Астрология + машинное обучение на финансовых рынках
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-05-14 10:25

Публикую промежуточные результаты январского исследования с двумя целями: во-первых, создать прецедент, на который впоследствии можно ссылаться (пример применения астрологии), во-вторых, пригласить к сотрудничеству (об этом ниже).
SUMMARY: модель машинного обучения, построенная на астрологических данных, предсказывает волатильность валютной пары GBPUSD с точностью, значительно отличной от случайного угадывания (roc auc = 0.59).
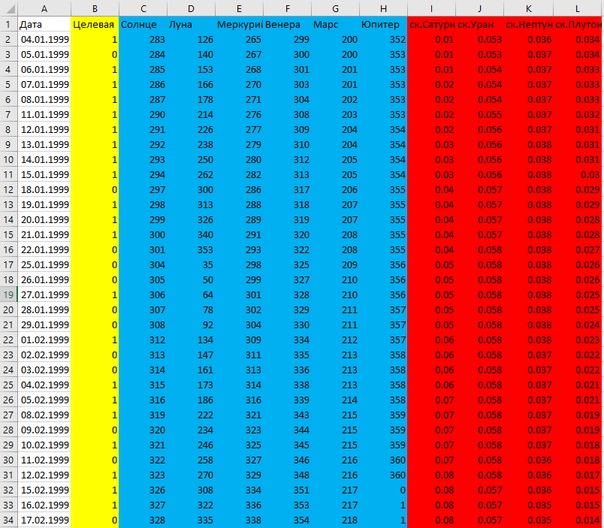
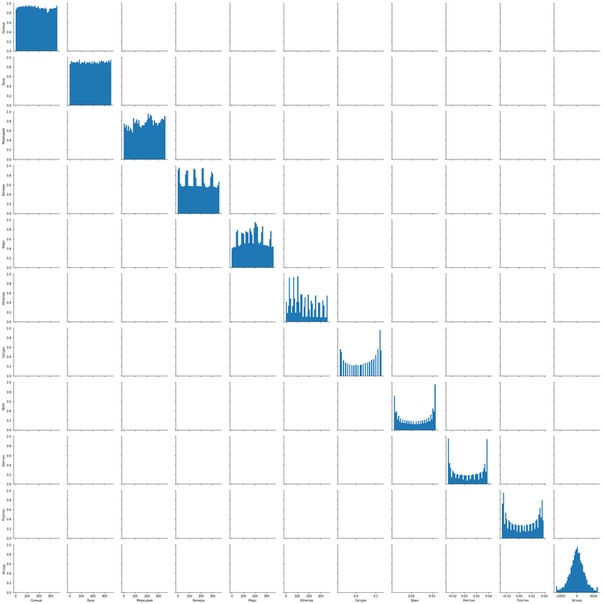
ЦЕЛЕВАЯ. Выборка — дневные данные пары фунт-доллар с 1999 по 2018 годы. Для обучения модели использовано 80% выборки, для тестирования 20%. В качестве меры волатильности взято отношение размаха цен (диапазона) данного дня к цене открытия этого дня по формуле: (High[d]-Low[d])*100/Open[d], т.е. волатильность дня в % цены. Распределение этой функции на рис.1.
ТИП ЗАДАЧИ — бинарная классификация. Порог разбиения классов — 0.6%. Что ниже — класс 0. Что выше — класс 1. Значение взято эмпирически, т.к. 0.6% — примерно та величина бара, с которой имеет смысл заниматься направленной торговлей в этот день ("вменяемая" волатильность). Дисбаланс классов в обучающей выборке получился примерно 1 к 2.3 в пользу класса 1.
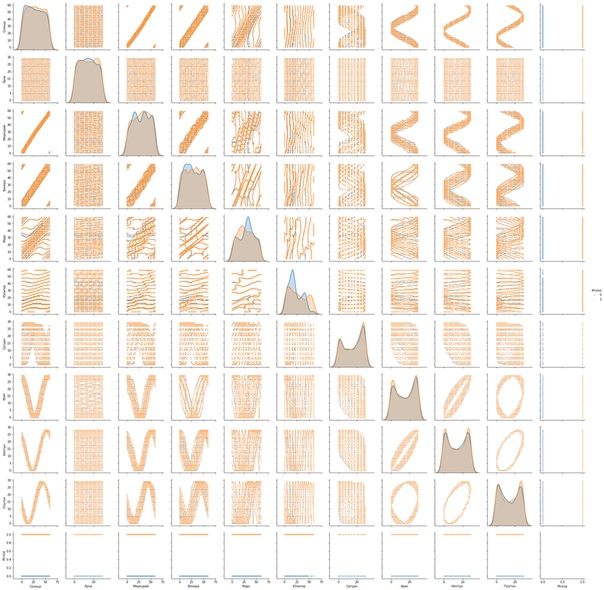
ДАННЫЕ. Использовано текущее положение на небе (градус) первых 6 планет, до Юпитера. Это позволяет отказаться от использования натальных карт (на отношение курсов валюты влияет слишком много факторов) и определять смысл каждой области Зодиака для данной планеты эмпирически, на основе выборки ценовых данных. Сатурн и более медленные не используются, т.к. за 20 лет выборки не совершили даже 1 полного оборота, соответственно данные не репрезентативны. Вместо их положения взяты скорости этих планет в % относительно средней. Датасет выглядит следующим образом (рис.2). Целевая желтой, положения планет синим, скорости красным. Достаточно скромный набор данных. Распределения данных на рис.3.
