Stepik "Введение в Data Science и машинное обучение", часть 2
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-30 11:00
Stepik 1.4. Pandas, Dataframes
— В этом уроке мы начнем знакомиться с библиотеками анализа данных: Pandas и Numpy
— Для работы с кодом мы будем использовать Jupyter Notebook
— Как установить Jupyter Notebook
— Запускаем на Windows, Mac , Ubuntu
Что такое Jupyter?
Jupyter - это отличный инструмент для data-scientist, поскольку он позволяет в одном документе сочетать текстовое описание, таблицы, ссылки, программный код, графические результаты. То есть работа над проектом, будет максимально продуктивной, поскольку что называется не "отходя от кассы" можно проверить гипотезу и получить результат. Для использования в качестве IDE он конечно не подходит, но как инструмент в сфере анализа данных и машинного обучения - он очень хорош.
Весь код на протяжении курса будет написан в нём.
Код можно запускать сочетанием клавиш Shift + Enter или нажатием кнопки Run.
Данные, которые мы будем использовать в этом и следующих уроках представлены здесь.
Pandas. Работа с двумерными данными
Импорт библиотеки
Прежде, чем начать работу с библиотекой - мы должны её импортировать:

Сокращения pd и np стали стандартами при работе с данными библиотеками. Чтобы легче было привыкать читать чужой код, использующему эти библиотеки, советуют привыкнуть импортировать библиотеки с использованием такой конструкции.
С чем работает pandas?
Pandas работает с объектом dataframe, который хранит в себе таблицу с данными. Но помимо данных, этот объект имеет специальные методы, позволяющие работать с этими данными, получать информацию по этим данным.
Мы можем получить информацию о размере таблицы, о типах данных внутри нее, получить доступ к определенным строкам, агрегировать и фильтровать информацию в ней и т.д.
DataFrame - не просто таблица с данными. Это и данные, и целый комплекс действий, и информации, связанных с этими данными.
Создание dataframe из файла
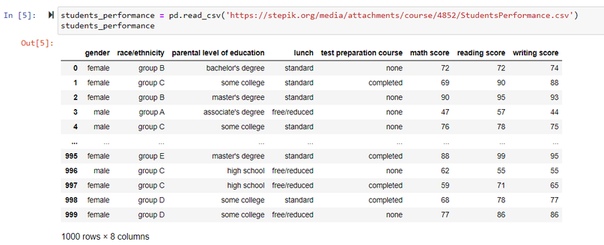
Давайте создадим объект dataframe для дальнейшей работы с библиотекой из csv файла. Для этого используем метод read_csv().
Открывать мы будем пример csv документа - StudentsPerformance.csv, скачанный в ту же папку, что и наш notebook.
Для просмотра содержимого dataframe нужно просто выполнить инструкцию ниже, и мы увидим таблицу из 1000 строк и 8 столбцов.

Но гораздо полезнее создать переменную, связанную с данным dataframe, чтобы в дальнейшем работать с ней и получать необходимую информацию.

Также можно не скачивать файл, а указать ссылку из курса.
Какие операции с dataframe доступны?
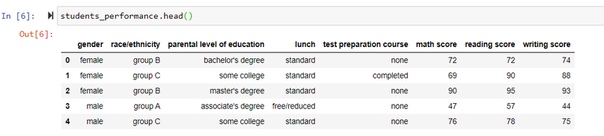
Вывод первых строк
Выведем первые 5 строк:
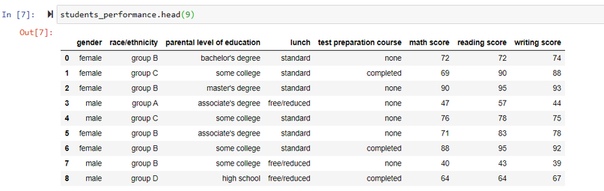
Выведем первые N строк
Для вывода первых N строк нужно выполнить - students_performance.head(N), где N - любое число:
Вывод последних строк
Выведем последние 5 строк:
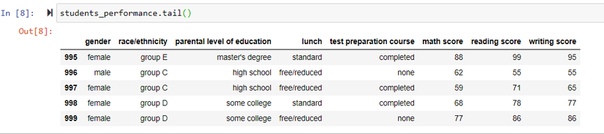
Выведем последние N строк.
Для этого по аналогии с получением N первых строк - N передается как аргумент метода tail: students_performance.tail(N):

Автор: Зульфара Шаймухаметова
Главный редактор: Диляра Ахметзакирова
Телеграм: t.me/ainewsline
Источник: m.vk.com