Data mining. Как превращать данные в золото и зачем для этого Java?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-05-14 13:55

Сегодня поговорим о Data mining (“добыча данных”, “интеллектуальный анализ данных”, “глубинный анализ данных” или просто “майнинг данных” в русскоязычной интерпретации).
“Мы верим в Бога. Чтобы поверить во все остальное, нужны данные.”
Уильям Эдвардс Деминг (W. Edwards Deming), американский ученый и статистик.
Что такое Data mining?
Data mining — это собирательное название, которое используется для описания целого ряда методов исследования и анализа больших объемов данных для выявления в них закономерностей и правил. Добыча данных считается отдельной дисциплиной в области науки о данных.
Если говорить о распространенном применении знаний и разработок в данной сфере, то Data mining компании чаще всего используют для того, чтобы извлекать из данных полезную для себя информацию. С помощью программных решений для поиска паттернов в больших объемах данных компании могут изучать поведение и привычки потребителей, чтобы разрабатывать более эффективные маркетинговые решения, повышать продажи и сокращать расходы.
Кроме того, методы интеллектуального анализа данных используются для построения моделей машинного обучения (machine learning, ML), которые используются в современных приложениях искусственного интеллекта, таких как алгоритмы поисковых систем и системы рекомендаций, например.
“Можно иметь данные, но не иметь информации, но информации без данных не бывает.”
Дэниел Киз Моран (Daniel Keys Moran), эксперт в программировании и писатель.
Чем Data mining отличается от Больших данных (Big data)?
Также будет полезно сразу прояснить, чем добыча данных как понятие отличается от Больших данных.
Если говорить по-простому, то термином Big data обозначают все аспекты больших объемов данных разного рода, включая как структурированные, так и неструктурированные данные, их сбор, хранение, классификацию и т.д. Тогда как Data mining относится исключительно к глубокому погружению в данные для извлечения ключевых знаний, шаблонов и сходств, а также другой информации из данных любого объема (как большого, так и не очень).
Таким образом, оба понятия относятся к данным и в целом пересекаются, но Data mining — это уже об использовании собранной информации с конкретными целями.
“Без глубинного анализа данных компании ничего не видят и не слышат; в Сети они так же беспомощны и растеряны, как олень, выбежавший на автостраду.”
Джеффри Мур (Geoffrey Moore), писатель и специалист по теории менеджмента.

Сферы применения Data mining
Применяется глубинный анализ данных, как вы понимаете, очень широко. Давайте коротко пройдемся по тем отраслям и сферам деятельности, где он используется чаще всего.
- Маркетинг и таргетинг целевых групп потребителей в ритейле.
Чаще других дата майнинг применяют ритейлеры, чтобы лучше понимать потребности своих клиентов. Анализ данных позволяет им более точно разделять потребителей по группам и подстраивать под них рекламные акции.
Например, продуктовые супермаркеты часто предлагают покупателям завести карту постоянного клиента, которая открывает скидки, недоступные остальным. С помощью таких карт ритейлеры собирают данные о том, какие покупки совершают те или иные группы потребителей. Применение глубинного анализа к этим данным позволяет изучать их привычки и предпочтения, адаптируя к учётом этой информации ассортимент и акции.
- Управление кредитными рисками и кредитными историями в банках.
Банки разрабатывают и внедряют модели интеллектуального анализа данных для прогнозирования способности заемщика брать и погашать кредиты. Используя разного рода демографические и личные данные заемщика, эти модели автоматически определяют процентную ставку в зависимости от уровня риска каждого клиента индивидуально.
- Обнаружение и борьба с мошенничеством в финансовой сфере.
Финансовые организации используют Data mining для обнаружения и предотвращения мошеннических транзакций. Данная форма анализа применяется ко всем транзакциям, и зачастую потребители даже не подозревают об этом. Например, отслеживание регулярных расходов клиента банка позволяет автоматически выявлять подозрительные платежи и мгновенно задерживать их осуществление до тех пор, пока пользователь не подтвердит покупку. Таким образом Data mining используется для защиты потребителей от разного рода мошенников.
- Анализ настроений в социологии.
Анализ настроений на основе данных социальных сетей — также распространенная сфера применения глубинного анализа данных, в которой используется метод, называемый анализом текста. С его помощью можно получить понимание того, как определенная группа людей относится к определенной теме. Это делается с помощью автоматического анализа данных из социальных сетей или других публичных источников.
- Биоинформация в здравоохранении.
В медицине Data mining модели используются, чтобы предсказывать вероятность возникновения у пациента различных недугов на основании факторов риска. Для этого собирают и анализируют демографические, семейные и генетические данные. В развивающихся странах с большим населением такие модели не так давно начали внедрять, чтобы диагностировать пациентов и расставлять приоритеты медицинской помощи еще до прибытия врачей и личного осмотра.
“Если изучать данные достаточно тщательно, можно найти в них сообщения от Бога.”
Скотт Адамс (Scott Adams), писатель, юморист

