Машинное обучение в Power BI на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-05-29 07:00

Реализованное машинное обучение на AutoML позволяет реализовывать ML-модели внутри Power BI. Однако этот функционал доступен только для данных, размещенных на Power BI Premium и Embedded.
Также в Power BI поддерживается интеграция со службой машинного обучения Azure. Однако для доступа к модели Azure ML из Power BI у пользователя должна иметься подписка на Azure.
Возможность воспользоваться платной подпиской Azure или проприетарным доступом к емкостям Power BI Premium и Embedded имеется не всегда. Обойти это ограничение стало возможно в новых версиях Power BI с появлением поддержки open source библиотек на Python.
Прогноз текучки персонала на Scikit-learn
Рассмотрим небольшой пример применения машинного обучения на Python для получения прогноза объемов текучки персонала организации. Это можно сделать с помощью библиотеки Scikit-learn предоставляющей широкий набор алгоритмов обучения. Мы воспользуемся редактором запросов Python в Power BI, что позволит применить Python для очистки данных, произвести заполнение отсутствующих данных, прогнозирование и кластеризацию, а также подготовку модели данных и создание отчетов. Таким образом мы можем выполнить типовые этапы машинного обучения непосредственно в редакторе запросов Power BI:
- Предварительная обработка данных.
- Машинное обучение.
- Сохранение результатов прогноза.
Для классификации сотрудников и прогноза вероятности увольнения будет использоваться метод логистической регрессии. Величина, которую мы будем прогнозировать – количество увольняющихся сотрудников из компании. При оценке качества модели машинного обучения на основе логистической регрессии будут использоваться обезличенные показатели 15 тысяч сотрудников некой западной компании, получены из открытых источников в Интернет, содержащей параметры увольняющегося из компании сотрудника. Среди параметров есть, например, такие как уровень удовлетворенности, оценка деятельности сотрудника, количество реализованных сотрудником проектов, срок его работы в компании, отдел, в котором он работал и т.п.
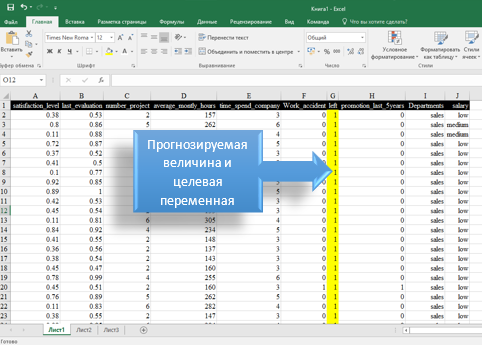
Цель машинного обучения
Нашей целью является создание модели машинного обучения, с помощью которой мы сможем выявить закономерности в имеющемся наборе исходных данных и получить прогноз, который запишется в добавленные новые столбцы наших исходных данных, которые будут описывать вероятность увольнения сотрудника.
Моделирование на Python
Набор исходных данных содержится в csv-файле, для обработки которого будет использоваться сценарий на Python. Рассмотрим составляющие этого сценария.
- Загрузка необходимых зависимостей:
# Загрузить зависимости import pandas as pd import numpy as np from sklearn.preprocessing import LabelEncoder, StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression2. Загрузка набора исходных данных – датасета из csv-файла (часть этого файла была продемонстрирована на рис. 1):
dataset = pd.read_csv('hr_data.csv')Выполнив первые две части сценария в IDE Spyder, мы загрузим наш исходный набор данных в датафрэйм.
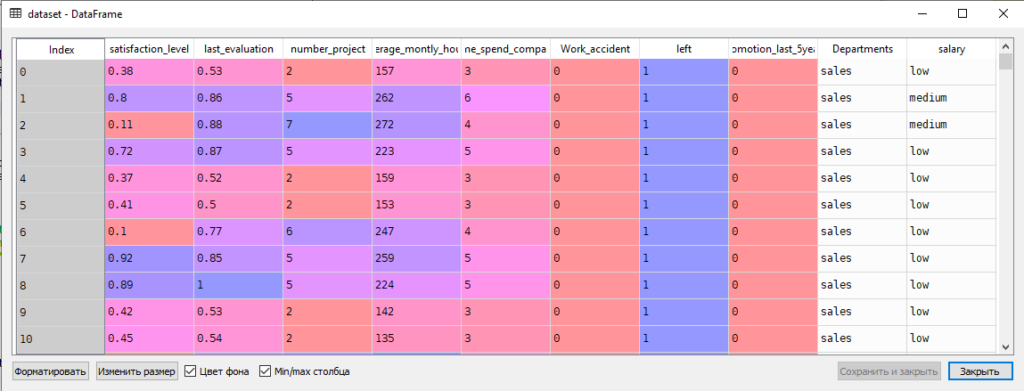
Как видно из рис. 4, у нас имеются два столбца, содержащих нечисловые категории – это отделы (Departments) и заработная плата (salary). Поэтому далее мы должны преобразовать эти два столбца – эти две фичи, в цифровой формат с помощью функции fit_transform().
