Как с помощью Python скачать все бесплатные учебники Springer Nature
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-05-08 12:01

Издательская компания Springer Nature выложила в открытый доступ более 500 учебников. При помощи скрипта, написанного на Python, мы скачаем все англоязычные книги, указанные в соответствующей таблице Excel.
1. Установка библиотек
Воспользуемся мощью библиотек Python:
- pandas – обработка и анализ данных.
- wget – инструмент загрузки файлов.
- requests – отправка HTTP-запросов.
- xlrd – обработка экселевских файлов (используется библиотекой pandas).
pip3 install xlrd pandas wget requests 2. Изучение списка учебников
Скачаем таблицу Free+English+textbooks.xlsx, содержащую 390 учебников (все списки и актуальные ссылки находятся здесь). Создадим файл download_textbooks.py и папку download, в которую будут скачиваться файлы.
В таблице Excel нас интересуют столбцы Book Title (название учебника), Edition (год издания) и OpenURL для получения ссылки на скачивание (Рис. 1).
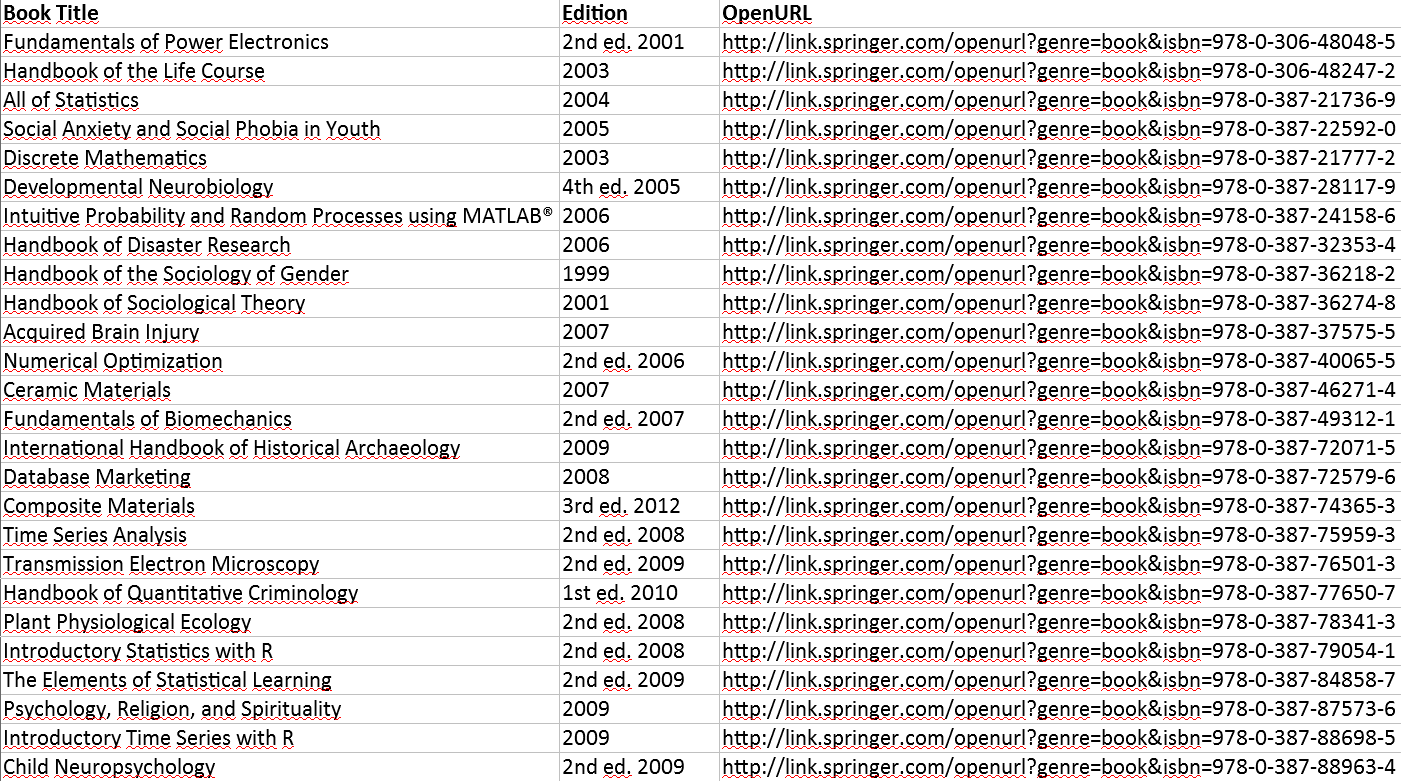
Добавим в download_textbooks.py следующие строчки:
import requests import wget import pandas as pd df = pd.read_excel("Free+English+textbooks.xlsx") print(df.head(10)) Запустим скрипт и получим первые десять строчек из списка (Рис. 2):

3. Выбор правильного URL
Напишем цикл для скачивания файлов:
for index, row in df.iterrows(): file_name = f"{row.loc['Book Title']}_{row.loc['Edition']}" url = f"{row.loc['OpenURL']}" wget.download(download_url, f"./download/{file_name}.pdf") Неплохо, но работает некорректно: столбец OpenUrl содержит ссылку на страницу с описанием книги, а не на конечный PDF-файл. Рассмотрим подробнее устройство ссылок на сайте издательства:
