Рады представить вам PyCaret – библиотеку машинного обучения с открытым исходным кодом на Python для обучения и развертывания моделей с учителем и без учителя в low-code среде. PyCaret позволит вам пройти путь от подготовки данных до развертывания модели за несколько секунд в той notebook-среде, которую вы выберете. По сравнению с другими открытыми библиотеками машинного обучения, PyCaret – это low-code альтернатива, которая поможет заменить сотни строк кода всего парой слов. Скорость проведения более эффективных экспериментов возрастет экспоненциально. PyCaret – это, по сути, оболочка Python над несколькими библиотеками машинного обучения, такими как scikit-learn, XGBoost, Microsoft LightGBM, spaCy и многими другими. PyCaret проста и удобна в использовании. Все операции, выполняемые PyCaret, последовательно сохраняются в пайплайне полностью готовом для развертывания. Будь то добавление пропущенных значений, преобразование категориальных данных, инженерия признаков или оптимизация гиперпараметров, PyCaret сможет все это автоматизировать. Чтобы узнать чуть больше о PyCaret посмотрите это короткое видео.
Начало работы с PyCaret
Первый стабильный релиз PyCaret версии 1.0.0 можно установить с помощью pip. Используйте интерфейс командной строки или среду notebook и запустите команду, приведенную ниже для установки PyCaret.
pip install pycaretЕсли вы пользуетесь Azure Notebooks или Google Colab, запустите следующую команду:
!pip install pycaretКогда вы установите PyCaret, все зависимости установятся автоматически. Вы можете ознакомиться со списком зависимостей здесь.
Легче быть не может
Пошаговое руководство
1. Получение данных