- Преобразование категорий в исходном наборе в числовые параметры:
# Преобразование категорий в числовые параметры le = LabelEncoder() dataset['Departments'] = le.fit_transform(dataset['Departments']) dataset['salary'] = le.fit_transform(dataset['salary'])После выполнения этой части сценария мы полностью избавимся от нечислового представления фич.
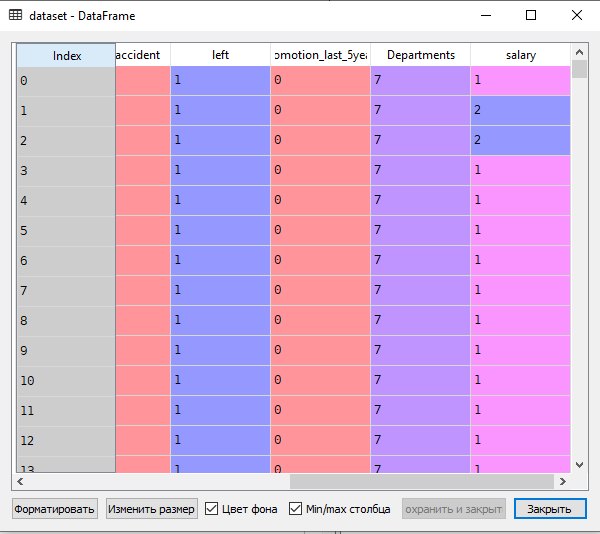
4. Предварительная обработка данных в исходном наборе:
# Предварительная обработка данных y = dataset['left'] features = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'promotion_last_5years', 'Departments', 'salary'] X=dataset[features]Эта часть сценария подготовит наборы данных, которые будут использоваться для логической регрессии.
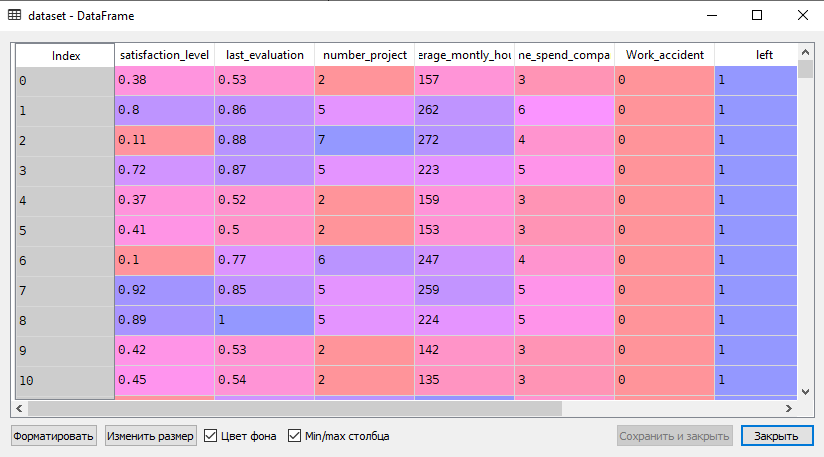
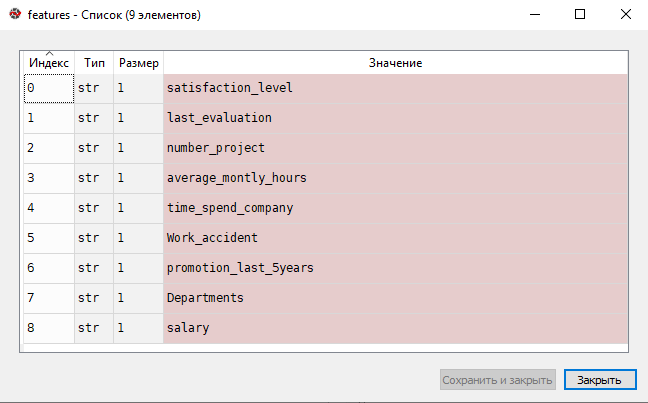
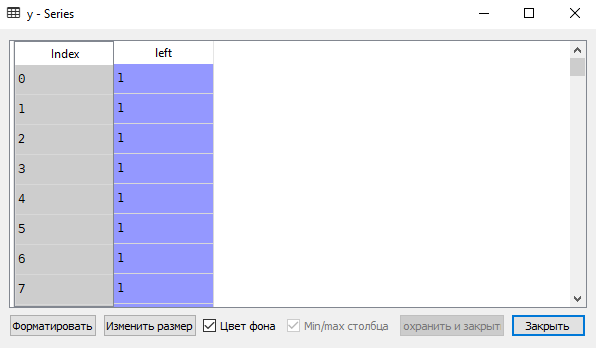
5. Масштабирование данных в исходном наборе:
# Масштабирование данных s = StandardScaler() X = s.fit_transform(X)Поскольку в датафрейме X данные имеют различный масштаб, их необходимо привести к общему основанию, что и выполняется на данном шаге сценария.
