Мама мыла LSTM: как устроены рекуррентные нейросети с долгой краткосрочной памятью
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-06-17 20:00
алгоритмы машинного обучения, Основы нейронных сетей, Нейронные сети для начинающих

Этот текст — про то, что такое языковая модель и зачем она нужна. Еще расскажем, почему рекуррентная нейросеть (RNN), хорошо подходит под машинную обработку языка и как работает LSTM — усложненная модель RNN.
Зачем обрабатывать текст на компьютере
Чтобы научить его подражать человеку
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов. Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».

Как использовать неслучайность речи?
Можно предсказывать самые вероятные слова
В компьютерной лингвистике есть понятие «языковая модель». Она описывает вероятность встретить в речи человека данную последовательность слов или символов. Насколько вероятно, что произвольный набор слов может быть нормальным предложением?
Языковые модели полезны: они могут, например, генерировать текст. Допустим, известно, что первое слово в предложении — «кошка». В базе данных языковой модели указано, что если «кошка» — часть последовательности, то после нее будет стоять слово «села». Записываем в блокноте слова «кошка села» и снова подаем на вход языковой модели. Модель знает, что после «кошка села» вероятнее всего встретить слово «на», а после «кошка села на» — слово «такси». Кошка села на такси.
Идея в том, чтобы итеративно (шаг за шагом) давать языковой модели дополнять самым вероятным следующим словом то, что она написала на предыдущем шаге. Типичный пример — клавиатура GBoard. Автор этого текста ввел на клавиатуре слово «английский» — модель предложила продолжение «язык». Дальше автор слово за словом дополнял фразу подсказками от модели, пока не получилось «английский язык аж в общем я не могу найти в интернете». Все такое видели. На вашем телефоне результат может быть иным, потому что GBoard запоминает цепочки введенных слов и обучается на них (если стоит соответствующая галочка в настройках). Но почему получается такая бессмыслица?
Вкратце: чтобы сделать хорошо, нужно учитывать больше контекста, а не одно-два последних слова. Но это уже не реализуешь «в лоб».
Языковая модель без нейросетей
Цепи Маркова
Языковая модель под капотом у экранной клавиатуры — несложная по сравнению с большими современными нейросетями, до которых мы еще доберемся. Как именно языковая модель решает, возможно ли после «манная» найти слово «каша»? Очень популярный вариант — использовать цепи Маркова (скорее всего, в вашем смартфоне они и используются — это гораздо легче нейросетей, а результат часто не сильно уступает).
Для этого разбиваем большой текст на биграммы (куски по два слова подряд) и смотрим, ага, биграмма «солнце ярко» встретилось 100 раз, а все остальные биграммы с «солнцем» — гораздо меньше. Может, в этом тексте часто повторяли «солнце ярко светило». А иногда было «взошло солнце. Запели петухи»: Тогда нужная нам биграмма получится «солнце запели». Но она встречалась реже, а после «солнца» чаще всего стоит «ярко». Так и запишем. В следующий раз после «солнца» подставим «ярко».
Если у разработчика мощные компьютеры, он может смотреть не на одно, а на три, на пять, на десять слов назад и все их учитывать. Но резко возрастает сложность вычислений: если в словаре сто слов, и для каждого из них мы записали самое вероятное следующее, это сто записей. Если же в словаре сто слов, и мы хотим смотреть на два слова назад, как на цельную последовательность, придется сохранять в словаре все комбинации из двух слов, то есть 100 в квадрате (10000), и писать самое вероятное следующее для каждой из них. Для трех слов назад — сто в кубе вариантов (1000000) комбинаций и так далее.
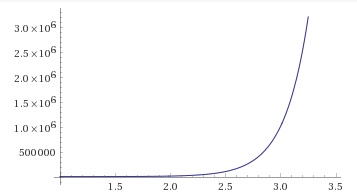
Дела еще усложняются, если учесть, что сохраняем не только самое вероятное следующее слово, а несколько самых вероятных, а то и распределение вероятностей для всего словаря, да и словарь содержит не сто слов. В общем, у такой языковой модели очень короткая память, иначе она сразу сжигает компьютер.
