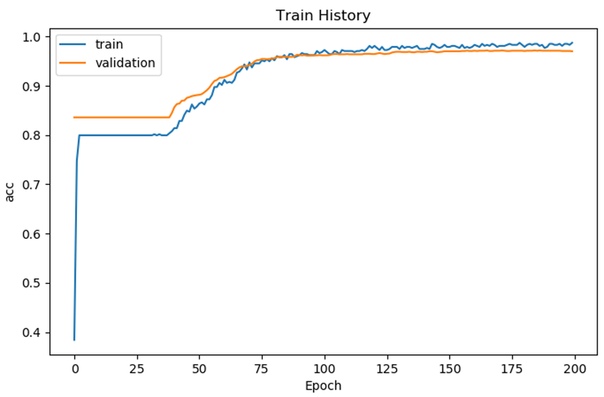
# Display the loss curves for training and validation sets show_train_history(train_history, 'loss', 'val_loss')
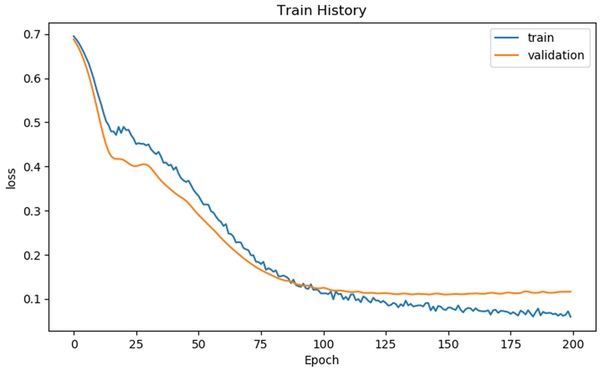
Шаг 7: Оценка модели
# Testing set for model evaluation scores = model.evaluate(test_feature_trans, test_label) # Display accuracy of the model print('n') print('Accuracy=', scores[1]) Accuracy= 0.98 prediction = model.predict_classes(test_feature_trans) df_ans = pd.DataFrame({'Real Class': test_label}) df_ans['Prediction'] = prediction df_ans['Prediction'].value_counts() df_ans['Real Class'].value_counts() cols = ['Real_Class_1', 'Real_Class_0'] # Gold standard rows = ['Prediction_1', 'Prediction_0'] # Diagnostic tool (our prediction) B1P1 = len(df_ans[(df_ans['Prediction'] == df_ans['Real Class']) & (df_ans['Real Class'] == 1)]) B1P0 = len(df_ans[(df_ans['Prediction'] != df_ans['Real Class']) & (df_ans['Real Class'] == 1)]) B0P1 = len(df_ans[(df_ans['Prediction'] != df_ans['Real Class']) & (df_ans['Real Class'] == 0)]) B0P0 = len(df_ans[(df_ans['Prediction'] == df_ans['Real Class']) & (df_ans['Real Class'] == 0)]) conf = np.array([[B1P1, B0P1], [B1P0, B0P0]]) df_cm = pd.DataFrame(conf, columns=[i for i in cols], index=[i for i in rows]) f, ax = plt.subplots(figsize=(5, 5)) sns.heatmap(df_cm, annot=True, ax=ax, fmt='d') plt.show()
# Making x label be on top is common in textbooks. ax.xaxis.set_ticks_position('top') print('Total number of test cases: ', np.sum(conf)) Total number of test cases: 600 # Model summary function def model_efficacy(conf): total_num = np.sum(conf) sen = conf[0][0] / (conf[0][0] + conf[1][0]) spe = conf[1][1] / (conf[1][0] + conf[1][1]) false_positive_rate = conf[0][1] / (conf[0][1] + conf[1][1]) false_negative_rate = conf[1][0] / (conf[0][0] + conf[1][0]) print('Total number of test cases: ', total_num) Total number of test cases: 600 print('G = gold standard, P = prediction') # G = gold standard; P = prediction print('G1P1: ', conf[0][0]) print('G0P1: ', conf[0][1]) print('G1P0: ', conf[1][0]) print('G0P0: ', conf[1][1]) print('--------------------------------------------------') print('Sensitivity: ', sen) print('Specificity: ', spe) print('False_positive_rate: ', false_positive_rate) print('False_negative_rate: ', false_negative_rate)Вывод:
G = gold standard, P = prediction G1P1: 74 G0P1: 5 G1P0: 7 G0P0: 514 -------------------------------------------------- Sensitivity: 0.9135802469135802 Specificity: 0.9865642994241842 False_positive_rate: 0.009633911368015413 False_negative_rate: 0.08641975308641975
Как видите, мы достигли точности 98%, что очень хорошо.
Так что это было все для демонстрации глубокого обучения.
