WaveNetEQ нейросеть улучшает качество аудиозаписи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-04 14:49

WaveNetEQ — это генеративная нейросеть, которая восстанавливает утерянные части аудиозаписи во время звонка. Модель основана на архитектуре WaveRNN от DeepMind. Исследователи выучили WaveNetEQ генерировать продолжение короткой аудиозаписи. Результаты модели сопоставимы с state-of-the-art. При этом модель достаточно быстро работает на инференсе, чтобы обрабатывать данные звонка непосредственно в мобильном устройстве. WaveNetEQ внедрена в приложение Google Duo.
Описание проблемы
Онлайн-звонки являются одной из частей обыденной жизни миллионов людей. Чтобы передать звонок по интернету, данные звонка делятся на короткие части, которые называются пакеты. Пакеты передаются по сети от отправителя к получателю. После того как пакеты дошли до получателя, они обратно собираются в аудиозапись. Однако пакеты часто приходят в неверном порядке или в неверное время. Получается, что итоговая аудиозапись у получателя может содержать искажения или паузы. В Google Duo 20% звонков теряют более 3% от всей аудиозаписи звонка, а 10% — более 8% от аудиозаписи. Исследователи предлагают восстанавливать утерянные части аудиозаписи с помощью нейросети.
Что внутри модели
Функционирующая система по восстановлению аудиозаписи (PLC система) должна одновременно извлекать информацию о контексте аудиозаписи и генерировать продолжение аудиозаписи. WaveNetEQ состоит из двух частей:
- Авторегрессионную нейросеть, которая генерирует продолжение аудиозаписи;
- Условная сеть, которая моделирует долгосрочные признаки, как, например, голос
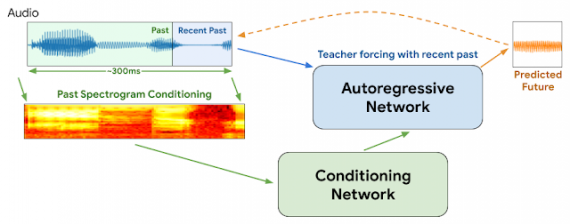
На вход модель получает спектрограмму прошлого аудиосигнала, которая обрабатывается в условной сети. Выход условной сети поступает в авторегрессионную сеть.

Телеграм: t.me/ainewsline
Источник: neurohive.io