Transformer в задаче рекомендаций
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-30 14:58
Все статьи, о которых пойдет речь, объединяет одно очень приятное свойство — наличие кода на github.
Далее будет много терминов, касающихся модели, предложенной в статье Attention is All You Need (https://arxiv.org/abs/1706.03762). Объяснять их в этом лонгриде на мой взгляд избыточно, поэтому если какой-то термин вам непонятен — имеет смысл почитать статью от Google Brain.
SASRec
Self-Attentive Sequential Recommendation
https://arxiv.org/abs/1808.09781
Архитектура здесь такая:
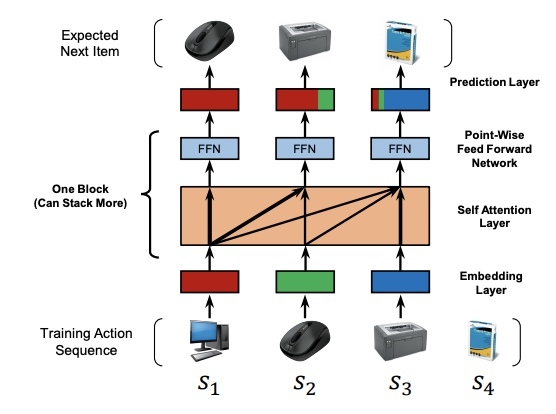
Работает так:
- Берем последовательность потребленных пользователем item'ов, делаем ее нужной длины (паддим если последовательность короткая или обрезаем если длинная), пропускаем через Embedding Layer — получаем эмбеддинги item'ов
- Прибавляем к эмбеддингам item'ов обучаемый эмбеддинг позиции (в отличие от оригинальной статьи от Google Brain, где эмбеддинг позиции фиксирован)
- Пуляем получившуюся последовательность в Self-Attention Layer => Point-Wise Feed-Forward Network (собственно Encoder из Transformer'а из статьи от Google Brain) — на выходе имеем последовательность той же длины, вектора в которой той же размерности, что исходные эмбеддинги. Здесь стоит обратить внимание, что Self-Attention умеет смотреть только на item'ы, которые были в прошлом (в оригинальной статье от Google Brain Self-Attention смотрит и вперед, и назад)
- Опционально стакаем еще сколько-то Encoder'ов из Transformer'а
- Последний вектор из тех, которые мы получили на выходе (справа вверху на картинке, перед Prediction Layer) — это вектор, описывающий состояние пользователя в данный момент. То есть это эмбеддинг пользователя. Мы хотим чтобы скалярное произведение этого эмбеддинга на эмбеддинги item'ов моделировало релевантность
- Оптимизируемый лосс — бинарная кросс-энтропия, в качестве отрицательных примеров будем брать случайный item, с которым пользователь не взаимодействовал (negative sampling)
Думаю, всем очевидно, что нереально гонять такую жирную нейронку в real-time чтобы отдавать рекомендации. Но прелесть этой архитектуры в том, что это и не требуется. Для генерации рекомендаций в проде мы будем использовать сохраненные эмбеддинги пользователей и item'ов и нам нужно будет лишь найти item'ы, наиболее близкие к эмбеддингу пользователя по dot-product. Эмбеддингом пользователя здесь будет являться опять-таки последний вектор с выхода модели для этого пользователя.
Следующие две работы рассматривают SASRec как бейзлайн.
Bert4Rec
https://arxiv.org/abs/1904.06690
Архитектура модели очень похожа на предыдущую:
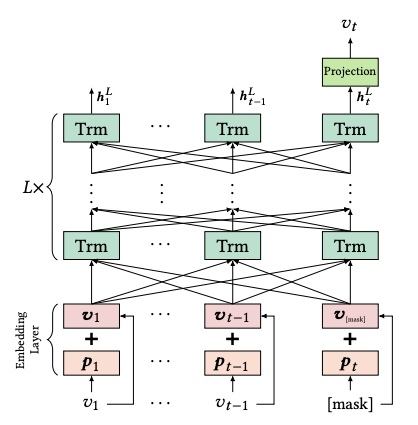
Здесь v_i — эмбеддинг item'а, p_i — обучаемый эмбеддинг позиции (как и в SASRec).