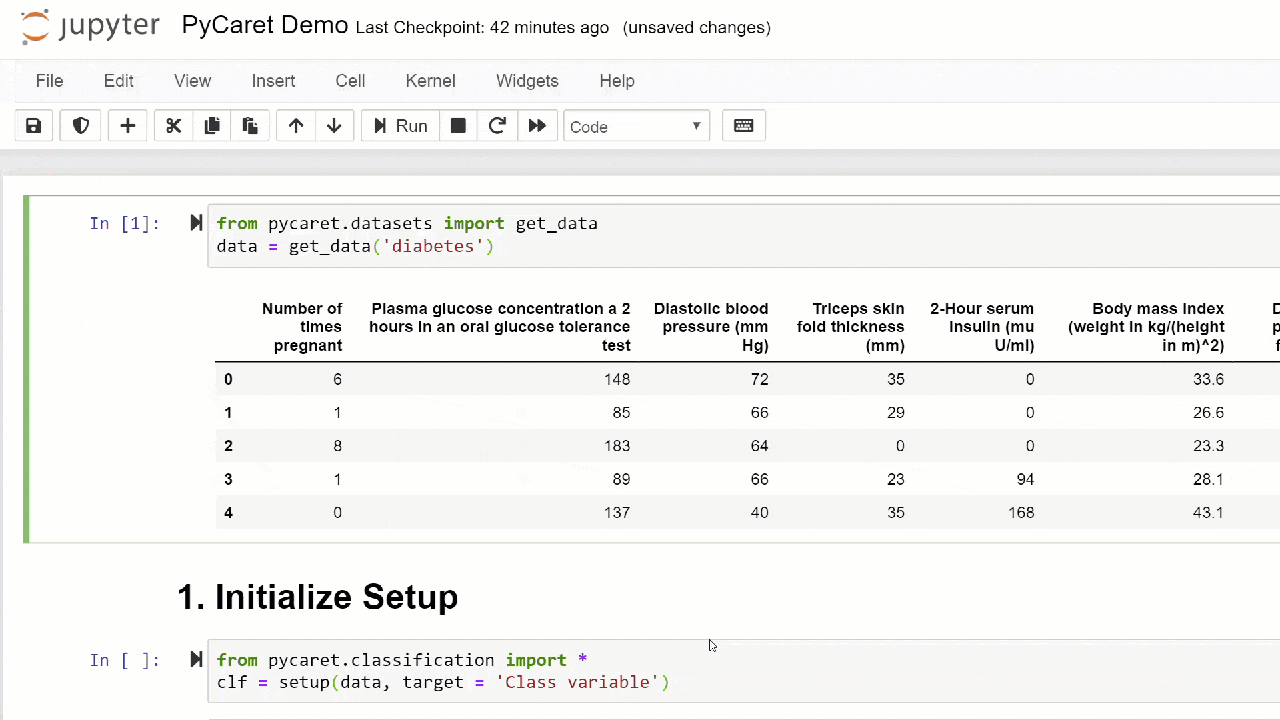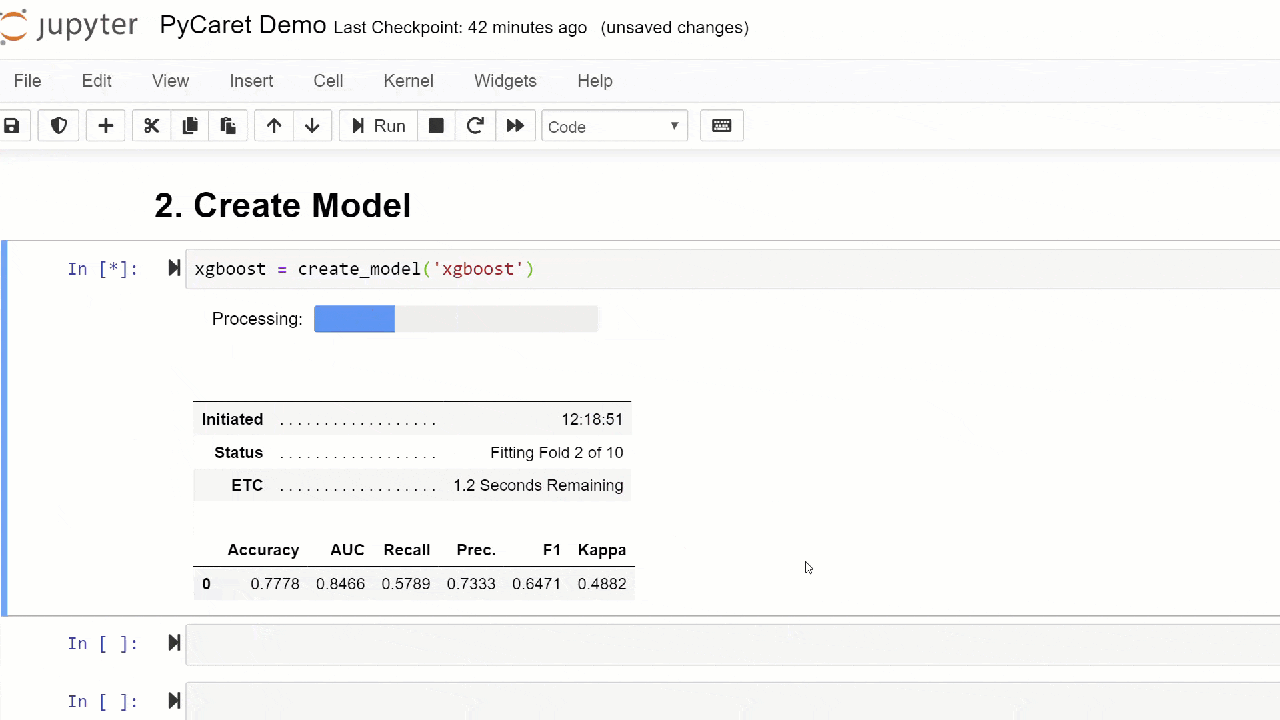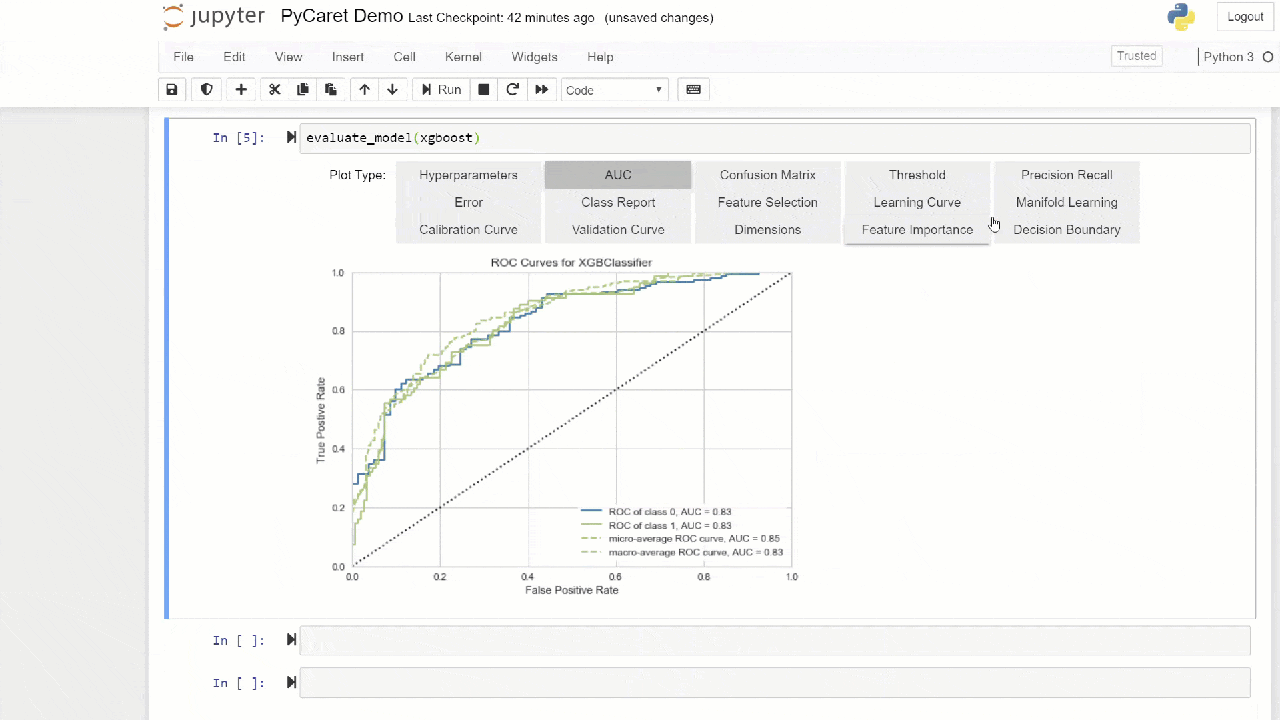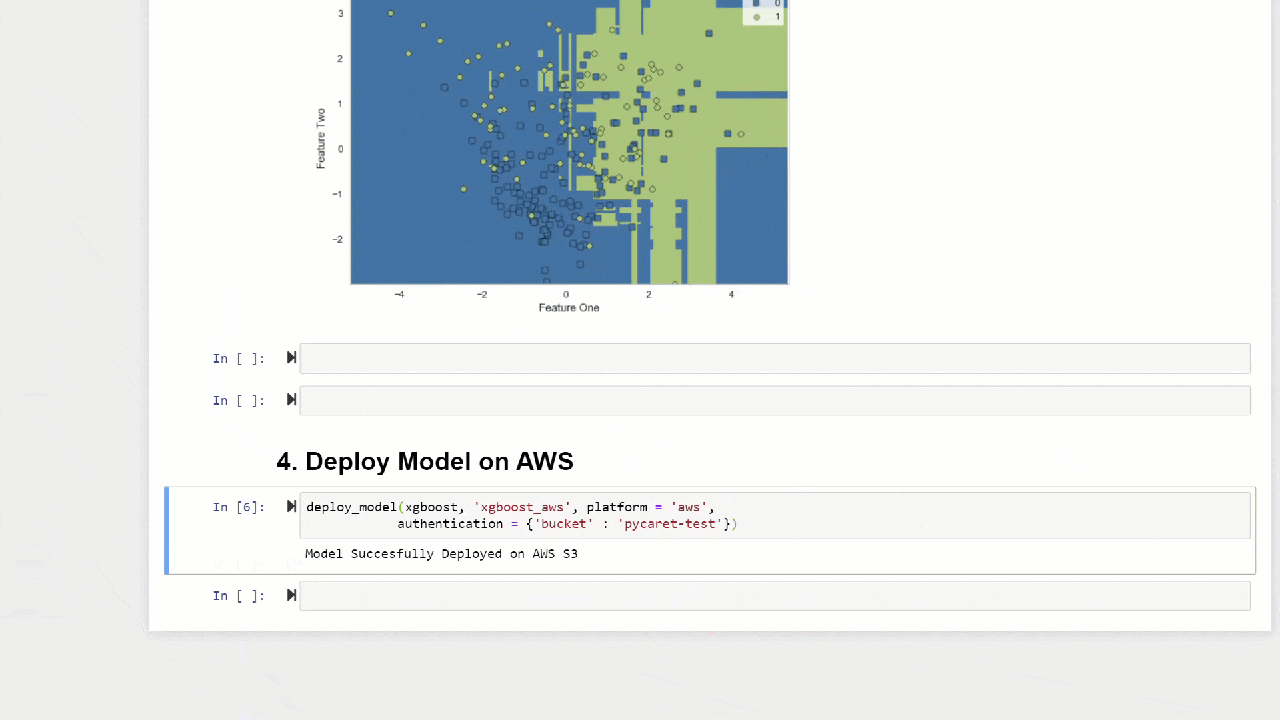
В этом пошаговом руководстве мы воспользуемся датасетом диабетиков, наша цель состоит в том, чтобы предсказать результат пациента (в двоичном формате 0 или 1) на основе нескольких факторов, таких как давление, уровень инсулина в крови, возраст и т.д. Этот датасет доступен на GitHub-репозитории PyCaret. Самый простой способ импортировать датасет напрямую из репозитория – это использовать функцию get_data из модулей pycaret.datasets.
from pycaret.datasets import get_data diabetes = get_data('diabetes')
2. Настройка среды
Любой эксперимент с машинным обучением в PyCaret начинается с настройки среды путем импорта необходимого модуля и инициализации
setup(). Модуль, который будет использоваться в этом примере – это pycaret.classification.После импорта модуля
setup() инициализируется путем определения датафрейма (‘diabetes’) и целевой переменной (‘Class variable’).from pycaret.classification import * exp1 = setup(diabetes, target = 'Class variable')
setup(). Задействуя более 20 функций для подготовки данных перед машинным обучением, PyCaret создает пайплайн преобразований на основе параметров, определенных в функции setup(). Он автоматически простраивает все зависимости в пайплайне, поэтому вам не нужно вручную управлять последовательным выполнением преобразований на тестовом или новом (невидимом) датасете. Пайплайн PyCaret можно легко переносить из одной среды в другую или развернуть на продакшене. Ниже вы можете ознакомиться с функциями препроцессинга, которые доступны в PyCaret с первого релиза.
