
В одной из последних статей мы говорили о том, как создать детектор аномалий в Power BI, интегрировав в него PyCaret, и помочь аналитикам и специалистам по анализу данных добавить машинное обучение в отчеты и панели мониторинга без лишних трудозатрат. В этой статье мы рассмотрим, как с помощью PyCaret и Power BI провести кластерный анализ. Если раньше вы ничего не слышали о PyCaret, начать знакомство с ним вы можете тут. Что мы разберем в сегодняшнем руководстве:
- Что такое кластеризация? Типы кластеризации.
- Обучение без учителя и реализация модели кластеризации в Power BI.
- Анализ результатов и визуализация информации на панели мониторинга.
- Как развернуть модель кластеризации на продакшене в Power BI?
Прежде чем мы начнем…
Если вы уже пользовались Python раньше, скорее всего у вас на компьютере уже есть дистрибутив Anaconda. Если нет, скачать дистрибутив Anaconda с Python 3.7 или выше вы можете отсюда.
Настройка среды
Перед тем как начать пользоваться возможностями машинного обучения PyCaret в Power BI, нужно создать виртуальную среду и установить в нее pycaret. Для этого нам нужно выполнить три шага:
Шаг 1 – Создать виртуальную среду
Откройте командную строку Anaconda и введите следующее:
conda create --name myenv python=3.7Шаг 2 – Установите PyCaret
Выполните следующую команду в командной строке Anaconda:
pip install pycaretУстановка может занять 15-20 минут. Если во время установки у вас возникнут какие-то проблемы, вы можете ознакомиться с их решением на нашей странице на GitHub. Шаг 3 – Укажите в Power BI, где установлен Python
Созданная виртуальная среда должна быть связана с Power BI. Сделать это можно с помощью Global Settings в Power BI Desktop (File ? Options ? Global ? Python scripting). Среда Anaconda по умолчанию ставится в директорию:
C:UsersusernameAppDataLocalContinuumanaconda3envsmyenv
Что такое кластеризация?
Кластеризация – это метод разбиения данных на группы по схожим характеристикам. Такие группы могут быть оказаться полезными для изучения данных, выявления закономерностей и анализа подмножеств данных. Организация данных в кластеры помогает выявить базовые структуры данных, что оказывается полезным во многих отраслях промышленности. Вот некоторые распространенные варианты использования кластеризации в бизнесе:
- Маркетинговая сегментация клиентов.
- Анализ покупательского поведения для проведения рекламных акций и скидок.
- Определение геокластеров во время вспышки эпидемии, такой как, например, COVID-19.
Типы кластеризации
Учитывая субъективный характер задач кластеризации, существуют различные алгоритмы, которые лучше подходят для решения тех или иных типов задач. У каждого алгоритма есть свои особенности и математическое обоснование, которое лежит в основе распределения по кластерам.
В сегодняшнем руководстве мы говорим о кластерном анализе в Power BI с использованием библиотеки Python под названием PyCaret и не будем глубоко уходить в математику.

Бизнес-контекст
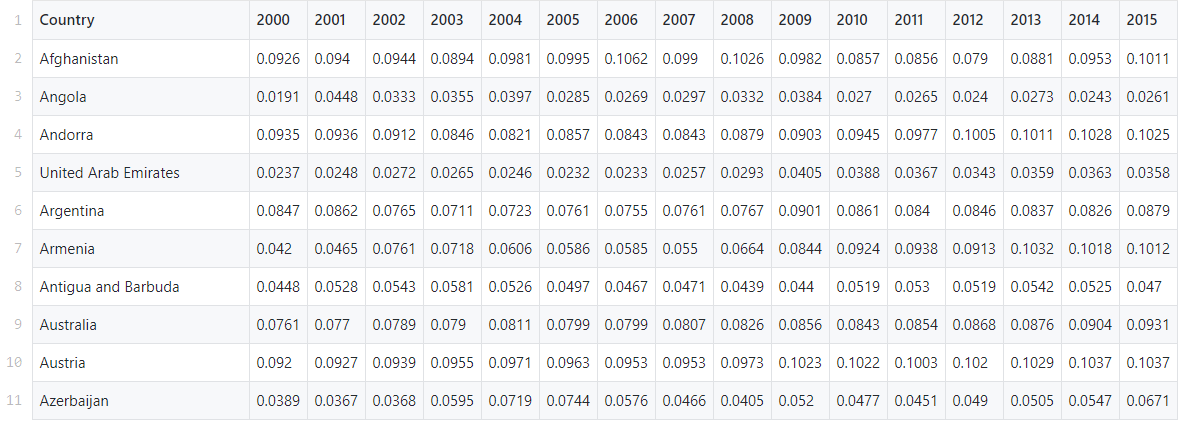
В этом руководстве мы воспользуемся уже готовым набором данных из базы данных World Health Organization’s Global Health Expenditure. В нем содержатся расходы на здравоохранение в процентах от национального ВВП для более чем 200 стран с 2000 по 2017 год.
