An interpretable mortality prediction model for COVID-19 patients
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-06-20 11:36
машинное обучение новости, искусственный интеллект в медицине
Внезапное увеличение числа случаев заболевания COVID-19 оказывает большое давление на медицинские услуги во всем мире. На этом этапе крайне важна быстрая, точная и ранняя клиническая оценка тяжести заболевания. Для поддержки принятия решений и логистического планирования в системах здравоохранения это исследование использует базу данных образцов крови от 485 инфицированных пациентов в регионе Ухань, Китай, для выявления важнейших прогностических биомаркеров смертности от болезней. Для этой цели средствами машинного обучения были отобраны три биомаркера, которые предсказывают смертность отдельных пациентов более чем на 10 дней вперед с точностью более 90%: молочная дегидрогеназа (ЛДГ), лимфоциты и высокочувствительный С-реактивный белок (СРБ). В частности, относительно высокие уровни ЛДГ сами по себе, по-видимому, играют решающую роль в выделении подавляющего большинства случаев, требующих немедленной медицинской помощи. Этот вывод согласуется с современными медицинскими знаниями о том, что высокие уровни ЛДГ связаны с разрушением тканей, происходящим при различных заболеваниях, включая легочные расстройства, такие как пневмония. В целом, эта статья предлагает простое и действенное правило принятия решений для быстрого прогнозирования пациентов с самым высоким риском, позволяющее им быть приоритетными и потенциально снижать смертность.
Главный
Вспышки эпидемии COVID-19 вызывают проблемы со здоровьем во всем мире с декабря 2019 года. Вирус вызывает лихорадку, кашель, усталость и легкие или тяжелые респираторные осложнения, которые, если они очень тяжелые, могут привести к смерти пациента. По состоянию на 6 марта во всем мире было зарегистрировано 98 192 суммарных случая инфицирования и 3045 смертей1. 11 марта Всемирная организация здравоохранения объявила вспышку вируса пандемией2. До сих пор сообщалось, что 13,8–19,1% инфицированных COVID-19 пациентов в Ухане, Китай,стали тяжело больными3,4, 5. Кроме того, последние сообщения выявили поразительный уровень летальности в критических случаях-61,5%, резко увеличивающийся с возрастом и у пациентов с сопутствующими заболеваниями. Тяжесть случаев заболевания оказывает большое давление на медицинские службы, что приводит к нехватке ресурсов интенсивной терапии.
К сожалению, в настоящее время не существует прогностического биомаркера, позволяющего выделить пациентов, нуждающихся в немедленной медицинской помощи, и оценить связанный с ними уровень смертности. Таким образом, способность выявлять случаи, которым грозит неминуемая смерть, стала насущной и в то же время сложной необходимостью. В этих условиях мы ретроспективно проанализировали образцы крови 485 пациентов из района Ухань, Китай, чтобы выявить надежные и значимые маркеры риска смертности. Для выявления наиболее дискриминантных биомаркеров смертности пациентов был разработан подход математического моделирования, основанный на современных интерпретируемых алгоритмах машинного обучения. Задача была сформулирована в виде классификационной задачи, где исходные данные включали основную информацию, симптомы, образцы крови и результаты лабораторных исследований, включая функцию печени, почек, функцию свертывания крови, электролиты и воспалительные факторы, взятые у первоначально общих, тяжелых и критических пациентов (табл.1), а также связанные с ними исходы, соответствующие выживаемости или смерти в конце периода обследования. Благодаря оптимизации этот классификатор нацелен на выявление наиболее важных биомаркеров, отличающих пациентов с неминуемым риском, тем самым облегчая клиническую нагрузку и потенциально снижая смертность.
Медицинские записи собирались с использованием стандартных форм отчетов о случаях заболевания, которые включали эпидемиологическую, демографическую, клиническую, лабораторную информацию и информацию об исходах смертности (Таблица 2 и дополнительные данные 1). Клинические результаты были прослежены до 24 февраля 2020 года. Исследование было одобрено Комитетом по этике больницы Тунцзи.
