Разбор задач отбора: ML
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-29 15:28
Алексей Тихонов
Описание задачи
В конкурсе необходимо было предсказать долю из потенциальной аудитории, которая просмотрит рекламные объявления, показываемые на нескольких рекламных площадках, конкретное число: 1, 2, 3 раза, ещё и в будущем. Это было не классическое соревнование по отправке итоговых предсказаний на известные тестовые данные, а предсказание на полностью неизвестных данных, подаваемых на работающую модель в докер-образе, запущенном на площадке конкурса. Данное решение в целом уравнивает шансы участников, так как не позволяет тем, кто любит подглядывать в тест, обогащать им тренировочный набор данных и подгонять модель под распределение тестовых данных. Здесь все в равных условиях, так как непонятно, что может быть в данных: и мусор, и спорадические выбросы или неверные разделители, но все эти нюансы одновременно заставляют думать и об обработке исключений.
Постановка задачи и обзор данных
Исходные данные были представлены в следующем виде:
- Файл
users.tsvсодержит информацию о пользователях: пол, возраст, город проживания. Этим пользователям, соответственно, и показывались объявления, как в текущей истории, так и в будущем, это было гарантировано организаторами в описании задачи. Просмотрев этот файл, учитывая большое число пропусков и неоднозначные результаты на валидации (при добавлении этих данных), в итоге я полностью отказался от их использования. - Файл
history.tsvсодержит комбинации пользователь-площадка, просмотр объявления за указанную цену в конкретный час (сквозной нумерацией) по историческим данным. То есть данный файл представлял собой некую статистику просмотров в прошлом, а как уже было сказано выше, оценивать новые данные мы должны были на следующем интервале времени. - Файл
validate.tsv— валидационный файл для тренировки модели, в нём как раз были данные о том, в какой интервал времени и по какой цене было показано объявление для конкретной аудитории (площадка и пользователь). Пользователи и площадки приводились в строковой форме вида (1,5,7,3,14,6). - Файл
validate_answers.tsv— файл ответов, состоящий из трёх колонок: какая доля (значения от 0 до 1) аудитории посмотрит объявление 1 раз, 2 раза, 3 раза. Соответственно, последовательности эти не возрастающие.
Цель конкурса: на новые данные из будущего в формате файла validate.tsv предсказать три набора значений — какая доля аудитории посмотрит объявление 1, 2 и 3 раза.
Предикторы
Итоговые предикторы представляют собой набор из двух комплексов:
- предикторы на основе истории и их сопоставлении с новыми данными,
- предикторы только на данных из будущего.
Среди первого комплекса, на основе файла истории, по сгруппированным парам «пользователь-площадка» были сгенерированы базовые статистики, и в дальнейшем их агрегация на пару «пользователь-площадка» в валидационном и тестовом файле. Далее следовал отбор предикторов разными способами — как исходя из частот использования предикторов на этапах разбиения и использования в самой модели, так и на валидациях, сверху вниз и снизу вверх. Несмотря на разные схемы отбора, в целом всё сводилось примерно к одному набору предикторов, и в итоге их оказалось 7. Среди предикторов на основе новых данных (их тоже на удивление оказалось 7) трактовка в целом гораздо проще:
- Delta — разность времени. Логично? Логично: чем больше интервал, тем, вероятнее, больше просмотров. Конечно, прямой зависимости нет, но физически должно быть именно так. Более того, это один из самых сильных предикторов, если рассматривать их по отдельности.
- Delta2 — тоже разность времени, но переведённая в сутки (целочисленным делением на 24). То есть линейную зависимость мы превращаем в кусочную. Идея здесь простая: мы не делаем различий между часами, но вот очень длительные интервалы (сутки) будут задавать свой тренд.
- CPM — непосредственно цена. Аналогично: чем дороже цена, тем более вероятен просмотр, опять же прямой зависимости, конечно, нет, но в «заигрывании» с другими предикторами на основе истории она явно прослеживается.
4—7. Это синусы и косинусы времён начала и конца показа объявлений, также переведённых в 24-часовую шкалу. Использование данных функций, в отличие от линейного времени, позволяет учесть интервалы времени, переходящие через сутки. Применение этих предикторов сразу дало улучшение на 1 пп.
Отклик и метрика
Представленная метрика конкурса:
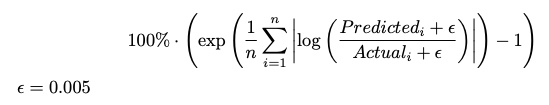
, где отклик представлен в единицах долей просмотренных объявлений, то есть в диапазоне [0, 1].
