Новые возможности Python 3.9: мнения экспертов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-06-13 12:01

Новый релиз языка программирования Python 3.9 случится ещё нескоро (ожидаемая дата – 5 октября), но одна за другой выходят бета-версии. Давайте посмотрим, какие улучшения и исправления мы можем ожидать. В этой статье представлен список наиболее интересных и примечательных вещей, которые должны появиться в версии 3.9.
Несмотря на то, что Гвидо сложил с себя полномочия «великодушного пожизненного диктатора», в этой версии автор языка оказал существенное влияние на выбор нового парсера. Вот как об этом пишет Адиль Хаштамов:
Начиная с Python 3.9 для парсинга используется PEG, ранее использовали LL. Выигрыша в производительности нет, но благодаря PEG в будущем возможно вводить более гибкие конструкции в язык. Модуль ast уже использует PEG для разбора исходного кода скрипта. Одним из инициаторов этого PEP был наш любимый Гвидо, у него в блоге есть целая серия постов на эту тему.
Установка бета-версии
Чтобы попробовать бета-версию Python 3.9, сначала её нужно установить. В идеале – без конфликтов с текущей версией Python. Последнюю версию можно найти на странице загрузки (названия файлов начинаются с python-3.9.0b). Например, на Linux установить версию локально без конфликтов с текущей версией можно следующим набором команд:
wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0b3.tgz tar xzvf Python-3.9.0b3.tgz cd Python-3.9.0b3 ./configure --prefix=$HOME/python-3.9.0b3 make make install $HOME/python-3.9.0b3/bin/python3.9 После выполнения последней команды появится классическое приветствие:
Python 3.9.0b3 (default, Jun 10 2020, 9:48:15) [GCC 7.5.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> Новые операторы словаря
Наиболее заметной новинкой является операторы слияния словарей | и |=. До сих пор нам приходилось выбирать один из трёх вариантов объединения словарей:
>>> # Словари, которые нужно соединить вместе: >>> d1 = {'x': 1, 'y': 4, 'z': 10} >>> d2 = {'a': 7, 'b': 9, 'x': 5} >>> # Ожидаемый результат после слияния: >>> d = {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9} >>> # Обратите внимание, что 'x' переопределяется значением второго словаря >>> # Первый способ: >>> d = dict(d1, **d2) >>> # Второй способ: >>> d = d1.copy() # cоздаём копию первого словаря >>> d.update(d2) # обновляем его "на месте" значениями второго словаря >>> # Третий способ: >>> d = {**d1, **d2} Первый вариант использует функцию инициализации словарей dict(iterable, **kwargs). Первый аргумент – обычный словарь, второй – список пары ключ/значение, в данном случае просто ещё один словарь, распакованный с использованием оператора **.
Второй подход использует метод update для обновления первого словаря парами ключ – значение из второго словаря. Поскольку update модифицирует словарь «на месте», нужно скопировать первый словарь в конечную переменную, чтобы избежать изменения оригинала.
Третий и, похоже, самый ясный способ – распаковать обе переменные d1 и d2 в результирующую переменную d.
Все приведенные варианты работают, но теперь есть более удобное решение:
>>> # Обычное слияние >>> d = d1 | d2 >>> d {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9} >>> # Слияние и поглощение =) >>> d1 |= d2 >>> d1 {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9} Первый пример похож на вариант с распаковкой d = {** d1, ** d2}. Второй пример может использоваться для объединения данных на месте, когда исходная переменная d1 обновляется значениями из второго операнда d2.
Видимо, разработчики Python посчитали способ
{**dict1, **dict2}не совсем удобным, и предложили в версии 3.9 при объединении словарей использовать синтаксис объединения сетов:dict1 | dict2, который используется и в более ранних версиях, чем 3.9.
Полноценный type hinting из коробки
В версии 3.9 для аннотации типов встроенных коллекций таких, как list и dict больше не нужно импортировать специальные типы (List, Dict и др.) из модуля typing:
>>> def greet_all(names: list[str]) -> None: ... for name in names: ... print("Hello, ", name) ... >>> greet_all(names=["Leo", "proglib.io readers"]) Hello, Leo Hello, proglib.io readers Минус целая пачка импортов! Просто потрясающе – за это я благодарен разработчикам версии 3.9. Я очень люблю тайп-хинтинги: это упрощает разработку и делает её более надёжной. Сейчас тайп-хинтинги можно использовать гораздо проще, чем раньше.
Топологическая сортировка
Следующая интересная новинка является частью модуля functools – класс TopologicalSorter. Класс упорядочивает граф, используя топологическую сортировку. Это такой порядок узлов, когда для двух любых узлов графа u и v, соединенных направленным ребром от u к v, u в последовательности предшествует v.
