В конце статьи поделимся с вами списком самых интересных материалов по этой теме.
Новый подход
Мультиагентное обучение с подкреплением – это развивающаяся и богатая область исследований. Тем не менее постоянное применение одноагентных алгоритмов в мультиагентных контекстах ставит нас в затруднительное положение. Обучение усложняется по многим причинам, в особенности из-за:
- Нестационарности между независимыми агентами;
- Экспоненциального роста пространств действий и состояний.
Исследователи нашли множество способов уменьшить воздействие этих факторов. Большая часть этих методов попадает под понятие «централизованного планирования с децентрализованным выполнением.»
Централизованное планирование
У каждого агента есть прямой доступ к локальным наблюдениям. Эти наблюдения могут быть самыми разнообразными: изображения окружающей среды, положения относительно определенных ориентиров или даже положения относительно других агентов. Помимо этого, во время обучения все агенты управляются центральным модулем или критиком.
Несмотря на то, что у каждого агента для обучения есть только локальная информация и локальные политики, существует сущность, которая наблюдает за всей системой агентов и говорит им, как обновлять политики. Таким образом уменьшается эффект нестационарности. Все агенты обучаются с помощью модуля с глобальной информацией.
Децентрализованное выполнение
Во время тестирования центральный модуль удаляется, а агенты со своими политиками и локальными данными остаются. Так уменьшается вред, наносимый увеличивающимися пространствами действий и состояний, поскольку совокупные политики никогда не изучаются. Вместо этого мы надеемся, что в центральном модуле достаточно информации, чтобы управлять локальной политикой обучения таким образом, чтобы оно было оптимальным для всей системы, как только наступит время проводить тестирование.
OpenAI
Исследователи из OpenAI, Калифорнийского университета в Беркли и Университета Макгилла, представили новый подход к мультиагентным настройкам с помощью Multi-Agent Deep Deterministic Policy Gradient. Такой подход, вдохновленный своим одноагентным аналогом DDPG, использует обучение вида «актер-критик» и показывает очень многообещающие результаты.
Архитектура
Данная статья предполагает, что вы знакомы с одноагентной версией MADDPG: Deep Deterministic Policy Gradients или DDPG. Чтобы освежить память, вы можете прочитать замечательную статью Криса Юна. У каждого агента есть пространство наблюдений и непрерывное пространство действий. Также у каждого агента есть три компонента:
- Сеть актеров, который использует локальные наблюдения для детерминированных действий;
- Целевая сеть актеров с аналогичным функционалом для стабильного обучения;
- Сеть критиков, которая использует совместные пары состояние-действие для оценки Q-значений.
По мере того, как критик с течением времени изучает совместные Q-значения функции, он отправляет соответствующие приближения Q-значения актеру, чтобы помочь в обучении. В следующем разделе мы рассмотрим это взаимодействие подробнее.
Помните, что критик может быть общей сетью между всеми N агентами. Другими словами, вместо того чтобы обучать N сетей, которые оценивают одно и то же значение, просто обучите одну сеть и используйте ее, чтобы она помогла обучению всех остальных агентов. То же самое относится и к сетям актеров, если агенты однородные.