Ресурсы данных
Для разработки модели была использована медицинская информация всех пациентов, собранная в период с 10 января по 18 февраля 2020 года. Данные, полученные от беременных и кормящих грудью женщин, пациентов моложе 18 лет и записей с материалом данных менее чем на 80% полным, были исключены из последующего анализа. У 375 пациентов наиболее распространенным начальным симптомом была лихорадка (49,9%), за которой следовали кашель (13,9%), усталость (3,7%) и одышка (2,1%). Возрастное распределение пациентов составило 58,83 ± 16,46 года, причем 59,7% составляли мужчины. Эпидемиологический анамнез включал жителей Уханя (37,9%), семейный кластер (6,4%) и медицинских работников (1,9%). Результаты лабораторных исследований приведены в таблице 2. Из 375 случаев, включенных в последующий анализ, 201 выздоровел от КОВИД-19 и был выписан из больницы, в то время как остальные 174 умерли> умерли. После этого 110 недавно выписанных или умерших пациентов в период с 19 февраля 2020 года по 24 февраля 2020 года были зачислены для анализа в качестве внешнего тестового набора данных.
Минимальное, максимальное и медианное время наблюдения (от поступления в больницу до смерти или выписки) для всех 485 (375 + 110) пациентов составляет 0 дней 02:01:58 (часы: минуты: секунды), 35 дней 04:05:54 и 11 дней 04:15:36 соответственно. Высокий уровень смертности, наблюдаемый в нашем исследовании, был связан с тем, что больница Тунцзи принимала более высокий уровень тяжелых и критических случаев в Ухане. Тяжесть состояния пациента эмпирически оценивалась врачами по критериям, приведенным в Таблице 1, только при поступлении7. На рис.1 представлены результаты лечения пациентов трех различных групп.
Инжир. 1: блок-схема приема пациентов.
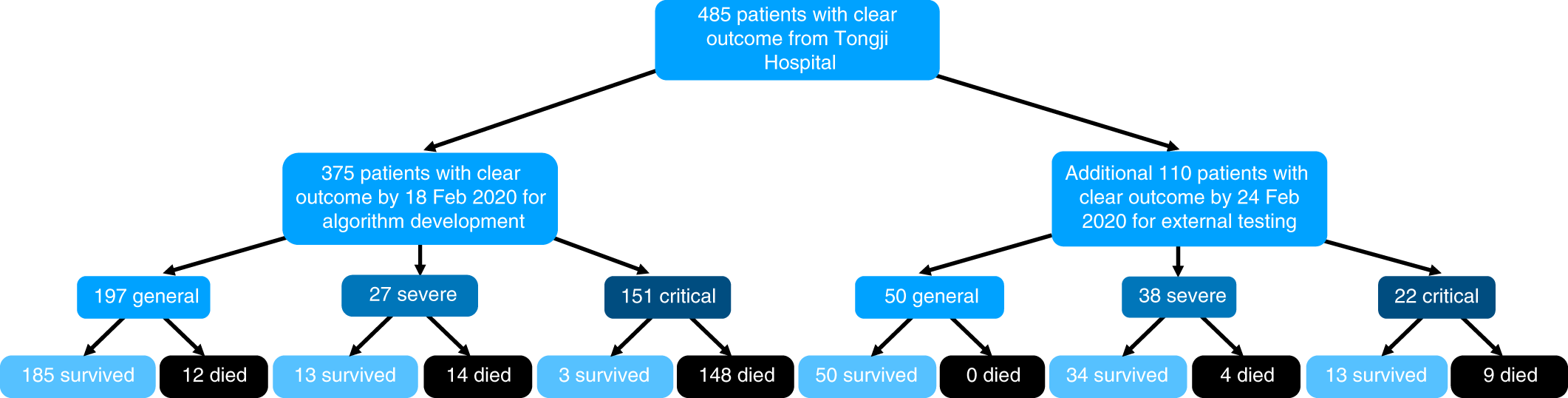
Первоначально для разработки модели было использовано 375 пациентов с определенным исходом до 18 февраля 2020 года, затем еще 110 пациентов с определенным исходом в период с 19 февраля 2020 года по 24 февраля 2020 года были использованы в качестве внешнего тестового набора данных.