Наша задача – найти паттерны и группы в этих данных с помощью метода k-средних.
Данные можно найти здесь.
Итак, начнем
Теперь, когда вы настроили среду Anaconda, поставили PyCaret, понимаете основы кластерного анализа и бизнес-контекст, пора приступать к делу.
1. Получение данных
Первым шагом мы импортируем набор данных в Power BI Desktop. Вы можете загрузить данные с помощью веб-коннектора. (Power BI Desktop ? Get Data ? From Web).

2. Обучение модели
Для обучения модели кластеризации в Power BI нам нужно выполнить скрипт на Python в Power Query Editor (Power Query Editor ? Transform ? Run python script). В качестве скрипта используйте следующий код:
from pycaret.clustering import * dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
ignore_features. Есть множество причин, по которым вам может понадобиться исключить те или иные столбцы, чтобы лучше обучить модель машинного обучения.PyCaret позволяет вам скрывать ненужные столбцы, вместо того, чтобы удалять их, поскольку, они могут вам понадобиться в будущем для проведения дальнейшего анализа. Например, сейчас мы не захотели использовать «Country» для обучения и передали этот столбец в
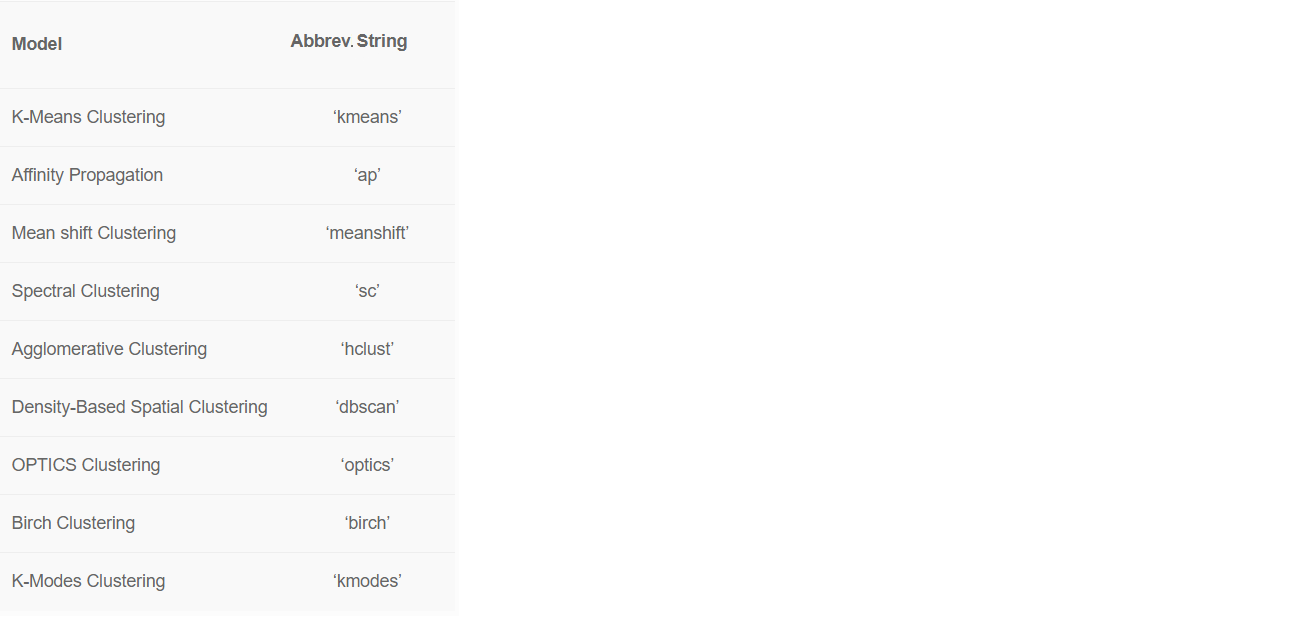
ignore_features.Сейчас в PyCaret есть 8 готовых к использованию алгоритмов машинного обучения.