Поэтому важная задача разработчика языковой модели — обеспечить ей «долгосрочную память». Одно из решений — рекуррентные нейросети.
Что такое рекуррентность?
Рекуррентность нейросети означает, что она смотрит на свою работу в прошлом
Почему нейросеть — рекуррентная? Рекуррентный — значит, регулярно к чему-то возвращающийся. Рекуррентная нейросеть возвращается к своей работе с прошлого шага, потому и получила свое название.
Условимся, что работаем с текстом и хотим дописывать его по одному слову, опираясь на предыдущие слова. Как раньше делали с экранной клавиатурой, только теперь с нейросетью. Нейросеть не понимает человеческие слова, для работы с ней их нужно закодировать в виде векторов, то есть наборов чисел.
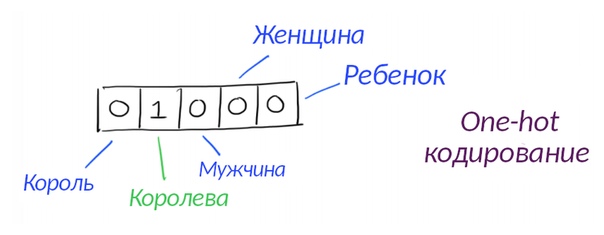
Вот простой способ: считаем слова в словаре, с которым мы работаем: допустим, их сто. Нарисуем сто нулей и посмотрим, какой номер по алфавиту у слова, которое мы кодируем. Оно 53-е. Тогда среди ста нулей заменим 53-й ноль на единицу, получится вектор вроде 000010000, только длиннее. Такой подход называется one-hot кодированием, и он не очень крутой, потому что вектор выходит слишком уж длинный.
Более продвинутый вариант — взять вектора, полученные через word2vec, FastText или другие алгоритмы кодирования, о них мы писали ранее. В них внутрь вектора «зашивается» информация о синонимах слова и его семантических отношениях с другими словами. Как именно эта информация туда попадает — читайте в наших статьях по ссылкам (1, 2).
Нейросеть — это несколько групп (слоев) нейронов. С отдельным нейроном никто не работает: в компьютере хранятся и обрабатываются вектора (одномерные строки из чисел), матрицы (двумерные таблицы) или тензоры (трехмерные «стопки» из матриц). Мы упростим и будем писать, что везде вектор или матрица. Для разработчика важно, что нейрон — это число, которое надо хранить, изменять и куда-то передавать.
Когда слово попадает на слой нейросети, некоторые нейроны меняют значение (активируются) и по картине активации предсказывается словарный номер следующего слова в тексте. Сначала это случайные активации и случайные слова, но после обучения нейросети мера ошибки уменьшится, и слова будут похожи на правду. Активироваться (можете представить себе, что они включаются или загораются как лампочки) будут уже не случайные нейроны, а вполне конкретные. Ага, получается, если тренированная нейросеть получает слово «мыла» после слова «мама», всегда зажигаются вон те 15 нейронов. Наверное, в этом есть какой-то смысл? Да, смысл есть. Если слово активирует одни и те же нейроны, активацию (состояние нейронов) можно рассматривать как «след» контекста.


RNN сохраняет свое состояние и передает его дальше
В RNN есть числовой вектор (т.е. список циферок), где хранится память о контексте: сохраним его и сделаем входными данными на следующем слое.
Вот важный момент: состояния нейронов в слое представим вектором из нулей и единиц (подряд выписав состояния). Перед началом работы все слои либо деактивированы (вектор 0000000000000, нулей в нем — по количеству нейронов в слое), либо заданы случайно.
