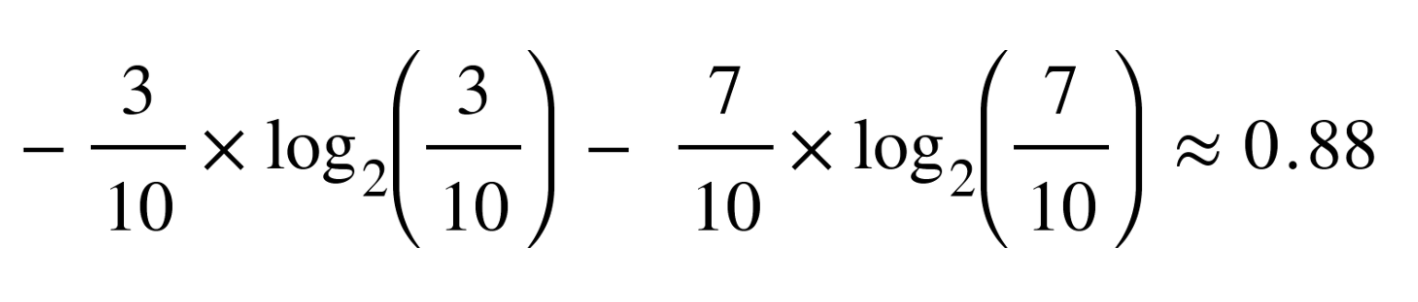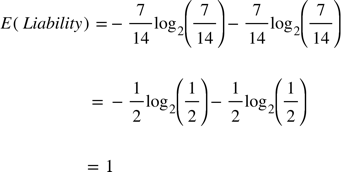Перевод статьи подготовлен в преддверии старта курса «Machine Learning».
Вы специалист по Data Science, который сейчас идет по тропе обучения. И вы уже прошли долгий путь с того момента, как написали свою первую строку кода на Python или R. Вы знаете Scikit-Learn как свои пять пальцев. Теперь вы больше сидите на Kaggle, чем на Facebook. Вы не новичок в создании потрясающих случайных лесов и других моделей ансамбля деревьев решений, которые отлично справляются со своей работой. Тем не менее, вы знаете, что ничего не добьетесь, если не будете всесторонне развиваться. Вам хочется копнуть глубже и разобраться в тонкостях и концепциях, лежащих в основе популярных моделей машинного обучения. Что ж, мне тоже.
Сегодня я расскажу о понятии энтропии — одной из важнейших тем статистики, а позже мы поговорим о понятии Information Gain (информационный выигрыш) и выясним, почему эти фундаментальные концепции формируют основу того, как исходя из полученных данных строятся деревья решений. Хорошо. А теперь преступим.
Что такое энтропия? Говоря простым языком, энтропия – это не что иное, как мера беспорядка. (Еще ее можно считать мерой чистоты, и скоро вы увидите почему. Но мне больше нравится беспорядок, потому что он звучит круче.)
Математическая формула энтропии выглядит следующим образом:
Энтропия. Иногда записывается как H.
Здесь pi – это частотная вероятность элемента/класса i наших данных. Для простоты, предположим, что у нас всего два класса: положительный и отрицательный. Тогда i будет принимать значение либо «+», либо «-». Если бы у нас было в общей сложности 100 точек в нашем наборе данных, 30 из которых принадлежали бы положительному классу, а 70 – отрицательному, тогда p+ было бы равно 3/10, а p- будет 7/10. Тут все просто.
Если я буду вычислять энтропию классов из этого примера, то вот, что я получу, воспользовавшись формулой выше:
Энтропия составит примерно 0,88. Такое значение считается довольно высоким, то есть у нас высокий уровень энтропии или беспорядка (то есть низкое значение чистоты). Энтропия измеряется в диапазоне от 0 до 1. В зависимости от количества классов в вашем наборе данных значение энтропии может оказаться больше 1, но означать это будет все то же, что уровень беспорядка крайне высок. Для простоты объяснения в сегодняшней статье энтропия у нас будет находиться в пределах от 0 до 1. Взгляните на график ниже.
