Как обучить линейную регрессионную модель в Kotlin с помощью TensorFlow API
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-30 14:13
В своей предыдущей статье я показал, как можно обучить линейную регрессионную модель в Kotlin с помощью TensorFlow API. На этот раз я решил заняться чем-то более сложным, например, сверточными сетями. В этой статье я покажу вам, как вы можете обучить модель LeNet в Котлине.
Вступление:
Архитектура LeNet-5 была опубликована в 1998 году, более 20 лет назад, но она остается краеугольным камнем всех сверточных сетей. Его строительные блоки (слои и функции активации) используются в более сложных архитектурах и по сей день.
Names5«” бђ " очень часто названия нейронных сетей выводятся из числа свернутых и полностью связанных слоев, которые они имеют.
Оригинальная статья содержит архитектурную схему, которая широко известна, и вы, вероятно, видели ее много раз раньше.
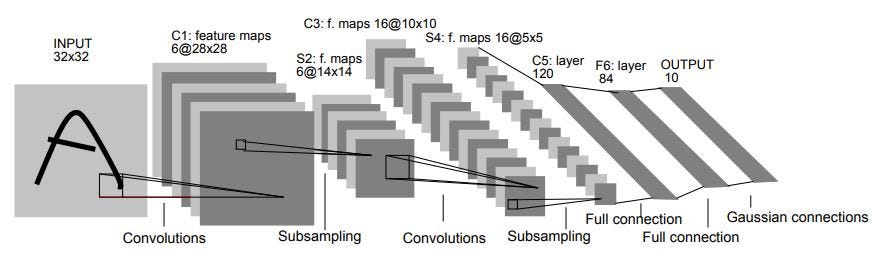
Я предпочитаю современную визуализацию, как показано ниже:
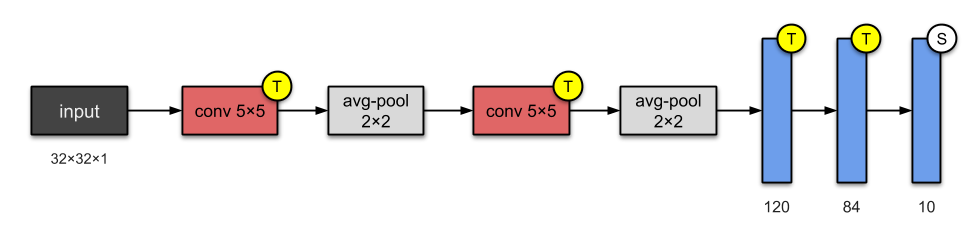
Он имеет 2 сверточных (conv) и 3 полностью Соединенных (плотных) слоя. Он также содержит блоки avg-пула, которые являются суб-выборочными слоями.
Этот паттерн (conv layer + pooling, повторенный несколько раз, плюс несколько плотных слоев в конце) стал обычным паттерном в более сложных сверточных сетях, и мы увидим его в следующих статьях о VGG или AlexNet.
LeNet-5 слоев:
Я буду использовать сеть LeNet-5 для обучения модели на базе набора данных MNIST, который идентифицирует рукописные цифры. Моя архитектура будет немного отличаться от оригинальной архитектуры, чтобы быстрее достичь локального минимума.
В Keras эта модель выглядит очень просто, но API Keras еще не доступен на JVM, и эта модель будет представлена в виде графика тензорного потока.
Время шло, и первоначальная модель была подорвана сомнениями. В последнее время классическая архитектура претерпела косметические изменения, которые я применил в своем примере на Котлине. Позвольте мне перечислить основные из них:
Обновленные слои LeNet-4-zaleslaw:
Прежде всего, давайте определим гиперпараметры и другие полезные константы, загрузим набор данных MNIST и определим заполнители для наших данных:
Что это за числа в тензорной форме изображений?
Входные данные из набора данных MNIST являются изображениями в оттенках серого, следовательно, они находятся в измерении [height, width, num_channels] ([28, 28, 1]).
Первое измерение заполнено -1, что означает неизвестное количество изображений для ввода нашего CNN.
Первый сверточный слой
Типичное объявление уровня conv2d состоит из следующих шагов:
Хорошо, но что делает слой conv2d с входным изображением?
Он просто преобразует входные данные, применяя специальную функцию свертки: берет кусочек входных пикселей и умножает на ядро (специальная матрица с небольшим размером). Веса этого ядра являются параметрами CNN и могут быть найдены с помощью градиентного спуска или других оптимизаторов, таких как Adam или RMSprop.