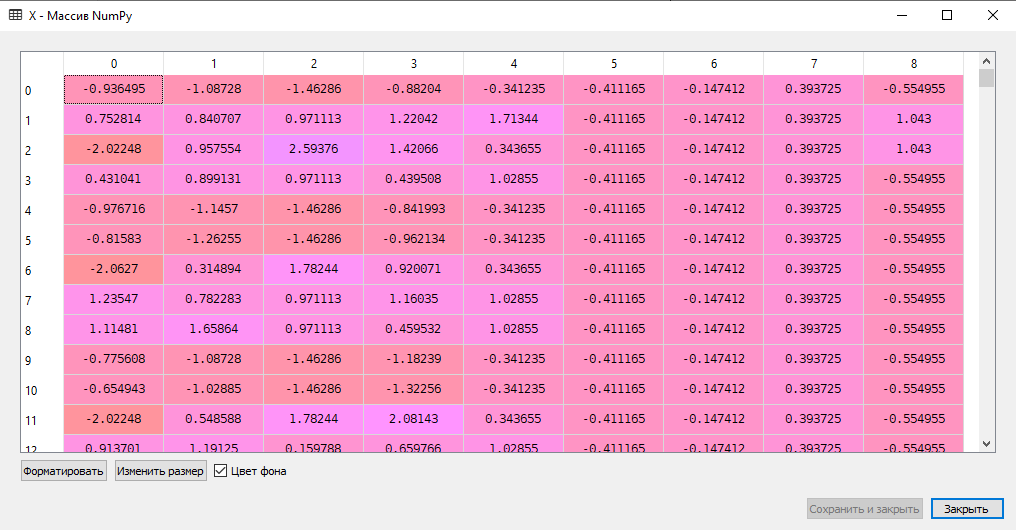
6. Стандартный шаг по разделению данных исходного набора на обучающую и тестовую выборки:
# Разделить и обучить на наборе данных X_train,X_test,y_train,y_test = train_test_split(X,y)7. Моделирование результатов прогноза с помощью логистической регрессии, в результате выполнения которого логистическая модель окажется обученой:
# Моделирование результатов прогноза log = LogisticRegression() log.fit(X_train,y_train) y_pred = log.predict(X) y_prob = log.predict_proba(X)8. Добавление полученных результатов прогноза в исходный набор данных – то есть сохранение результатов прогноза, полученного после обучения модели:
# Добавление столбцов в набор данных dataset['predictions'] = y_pred dataset['probability of leaving'] = y_prob[:,1]В результате выполнения последнего шага сценария в датасет будут записаны прогнозные значения.