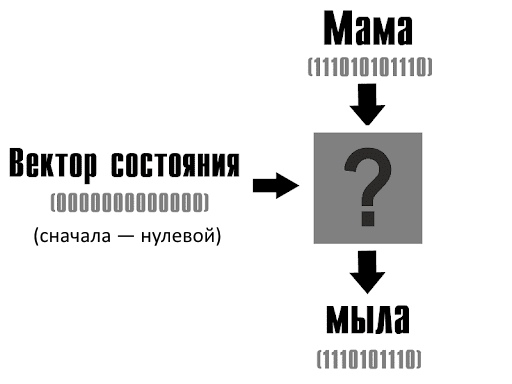
На вход подается первое слово — мама. Некоторые нейроны активируются согласно правилу (функции активации), которое определил разработчик. Функция «перемалывает» только вектора, а от самих слов уже ничего не осталось, поэтому нельзя сказать, что один нейрон реагирует на букву «с», а другой — на третий символ с конца. Слой нейронов выдает вектор — это код следующего слова (мыла), предсказание нейросети. Поскольку некоторые нейроны слоя активировались, вектор «состояния» поменялся, там появились единицы: 01001110100. В этих единицах зашифрованы данные о том, что первым словом была «мама».
Теперь мы хотим угадать третье слово (мама мыла что? — раму!) с учетом догадки о втором слове и контекста до него. Для этого на следующий слой подаем старый вектор состояния (в нем зашифрована «мама») и вектор слова «мыла».
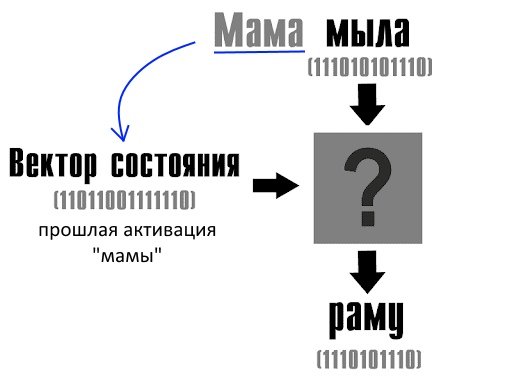
Так мы объяснили нейросети, что нужно посмотреть, какие слова чаще всего стоят после слова «мыла», если до этого еще была «мама».
Контекст не ограничивается одним словом: окно памяти RNN широко, но старые слова из него все равно «вымываются». Это проблема, и ниже мы рассказываем, как умеют ее решать.
На каждом шаге следующий слой делает то же, что прошлый, но с новыми векторами. Поэтому рекуррентные нейросети схематически рисуют так, как будто они снова и снова загружают разные данные в один и тот же «черный ящик».
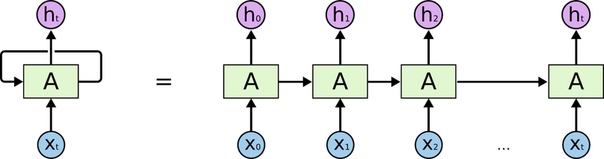
Выше — иллюстрация рекуррентности, ее принято обозначать такой «петлей» вокруг слоя.
Первое слово (х0) попадает на первый слой, и он делает предсказание (h0). Первый слой сохраняет вектор активации нейронов и передает его «себе в будущем», то есть второму слою. Первое предсказание h0 становится вторым входным словом x1.
Так обеспечивается память нейросети о контексте. По еще не очень эффективно, но уже гораздо лучше, чем «в лоб» сохранять 10 000 комбинаций из двух слов и запоминать для них следующее вероятное.
Вектор контекста размывается, и это проблема
Переписывать вектор контекста — как делать ксерокопию ксерокопии: в конце-концов станет ничего не понятно. Надо переписывать отдельные части

Почему неэффективно передавать контекст со слоя на слой? Потому что в него все время что-то записывается прямо поверх старой информации. Вектор состояния, двигаясь по тексту, впитывает все больше данных о прежних словах, а его размер при этом не увеличивается — это все то же количество ноликов и единиц. А значит, информация о контексте при постоянной перезаписи вектора состояния спрессовывается все плотнее — и это ведет к потерям.