Были опробованы разные преобразования данных, в т.ч. разбиение на "осмысленные" интервалы, чтобы упростить работу модели и увеличить репрезентативность позиций планет. Также применялся переход к категориальным данным (1hot-кодирование), чтобы модель интерпретировала данные в отрыве от величины интервала (просто по смыслу "попадает/не попадает планета в этот интервал"), что более логично с астрологической точки зрения. Все эти манипуляции дали ухудшение результата: очевидно, следует модели самой предоставить разбиение данных на те интервалы, которые она считает правильными, благо это деревья.
Можно видеть, что прогностическая способность этих признаков очень мощная (рис.4), особенно у положения Марса и Юпитера (символически совершенно логично связаны с волатильностью, т.е. размахом (Юпитер) движения (Марс)). В то же время скорости старших планет почти индифференты к целевой функции.
МОДЕЛЬ. Обучение модели велось методом кросс-валидации на 5 фолдах (частях обучающей выборки), результат проверялся на тестовой. Были опробованы разные варианты моделей на опорных векторах (SVC), деревья, случайные леса, бустинги. Лучший результат дал XGBoost тоже, как ни странно, с очень скромной архитектурой: всего два(!) дерева с глубиной 7.
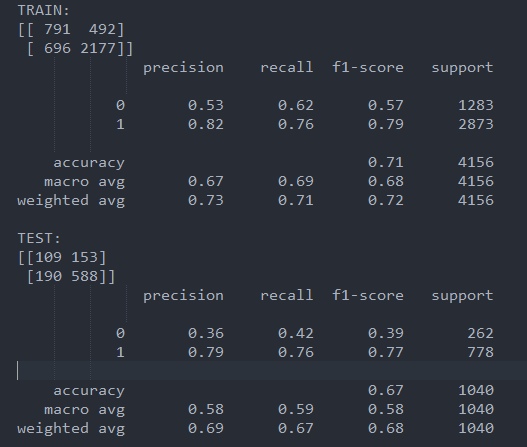
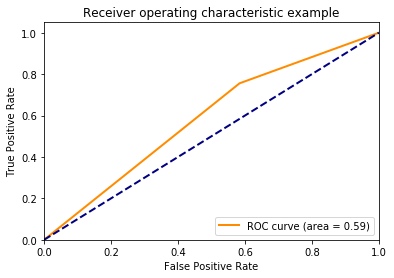
РЕЗУЛЬТАТ. Итоговая матрица ошибок выглядит следующим образом, для обучающей и тестовой выборок соответственно (рис.5). Можно видеть, что асимметрия на тестовой выборке больше, поэтому модель стала реже выбирать (меньший recall) и хуже предсказывать (precision) низковолатильные дни. Но в целом результат по точности (accuracy) снизился незначительно: 0.67 на тесте против 0.71 на обучении. Однако точность не может быть критерием работы модели в задаче с дисбалансом классов, поэтому отличие от случайного угадывания оцениваем по площади под ROC-кривой (рис.6), которая на тестовой выборке равна 0.59. Она значительно превосходит уровень случайного угадывания (0.5), значит, модель эффективна.
ПРИМЕНЕНИЕ. Данную модель можно использовать для торговли волатильностью, например посредством дельта-хеджированных опционных конструкций, которым без разницы, куда пойдет цена, но вы выиграете, если волатильность возрастет, либо если она этого не сделает (в зав-ти от ставки).
ПРОБЛЕМА. Сам я не занимаюсь опционной торговлей, моя сфера — направленная торговля, поэтому это исследование начиналось с попыток определить направление цены. Бинарная классификация "рост-падение" дает некоторый результат, но не может иметь практической ценности, потому что, в силу островершинности распределения ценовых приращений (рис.3, нижний правый угол), большая часть этих ответов будет приходиться на дни, когда был лишь незначительный рост или незначительное падение, недостаточные для торговли.
Классификация из 3 классов, наиболее логичная в данном случае (рост выше порога — падение выше порога — все внутри порога) не дает результатов, отличных от случайных.
ПРЕДЛОЖЕНИЕ О СОТРУДНИЧЕСТВЕ. Соответственно, в данный момент я активно не занимаюсь этой темы, но жалко что она пылится, т.к. результат есть. Если вам это интересно и вы владеете машинным обучением — могу "делегировать" вам это направление исследования, на условиях взаимного обмена результатами. Обучать МО с нуля не буду, но подсказать и ввести в курс дела могу.
Что примерно для этого требуется: базовые знания в теории вероятностей и мат. статистике, умение работать с распределениями, анализировать данные, понимать связи данных, умение преобразовывать данные к нужному виду, умение ставить задачи в МО, формировать и преобразовывать целевую, знание основных моделей МО, как они устроены и каких данных требуют, как их обучать и оценивать. Из инструментов, желательно Python, минимальный набор библиотек: scikit-learn, pandas, numpy, seaborne, matplotlib. Но можно и любую другую среду для создания моделей.
Пруфов на гитхабе не будет, сорри: это еще не коммерческая тайна, но уже рабочая модель, которая может иметь коммерческое применение.
Телеграм: t.me/ainewsline
Источник: vk.com