Data mining и Java
Как вы уже, должно быть, поняли из контекста, в сфере добычи данных, как и везде в Big data, Java является одним из основных языков программирования. Поэтому сделаем небольшой обзор основных инструментов дата майнинга на Java.
- RapidMiner
RapidMiner — это открытая платформа для добычи данных, написанная на Java. Одно из лучших доступных решений для прогнозного анализа с возможностью создания интегрированных сред для глубокого обучения, анализа текстов и машинного обучения. Многие организации используют для глубинного анализа данных именно ее. RapidMiner можно использовать как на локальных серверах, так и в облаке.
- Apache Mahout
Apache Mahout — это open source Java библиотека для машинного обучения от Apache. Mahout является именно инструментом масштабируемого машинного обучения с возможностью обработки данных на одной или нескольких машинах. Реализации данного машинного обучения написаны на Java, некоторые части построены на Apache Hadoop.
- MicroStrategy
MicroStrategy — это программная платформа для бизнес-аналитики и анализа данных, которая поддерживает все модели добычи данных. Благодаря широкому набору собственных шлюзов и драйверов платформа может подключаться к любому корпоративному ресурсу и анализировать его данные. MicroStrategy отлично справляется с преобразованием сложных данных в упрощенные визуализации, которые можно использовать с разными целями.
- Java Data Mining Package
Java Data Mining Package — это библиотека Java с открытым исходным кодом для анализа данных и машинного обучения. Она облегчает доступ к источникам данных и алгоритмам машинного обучения и предоставляет модули визуализации. JDMP включает в себя ряд алгоритмов и инструментов, а также интерфейсы для других пакетов машинного обучения и интеллектуального анализа данных (таких как LibLinear, Elasticsearch, LibSVM, Mallet, Lucene, Octave и другие).
- WEKA Machine Learning Suite
Waikato Environment for Knowledge Analysis (WEKA) Machine Learning Suite — это открытый список алгоритмов, которые используются для разработки методов машинного обучения. Все алгоритмы WEKA заточены под машинное обучение и интеллектуальный анализ данных. Сейчас набор WEKA Machine Learning Suite широко используется в бизнес-среде, предоставляя компаниям упрощенный анализ данных и предиктивную аналитику.
“Современный мир переполнен данными, и благодаря этому мы можем видеть потребителей намного яснее.”
Макс Левчин (Max Levchin), со-основатель PayPal
Как осуществляется добыча данных
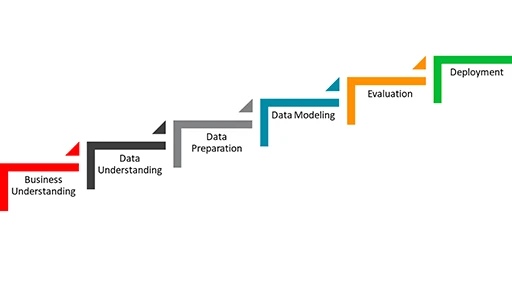
Общепринятый процесс майнинга данных состоит из шести этапов.
• Определение бизнес-целей.
Для начала нужно сформировать общие бизнес-цели проекта и понять, как майнинг данных поможет их достичь. На этой стадии должен быть разработан план, включающий сроки, действия и назначения ролей.
• Понимание данных.
На втором этапе проводится сбор необходимых данных из разных источников. Для изучения свойств данных, чтобы гарантировать, что они помогут достичь бизнес-целей, часто используют инструменты визуализации. На этом и следующем этапе чаще всего применяются Java-инструменты и, соответственно, требуется квалификация Java-программиста.
• Подготовка данных.
Затем данные очищаются и дополняются, чтобы убедиться, что массив готов к добыче информации. В зависимости от объема анализируемых данных и количества источников данных, обработка может занимать огромное количество времени. Поэтому для обработки используют современные системы управления базами данных (СУБД), что позволяет ускорить процесс глубинного анализа.
• Моделирование данных.
На этом этапе к данным применяются специальные инструменты и математические модели, которые позволяют находить в них закономерности.
• Оценка.
Затем полученные результаты оценивают и сопоставляют с бизнес-целями, чтобы определить, позволяют ли полученные данные их достичь.
• Развертывание.
Ну и на заключительном этапе добытые в результате вышеописанных шагов данные интегрируются в бизнес-операции. В качестве инструмента для внедрения полученной информации часто используют различные платформы бизнес-аналитики.
“Добыча данных — это навык, который требуется практически везде. Изучите его, и вы будете универсально востребованы.”
Джон Элдер (John Elder), основатель аналитической компании Elder Research
Зарплаты Data mining специалистов
Как вы уже, должно быть, поняли из всего вышесказанного, добыча данных очень и очень востребована на рынке, а следовательно и спрос на специалистов в данной сфере остается стабильно высоким. Поэтому напоследок посмотрим на то, сколько зарабатывают Data mining спецы.
Согласно данным рекрутингового ресурса Indeed, в США средние зарплаты в сфере интеллектуального анализа данных варьируются от около $44 тыс. в год для простых аналитиков данных до около $141 тыс. в год для специалистов в сфере машинного обучения. Ресурс PayScale сообщает, что средняя зарплата спеца по добыче данных в США составляет $60 тыс. в год.
В России, согласно этим данным, Data mining эксперты зарабатывают от 50 тыс. рублей до 180 тыс. рублей в месяц. По Украине и Беларуси актуальную информацию по зарплатам в данной сфере нам найти не удалось, но, после изучения ряда открытых вакансий, можно заключить, что цифры не сильно отличаются от России и составляют, в среднем, от $1 тыс до 2-3 тыс. в месяц.
Телеграм: t.me/ainewsline
Источник: javarush.ru