При этом система не различает важные данные о контексте и неважные — просто запоминает всё подряд. Поэтому важная языковая информация размывается, затирается новой, и, если предложение длинное, высоки шансы записать на месте важного какой-нибудь грамматический мусор. В очень длинном предложении мусор запишется наверняка. Если добавить на каждый слой нейронов и так увеличить длину вектора состояния, это не добавит памяти нейросети: поверх нужных битов все равно могут записаться ненужные, зато это сильно добавит вычислительной сложности. Снова нейросеть во мнемоническом тупике.
Но из этого тупика нашли выход! Даже несколько: первый, о нем ниже в тексте, называется LSTM (Long Short Term Memory Network), или сеть с долгой краткосрочной памятью. Эта архитектура сама решает, что «запомнить», а что «забыть» на каждом временном шаге.
В другой раз мы расскажем о более продвинутом способе улучшить контекстную память — о механизме внимания: самые современные нейросети не запоминают всё, а определяют, какие части предложения важны, и концентрируются только на них.
Но пока — LSTM!
Что происходит внутри одного слоя нейронов
Умножение на матрицу, сдвиг и функция активации
Мы уже знаем, как читать эту иллюстрацию: вектор X входного слова попадает в «черный ящик» A, там как-то активируются некоторые нейроны, они предсказывают следующее слово h. А потом мы сообщаем на следующий слой о том, какие нейроны активировались.
Что в черном ящике? Как активируются нейроны? Довольно просто:
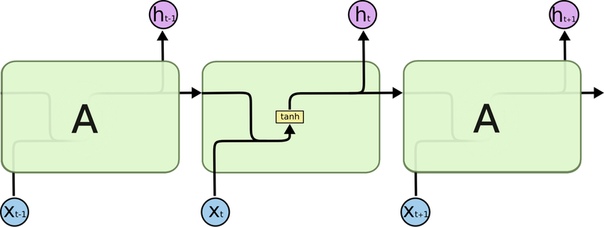
Слой нейронов (здесь) — это три операции:
- умножение входного вектора X на матрицу весов
- прибавление сдвига
- функция активации нейронов «гиперболический тангенс» tanh (чаще всего она, но там может быть и другая)
График функции tanh выглядит просто (как и графики других возможных функций активации):
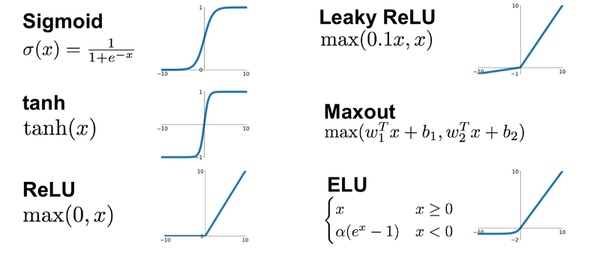
Выбор функции активации зависит от целей и идеи разработчика. Кроме того, он может для удобства назвать слоем не умножение-активацию, а, например, умножение, сдвиг, активацию, потом опять умножение и сдвиг. Состав слоя обычно описан в документации к архитектуре.
В нашем примере вектор слова сперва умножается на матрицу весов — при первом запуске нейросети в ней случайные значения, но их нужно скорректировать, «выучить» во время тренировки. Чтобы выучить матрицу весов, нейросеть начинает со случайных предсказаний, сильно ошибается, и постепенно уменьшает меру ошибки на следующих предсказаниях, меняя матрицу так, чтобы предсказывать точнее. За обучение отвечают обратное распространение ошибки и градиентный спуск. Подробнее — в нашей статье.
У каждого слоя в RNN своя отдельная матрица, и все надо выучить, поэтому эта архитектура тренируются долго.