Ранее подобную задачу приходилось решать самостоятельно, используя сортировку Хана или поиск в глубину, то есть далеко не самые простые алгоритмы. Теперь в случае необходимости, например, при планировании зависящих друг от друга заданий, достаточно сделать следующее:
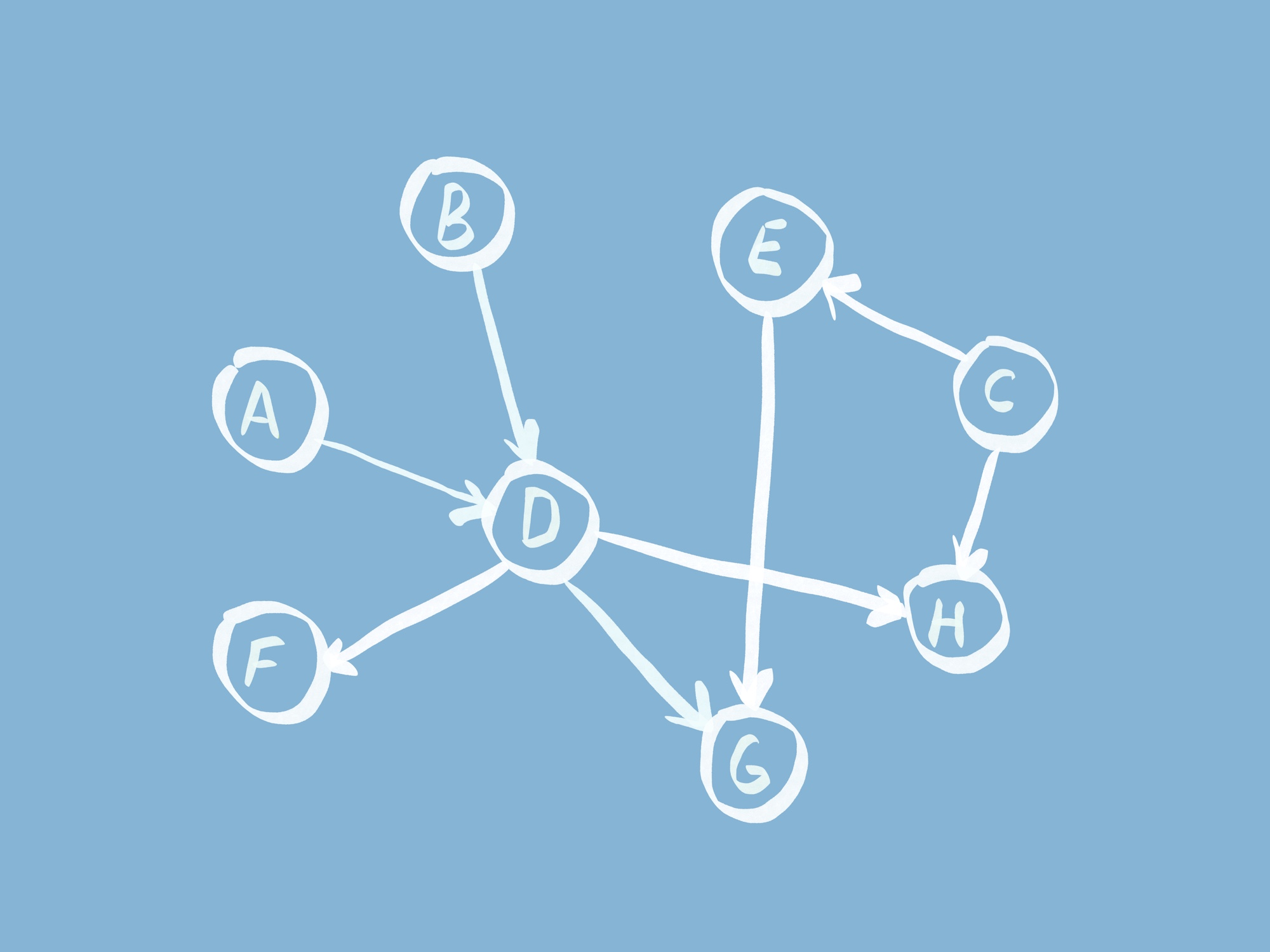
В приведенном примере мы описали граф, используя словарь, в котором ключи – это исходящие узлы, а значения – наборы их соседей. Затем мы создали экземпляр сортировщика графа и вызвали функцию static_order.
Нужно помнить, что при топологической сортировке порядок элементов неоднозначен: когда несколько узлов находятся на одном уровне графа, они возвращаются в том же порядке, в котором были добавлены в граф.