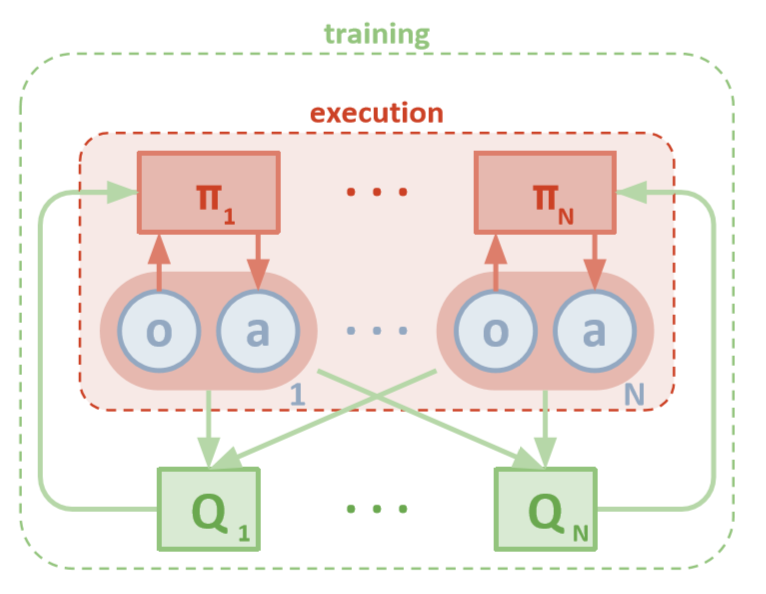
Обучение
Во-первых, MADDPG использует воспроизведение опыта (experience replay) для эффективного off-policy обучения. На каждом промежутке времени агент хранит следующий переход:
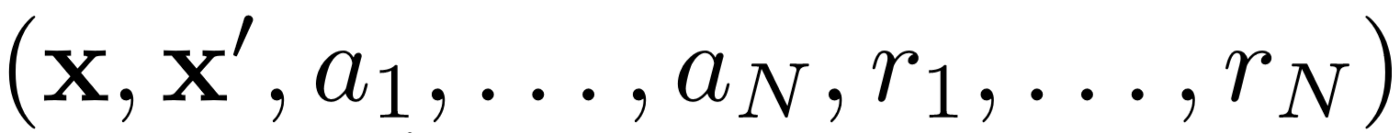
Обновления критика
Для обновления центрального критика агента мы используем lookahead TD-ошибку:
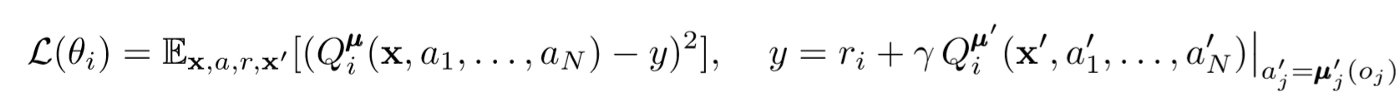
Обновления актеров
Подобно одноагентной DDPG мы используем deterministic policy gradient для обновления каждого параметра актера агента.
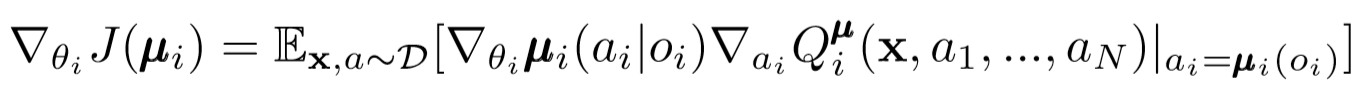
Выводы из политик и ансамбли политик
Мы можем сделать еще один шаг в вопросе децентрализации. В предыдущих обновлениях мы предполагали, что каждый агент автоматически узнает действия других агентов. Однако, MADDPG предлагает делать выводы из политики других агентов, чтобы сделать обучение еще более независимым. Фактически каждый агент будет добавлять N-1 сетей для оценки истинности политики всех других агентов. Мы используем вероятностную сеть, чтобы максимизировать логарифмическую вероятность вывода наблюдаемого действия другого агента.
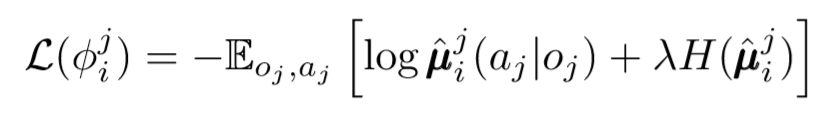
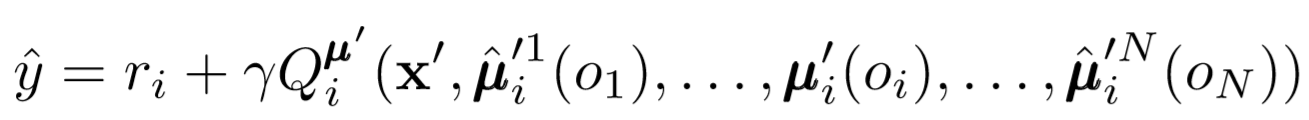
Ансамбли политик
В вышеописанном подходе есть одна большая проблема. Во многих мультиагентных настройках, особенно в конкурентных, агенты могут создавать политики, которые могут переобучиться на поведении других агентов. Это сделает политику хрупкой, нестабильной и, как правило, неоптимальной. Чтобы компенсировать этот недостаток, MADDPG обучает коллекцию из K подполитик для каждого агента. На каждом временном шаге агент случайным образом выбирает одну из подполитик для выбора действия. А затем выполняет его.