Вектор слова умножается на матрицу весов — и получается новый вектор. Он складывается со «сдвигом» («bias»), и вектор-сумму «пропускают» через одну из функций активации (в RNN обычно — через tanh, гиперболический тангенс).
Через функцию активации каждый элемент вектора-суммы проходит отдельно. То, что записано в векторе — и есть состояния нейронов. Пока они могут быть любыми, но после функции tanh становятся в диапазон между ?1 и 1. Таким образом нейроны в RNN могут активироваться сильнее или слабее, генерируя сигнал от ?1 до 1 (или от 0 до 1, если позволяет функция активации).
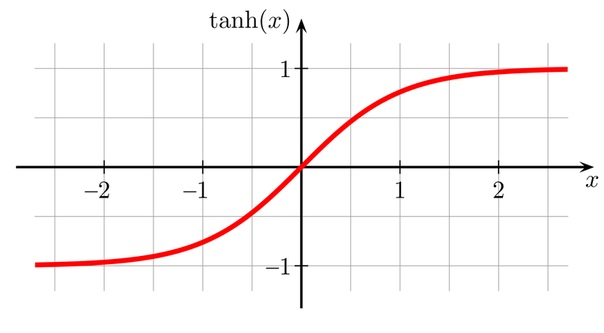
Tanh расшифруем так: нейрон немного активируется, если элемент, с которым он работал — немного больше, чем ?2. Если сильно больше — выдаст максимальный сигнал. На практике функцию могут сдвигать вдоль осей, прибавляя к ней аргументы, поэтому не обязательно началом активации будет именно эта точка.
LSTM — Long Short Term Memory
Нейросеть, которая сама решает, какой контекст нужно запомнить
LSTM — одна из самых крутых архитектур для обработки естественного языка вплоть до июня 2017. Ниже — наш пересказ фрагментов статьи из блога Кристофера Олаха, сотрудника Google Brain и OpenAI.
До этого мы рассматривали простую рекуррентную нейронную сеть, то есть RNN. Ниже — схема LSTM. Главное — без паники!
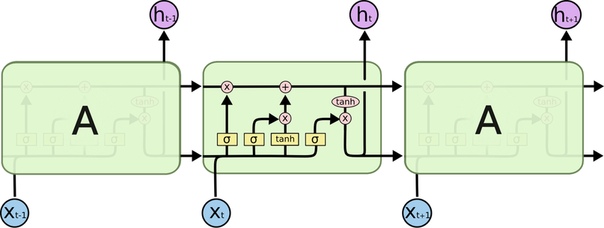
Легенда карты:

Во-первых, по «трубам» этой схемы текут вектора. Входное слово X(t) в синем кружочке — в виде вектора, в стрелочках — вектор, все операции — с векторами.
В желтых кирпичах — слой нейросети. Напомним: это значит, что там спрятаны три операции: сначала входной вектор умножается на матрицу весов слоя (которую нейросеть вырабатывает в ходе тренировки), к произведению прибавляется сдвиг (bias), наконец, вектор-сумма поэлементно проходит через функцию активациинейронов: сигмоиду или гиперболический тангенс. Их графики вы видели выше.
Посимвольная операция означает, что что каждый элемент вектора по отдельности терпит какие-то изменения (как с функцией tanh), а «склеивание» из векторов [1, 2] и [3, 4] дает один вектор [1, 2, 3, 4].
Вектор памяти LSTM
Передается со слоя на слой, из него составляется предсказание
Важнейшая часть LSTM — вот эта труба сверху. Она передает со слоя на слой вектор, кодирующий контекст (будем звать его «вектор памяти»).