Если внимательно посмотреть на формулу метрики, то, с одной стороны, данная метрика примерно соответствует среднегеометрическому отклонению предсказаний от истинного значения, что явно лучше, чем среднеарифметическая метрика (по причине более низкого итогового результата). С другой стороны, если опустить экспоненту, которая на малых значениях ведёт себя, почти как сам показатель её степени, метрика трансформируется в MAE на логарифм отклика со смещением. Таким образом, для построения идеологически верных моделей необходимо использовать исходный отклик со смещением на функцию потерь, в которой в явном виде есть логарифмирование или же, наоборот, предварительно использовать логарифмирование отклика со смещением и линейную функцию потерь (MAE, eps, Huber). Но, учитывая мою модель (в которой в явном виде не задаётся функция потерь), оптимальную трансформацию отклика я выбирал, исходя из результатов модели на валидациях. Мной были рассмотрены следующие варианты отклика: оригинальные доли, логарифмирование долей, переход к абсолютным значениям количества пользователей, их логарифмирование с различными смещениями (здесь была попытка использовать одно унифицированное смещение при переходе к абсолютным значениям, так как смещение 0.005 указано для долей, а аудитория была разной — от 300 до 2500, поэтому смещение должно было быть в границах от 1 до 12, но я проверял только крайние значения) и корень из абсолютного значения просматриваемых людей.
В итоге победителем с явным отрывом оказался отклик — корень из абсолютных значений пользователей. При этом на разных предсказаниях (на 1 просмотр, на 2, на 3) иногда побеждали и модели с логарифмированием абсолютных значений — это связано с явным преобладанием 0 в откликах, и, как следствие, логарифмирование с каким-то смещением подходило лучше. Но если оценивать в среднем, то простой корень без всяких смещений показывал хорошие стабильные результаты, поэтому хотелось не усложнять решение, а остановиться на простом унифицированном способе — взяв просто корень из людей. Чем я могу объяснить, почему переход к людям значительно улучшает результат относительно долей (более чем в 2 раза)? Видимо, дело в том, что, переходя к людям, домножая долю на аудиторию, или, что то же самое, деля все предикторы на эту же аудиторию, мы переходим в размерность относительно одного человека, а учитывая, что в основе моей модели — регрессии, итоговый результат есть некая взвешенная оценка вероятности относительно каждого предиктора. Вполне возможно, что если нормировать на аудиторию было необходимо только часть предикторов, например, из предикторов первой группы, где была сумма по всем парам, то эта нормировка тем самым приближала бы размерности всех предикторов к единой системе отсчёта (на одну персону), и итоговая регрессия, её отклик, были бы не чем иным, как средневзвешенной суммой вкладов каждого предиктора (которые характеризуют одного человека) на итоговую вероятность просмотра — тогда, возможно, и результат был бы сильно лучше. Но на момент решения конкурса с этой стороны я не подходил и работал исключительно с трансформированным откликом.
Модель
На самом деле данный раздел необходимо было ставить выше, так как именно из типа модели приходилось подбирать вид отклика и необходимые используемые предикторы. Именно модель подстраивалась под данные и, так или иначе, даже на разных предикторах можно было выйти на приемлемый результат. Но мне хотелось, чтобы именно в среднем было какое-то обоснование выбора конкретных предикторов, поэтому именно многократно на валидациях и отбирались комбинации предикторов.
Я использовал модель из семейства деревьев регрессионных моделей, а именно — модель cubist (модель 1992 года) и её реализацию в одноимённом пакете. Вернее, итоговый результат — это среднегеометрическое двух наборов моделей, каждый из которых состоял из трёх отдельных моделей, но каскадом: предсказание предыдущей модели (на 1 просмотр) использовалось как предиктор для второй и третьей модели, а итоговое предсказание на второй просмотр — как предиктор на третью модель.
Тем самым дополнительно опосредованно модель «понимала» (из-за регрессий), что каждый следующий отклик цепляется за ранее предсказанный ответ предыдущего отклика, а остальными предикторами ответ корректируется, причём он должен быть не больше предыдущего. Конечно, это не гарантированно, но является дополнительной страховкой.
И, разумеется, я проверил и три модели, предсказывающие отклики по отдельности. Результат был слабее. Опять же из-за обилия нулей при вторых и третьих просмотрах семейство регрессий не могло достаточно точно уходить в 0, а когда мы добавляем поводыря предыдущей оценки, которая уже 0 или близка к нему, получаемое семейство регрессий также падает в окрестность данного значения и корректирует лишь отклик на второй и третий просмотр.