Разработка модели машинного обучения
У большинства пациентов во время пребывания в больнице брали несколько образцов крови. Однако обучение и тестирование модели используют только данные из окончательной выборки в качестве входных данных для модели, чтобы оценить важнейшие биомаркеры тяжести заболевания, выделить пациентов, которые нуждаются в немедленной медицинской помощи, и точно сопоставить соответствующие признаки с каждой меткой. Тем не менее, модель может быть применена ко всем другим образцам крови и оценена прогностическая способность идентифицированных биомаркеров (см. раздел Оценка горизонта прогнозирования). Недостающие данные были дополнены цифрой "-1". Выходные данные модели соответствуют смертности пациентов. Выжившие пациенты были отнесены к классу 0, а умершие-к классу 1.
Модели производительности оценивались путем оценки точности классификации (отношение истинных предсказаний ко всем предсказаниям), точности, чувствительности / отзыва и баллов F1 (определенных ниже):
Precisioni=TPiTPi+FPi
(1)
Recalli=TPiTPi+FNi
(2)
F1i=2xPrecisionixRecalliPrecisioni+Recalli
(3)
Точность=TP+TNTP+TN+FP+FN
(4)
Макроаверсии (оценка)=1C?iscorei
(5)
Weightedaverages(результат)=1 и?ини?scoreiscore?{точность,Напомним,Ф1}
(6)
где i?C
представляет класс, N-число всех выборок, C-число всех классов, Ni-число выборок, TNi в классе i, TPi, FPi и FNi означают истинно положительные, истинно отрицательные, ложноположительные и ложноотрицательные показатели для класса i соответственно. Всего было рассмотрено 75 признаков.
В этом исследовании в качестве модели предиктора используется контролируемый классификатор Xgboost8. XGBoost-это высокопроизводительный алгоритм машинного обучения, который обладает большим потенциалом интерпретируемости благодаря своей рекурсивной древовидной системе принятия решений. В отличие от этого, внутренние модельные механизмы стратегий моделирования черного ящика, как правило, трудно интерпретировать. Важность каждого отдельного признака в XGBoost определяется его накопленным использованием на каждом шаге принятия решений в деревьях. Это вычисляет метрику, характеризующую относительную важность каждого признака, что особенно ценно для оценки признаков, которые являются наиболее дискриминационными из результатов модели, особенно когда они связаны с значимыми клиническими параметрами.
XGBoost изначально обучался со следующими настройками параметров по умолчанию: максимальная глубина равна 4, скорость обучения равна 0,2, количество древовидных оценок равно 150, значение параметра регуляризации ? равно 1, а ‘subsample’ и ‘colsample_bytree’ равны 0,9, чтобы предотвратить перенапряжение для случаев с большим количеством признаков и небольшим размером выборки8. Мы называем его "Многодеревянным алгоритмом XGBoost".
Важность функции для работоспособного дерева решений
Для оценки маркеров риска неминуемой смертности мы оценивали вклад каждого параметра пациента в принятие решений алгоритма. Характеристики были ранжированы по многоствольного дерева XGBoost в соответствии с их важностью (дополнительный рис. 1 и 2 и дополнительный алгоритм 1). Характеристики модели не показали улучшения в области под кривой (AUC) баллов, когда число верхних признаков увеличилось до четырех. Таким образом, ряд ключевых признаков был установлен на следующие три: молочная дегидрогеназа (ЛДГ), лимфоциты и высокочувствительный С-реактивный белок (СРБ).