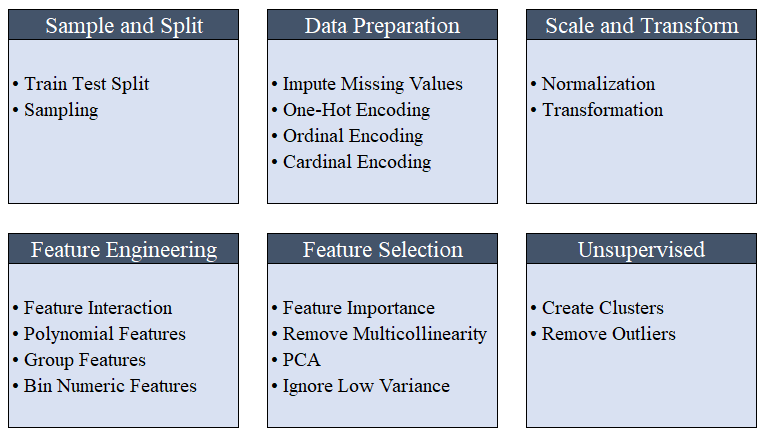
setup(). Вы можете узнать больше о возможностях препроцессинга в PyCaret здесь. 3. Сравнение моделейЭто первый шаг, который рекомендуется выполнить при работе с обучением с учителем (классификация или регрессия). Эта функция обучает все модели в библиотеке моделей и сравнивает между собой оценочный показатель с помощью кросс-валидации по К-блокам (по умолчанию 10 блоков). Оценочные показатели используются следующие:
- Для классификации: Accuracy, AUC, Recall, Precision, F1, Kappa
- Для регрессии: MAE, MSE, RMSE, R2, RMSLE, MAPE
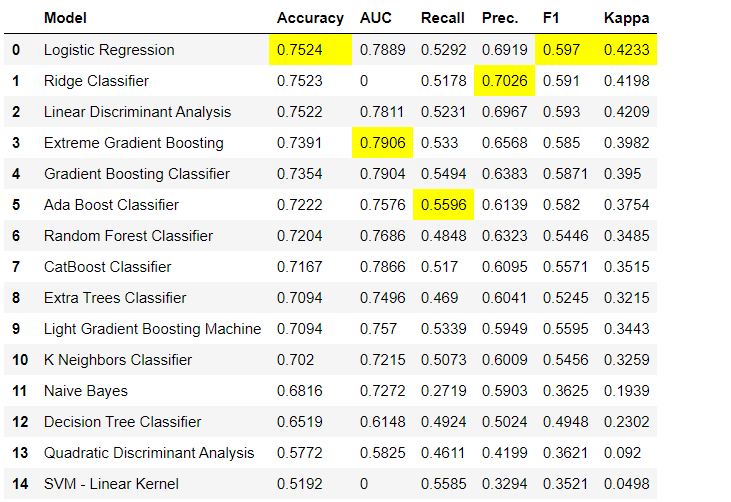
fold. Таблица по умолчанию отсортирована по «Accuracy» от самого высокого значения, к самому низкому. Порядок сортировки также можно изменить с помощью параметра
sort.4. Создание модели
Создать модель в любом модуле PyCaret так просто, что нужно просто написать
create_model. На вход функция принимает один параметр, т.е. имя модели, передаваемое в виде строки. Эта функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.adaboost = create_model('ada')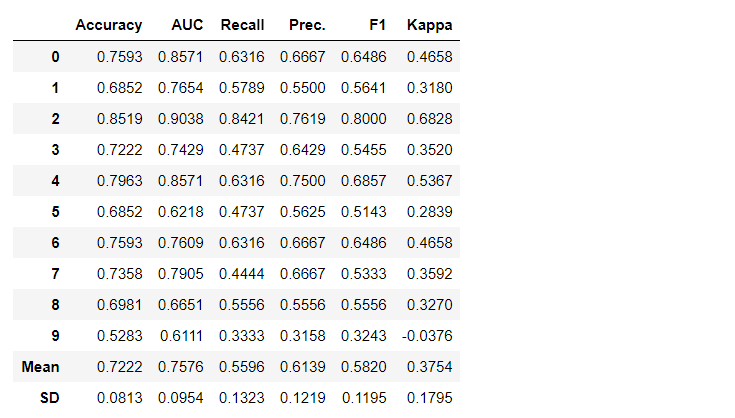
create_model, которая под капотом представляет из себя оценщик scikit-learn. Доступ к исходным атрибутам обучаемого объекта можно получить с помощью функции period ( . ) после переменной. Пример использования вы можете найти ниже.