На оси X отражено количество точек из положительного класса в каждой окружности, а на оси Y – соответствующие им энтропии. Вы сразу же можете заметить перевернутую U-образную форму графика. Энтропия будет наименьшей в экстремумах, когда внутри окружности нет положительных элементов в принципе, либо когда в них только положительные элементы. То есть, когда в окружности одинаковые элементы – беспорядок будет равен 0. Энтропия окажется наиболее высокой в середине графика, где внутри окружности будут равномерно распределены положительные и отрицательные элементы. Здесь будет достигаться самая большая энтропия или беспорядок, поскольку не будет преобладающих элементов. Есть ли какая-то причина тому, что энтропия измеряется именно с помощью логарифма по основанию 2 или же почему энтропия измеряется между 0 и 1, а не в ином диапазоне? Нет, причины нет. Это всего лишь метрика. Не так важно понимать, почему так происходит. Важно знать, как вычисляется и как работает то, что мы получили выше. Энтропия – это мера беспорядка или неопределенности, а цель моделей машинного обучения и специалистов по Data Science в целом состоит в том, чтобы эту неопределенность уменьшить.
Теперь мы знаем, как измеряется беспорядок. Дальше нам понадобится величина для измерения уменьшения этого беспорядка в дополнительной информации (признаках/независимых переменных) целевой переменной/класса. Вот тут в игру вступает Information Gain или информационный выигрыш. С точки зрения математики его можно записать так:
Мы просто вычтем энтропию Y от X, из энтропии Y, чтобы вычислить уменьшение неопределенности относительно Y при условии наличия информации X об Y. Чем сильнее уменьшается неопределенность, тем больше информации может быть получено из Y об X. Давайте рассмотрим простой пример таблицы сопряженности, чтобы приблизиться к вопросу о том, как деревья решений используют энтропию и информационный выигрыш, чтобы решить по какому признаку разбивать узлы в процессе обучения на данных.
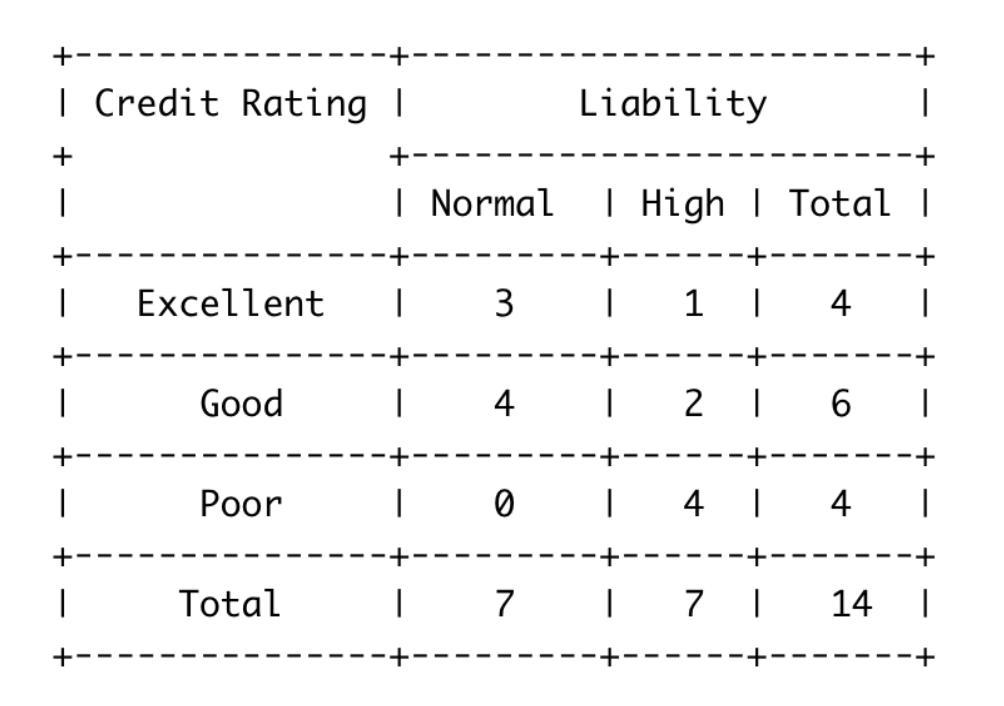
Пример: Таблица сопряженности
Здесь нашей целевой переменной будет Liability, которая может принимать всего два значения: “Normal” и “High”. Еще у нас есть всего один признак, который называется Credit Rating, он распределяет значения по трем категориям: “Excellent”, “Good” и “Poor”. Всего было сделано 14 наблюдений. 7 из них относятся к классу Normal Liability, и еще 7 к классу High Liability. Это уже само по себе разделение.