В таблице 3 приведены характеристики Многодеревянной модели XGBoost. Полученные результаты показывают, что модель способна точно идентифицировать исход лечения пациентов, независимо от их первоначального диагноза при поступлении в стационар. Примечательно, что показатели внешнего тестового набора (подробно описанного ниже) аналогичны показателям обучающего и валидационного наборов, что позволяет предположить, что модель отражает ключевые биомаркеры смертности пациентов. Набор выбранных признаков представлен графически для каждого пациента на дополнительном фиг. 3, демонстрируют четкую оформленность. В таблице 3 Далее подчеркивается важность ЛДГ как важнейшего биомаркера смертности пациентов.
Таблица 3 эффективность Многодеревянной классификации XGBoost при различении исходов смертности с использованием 100-раундовой пятикратной перекрестной валидации с использованием дополнительного алгоритма 1
Полноразмерный стол
Разработка клинически работоспособного дерева решений
Следуя предыдущим выводам о важности ЛДГ, лимфоцитов и ГС-СРБ, мы стремились построить упрощенную и клинически работоспособную модель принятия решений. Алгоритмы XGBoost основаны на рекурсивном построении дерева решений из прошлых остатков и могут идентифицировать те деревья, которые вносят наибольший вклад в решение прогнозной модели. Деревья решений - это простые классификаторы, состоящие из последовательностей бинарных решений, организованных иерархически. Следовательно, если точность дерева остается высокой, то снижение сложности модели до такой структуры имеет потенциал для выявления клинически переносимого алгоритма принятия решений. В дальнейшем мы будем называть последнюю "интерпретируемой моделью" или "одноперевесным XGBoost".
Было 24 пациента с неполными измерениями по крайней мере одного из трех основных биомаркеров в их последних образцах крови, в результате чего 351 пациент идентифицировал модель XGBoost с одним деревом. Чтобы идентифицировать модель, XGBoost был переобучен с теми же параметрами, что и описанный выше, за исключением следующих: количество древовидных оценок установлено равным 1, значения параметров регуляризации ? и ? установлены равными 0, а функции подвыборки и max установлены равными 1, так как проблемы с переналадкой были исключены на основе предыдущего моделирования8. Интерпретируемое дерево решений было получено случайным разбиением 351 пациента на обучающие и валидационные наборы данных в соотношении 7: 3. Полученная древовидная структура и характеристики показаны, соответственно, на фиг. 2 и дополнительные таблицы 1 и 2.
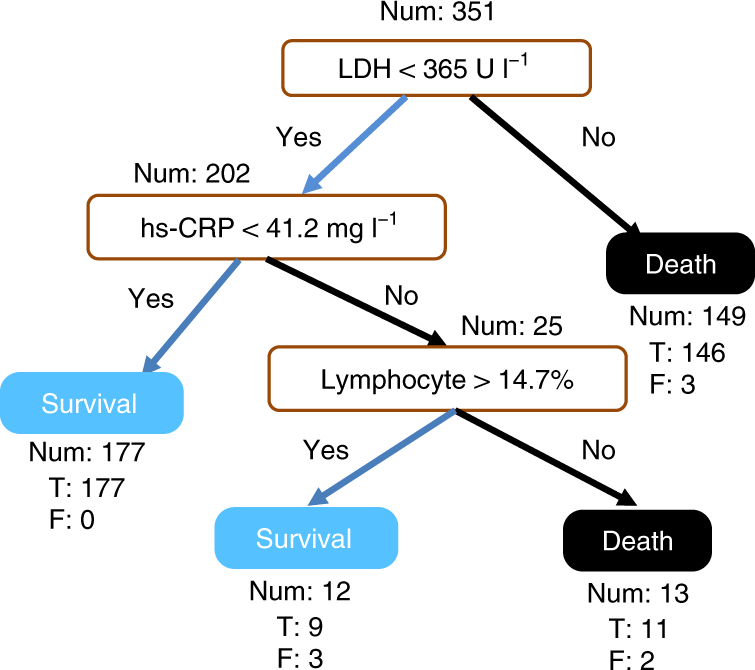
Кроме того, результаты интерпретируемой модели были оценены для внешнего набора тестов на последних образцах крови 110 пациентов, которые не были частью обучения или валидации Одноперевесной модели XGBoost (табл.4). Соответствующая матрица путаницы представлена на дополнительном фиг. 5, который показывает 100% точность прогноза выживаемости и 81% точность прогноза смертности. В целом баллы по прогнозированию выживаемости и смертности, точности, макро-и средневзвешенным значениям стабильно превышают 0,90.