Функция
tune_model используется для автоматической настройки гиперпараметров модели машинного обучения. PyCaret использует random grid search в определенном пространстве поиска. Функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.tuned_adaboost = tune_model('ada') 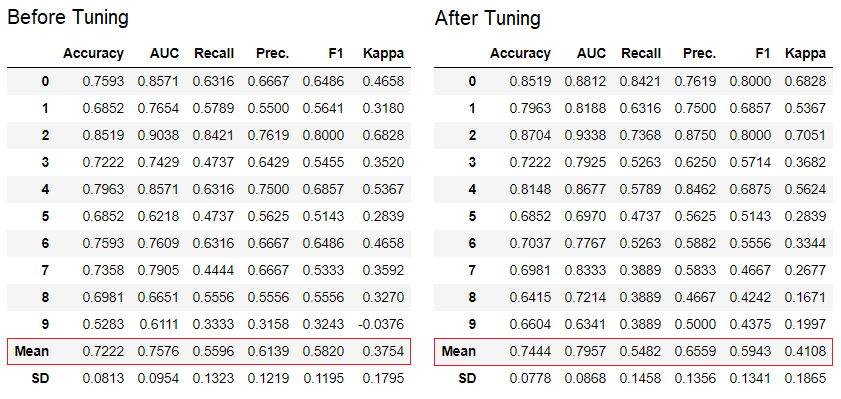
tune_model в модулях обучения без учителя, таких как pycaret.nlp, pycaret.clustering и pycaret.anomaly, может использоваться совместно с модулями обучения с учителем. Например, модуль NLP в PyCaret может использоваться для настройки параметра number of topics путем оценки объективной функции или функции потерь из модели с учителем, такой как «Accuracy» или «R2».6. Ансамбль моделей
Функция
ensemble_model используется для создания ансамбля обученных моделей. На вход она принимает один параметр – объект обученной модели. Функция возвращает таблицу с кросс-валидированными оценками и объект обученной модели.# creating a decision tree model dt = create_model('dt') # ensembling a trained dt model dt_bagged = ensemble_model(dt)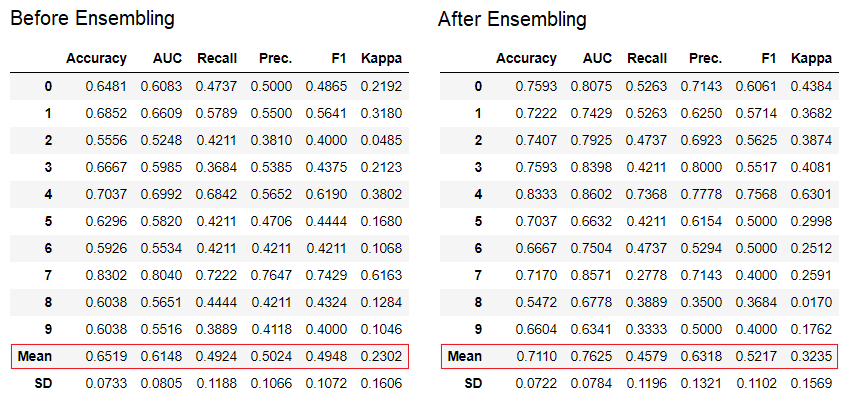