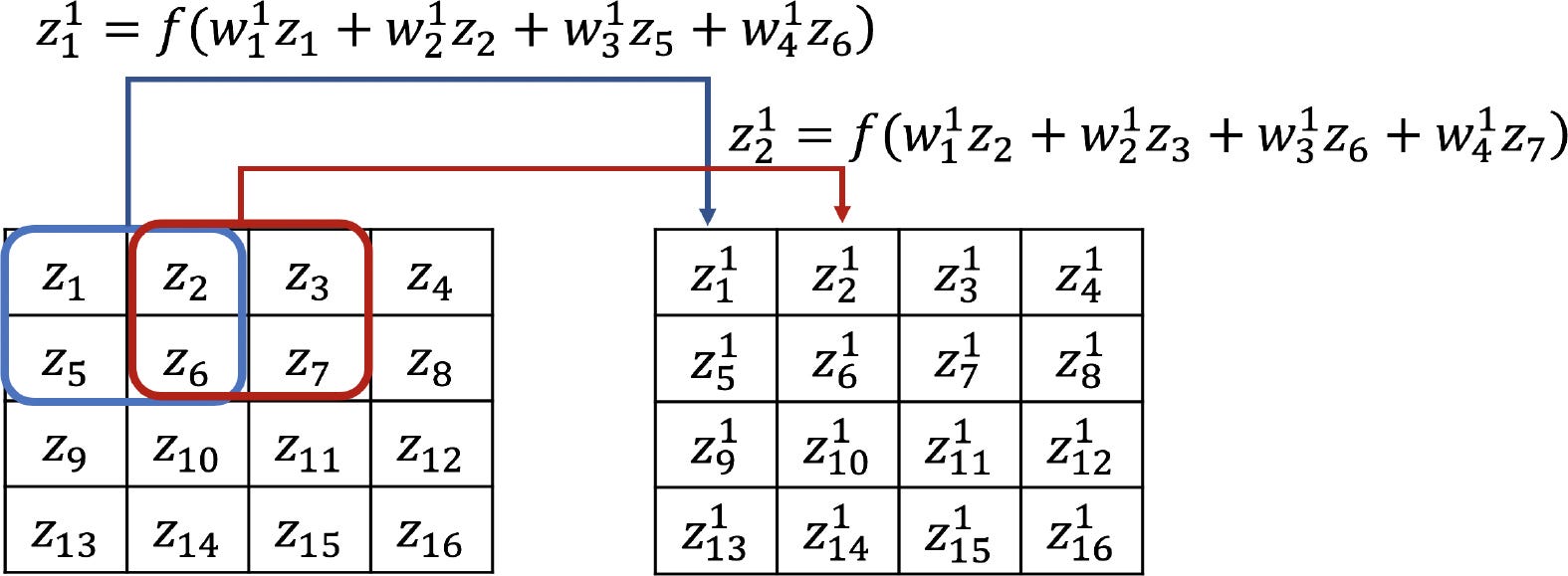
Правильный расчет формы-это самое сложное, когда вы работаете с графом TensorFlow. Я постараюсь дать здесь некоторые рекомендации и общие практики.
Для любого 2D слоя свертки, предполагая, что он получает входные данные X с размером: X БЂ " ” batch_size, input_height, input_width, input_depth].
Тогда веса w этого слоя свертки будут иметь размерность: w БЂ " ” filter_height, filter_width, input_depth, output_depth].
Этот слой свертки выводит y в размерности: y БЂ " ” batch_size, output_height, output_width, output_depth].
Input_depth для этого слоя равен 1 (Количество каналов), output_depth-32 (количество желаемых фильтров для извлечения низкоуровневых паттернов, таких как линии или фрагменты примитивных кривых).
Нужно описать несколько цифр в этом фрагменте кода:
Первый слой объединения
Как только объект был обнаружен, его точное местоположение становится менее важным. Имеет значение только его приблизительное положение относительно других объектов. Например, как только мы узнаем, что входное изображение содержит конечную точку грубо горизонтального сегмента в верхней левой области, угол в верхней правой области и конечную точку грубо вертикального сегмента в нижней части изображения, мы можем сказать, что входное изображение является 7. Простой способ уменьшить точность, с которой положение отдельных объектов кодируется на карте объектов, заключается в уменьшении пространственного разрешения карты объектов. Это может быть достигнуто с помощью так называемых слоев субсэмплирования, которые выполняют локальное усреднение и субсэмплирование, снижая разрешение карты объектов и снижая чувствительность выходных данных к сдвигам и искажениям. [1].