Таблица 4 производительность предложенной интерпретируемой модели на внешнем тестовом наборе данных
Полноразмерный стол
Наконец, для целей сравнения результаты интерпретируемой модели были сопоставлены с другими стандартными методами, такими как случайный лес и логистическая регрессия 9. Кривые рабочих характеристик приемника и оценки AUC приведены в дополнительной таблице 3 и дополнительном рисунке. 4.
Оценка горизонта прогнозирования
У большинства пациентов на протяжении всего пребывания в больнице брались многочисленные пробы крови. Всего было отобрано 909 образцов крови с полными измерениями этих трех признаков для всех 485 пациентов, использованных для обучения и валидации, и 251 образец крови с полными измерениями этих трех признаков для 110 пациентов во внешнем тестовом наборе. Прогностический потенциал нашей модели оценивался по всем анализам крови для всех 485 пациентов и 110 пациентов в наборе данных внешнего теста (рис. 3 и дополнительные фиг. 6 и 7). В среднем точность нашего алгоритма составляла 90%, что еще раз доказывало, что модель может быть применена к любому образцу крови, в том числе и к тем, которые были взяты намного раньше дня первичного клинического исхода. В среднем модель могла предсказать исход всех истинно положительных пациентов примерно за 10 дней (11 дней для пациентов во внешнем тестовом наборе) до исхода, используя все их образцы крови (рис. 3b, c). Модель может даже предсказать 18 дней вперед с совокупной точностью выше 90% (рис. 3d, e). Точность прогноза возрастает ближе к исходу пациента. Этот анализ горизонта прогнозирования предполагает, что, когда состояние пациента ухудшается, клинический маршрут способен дать раннее предупреждение клиницистам за несколько дней до этого.
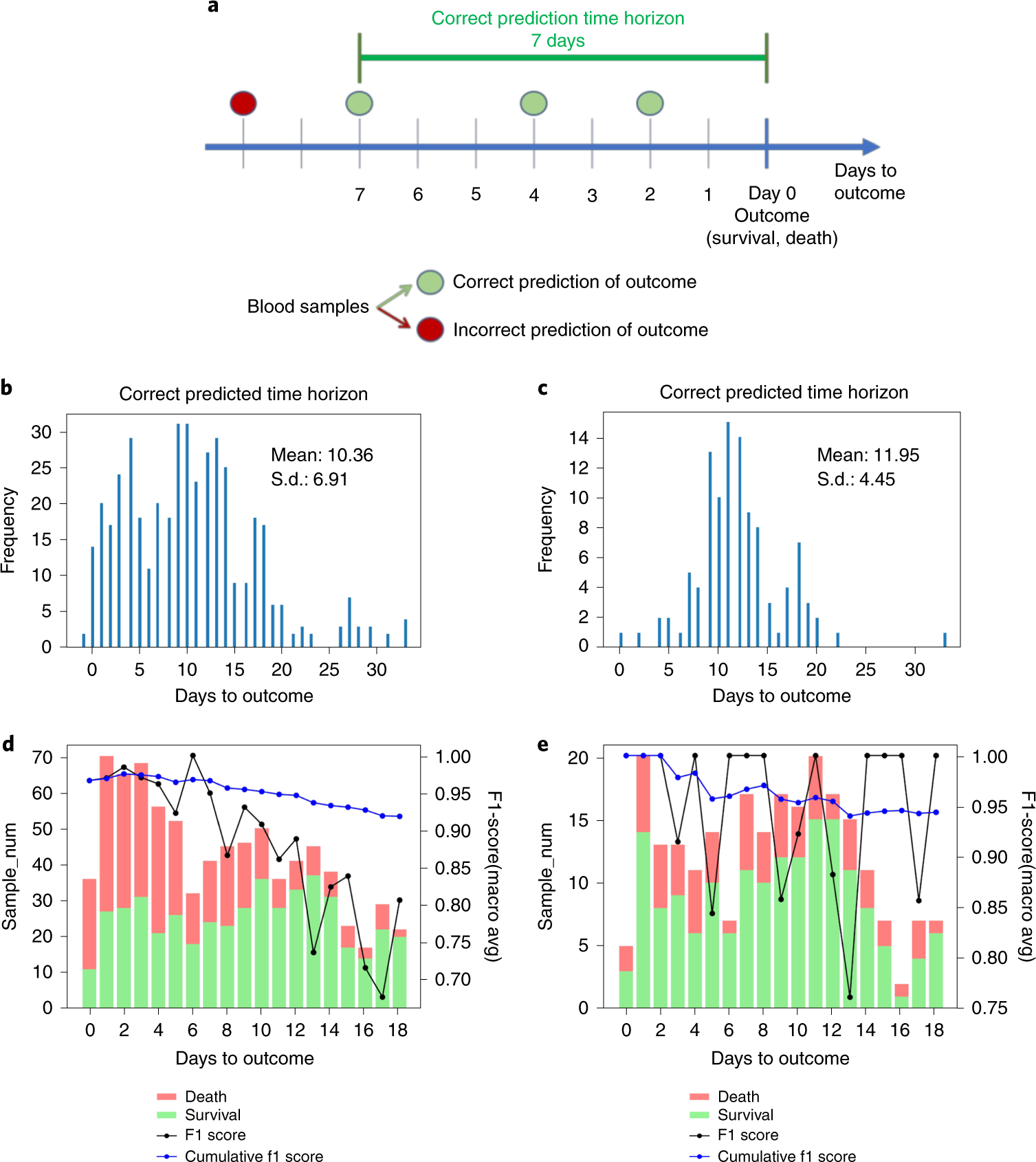