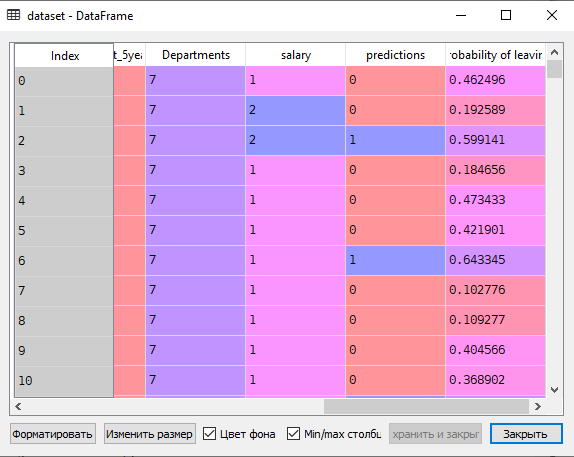
Выполнение Python-сценария в Power BI
Теперь необходимо воспользоваться скриптом на Python, чтобы обработать данные исходного набора данные в Power BI. Для это необходимо:
- Загрузить исходные данные из csv-файла в Power BI Desktop.
- В редакторе Power Query с закладки «Преобразование» нажать кнопку «Запустить скрипт Python».
- В редактор Power BI поместить весь использованный нами сценарий на Python за исключением шага загрузки датасета, поскольку он уже загружен в Power BI.
- Запустить сценарий на выполнение.
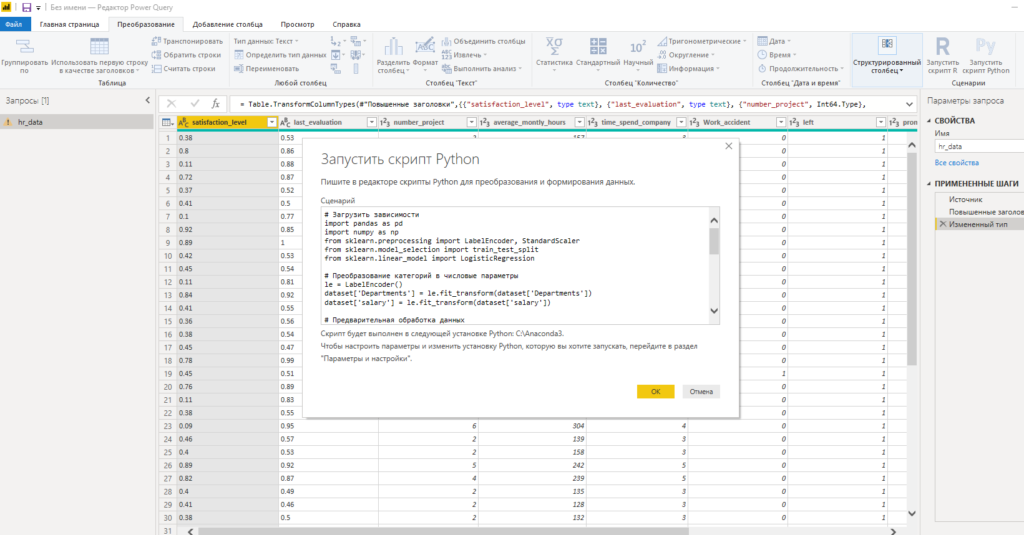
Как только выполнение сценария будет завершено, в Power BI создастся новая таблица результатов, которая будет содержать обновленные данные исходной таблицы, которая уже находится в модели данных Power BI.
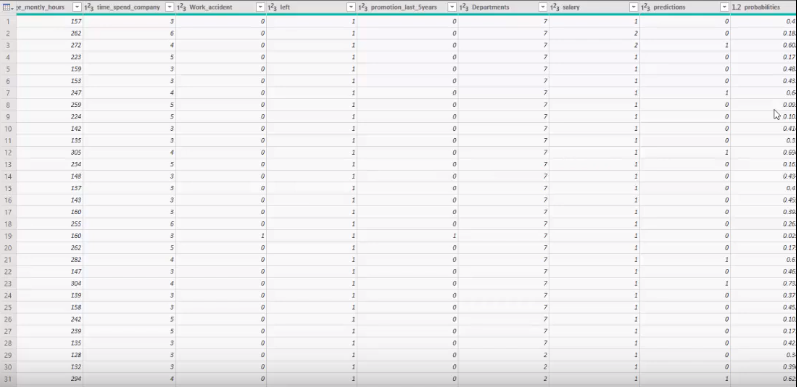
Можно использовать Power BI для визуализации результатов моделирования и сопоставлять прогнозные и фактические данные. Также можно улучшить качество прогноза логистической регрессии или применить другие алгоритмы машинного обучения.
Телеграм: t.me/ainewsline
Источник: newtechaudit.ru