- Чтобы изменить тип модели, используйте параметр model в
get_clusters(). - Чтобы изменить количество кластеров, используйте параметр
num_clusters.
Например, вот так можно сделать кластеризацию по методу k-средних на 6 кластеров.
from pycaret.clustering import * dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])Вывод:

Вот так конечный результат будет выглядеть в Power BI.
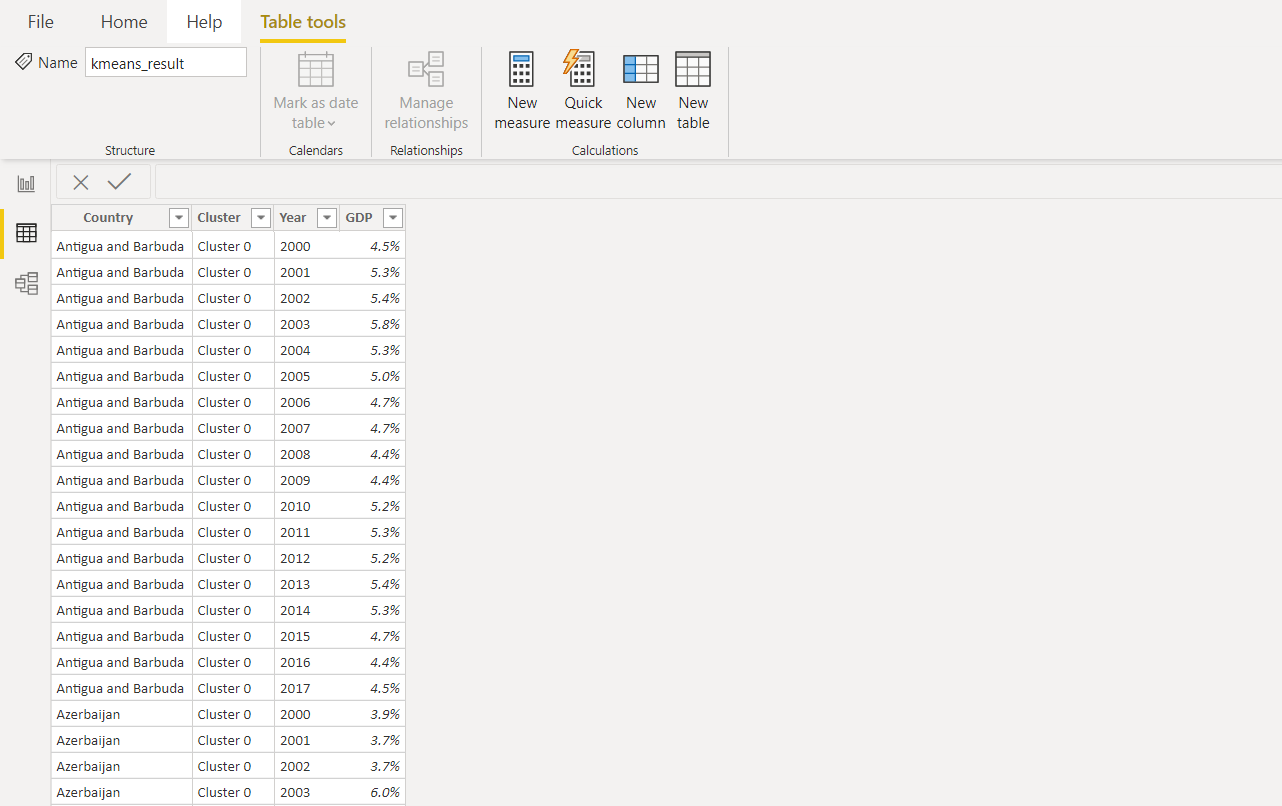
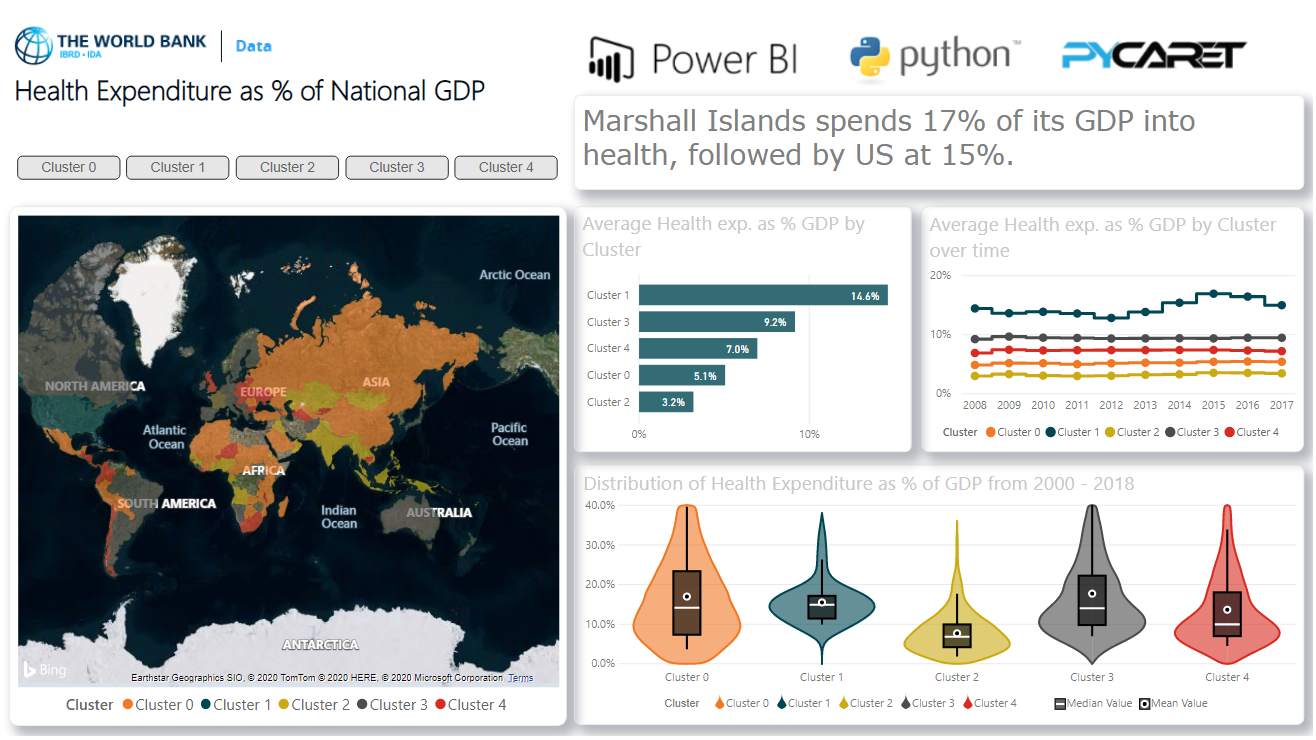
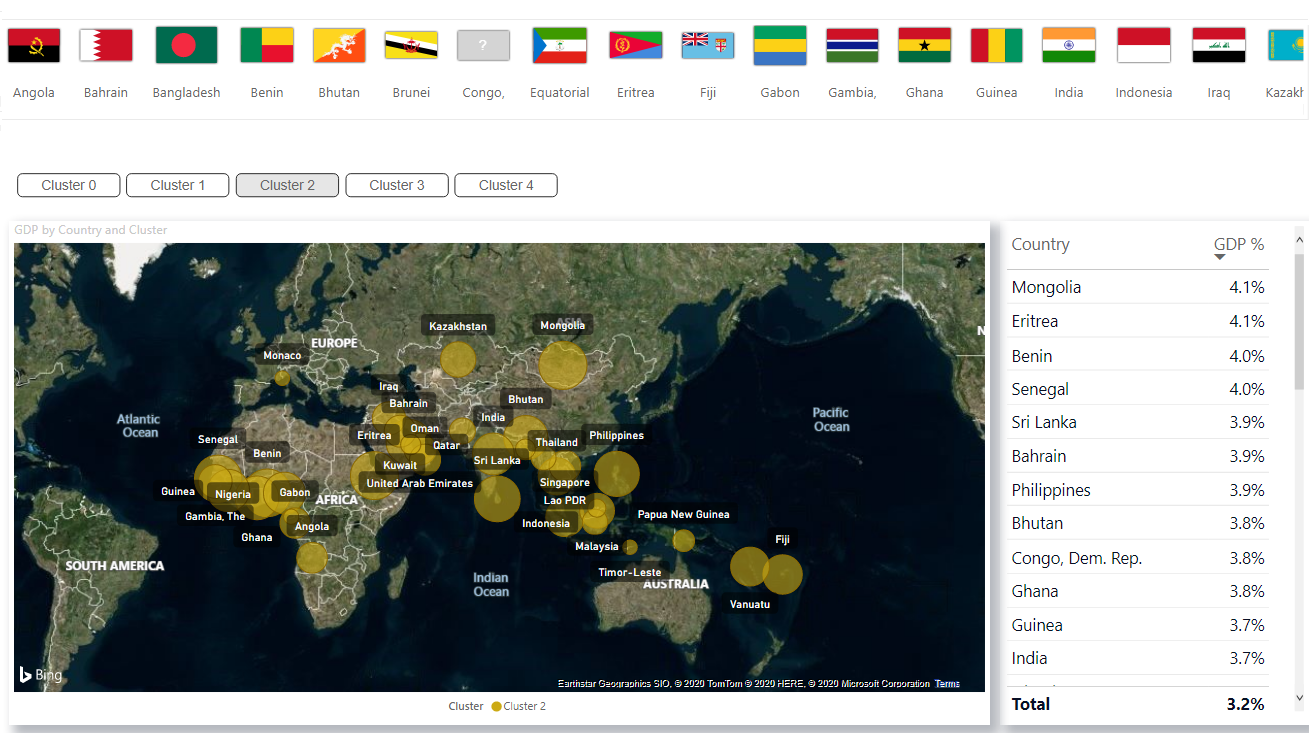
3. Панель мониторинга
Когда вы обзавелись метками кластеров в Power BI, вы можете визуализировать их в панели мониторинга в Power BI для проведения аналитики:
Реализация кластеризации на продакшене
Выше мы продемонстрировали самую простую реализацию кластеризации в Power BI. Отмечу, что такой метод обучает модель кластеризации каждый раз при обновлении набора данных в Power BI. Это может стать проблемой по следующим причинам:
- При повторном обучении модели на новых данных метки кластеров могут измениться (то есть, если раньше некоторые точки данных были отнесены к первому кластеру, то при повторном обучении они могут быть отнесены ко второму кластеру);
- Вам не захочется каждый раз тратить по несколько часов на переобучение модели.
Более эффективным способом реализации кластеризации в Power BI вместо повторного обучения раз за разом является использование предобученной модели для создания меток кластеров.
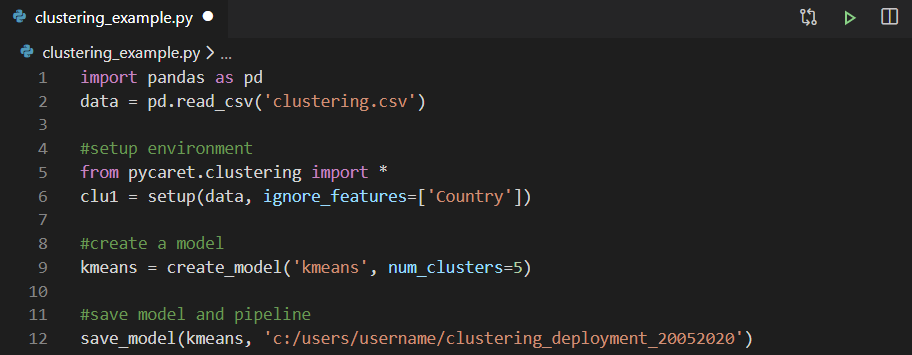
Заблаговременное обучение модели
Для обучения модели можно использовать любую интегрированную среду разработки (IDE) или Notebook. В этом примере мы обучали модель кластеризации в Visual Studio Code.

Использование предобученной модели
Выполните код ниже, чтобы сгенерировать метки из предобученной модели:
from pycaret.clustering import * dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)Результат будет тем же, что мы наблюдали ранее. Разница лишь в том, что при использовании предобученной модели метки будут генерироваться на основе нового набора данных с использованием старой модели, а не на модели, которая была повторно обучена.
Работа с сервисом Power BI
После того, как вы загрузите файл .pbix в сервис Power BI, нужно будет выполнить еще несколько шагов, чтобы обеспечить плавную интеграцию пайплайна машинного обучения в ваш пайплайн данных. Шаги будут следующие:
- Включите запланированное обновление набора данных – это позволит по расписанию обновлять workbook с вашим набором данных с помощью скрипта на Python, загляните в раздел Configuring scheduled refresh, в котором также есть информация о Personal Gateway.
- Установите Personal Gateway – вам понадобится Personal Gateway, который должен быть установлен в той же директории, где установлен Python. Сервис Power BI должен иметь доступ к среде Python. Здесь вы можете узнать больше о том, как установить и настроить Personal Gateway.
Если вы хотите узнать больше о кластерном анализе, то можете ознакомиться с нашим руководством в этом notebook’e.