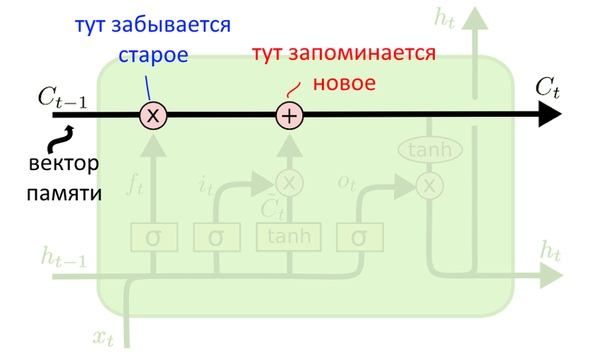
К трубе подключены два розовых «вентиля»: слева направо — вентиль «забывания» и вентиль «запоминания». Они контролируют, что нужно забыть, а что — запомнить.
После забывания и запоминания часть вектора памяти становится вектором-предсказанием слоя или его «скрытым состоянием» — hidden state, сокращенно h(t). Как это делается — расскажем чуть позже.
Забывание контекста в LSTM
Первый шаг LSTM — оценить, какой контекст ей больше не нужен
Работа начинается так: с предыдущего слоя (или с начала работы нейросети) приехали два вектора: первый — h(t-1) предсказание прошлого слоя. Второй вектор — X(t), кодирует новое входное слово.
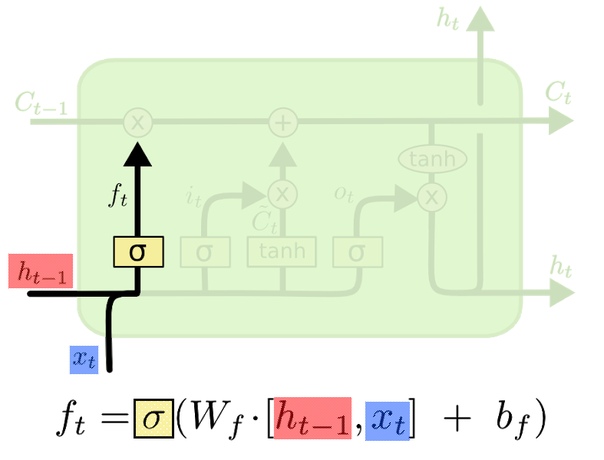
Вектора X(t) и h(t-1) сначала склеиваем, а затем умножаем на матрицу весов, которую выучила нейросеть в процессе тренировки (если вы забыли, как происходит эта тренировка, снова предложим нашу статью про градиентный спуск). На формуле сверху эта матрица обозначена как W(f), что значит forget weights, веса забывания. К произведению добавляем сдвиг b(f).
Получившийся вектор-сумму поэлементно пропускаем через сигмоидную функцию активации (буква в желтом квадрате — «сигма»). Она решает, какие значения старого контекста нужно забыть. Для каждого элемента вектора функция выдает значение от 0 до 1, где 1 значит «оставить элемент целиком», а 0 — «целиком избавиться от элемента». Выходит вектор, который оценивает, насколько сильно нужно забыть ту или иную часть прошлого контекста. Так и назовём — «оценочный» вектор f(t).
Забыть контекст бывает нужно, например, если появилось новое подлежащее и надо запомнить его род и число. Для этого род и число старого подлежащего придется стереть. Разумеется, нейросеть не оперирует категориями подлежащего — но архитектура LSTM скорее всего вычислит, что оно появилось, и сумеет предположить, что старые род и число стали нерелевантны. Читайте дальше, чтобы понять, как.
Итак, мы посмотрели на контекстный вектор, на вектор нового слова, решили, что хотим забыть части старого контекста, и выразили это желание вектором.
Запоминание контекста в LSTM
Второй шаг LSTM — оценить, какой новый контекст надо записать и насколько он важен
Что теперь? Сперва решили, что «забыть», теперь решаем, что «запомнить». На входе, опять старый вектор-предсказание h(t-1) и новое слово X(t). Эти вектора склеиваются и попадают на два независимых слоя.
