
Различные алгоритмы машинного обучения интегрированы в множество высокоуровневых языков программирования. Наиболее популярным и быстро развивающимся из них является Python.
TensorFlow — открытая программная библиотека для машинного обучения, разработанная компанией Google для решения задач построения и тренировки нейронной сети с целью автоматического нахождения и классификации образов, достигая качества человеческого восприятия. Основной API для работы с библиотекой реализован для Python.
Keras — открытая нейросетевая библиотека. Она представляет собой надстройку над фреймворками TensorFlow и Theano. Нацелена на оперативную работу с сетями глубинного обучения, при этом спроектирована так, чтобы быть компактной, модульной и расширяемой.
В качестве интерпретатора выбрана последняя на данный момент версия Python 3.7.2. Среда разработки — PyCharm Community.
Подготовка данных.
В современном мире, для большинства задач ИИ, не требуется собирать набор данных вручную, существует множество ресурсов, где после прохождения регистрации есть возможность скачать готовые датасеты. Был выбран набор данных с десятью цифрами на языке жестов (рис.1).

Значения пикселей в картинках нормализованы и находятся в интервале (0,1). Их можно сразу использовать для входа в нейронную сеть, но наиболее оптимальный результат будет достигнут, если выполнить процедуру стандартизации. После её выполнения у каждой матрицы пикселей будут выполнены правила:
Среднее значение по матрице равно нулю
Дисперсия в матрице равна единице.
Фотографии стандартизируются и добавляются в новый массив для последующего их объединения с предыдущими данными (Рис.2)

Network_sign_lang.py — основной файл проекта в которым описана нейросеть. В начале скрипта описываются несколько глобальных переменных нейросети (Рис.3).

Импортируется в проект функция train_test_split() из библиотеки Sklearn, она разбивает массивы X и y в отношении 80:20 на обучающую и тестовую выборки, а так же случайным образом перемешивает данные, чтобы они не были отсортированы по классам.
Затем инициализируется модель (Рис.4), добавляется первый слой Conv2D. На вход подается изображения из массива Xtrain, указывается размерность выходного пространства — 64, ядро свертки — 4х4, шаг свертки и функция активации слоя ReLU.

Следующим добавляется слой пулинга (MaxPooling2D). Он служит еще одним фильтром для выхода модели. Поскольку при отображении цифр по горизонтали или вертикали, смысл изображения не меняется, нейросеть должна классифицировать их одинаково.
Flatten слой служит связующим звеном между полученными алгоритмом данными и выходным вектором с предсказанием. Последний слой сети – слой Dense с функцией активации sofmax. Данная функция позволяет получить нормализованный вектор вероятностей для каждого класса, где сумма вероятностей будет равна единице.
Далее необходимо скомпилировать созданную модель, указав следующие параметры: метрику, функцию потерь и оптимизатор. В качестве метрики выбирается точность (accuracy) – процент верно классифицированных примеров. Функция потерь – categorical_crossentropy. Алгоритм оптимизации — Adam. Перед запуском обучения добавляется несколько возвратных функций (callbacks). EarlyStopping — останавливает обучение нейросети, когда её точность перестает возрастать с эпохами обучения. ModelCheckpoint – сохраняет наилучшие веса модели в файл для их последующего использования.
Запускается обучение нейронной сети с сохранением данных о его процессе в переменную histor. Validation_split – возьмет десять процентов от обучающих данных для валидации, что представляет собой еще один способ регуляризации.
Размер обучающей выборки составляет 1965 примеров, тестовой – 547, валидационной – 219. После завершения процесса обучения строится график зависимости точностей, полученных на обучающих и тестовых данных (Рис.5).

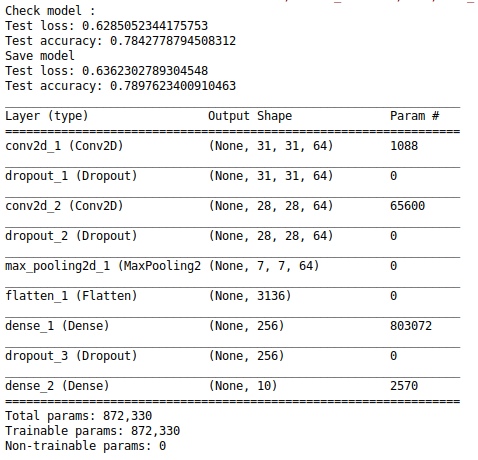
Следующим шагом будет загрузка полученных нейросетей в другой скрипт для проверки их функционирования. Выводятся значения метрик на тестовых данных (Рис.6).
Про препроцессинг данных и интеграцию нейросети определенного формата в IOS приложении мы расскажем в следующей части.