Теперь давайте сосредоточимся на последнем модуле, где я представлю обработку естественного языка.
Что вы подразумеваете под обработкой естественного языка?
Обработка естественного языка (NLP) – это наука об извлечении полезной информации из текста на естественном языке для анализа и анализа текста.
НЛП использует концепции информатики и искусственного интеллекта для изучения данных и получения из них полезной информации. Это то, что компьютеры и смартфоны используют для понимания нашего языка, как разговорного, так и письменного.
Прежде чем мы поймем, где используется НЛП, позвольте мне прояснить распространенное заблуждение. Люди часто путаются между Text Mining и NLP.
В чем разница между Text Mining и NLP?
- Text Mining – это процесс получения полезной информации из текста.
- NLP (Обработка естественного языка) – это метод, используемый для анализа и анализа текста.
Таким образом, мы можем сказать, что текст Text Mining может осуществляться с использованием различных методологий НЛП.
Теперь давайте разберемся, где используется НЛП.
Приложения для обработки естественного языка
Вот список реальных приложений, которые используют методы НЛП:
- Сентиментальный анализ: внедряя технологических гигантов NLP, таких как Amazon и Netflix, узнайте у своих клиентов, как улучшить свои продукты, и дайте лучшие рекомендации.
- Чатбот: Чатботы становятся популярными в сфере обслуживания клиентов. Популярным примером является Eva, чат-робот HDFC, который обработал более 3 миллионов запросов клиентов, взаимодействовал с более чем полумиллионом уникальных пользователей и провел более миллиона разговоров.
- Распознавание речи: НЛП широко используется в распознавании речи, мы все знаем об Алексе, Сири, помощнике Google и Кортане. Они все приложения НЛП.
- Машинный перевод: популярный переводчик Google использует обработку естественного языка для обработки и перевода одного языка на другой. Он также используется для проверки орфографии, поиска по ключевым словам, извлечения информации.
- Соответствие рекламы: НЛП также используется в согласовании рекламы, чтобы рекомендоватьобъявления на основе истории поиска.
Теперь давайте разберемся с важными понятиями в НЛП.
Терминологии в обработке естественного языка
В этом разделе я рассмотрю все основные термины в рамках НЛП. Следующие процессы используются для анализа естественного языка с целью получения некоторых значимых идей:
Токенизация
Токенизация в основном означает разбиение данных на более мелкие порции или токены, чтобы их можно было легко анализировать.
Например, предложение «Tokens are simple» можно разбить на следующие токены:
- Tokens
- Are
- Simple
Выполняя токенизацию, вы можете понять важность каждого токена в предложении.
Стемминг
Стемминг – процесс обрезания префиксов и суффиксов слова и учета только корневого слова.
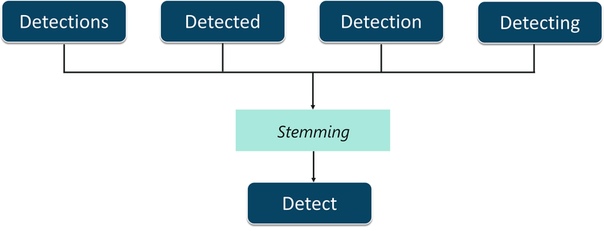
Давайте разберемся с этим на примере. Как показано на рисунке, слова,
- Обнаружение
- Детектирование
- Обнаруженный
- Обнаружения
все это может быть урезано до их корня слова, то есть обнаружить . Stemming помогает в редактировании таких слов, так что анализ документа становится проще. Тем не менее, этот процесс может быть успешным в некоторых случаях. Поэтому используется другой процесс, называемый лемматизацией.
Лемматизации
Лемматизация похожа на определение, однако она более эффективна, поскольку учитывает морфологический анализ слов. Вывод лемматизации – правильное слово.
Пример лемматизации: слова «ушел», «идет» и «ушел» переводятся в слово «уйти» с помощью лемматизации.
Стоп-Слова
Стоп-слова – это набор часто используемых слов на любом языке. Стоп-слова имеют решающее значение для анализа текста и должны быть удалены, чтобы лучше понять любой документ. Логика заключается в том, что если из документа удаляются часто используемые слова, мы можем сосредоточиться на наиболее важных словах.

Например, допустим, вы хотите сделать клубничный молочный коктейль. Если вы откроете Google и введете «как приготовить молочный коктейль из клубники», вы получите результаты «как» сделать «клубничный» молочный коктейль. Даже если вы хотите получить результаты только для клубничного молочного коктейля. Эти слова называются стоп-словами. Всегда лучше избавиться от таких слов перед выполнением любого анализа.
Если вы хотите узнать больше об обработке естественного языка, вы можете посмотреть это видео нашими экспертами по НЛП.
Телеграм: t.me/ainewsline
Источник: m.vk.com