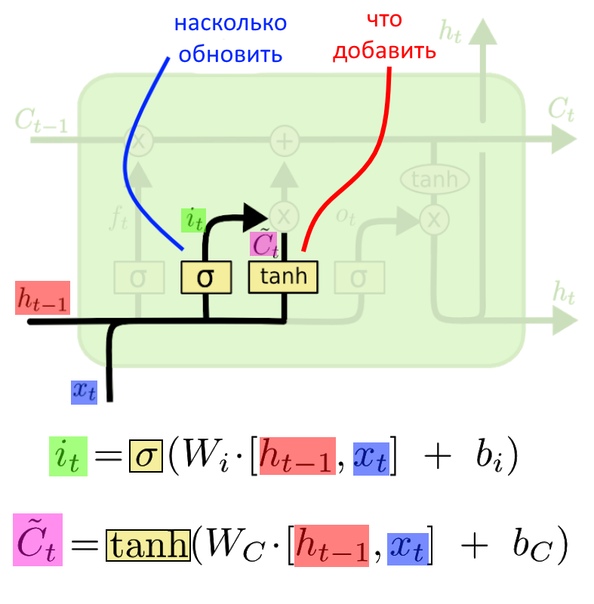
На слое справа (где написано tanh) вектора X(t) и h(t-1) умножаются на матрицу весов W©, она получается в процессе тренировки. К произведению прибавляют сдвиг, и вектор-сумма поэлементно проходит через функцию активации «гиперболический тангенс», tanh. Так составляется вектор из новых значений, которые хочется записать в «вектор памяти». Назовем его «вектор новых значений».
Нейронный слой слева умножает вход на выученную матрицу весов W(i) — input weights, веса входа. Добавляется сдвиг b(i), и вектор-сумма поэлементно проходит через сигмоидную функцию. Так формируется «оценочный» вектор i(t): на него умножим «вектор новых значений». Если в оценочном векторе есть нули, какие-то элементы новых значений на них умножатся и не дойдут то контекста.
LSTM выразило, что важного хочется добавить в контекст. Но пока ничего туда не записывается.
Запись новых значений в контекст
Забыть контекст — значит умножить его ненужные части на ноль из «оценочного вектора». Чтобы запомнить новый — прибавляем взвешенный «вектор новых значений»
Запись в вектор памяти происходит на этом шаге: мы умножаем старый вектор памяти на «оценочный» f(t), таким образом забывая (умножая на ноль) то, что решили забыть. А то, что решили не забывать, умножаем примерно на единицу (оставляем как есть).
К «забывшему» вектору памяти прибавляем взвешенный «вектор новых значений». Взвешенный — значит умноженный на «оценочный» i(t), то есть среди «сырых» новых значений некоторые тоже умножились на ноль и так и не попали в вектор контекста.
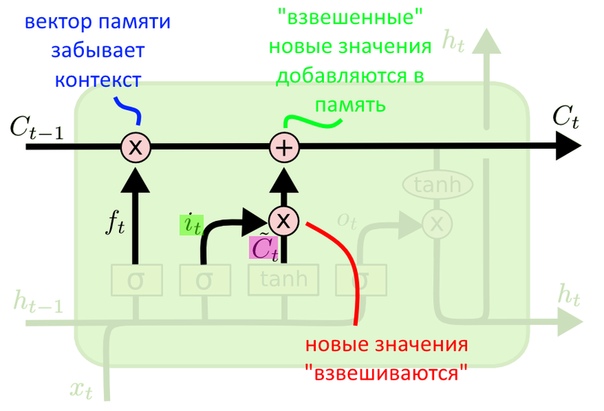
Если LSTM работает с языковой моделью, то это был как раз тот момент, когда мы стираем информацию о роде старого подлежащего и добавляем род нового.
Предсказание LSTM
Предсказание получается из «фильтрованного» вектора контекста
Наконец решаем, какую часть «вектора памяти» подать дальше как предсказание. Слой с сигмоидной активацией снова определяет, какие части вектора памяти важны, строит свой «оценочный» вектор o(t) — это первая строка формул с картинки.