- Возьмем какую-нибудь ссылку из столбца
OpenUrl, например, http://link.springer.com/openurl?genre=book&isbn=978-0-306-48048-5 - Она перенаправляет на https://link.springer.com/book/10.1007%2Fb100747
- На странице есть кнопка для скачивания PDF-файла https://link.springer.com/content/pdf/10.1007%2F0-387-36274-6.pdf
Таким образом, в цикл for нужно добавить 3 шага:
- Открыть ссылку из столбца
OpenURL. - Получить перенаправленный URL.
- Переформатировать структуру строки URL в конечный URL для загрузки PDF-файла.
В итоге код выглядит следующим образом:
import requests, wget import pandas as pd df = pd.read_excel("Free+English+textbooks.xlsx") for index, row in df.iterrows(): file_name = f"{row.loc['Book Title']}_{row.loc['Edition']}".replace('/','-').replace(':','-') url = f"{row.loc['OpenURL']}" r = requests.get(url) download_url = f"{r.url.replace('book','content/pdf')}.pdf" wget.download(download_url, f"./download/{file_name}.pdf") print(f"downloading {file_name}.pdf Complete ....") 4. Скачивание учебников
Запустим скрипт download_textbooks.py (Рис. 3), откроем папку download и проследим за результатом работы (Рис. 4).
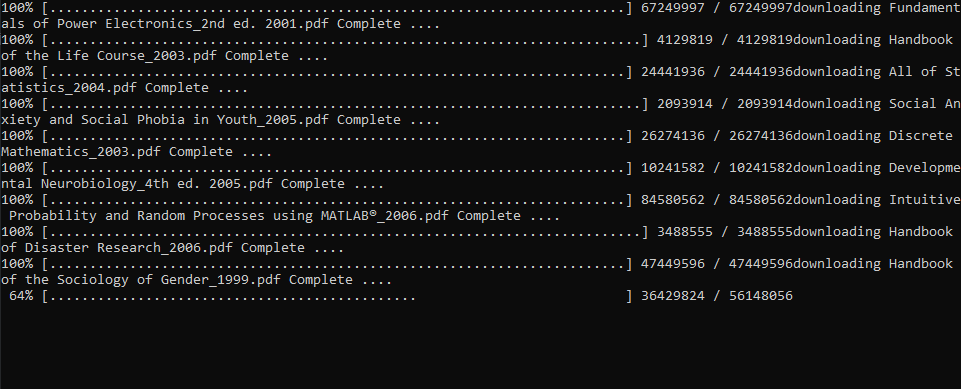
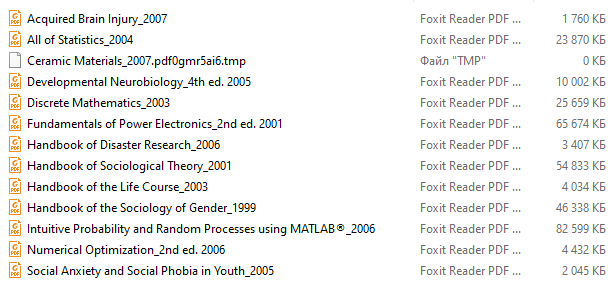
***
Вот и всё. Мы освободились от ненужной рутины, автоматизировав процесс скачивания всего за 10 строчек кода, используя библиотеки pandas, wget, requests и xlrd. Приятного чтения!
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io