а, иллюстрация концепции правильного прогнозирования временного горизонта. б, гистограмма максимальных правильных временных горизонтов предиктона для всех 485 пациентов с истинным положительным прогнозом. Обратите внимание, что есть два пациента с отрицательными днями, так как их единственные результаты анализа крови поступили через один день после их клинического исхода. c, гистограмма максимальных правильных временных горизонтов прогнозирования для 110 пациентов во внешнем тестовом наборе с истинным положительным прогнозом. d, прогностическая эффективность (оценка F1 и кумулятивная оценка F1), оцененная в отношении дня исхода для всех 485 пациентов. e, прогностическая эффективность (оценка F1 и кумулятивная оценка F1), оцененная в зависимости от дня исхода для 110 пациентов во внешнем тестовом наборе.
Полноразмерное изображение
Обсуждение
Значение нашей работы двояко. Во-первых, это выходит за рамки обеспечения факторов высокого риска4. Он предоставляет простой и интуитивно понятный клинический тест для точной и быстрой количественной оценки риска смерти. Например, рутинная последовательная респираторная поддерживающая терапия для пациентов с SpO2 ниже 93% включает интраназальную катетеризацию кислорода, подачу кислорода через маску, подачу кислорода с высоким потоком через носовой катетер, неинвазивную вентиляционную поддержку, инвазивную вентиляционную поддержку и экстракорпоральную мембранную оксигенацию. Предсказание того, что для некоторых пациентов эта последовательная кислородотерапия приводит к неудовлетворительным терапевтическим эффектам, может помешать врачам использовать различные подходы. Цель модели состоит в том, чтобы выявить пациентов высокого риска до наступления необратимых последствий. Во-вторых, три ключевых признака, ЛДГ, лимфоциты и hs-CRP, могут быть легко собраны в любой больнице. В переполненных больницах и при нехватке медицинских ресурсов эта простая модель может помочь быстро расставить приоритеты среди пациентов, особенно во время пандемии, когда приходится выделять ограниченные медицинские ресурсы10.