Отличия от SASRec:
- Self-Attention здесь смотрит как в прошлое, так и в будущее (в SASRec смотрел только в прошлое)
- На выходе из слоев Self-Attention Layer => Point-Wise Feed-Forward Network (на этой схеме называются Trm — Transformer) мы получаем вектора h_i не обязательно той же размерности, что исходные эмбеддинги
- Последний из выходных векторов h_t мы прогоняем через полносвязный слой с нелинейностью, что дает нам вектор размерности исходных эмбеддингов:
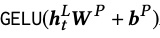
- Получившийся вектор мы будем умножать на матрицу эмбеддингов item'ов E (к результату прибавим bias'ы item'ов) и все это будем передавать в здоровенный softmax (к-во выходов = к-ву доступных item'ов в системе):
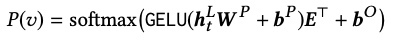
- Оптимизировать будем кросс-энтропию, но уже не бинарную, а многоклассовую
Несмотря на то, что предсказания генерируются более сложно, мы все еще можем свести это к задаче поиска ближайших (в терминах dot-product) item'ов пользователю. В качестве эмбеддингов пользователей мы будем использовать это:
В качестве эмбеддингов item'ов — собственно эмбеддинги item'ов. Если сделать в точности так — мы проигнорируем b_o (bias'ы item'ов). В каких-то случаях это может нас устроить (например если мы хотим чуть меньше рекомендовать популярные item'ы). Если же мы хотим делать инференс в точности как в обучении — нужно увеличить размерности эмбеддингов на 1, докинуть в эмбеддинг пользователя единичку, а в эмбеддинг item'а bias этого item'а. Тогда к скалярному произведению прибавится в точности bias нужного item'а.
SSE-PT
Sequential Recommendation Via Personalized Transformer
https://openreview.net/forum?id=HkeuD34KPH
Архитектура модели:
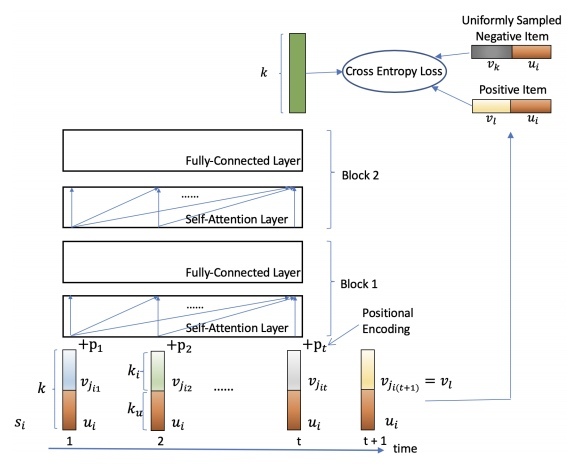
Отличия от SASRec:
- Ни в SASRec, ни в Bert4Rec не используются эмбеддинги пользователей — эмбеддингом пользователя там мы считаем выход Transformer'а, который порождает последовательность потребленных этим пользователем item'ов. Авторы SASRec утверждают, что эмбеддинги пользователей переобучаются и не дают профита. В этой работе авторам удалось извлечь профит из использования эмбеддингов пользователей. Это получилось за счет использования техники регуляризации эмбеддингов, описанной здесь https://www.researchgate.net/publication/333419022_Stochastic_Shared_Embeddings_Data-driven_Regularization_of_Embedding_Layers. Основная идея в том, что на этапе обучения с какой-то вероятностью эмбеддинг подменяется другим
- В этой архитектуре на вход Transformer'у подается последовательность конкатенированных векторов итемов (v_j_i_n) c вектором пользователя (u_i)
- На выходе мы получаем вектор той же размерности. Для того, чтобы посчитать релевантность item'а пользователю нужно конкатенировать вектор item'а с вектором пользователя и скалярно умножить на выходной вектор
- Оптимизируемый лосс такой же, как в SASRec
- Предложена модификация архитектуры SSE-PT++, которая умеет работать с очень длинными последовательностями, «умно» сэмплируя их
Главная проблема этой архитектуры в том, что мы не можем использовать knn-индексы для генерации рекомендаций в production. В двух предыдущих работах мы сохраняли эмбеддинги пользователей (на самом деле выходы Transformer'а), эмбеддинги item'ов, и все, что нам оставалось сделать для определения релевантности — их перемножить. Именно поэтому мы могли использовать knn-индексы, которые умеют очень быстро по вектору пользователя найти top-k item'ов, вектора которых дают максимальное скалярное произведение с этим пользователем (реализация одного из таких индексов: https://github.com/nmslib/nmslib). Здесь же перед скалярным произведением нам нужно что-то конкатенировать — и это все ломает.
Но в целом скалярное произведение — быстрая операция и если item'ов в системе не так много или если ограничения на время ответа не такие жесткие, архитектура вполне годна к использованию в production. Делать inference Transformer'а на каждый запрос рекомендаций здесь не нужно.
Телеграм: t.me/ainewsline
Источник: m.vk.com