Помимо статического упорядочения, класс поддерживает параллельную обработку узлов. Это удобно при работе с очередями задач – примеры можно найти в обновленной документации библиотеки functools.
Главный вопрос – почему класс оказался именно в functools? В обсуждениях к публикации «Что нового ожидается в Python 3.9» её автор, пользователь Хабра elmos, отвечает следующим образом:
В bugs.python.org/issue17005 единственное побуждение положить в functools аргументировано тем, что топологическая сортировка «is somewhat related to total ordering», но большого обсуждения, куда бы лучше положить этот класс, судя по всему, не было.
Адреса IPv6 с параметром scope
Еще одно улучшение, появившееся в Python 3.9, – возможность указывать область адресов IPv6 (scope). Область может быть указана в конце IP-адреса с помощью знака процента – например: 3FFE:0:0:1:200:F8FF:FE75:50DF%2 – этот IP-адрес находится в области 2 и соответствует локальному адресу.
>>> from ipaddress import IPv6Address >>> addr = IPv6Address('ff02::fa51%2') >>> print(addr.scope_id) 2 Два адреса с разными параметрами scope не равны друг другу при использовании обычных операторов сравнения Python.
Новые функции модуля math
Несколько функций было добавлено и улучшено в модуле math. Например, расширены возможности функции поиска наибольшего общего делителя (НОД):
>>> import math >>> math.gcd(80, 64, 152) 8 Ранее функция math.gcd() могла вычислить НОД лишь для двух чисел. Если требовалось вычислить три и больше, приходилось делать что-то вроде math.gcd(80, math.gcd(64, 152)). Теперь функции math.gcd() можно передать любое число аргументов.
Добавлена новая функция поиска наименьшего общего кратногоmath.lcm(), которая так же, как math.gcd(), принимает любое число аргументов:
>>> import math >>> math.lcm(4, 8, 5) 40 Другие две новые функции тесно связаны между собой. Это math.nextafter() и math.ulp():
>>> math.nextafter(4, 5) 4.000000000000001 >>> math.nextafter(9, 0) 8.999999999999998 >>> math.ulp(1000000000000000) 0.125 >>> math.ulp(3.14159265) 4.440892098500626e-16 Действие функции math.nextafter(x, y) выглядит довольно просто. Она возвращает ??следующее число типа float, идущее после x в направлении к числу y (с учетом точности чисел с плавающей точкой).
Функцию math.ulp() можно использовать в качестве меры точности численных расчетов для данного числа. Сокращение ulp соответствует Unit in the last place – особому математическому интервалу между соседними float-числами. Этот интервал зависит от величины числа и способа представления чисел в конкретной операционной системе.
Новые строковые функции
Для работы со строками в языке программирования Python в последней версии добавлена пара удобных вспомогательных функций:
>>> # удалим префикс >>> "someText".removeprefix("some") 'Text' >>> # удалим суффикс >>> "someText".removesuffix("Text") 'some' Раньше в Python тех же результатов можно было достичь, используя подобную функцию:
if test_func_name.startswith("some"): print(test_func_name[4:]) else: print(test_func_name) Это простые операции, но, учитывая их распространенность, удобно иметь под рукой встроенные функции.
Помимо всех прочих нововведений в версии 3.9 нас ждал ещё один «сюрприз» – теперь новые версии будут выходить не раз в 18 месяцев, как раньше, а каждый год. Это означает, что новых «фич» теперь будут добавлять, скорее всего, меньше. Зато обновления не будут такими болезненными.
Мне из всех нововведений версии 3.9 самыми полезными показались новые операторы для работы со словарями и новые функции для обработки строк – я очень долго ждал что-то похожее наremoveprefix()иremovesuffix().
Коды состояния HTTP
Текстовые описания кодов состояний HTTP добавлены в http.HTTPStatus.
>>> import http >>> http.HTTPStatus.NOT_FOUND <HTTPStatus.NOT_FOUND: 404> >>> http.HTTPStatus.EARLY_HINTS <HTTPStatus.EARLY_HINTS: 103> >>> http.HTTPStatus.TOO_EARLY <HTTPStatus.TOO_EARLY: 425> >>> http.HTTPStatus.IM_A_TEAPOT <HTTPStatus.IM_A_TEAPOT: 418> Да, названия и назначения некоторых статусов довольно забавны, но для критичных кодов это позволяет делать их обработку более явной.
Заключение
Конечно, изменений произошло гораздо больше, но вряд ли имеет смысл перечислять все. Ведь с полным перечнем обновлений в Python 3.9 можно ознакомиться в статье официальной документации. Нельзя сказать, что какое-либо изменение имеет критическое значение – просто программирование на Python становится ещё удобнее и эффективнее.
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io