Чем же хороша данная модель? Сразу увидев данные, я про неё вспомнил, так как на одном из предыдущих конкурсов в сопоставимой задаче (линейные связи и их корректировки) она оказалась также одной из лучших. Да и в целом, так как у нас здесь достаточно линейные данные, есть явная зависимость между количествами просмотров (второй меньше первого, третий меньше второго), данных не много — всего 1000 строк, есть небольшое число предикторов, а данная модель очень быстра, построение занимало несколько секунд, поэтому на ней удобно было тестировать многие гипотезы, а ещё у неё практически нет гиперпараметров, на которых можно было бы переобучиться.
Как же получается предсказание в данной модели по одному дереву? В отличие от классических деревьев регрессии, где в узле остается одно финальное предсказание, здесь используется начальный набор из 100 правил (которые в итоге значительно сокращаются: в среднем на одно дерево оставалось порядка 10-20 правил), в терминальном узле используется линейная регрессия на подмножестве предикторов, а итоговый прогноз есть взвешенная комбинация прогнозов, находящихся на одном пути по дереву. Но и это ещё не все: также используются комитеты (аналог итераций в бустинге), то есть строятся следующие деревья, которые корректируют ответ предыдущей модели (заниженную увеличивают, завышенную уменьшают), и итоговый ответ есть среднее по всем комитетам. Более подробно о данной модели, критериях расщепления и сглаживании предсказаний рассказано в презентации авторов пакета: https://www.dropbox.com/s/2vf3swfbk48lfdc/RulesRulesRules.pdf?dl=0 и в публикациях авторов на сайте: https://www.rulequest.com/cubist-pubs.html.
Заключение
Несмотря на то, что занявшие первые 5 мест в данном конкурсе использовали различные модели, в том числе и современные (1-е место — SVR, 2-е место — catboost, 3-е место — neural net, 5-е место — lightgbm, хотя у всех призеров были гораздо более сложные предикторы), мне удалось занять 4-е место, используя одну из старейших классических моделей 1992 года (даже идеи SVR появились позже) на достаточно простых и очевидных предикторах, что ещё раз подтверждает: не всегда достаточно просто бустить на сгенерированных предикторах (эти подходы были сильно ниже в итоговом рейтинге), здесь играет значительную роль и здравый смысл предикторов, и трансформация отклика, и лосс функция потерь в моделях, в которых её можно было настраивать. В целом конкурс получился очень интересным и творческим с соответствующими выводами.
Иван Брагин
Второй этап, Docker, даны несколько файлов — сложно… В первые дни конкурса были мнения, что в топ-40 попадёт baseline-решение, но не тут-то было.
Задача, которую нам предложили: есть рекламодатель, который установил цену, интервал времени показа объявления, платформы, где его показывать, выбрал список пользователей и теперь хочет понять, какой процент среди выбранных людей увидит его объявление хотя бы N раз (N = 1, 2, 3). Легко догадаться, что чем выше цена рекламы и чем дольше она висит, тем больше пользователей её посмотрят. Сложнее выделить признаки из списка пользователей и платформ.
С учётом того, что предложенная метрика дифференцируема, я решил учить нейронку с лоссом == метрика:
https://github.com/BraginIvan/vkcup2019/blob/master/stage2.ipynb. Хотя в последний день я попробовал обучить бустинг с метрикой bce (потому что логарифм) и получил результат не хуже нейронки:https://github.com/BraginIvan/vkcup2019/blob/master/stage2_boosting.ipynb. Если брать mse/mae в чистом виде, то результат получался значительно хуже. Но можно сначала прологарифмировать target, а потом оптимизировать mse (до этого я сам не догадался).
Итак, две фичи у нас есть: цена и длительность показа. Достаточно добавить всего одну фичу, чтобы попасть в топ-20. По каждому пользователю у нас есть история рекламных объявлений, которые он смотрел. Чем больше реклам он видел, тем выше вероятность, что он посмотрит и очередную рекламу. Но если, например, пользователь никогда не смотрел рекламу на платформе 11, а рекламодатель выставляет объявление именно на этой платформе, то вероятность просмотра близка к нулю. Думаю, тут можно посчитать вероятности просмотра объявления независимо для каждого пользователя, смапить список пользователей на список вероятностей и посчитать моду. Но мы же ML-инженеры, зачем нам теорвер, если есть lgbm?