Если мы посмотрим на итоговую сумму значений в первой строке, то увидим, что у нас есть 4 наблюдения со значением Excellent по признаку Credit Rating. Более того, я даже могу сказать, что моя целевая переменная разбивается по “Excellent” Credit Rating. Среди наблюдений со значением “Excellent” по признаку Credit Rating, есть 3, которые относятся к классу Normal Liability и 1, которое относится к High Liability. Аналогично я могу вычислить подобные результаты для других значений Credit Rating из таблицы сопряженности.
Для примера я использую вышеприведенную таблицу сопряженности, чтобы самостоятельно вычислить энтропию нашей целевой переменной, а затем вычислить ее энтропию с учетом дополнительной информации признака Credit Rating. Так я смогу рассчитать сколько дополнительной информации мне даст Credit Rating для целевой переменной Liability.
Итак, приступим.
Энтропия нашей целевой переменной равна 1, что значит максимальный беспорядок из-за равномерного распределения элементов между “Normal” и “High”. Следующим шагом мы рассчитаем энтропию целевой переменной Liability с учетом дополнительной информации из Credit Rating. Для этого мы рассчитаем энтропию Liability для каждого значения Credit Rating и сложим их с помощью среднего взвешенного отношения наблюдений для каждого значения. Почему мы используем среднее взвешенное, станет яснее, когда мы будем говорить о деревьях решений.
Мы получили энтропию нашей целевой переменной с учетом признака Credit Rating. Теперь мы можем вычислить информационный выигрыш Liability от Credit Rating, чтобы понять, насколько этот признак информативен.
Знание Credit Rating помогло нам уменьшить неопределенность нашей целевой переменной Liability. Разве не так должен работать хороший признак? Давать нам информацию о целевой переменной? Что ж, именно по этой причине деревья решений используют энтропию и информационный выигрыш. Они определяют по какому признаку разбивать узлы на ветви, чтобы с каждым следующим разбиением приближаться к целевой переменной, а также, чтобы понять, когда построение дерева нужно завершить! (в дополнение к гиперпараметрам, таким как максимальная глубина, конечно же). Давайте посмотрим, как это все работает на следующем примере с использованием деревьев решений.
Пример: Дерево Решений
Давайте рассмотрим пример построения дерева решений, с целью предсказания того, будет ли кредит человека списан или нет. В популяции будет 30 экземпляров. 16 будут принадлежать классу “write-off”, а другие 14 к “non-write-off”. У нас будет два признака, а именно “Balance”, который может принимать два значения: “< 50K” или “>50K”, и “Residence”, который принимает три значения: “OWN”, “RENT” или “OTHER”. Я продемонстрирую, как алгоритм дерева решений будет принимать решение о том, какой атрибут разбить первым и какой признак будет более информативным, то есть лучше всего устраняет неопределенность целевой переменной с помощью использования концепции энтропии и информационного выигрыша.