Увеличение ЛДГ отражает разрушение ткани / клетки и рассматривается как общий признак повреждения ткани/клетки. Сывороточный ЛДГ был идентифицирован как важный биомаркер активности и тяжести идиопатического легочного фиброза11. У пациентов с тяжелым легочным интерстициальным заболеванием повышение ЛДГ является значительным и является одним из важнейших прогностических маркеров поражения легких11. Для тяжелобольных пациентов с COVID-19 повышение уровня ЛДГ указывает на увеличение активности и степени повреждения легких.
Повышение уровня ГС-СРБ, важного маркера неблагоприятного прогноза при остром респираторном дистресс-синдроме12, 13, отражает стойкое состояние воспаления14. Результатом этой стойкой воспалительной реакции являются большие серо-белые очаги в легких пациентов с COVID-19 (наблюдаемые при аутопсии)15. В тканевых срезах также наблюдается большое количество липкого секрета, выходящего из альвеол15.
Наконец, наши результаты также предполагают, что лимфоциты могут служить потенциальной терапевтической мишенью. Эта гипотеза подтверждается результатами клинических исследований4, 16. Лимфопения является общей чертой у пациентов с COVID-19 и может быть критическим фактором, связанным с тяжестью заболевания и смертностью17. Поврежденные клетки альвеолярного эпителия могут индуцировать инфильтрацию лимфоцитов, приводя к стойкой лимфопении, как это было замечено в SARS-CoV-2 и MERS-CoV (они имеют сходные альвеолярные проникающие и антигенпрезентирующие клетки (APC), повреждающие пути)18,19. Биопсийное исследование предоставило убедительные доказательства существенного снижения количества периферических CD4 и CD8 Т-клеток, в то время как их статус был гиперактивирован 20. Кроме того, Цзин и его коллеги сообщили, что лимфопения в основном связана со снижением количества CD4 и CD8 Т-клеток 21. Таким образом, вероятно, что лимфоциты играют различную роль в COVID-19, что заслуживает дальнейшего изучения.
В этом исследовании есть место для дальнейшего совершенствования, которое остается для будущей работы. Во-первых, учитывая, что предлагаемый метод машинного обучения основан исключительно на данных, наша модель может отличаться, если исходить из разных наборов данных. По мере поступления новых данных вся процедура может быть легко повторена для получения более точных моделей. Это одноцентровое ретроспективное исследование, которое дает предварительную оценку клинического течения и исхода заболевания. Мы с нетерпением ожидаем последующих крупномасштабных и многоцентровых исследований. Во-вторых, хотя у нас был пул из более чем 70 клинических признаков, наш принцип моделирования-это компромисс между минимальным количеством признаков и способностью к хорошему прогнозированию, поэтому мы избегаем чрезмерной подгонки. Наконец, это исследование устанавливает баланс между интерпретируемостью модели и улучшенной точностью. Хотя клинические условия, как правило, предпочитают интерпретируемые модели, вполне возможно, что модель черного ящика может привести к улучшению производительности.
Вывод
Таким образом, это исследование выявило три показателя (ЛДГ, ХС-СРБ и лимфоциты), а также клинический маршрут (рис. 2), для прогностического прогноза COVID-19. Мы разработали модель машинного обучения XGBoost, которая позволяет прогнозировать смертность пациентов более чем за 10 дней с точностью более 90%, позволяя выявлять, раннее вмешательство и потенциально снижать смертность у пациентов с COVID-19.
Отчетности Резюме
Более подробная информация о дизайне исследований доступна в сводке отчетов Nature Research Reporting, связанной с этой статьей.
Доступность данных и кода
Данные доступны в дополнительной информации. Реализация кода доступна по адресу https://github.io/HAIRLAB/Pre_Surv_COVID_19 по лицензии MIT (https://doi.org/10.5281/zenodo.3758806).
Телеграм: t.me/ainewsline
Источник: www.nature.com