Вместо аналитического решения я решил посчитать для каждой пары пользователь+платформа количество просмотренных объявлений. То есть (user1, publisher8) -> 10, (user7, publisher1) -> 4… Далее пробегаем по всем новым объявлениям и считаем сумму от мапинга пермутаций (users, publishers) объявления по полученному словарю. То есть, если объявление будет показано пользователям 10, 12, 88 на платформах 1, 3, то находим в полученном по history словаре значения по (10,1),(10,3),(12,3),(12,3),(88,3),(88,3) и берём сумму. Добавив эту фичу (activity) к двум имеющимся, получаем скор < 20.
Все дальнейшие улучшения основываются на activity. А давайте считать словарь пользователь+платформа не по всей history, а только по дешёвым объявлениям; а давайте брать не сумму от всех значений на i-й квантиль и т. д. Далее немного делений и умножений фич друг на друга и настройка гиперпараметров. Самая лучшая фича получилась activity * hours_diff * cpm / audience_size — на графике от target она линейно возрастающая с небольшими выбросами. Только по этой фиче без ML можно получить ~34.
Не меньше времени ушло на запуск кода на сервере. Собрать и запушить труда не составляло, но решение постоянно падало. Оказалось, у меня было две больших проблемы.
- Убрав весь код, кроме загрузки tensorflow-модели, я снова получил ошибку и понял, что моё решение не помещалось в память. Пришлось переписать inference на tflite.
- В данных на тестовой части были особенности, которые приводили к делению на 0 или подобным проблемам. Для отладки я сильно испортил
validate.csvи заставил код работать на испорченной версии данных.
Далее сабмиты проходили без проблем. Сравнивая с другими платформами, можно сказать, что mlbootcamp хорошо подготовили inference в docker, особенно для первого раза.
Я занял 3-е место. Я видел в чате, что участник, занявший первое место, использовал данные о времени начала и окончания объявления (hour % 24) вместе с городами пользователей.
Илья Корнаков
Задача отборочного раунда ML-трека оказалась довольно необычной: во-первых, требовалось предсказать величину, во многом определяемую внутренними алгоритмами VK, во-вторых, для тренировки было дано два разных типа входных данных, в-третьих, требовалось отправлять код для предсказаний в виде Docker-контейнера, а не сами предсказания. Эти особенности сделали задачу интересной — было бы круто видеть больше ML-соревнований, экспериментирующих с нестандартными элементами. Это отразилось и на результатах: топ-3 участников использовали очень разные подходы. В этом write-up'е я опишу свой подход (и ошибки, которые я совершил).
Data Exploration
Первое, что имеет смысл сделать, — это посмотреть на данные в вашем любимом environment'e для анализа данных (Jupyter/Colab/…). У нас есть два dataset'а — history.tsv и validate.tsv. Мы видим, что history.tsv гораздо больше, но validate.tsv (всего 1000 примеров) гораздо лучше подходит для тренировки (данные ровно в том формате, который нужен для предсказаний).
Мы также видим, что у нас несколько сущностей: publishers (21 штука), cities (2457 штук), users (25536 штук, у каждого есть пол, возраст и city).
В validate.tsv мы видим распределения audience_size (в диапазоне ~300-2500) и cpm. Объединив его с validate_answers.tsv, мы также видим распределения ответов; всё это даёт нам представление о данных, с которыми мы работаем.
На этом этапе также имеет смысл сравнить временные интервалы history.tsv и validate.tsv — и увидеть, что интервал для validate.tsv находится внутри интервала для history.tsv. Я этого не сделал (предполагая, что он идёт после history), и это была самая большая моя ошибка (перекрывающиеся интервалы означают, что нельзя просто так тренировать модели на validate на фичах, насчитанных на history).
Первые модели
Что вообще можно сделать с нашими данными? Первое, что приходит в голову, — просто забить на history и натренировать модель на данных, полученных из validate.tsv (audience_size, duration = hour_end - hour_start, one-hot фичи для publisher'ов, cpm). Для моделей на таких табличных данных лучше всего подходят boosted decision trees, например XGBoost или CatBoost. Я остановился на последнем. Прежде чем тренировать модель, нужно понять, что у нас за метрика. Несложно заметить, что метрика в задаче превращается в Mean Average Error после преобразования labels := log(labels + eps). Однако для простоты мы будем оптимизировать Mean Squared Error с преобразованными labels. Удобство workflow «простые фичи + Catboost» ещё и в том, что посчитать модель в Docker-контейнере можно очень просто (фичи считаются тривиально, модели с деревьями очень быстрые). Это довольно полезно в нашей задаче, где модели запускаются на сервере.