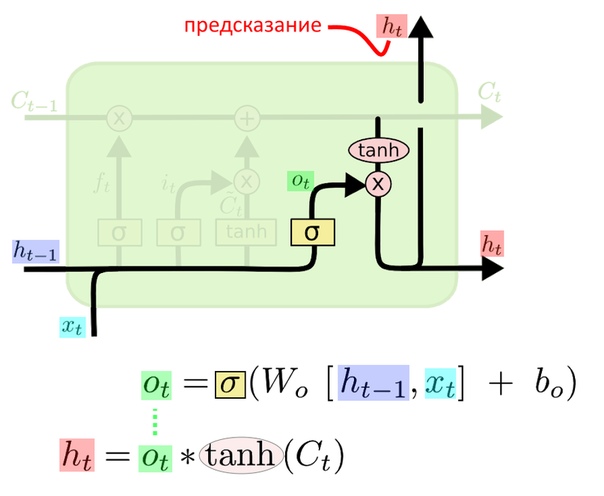
Допустим, в векторе контекста записано, что где-то в прошлом встретились слова «пушистый» и «деревянный». На вход подается «гладкий», и нужно сгенерировать следующее слово. Мы бы хотели увидеть «стол». Хороший оценочный вектор умножит на ноль контекстные данные о «пушистом» и на единицу — данные о «гладком». Такой вектор получится умножением входных данных на хорошую матрицу весов: ее элементы правильно подбираются при тренировке. Матрица изменяема, она подстраивается под входные примеры во время обучения. Поэтому в нейросетях так важно найти качественные тренировочные данные.
Вектор памяти C(t) поэлементно «пропускается» через функцию tanh, и все крупные элементы становятся либо 1, либо ?1. «Пушистый» и «деревянный» в контексте как бы приводятся к общему знаменателю. Наконец вектор контекста перемножается с «оценочным» — на второй строке формул. Раз теперь на входе «гладкий», прошлую «пушистость» чего-то там удалось забыть и сконцентрироваться на «деревянности»: так больше вероятность предсказать «деревянный гладкий стол». Получился вектор h(t).
Именно h(t) — предсказание, результат работы слоя LSTM.
Вот способ превратить h(t) в словарный номер следующего слова. h(t) умножим на тренируемую матрицу длиной в словарь (допустим, в словаре 100 тысяч слов), и «подсветим» самые большие значения результата функцией Softmax. Без подробностей — Softmax превращает элементы вектора в нули или в положительные числа, суммарно дающие единицу. Такой набор удобно толковать как вероятность встретить то или иное слово. Если третий элемент вектора — 0.8, значит, 0.8 — вероятность, что следующее слово — абажур (или что у нас третье в словаре по алфавиту).
Заключение
LSTM широко применяется там, где есть неслучайные последовательности. До изобретения трансформеров это вообще был стандартный ответ на вопрос, какую нейросеть брать для обработки языка — бери один из вариантов LSTM (а есть модификации) или GRU, похожую на LSTM архитектуру. Машинный перевод, распознавание речи, рукописного текста, анализ музыки, жестов, семантики, потоков машин в городе, белковых последовательностей — везде LSTM. Это мощная нейросетевая архитектура, и тем не менее, она всего лишь определяет, в каком порядке складываются и перемножаются вектора. Конкретный смысл в свой проект вкладывает сам разработчик.
Может быть, было сложновато, но если вы дочитали сюда, то спасибо за интерес к теме. «Системный Блокъ» постарался сохранить баланс между техническими деталями и упрощением, и надеется, что рекуррентные нейронные сети сегодня стали чуточку менее таинственными! В следующий раз расскажем, как улучшить модель LSTM при помощи «механизма внимания».
Владимир Селеверстов
Источники
- Understanding LSTM Networks — послужило основой нашего текста, загляните сюда
- Complete Guide of Activation Functions
- AI Language Models & Transformers — Computerphile
- AI YouTube Comments — Computerphile
Телеграм: t.me/ainewsline
Источник: m.vk.com