Я предпочитаю MaxPooling оригинальному AvgPooling.
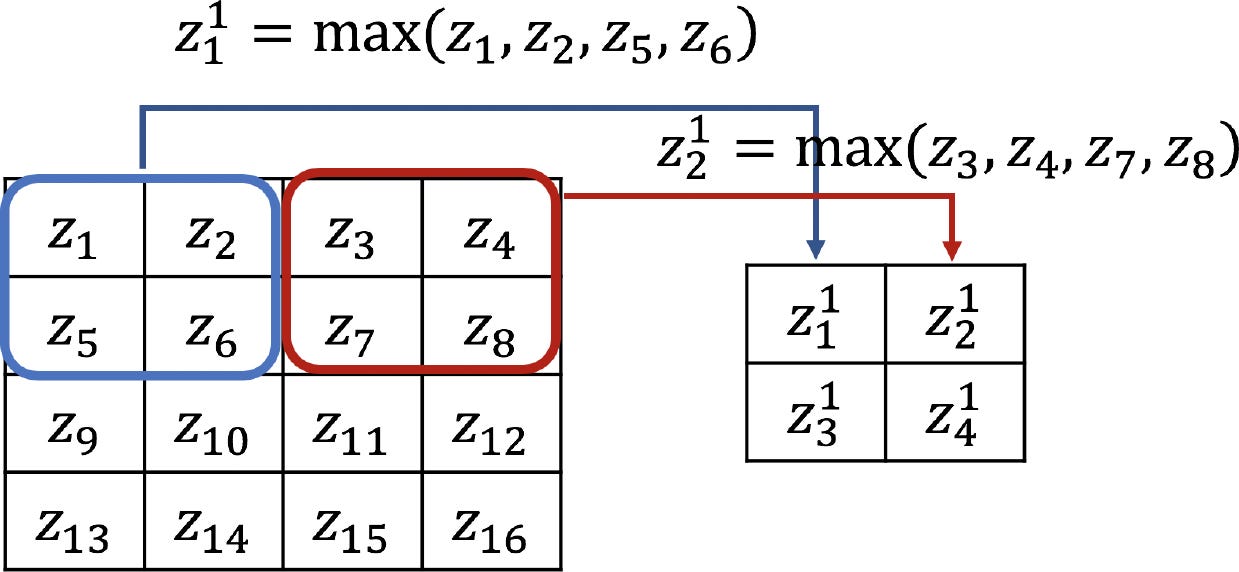
Декларация очень проста:
Два интаррея - это просто упакованные размеры ядра и шага для каждого измерения входного тензора. На самом деле только два средних (ядро[2]; ядро[3]; шаги[2]; шаги[3]) играют значительную роль в обучении TensorFlow CNN. Значения по краям массива обычно остаются заполненными единицами измерения.
Второй сверточный слой и слой объединения
Этот слой является копией предыдущего с измененным количеством входных и выходных фильтров. Input_depth равен 32 из-за 32 фильтров из первого слоя conv2d.
64 - это новое значение для фильтров во втором слое conv2d (при желании его можно увеличить).
Второй слой MaxPooling может быть добавлен таким же образом, как и предыдущий.
Сгладить 2d-вход
Следующий шаг включает в себя сглаживание квадратного входного сигнала до простого вектора с размером 3136 (7 * 7 * 64 БЂ” форма слоя preivous max pooling).
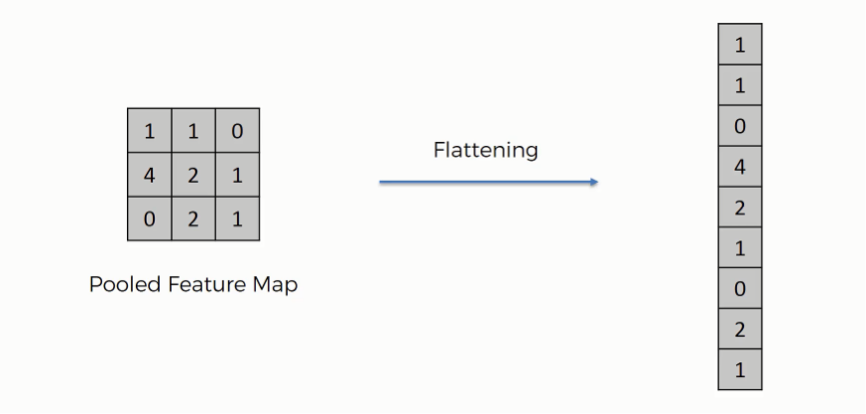
Операция сглаживания-это просто изменение формы вдоль двух осей.