Градиент политики немного изменяется. Мы берем среднее значение по K подполитикам, используем линейность ожидания и распространяем обновления с помощью функции Q-значения.
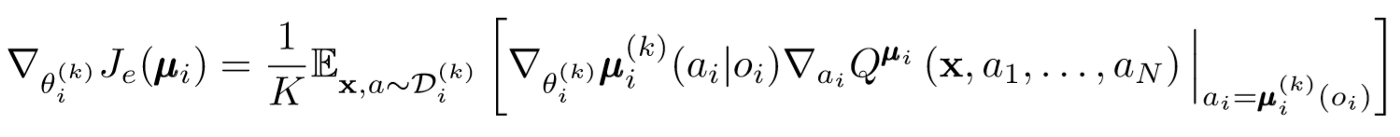
Вернемся на шаг назад
Вот так в общих чертах и выглядит весь алгоритм. Сейчас нужно вернуться назад и осознать, что именно мы сделали и интуитивно понять, почему это работает. По сути, мы сделали следующее:
- Определили актеров для агентов, которые используют только локальные наблюдения. Таким образом можно взять под контроль отрицательный эффект от экспоненциально увеличивающихся пространств состояний и действий.
- Определили центрального критика для каждого агента, который использует совместную информацию. Так мы смогли уменьшить влияние нестационарности и помогли актеру сделать стать оптимальным для глобальной системы.
- Определили сети выводов из политик для оценки политик других агентов. Так мы смогли ограничить взаимозависимость агентов и устранить необходимость в том, чтобы у агентов была совершенная информация.
- Определили ансамбли политик для уменьшения эффекта и возможности переобучения на политиках других агентов.
Каждый компонент алгоритма служит определенной отдельной цели. Мощным алгоритм MADDPG делает следующее: его компоненты разработаны специально для преодоления серьезных препятствий, которые обычно встают перед мультиагентными системами. Дальше мы поговорим о производительности алгоритма.
Результаты
MADDPG был апробирован во многих средах. Полный обзор его работы можно найти в статье [1]. Здесь мы поговорим только о задаче кооперативной коммуникации.
Обзор среды
Есть два агента: говорящий и слушающий. На каждой итерации слушающий получает цветную точку на карте, к которой нужно двигаться, и получает награду, пропорциональную расстоянию до этой точки. Но вот в чем загвоздка: слушающий знает только свое положение и цвет конечных точек. Он не знает, к какой точке он должен двигаться. Однако говорящий знает цвет нужной точки для текущей итерации. В результате два агента должны провзаимодействовать для решения этой задачи.
Сравнение
Для решения этой задачи в статье противопоставляются MADDPG и современные одноагентные методы. С использованием MADDPG видны значительные улучшения.
Также было показано, что выводы из политик, даже если политики не были обучены идеально, достигали они тех же успехов, каких можно достичь при использовании истинных наблюдений. Более того, не было замечено значительного замедления конвергенции.
Наконец, ансамбли политик показали очень многообещающие результаты. В статье [1] исследуется влияние ансамблей в конкурентной среде и демонстрируется значительное улучшение производительности по сравнению с агентами с одной политикой.
Заключение
Вот и все. Здесь мы рассмотрели новый подход к мультиагентному обучению с подкреплением. Конечно, существует бесконечное количество методов, относящихся к MARL, однако MADDPG обеспечивает прочный фундамент для методов, которые решают самые глобальные проблемы мультиагентных систем.
Источники
Список полезных статей
- 3 ловушки, в которые попадают начинающие Data Scientists
- Алгоритм AdaBoost
- Как прошел 2019 год в области математики и Computer Science
- Машинное обучение столкнулось с нерешенной математической проблемой
- Понимаем теорему Байеса
- Поиск контуров лица за одну миллисекунду с помощью ансамбля деревьев регрессии
Всех, кому интересно узнать о курсах подробнее и ознакомиться с программой обучения, приглашаем на бесплатный вебинар с автором курса, в рамках которого будут даны ответы на основные вопросы. Также у участников вебинара будет возможность получить скидочный сертификат на оплату курса.