Бизнес-сценарии с применением ML (машинного обучения) охватывают все направления бизнеса и используют большинство типов данных: табличных, текстов и аудио, изображений и др. Проектов становится все больше, а количество специалистов растет не так быстро. Появляется идея о том, что часть работы этих «дорогих» дата-сайентистов можно автоматизировать. И тут на помощь приходит AutoML.
Под AutoML понимают разное. Мы в SAP считаем, что это автоматизация рутинных операций Data Science. Наверное, не стоит описывать определение подробнее в данной статье, так как довольно неплохо все уже сделал ранее Алексей Натекин тут. Если смотреть видео желания нет, то вот некоторые мысли на тему:

Вот еще примеры, что думают по этому поводу популярные лица из коммьюнити (первый комментарий относится к обсуждению новости того, что AutoML от Google занял 2-ое место).
Для того, чтобы решения и подходы AutoML можно было сравнивать, появился открытый бенчмарк. Коммерческие решения не очень любят таких сравнений по очень простой причине – открытая конфронтация почти невозможна. Кроме точности, слишком разный фокус на типы данных, встраивание и использование. Сделать саму модель – это 15-20% работы (а может и меньше), помимо этого есть огромный пласт прочих работ – от переносов, до публикации сервиса. SAP занимает свою позицию на рынке AutoML. У нас есть несколько разных движков с разным уровнем зрелости.
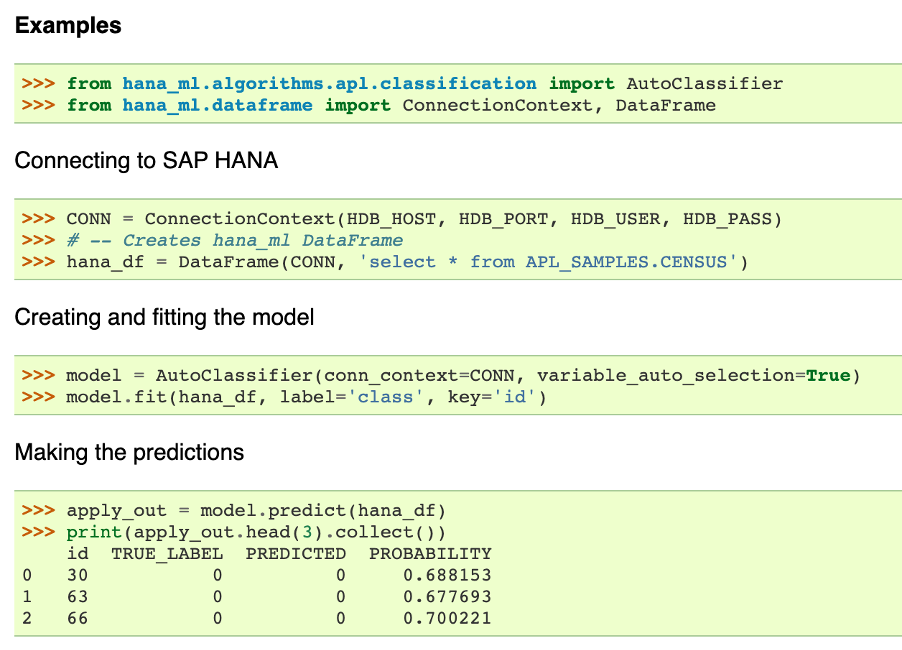
SAP Automated Preditive Library в SAP HANA, который исторически появился после покупки компании KXEN в 2013 году, развивался далее исключительно как инструмент максимально быстрой реализации моделей. Он удобен, когда нет тяжелого (по времени) бюджета на обучение моделей, но важен достаточно качественный результат. По сути – считайте это быстрой версией AutoGBDT.Сейчас есть привычная для большинства обертка на питоне, и выглядит это примерно так (рис.1).
Вторая ветка решения AutoML в SAP Data Intelligence от SAP появилась в декабре 2019 года. Это подход, построенный на базе привычных open source инструментов и дополненный собственными разработками. Здесь настраивается уже возможное время подсчетов, и в рамках кластера подбирается оптимальное сочетание шагов, алгоритмов, и гиперпараметров, где итоговый пайплайн выглядит примеров так (рис. 2).

Это AutoML, который является частью платформы SAP Data Intelligence и может работать как в cloud, так и в on-premise. Также, здесь появляется все, что необходимо для управления датасетами, интеграцией и, пожалуй, самое главное – стандартные механизмы встраивания в SAP S/4HANA c генерацией интерфейсов и сервисов.
Если рассмотреть последующие шаги, то вполне очевидно, что данные, с точки зрения бизнеса, должны насыщаться аннотациями, которые будут релевантными для определенных задач. Это и доменные признаки, и наилучшие формы агрегации при определенных связях бизнес-объектов, и предобученные микро-нейронные сети – фичеэкстракторы.
Если посмотреть на соревнования и статьи в области AutoML, то можно явно выделить следующие направления:
- AutoTable – табличные данные
- AutoCV – изображения и видео
- AutoNLP – тексты
- AutoTS – временные ряды
- AutoGraph – графы
- AutoSpeach – звук
- AutoAD – поиск аномалий
Предполагаю, появятся решения и под AutoRL – для обучения с подкрепления.
На текущий момент SAP фокусируется на работе с табличными данными, временными рядами и аномалиями в части AutoML решений. Причина – проста, построить интеллектуальное предприятие возможно только с огромным количеством моделей в каждой из бизнес-областей.
Ну и, конечно, в каждой компании своя специфика, поэтому, если стандартные модели (типовые) не подходят, необходима их кастомизация. И проще всего это сделать, используя инструменты, не требующие участия DS-специалистов.
В общем, много нового и интересного ждет нас в будущем…
Автор – Дмитрий Буслов, старший архитектор бизнес-решений SAP CIS.