Простейшая модель на таких фичах уже даёт финальный score 24.7, что все ещё не хватает для прохода дальше, но уже близко. Но мы всё ещё не использовали пользователей и историю — как бы получить разумные фичи из них?
Тут помогает здравый смысл. Как понять, что CPM объявления достаточно высокий для пользователя? Можно просто посчитать средний CPM показанного объявления для пользователя по истории. Как понять, что данный publisher подходит для пользователя? То же самое: считаем, сколько раз пользователь видел объявление с этим publisher'ом. Как понять, что время подходит для пользователя? Считаем статистику по hour % 24 по истории. Несколько таких простых фич — и мы получаем финальный score ~14.2, что достаточно для попадания в топ-5.
Fine-tuning
Дальше начинается самая затратная часть процесса — выжимание небольших улучшений метрики ценой больших усилий. Тут две отдельные части — подбор фич и улучшение модели. С точки зрения подбора фич, единственная стратегия — пробовать то, что кажется разумным, и запускать эксперименты.
В итоге я остановился на следующем:
- по каждому городу считаем статистику показов по временам суток (
hour % 24); - по каждому пользователю считаем кучу статистик:
• суммарное количество показов;
• суммарное количество показов по каждому publisher'у;
• средний CPM;
• показы по временам суток (hour % 24);
• минимальное время между последовательными показами рекламы (непонятно, насколько эта фича помогла).
Пусть у нас есть объявление с каким-то CPM, временным интервалом, publisher'ами и пользователями. Какие фичи у нас будут для этого объявления?
- Простые агрегации: средний возраст, самый часто встречающийся пол, средние по суммарному количеству показов и среднему CPM, среднее по количеству показов и среднему CPM, средняя сумма показов по publishers объявления.
- Статистики по времени: для каждого пользователя/города, считаем долю показов в данное временя суток. Суммируем по
hour % 24для всехhourмеждуhour_startиhour_end. - Фичи уровня объявления:
duration,cpm, категорийные фичи для publisher'ов.
На уровне моделей всё ещё интереснее. Тюнинг гиперпараметров Catboost'а особых улучшений не дал (более того, попытка оптимизировать MAE (ровно то, что нужно в задаче) вместо MSE сделала только хуже), зато обернуть его в bagging очень помогло. А именно — тренируем 20 Catboost-моделей на 90%-подмножествах данных, в качестве предсказания берём среднее. Этот трюк позволил улучшить score с ~13.2 до ~12.7.
Почему же bagging так сильно помогает? Обычно он используется для масштабирования (индивидуальные bags тренируются независимо), и на одной машине тюнинг learning rate позволяет достичь тех же результатов с точки зрения качества. Здесь это оказалось не так, и это интересный вопрос почему. Возможно, дело в нестандартном overfitting'е в моей модели (см. ниже).
Обсуждение
Одна из самых очевидных идей в этой задаче — использовать взаимодействия между разными объявлениями (например, если у нас в input'е есть объявление и 20 других объявлений на того же пользователя с тем же временным периодом и более высоким CPM, то вряд ли нас покажут). По непонятным причинам фичи на основе этой идеи вообще не помогали, возможно, это связано с тем, как генерировались данные.
Другой интересный момент — перекрывающиеся временные интервалы history.tsv и validate.tsv. Это означает, что модель, тренирующаяся на validate.tsv и использующая history.tsv, оверфитится неприятным образом (статистические фичи более точны на validate.tsv, чем на реальных тестовых данных, поэтому модель доверяет им слишком сильно). Такое должно лечиться методом вычитания эффекта объявления на статистики при подсчёте фичей для тренировочного объявления. К сожалению, я затупил и не заметил перекрывающиеся данные во время соревнования, поэтому не знаю, насколько сильно это помогло бы.
Ещё один интересный эффект: модели, используемые топ-3 участниками, сильно отличаются по своей природе (SVM, CatBoost, NN), в то время как результаты относительно близки. Это довольно неожиданно — зачастую правильный выбор модели сильно влияет на итоговый результат.
В целом задача получилась интересной, я с нетерпением жду финала. Надеюсь, там задача будет ещё лучше, и понравится мне и остальным участникам.
Телеграм: t.me/ainewsline
Источник: m.vk.com