Признак 1: Balance
Здесь кружки относятся к классу “write-off”, а звездочки – к классу “non-write-off”. Разбиение корня-родителя по атрибуту Balance даст нам 2 узла-наследника. В левом узле будет 13 наблюдений, где 12/13 (вероятность 0,92) наблюдений из класса “write-off”, и всего 1/13 (вероятность 0,08) наблюдений из класса “non-write-off”. В правом узле будет 17 из 30 наблюдений, где 13/17 (вероятность 0,76) наблюдений из класса “write-off” и 4/17 (вероятность 0,24) наблюдений из класса “non-write-off”.
Давайте вычислим энтропию корня и посмотрим, насколько дерево сможет уменьшить неопределенность с помощью разбиения по признаку Balance.
Разбиение по признаку Balance даст информационный выигрыш равный 0,37. Давайте посчитаем то же самое для признака Residence и сравним результаты.
Признак 2: Residence
Разбиение дерева по признаку Residence даст вам 3 узла-наследника. Левый узел-наследник получит 8 наблюдений, где 7/8 (вероятность 0,88) наблюдений из класса “write-off” и всего 1/8 (вероятность 0,12) наблюдений из класса “non-write-off”. Средний узел-наследник получит 10 наблюдений, где 4/10 (вероятность 0,4) наблюдений из класса “write-off” и 6/10 (вероятность 0,6) наблюдений из класса “non-write-off”. Правый узел-наследник получит 12 наблюдений, где 5/12 (вероятность 0,42) наблюдений из класса “write-off” и 7/12 (вероятность 0,58) наблюдений из класса “non-write-off”. Мы уже знаем энтропию узла-родителя, поэтому мы просто вычислим энтропию после разбиения, чтобы понять информационный выигрыш от признака Residence.
Информационный выигрыш от признака Balance почти в 3 раза больше, чем от Residence! Если вы снова взглянете на графы, то увидите, что разбиение по признаку Balance даст более чистые узлы-наследники, чем по Residence. Однако самый левый узел в Residence тоже достаточно чистый, но именно тут в игру вступает среднее взвешенное. Несмотря на то, что узел чистый, в нем меньше всего наблюдений, и его результат теряется при общем пересчете и вычислении итоговой энтропии по Residence. Это важно, поскольку мы ищем общую информативность признака и не хотим, чтобы конечный результат был искажен редким значением признака.
Сам по себе признак Balance дает больше информации о целевой переменной, чем Residence. Таким образом энтропия нашей целевой переменной уменьшается. Алгоритм дерева решений использует этот результат, чтобы сделать первое разбиение по признаку Balance, чтобы позже принять решение по какому признаку разбивать следующие узлы. В реальном мире, когда признаков больше двух, первое разбиение происходит по наиболее информативному признаку, а затем при каждом следующем разбиении будет пересчитываться информационный выигрыш относительно каждого дополнительного признака, поскольку он не будет таким же, как информационный выигрыш от каждого признака по отдельности. Энтропия и информационный выигрыш должны быть рассчитаны после того, как произойдет одно или несколько разбиений, что повлияет на итоговый результат. Дерево решений будет повторять этот процесс по мере своего роста в глубину, пока оно либо не достигнет определенной глубины, либо какое-то разбиение не приведет к более высокому информационному выигрышу за определенным порогом, который также может быть указан в качестве гиперпараметра!
Вот и все! Теперь вы знаете, что такое энтропия, информационный выигрыш и как они вычисляются. Теперь вы понимаете как дерево решений само по себе или в составе ансамбля принимает решения о наилучшем порядке разбиения по признакам и решает, когда остановиться при обучении на имеющихся данных. Что ж, если вам придется объяснять кому-то как работают деревья решений, надеюсь, вы достойно справитесь с этой задачей.
Надеюсь, вы извлекли что-нибудь полезное для себя из этой статьи. Если я что-то упустил или выразился неточно, напишите мне об этом. Я буду вам очень признателен! Спасибо.