Работаем с SQL Server с помощью Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-18 18:02

Ограничения SQL берут своё начало в декларативности языка – мы указываем SQL что мы хотим получить, а SQL извлекает нам это из указанной базы. Для простой обработки данных этого достаточно. Но что делать, если мы хотим большего? Приведённый ниже класс – наша основа для оптимизации сервера MS SQL, далее мы дополним его несколькими методами. Сторонний модуль pyodbc упрощает доступ к базам данных через программный интерфейс ODBC (Open Database Connectivity).
import pyodbc from datetime import datetime class Sql: def __init__(self, database, server="XXVIR00012,55000"): self.cnxn = pyodbc.connect("Driver={SQL Server Native Client 11.0};" "Server="+server+";" "Database="+database+";" "Trusted_Connection=yes;") self.query = "-- {} -- Made in Python".format(datetime.now() .strftime("%d/%m/%Y")) Чтобы подключиться к базе данных из Python с помощью этого класса, достаточно создать объект и передать имя базы данных, к примеру, sql = Sql('database123').
Давайте разберёмся, что происходит внутри класса. В метод инициализации __init__ мы передаём строку server="XXVIR00012,55000". Это строковое значение – имя нашего сервера, которое можно найти в диалоговом окне "Connect to Server" или в верхней части окна в среде MS SQL в Server Management Studio:
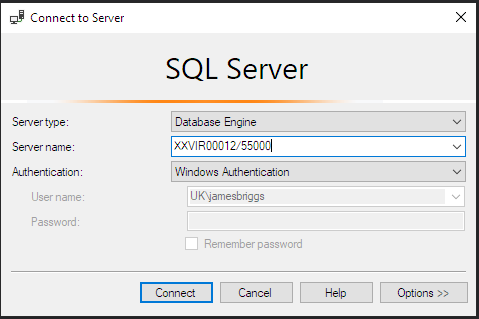
Все трудности подключения берёт на себя модуль pyodbc. Нам лишь нужно передать строку подключения в функцию pyodbc.connect().
self.cnxn = pyodbc.connect("Driver={SQL Server Native Client 11.0};" "Server="+self.server+";" "Database="+self.database+";" "Trusted_Connection=yes;") Подробнее о передаваемых в ODBC-интерфейс значениях читайте в официальном хелпе.
В конце класса создаётся строка, обновляемая с каждым передаваемым запросом:
self.query = "-- {} -- Made in Python".format(datetime.now() .strftime("%d/%m/%Y")) Это позволяет нам собирать логи и создавать более читабельный вывод. Для записи времени мы используем стандартную библиотеку datetime.
Компоненты
Есть несколько важных функций, направленных на передачу данных в базу данных или из неё. Для примера мы возьмём каталог, в котором имеется множество однотипных csv-файлов.
В текущем проекте мы хотим:
- Импортировать файлы в SQL-server.
- Объединить их в одну таблицу.
- Динамически создать несколько таблиц на основе категорий внутри столбца.
import sys sys.path.insert(0, r'C:Usermediumpysqlpluslib') import os import pandas as pd from data import Sql sql = Sql('database123') directory = r'C:Usermediumdata' # место хранения сгенерированных данных file_list = os.listdir(directory) # определить список всех файлов for file in file_list: df = pd.read_csv(directory+file) sql.push_dataframe(df, file[:-4]) # конвертируем список имен из file_list в имена таблиц table_names = [x[:-4] for x in file_list] sql.union(table_names, 'generic_jan') # объединяем файлы в одну таблицу sql.drop(table_names) # определяем список категорий в colX, например ['hr', 'finance', 'tech', 'c_suite'] sets = list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BY colX", response=True)['category']) for category in sets: sql.manual("SELECT * INTO generic_jan_"+category+" FROM generic_jan WHERE colX = '"+category+"'") Как мы видим, кроме инициализации в класс Sql нужно добавить методы push_dataframe и manual, union и drop. Опишем их.
Метод push_dataframe
Функция push_dataframe позволит поместить в базу данных датафрейм Pandas.
def push_dataframe(self, data, table="raw_data", batchsize=500): cursor = self.cnxn.cursor() # создаем курсор cursor.fast_executemany = True # активируем быстрое выполнение # создаём заготовку для создания таблицы (начало) query = "CREATE TABLE [" + table + "] ( " # итерируемся по столбцам for i in range(len(list(data))): query += " [{}] varchar(255)".format(list(data)[i]) # add column (everything is varchar for now) # добавляем корректное завершение if i != len(list(data))-1: query += ", " else: query += " );" cursor.execute(query) # запуск создания таблицы self.cnxn.commit() # коммит для изменений # append query to our SQL code logger self.query += (" -- create table " + query) # вставляем данные в батчи query = ("INSERT INTO [{}] ({}) ".format(table, '['+'], [' # берем столбцы .join(list(data)) + ']') + "VALUES (?{})".format(", ?"*(len(list(data))-1))) # вставляем данные в целевую таблицу for i in range(0, len(data), batchsize): if i+batchsize > len(data): batch = data[i: len(data)].values.tolist() else: batch = data[i: i+batchsize].values.tolist() # запускаем вставку батча cursor.executemany(query, batch) self.cnxn.commit() Это полезно, когда нужно загрузить много файлов.
Метод manual
Метод manual используется выше как отдельно, так и внутри функций union и drop. Она позволяет упростить выполнение SQL-кода.
def manual(self, query, response=False): cursor = self.cnxn.cursor() # создаем курсор выполнения if response: return read_sql(query, self.cnxn) try: cursor.execute(query) # execute except pyodbc.ProgrammingError as error: print("Warning: {}".format(error)) self.cnxn.commit() return "Query complete." Аргумент response даёт возможность вставить в датафрейм исходящую информацию нашего запроса. Извлечь все уникальные значения из colX в таблице generic_jan можно с помощью следующей строки:
sets = list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BY colX", response=True)['category']) Метод union
Теперь на основе метода manual создадим метод union:
def union(self, table_list, name="union", join="UNION"): query = "SELECT * INTO ["+name+"] FROM ( " query += f' {join} '.join( [f'SELECT [{x}].* FROM [{x}]' for x in table_list] ) query += ") x" self.manual(query, fast=True) Это «объединяющий» запрос с перебором списка имён таблиц из table_list .
Метод drop
Метод drop выполняет удаление таблиц:
def drop(self, tables): if isinstance(tables, str): # если отдельная строка, переведем в список tables = [tables] for table in tables: # проверяем наличие таблицы и удаляем, если существует query = ("IF OBJECT_ID ('["+table+"]', 'U') IS NOT NULL " "DROP TABLE ["+table+"]") self.manual(query) Функция drop позволяет удалить одну или несколько таблицу, поместив строку в tables, либо несколько таблиц, поместив туда же весь список.
Заключение
Сочетая описанные несложные методы мы значительно облегчили работу с большим количеством файлов в SQL Server. Если вас заинтересовала тема взаимодействия Python и SQL, почитайте наш пост «Как подружить Python и базы данных SQL. Подробное руководство». Успехов в развитии!
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io