Результатом применения операнда сплющивания является входной сигнал для плотного слоя.
Плотные слои и выходная мощность
Пришло время для старых добрых полностью Соединенных слоев.
На самом деле комбинация плоского операнда и первого плотного слоя не является точно типичным полносвязным слоем (в работе [1] он описывается как свернутый слой с ядром 1x1).
Каждый блок подключен к соседству 5x5 на всех 64 картах объектов (фильтрах).
Плотный слой включает в себя:
Аналогично слою conv2d, я согласен, но он работает с векторами, а не матрицами и не имеет специальной операции для применения к входу, как функция свертки.
Второй плотный слой образует выходы для 10 классов в задаче мультиклассификации:
Функция активации отсутствует из-за специальной метрики, которая будет использоваться позже (она в
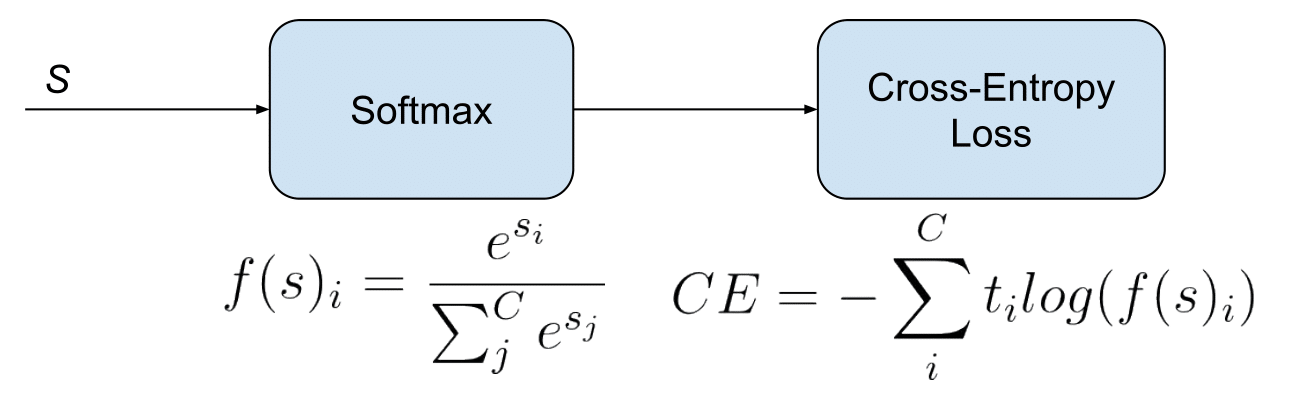
После этого мы можем настроить градиентный спуск вручную:
Когда все переменные готовы к пересчету путем обратного распространения, мы запускаем основной цикл обучения для N эпох с еще одним внутренним циклом по пакетам в течение каждой эпохи.
Оценка: встречайте Королеву точности!
Не так уж много пользы для обучения модели без расчета метрики в тестовом наборе данных.
Пусть form ™ s формирует оценочный тензорный граф потока с Метрикой точности для оценки обученной модели на тестовой части набора данных MNIST.
Здесь мы должны применить функцию активации Softmax к узлу logits, потому что Softmax может дать нам вероятности того, что изображение будет изображением данного класса (для каждого класса).
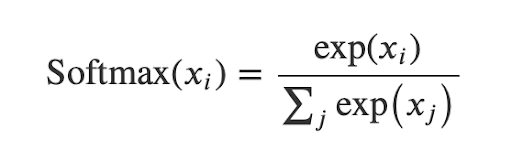
В конце мы запускаем наши тестовые данные через тензоры Model ™ ™ без вычисления градиента, чтобы предсказать по тестовым данным и сравнить с наземными истинами.
Вывод
Рад видеть вас в конце этой статьи. Полный код Kotlin для этого примера доступен здесь [2]. Java-версия этого кода доступна здесь [3].
Сегодня мы рассмотрели классическую модель распознавания рукописного текста. Конечно, чтобы отличить движущихся кошек от стоящих 3D собак, она не подходит в таком виде. Но основные понятия и фрагменты запрограммированного вычислительного графа, представленные в этой статье, вполне могут быть повторно использованы для написания более сложных моделей в Kotlin или Java.
P.S. Я уверен, что без глубокого понимания вычислительного графа TensorFlow и ручного расчета формы, независимо от того, насколько хорошо вы работаете с Keras, будет сложно создать что-то действительно новое и готовое к производству.
Телеграм: t.me/ainewsline
Источник: medium.com