method в функции ensemble_model.Также PyCaret предоставляет функции
blend_models и stack_models для объединения нескольких обученных моделей. 7. Визуализация моделиОценить производительность и провести диагностику обученной модели машинного обучения можно с помощью функции
plot_model. Она принимает в себя объект обученной модели и тип графика в виде строки.# create a model adaboost = create_model('ada') # AUC plot plot_model(adaboost, plot = 'auc') # Decision Boundary plot_model(adaboost, plot = 'boundary') # Precision Recall Curve plot_model(adaboost, plot = 'pr') # Validation Curve plot_model(adaboost, plot = 'vc')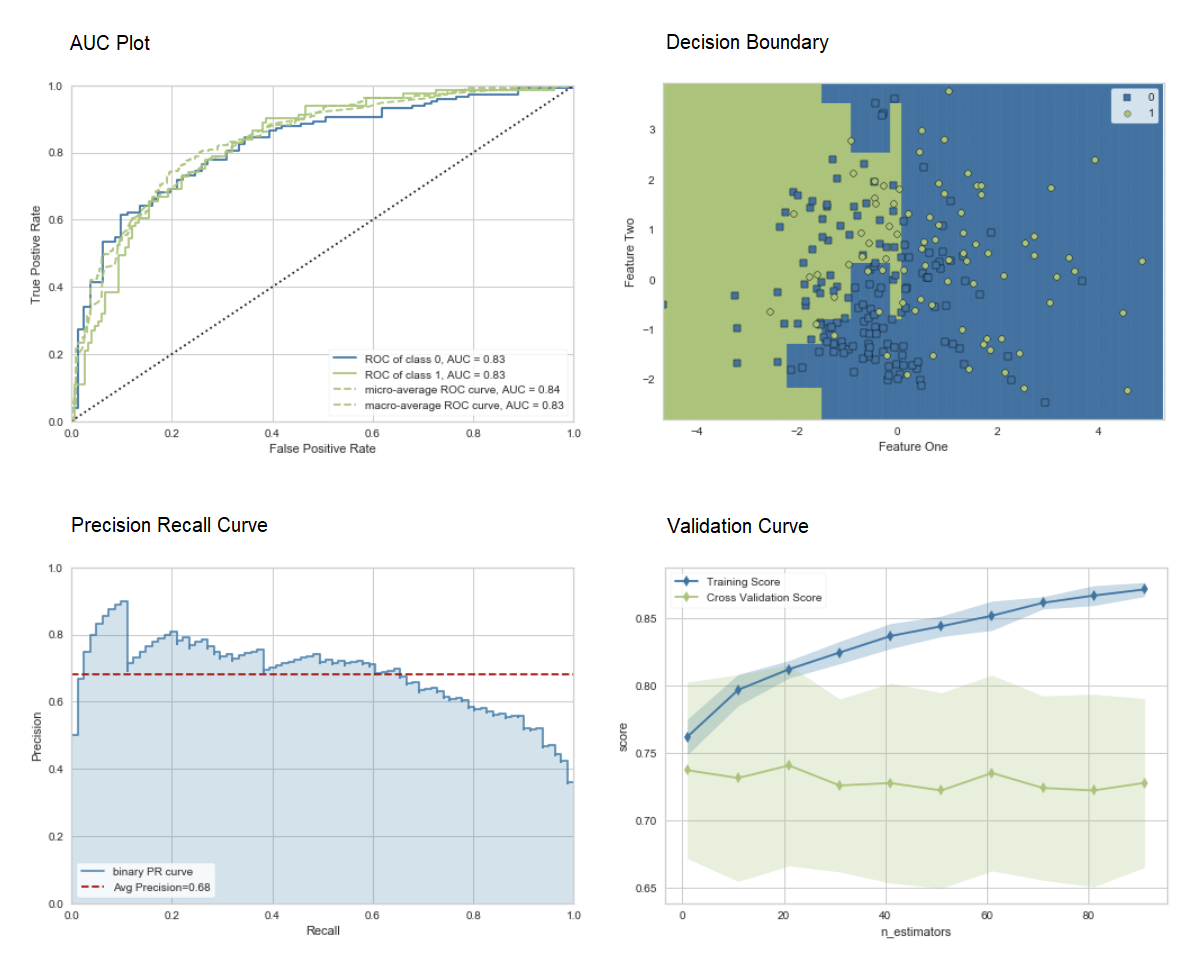
evaluate_model, чтобы увидеть графики с помощью пользовательского интерфейса notebook.
plot_model в модуле pycaret.nlp можно использовать для визуализации корпуса текстов и семантических тематических моделей. Здесь вы можете узнать о них больше. 8. Интерпретация моделиКогда данные нелинейные, что случается в реальной жизни достаточно часто, мы неизменно видим, что древовидные модели работают гораздо лучше, чем простые гауссовские модели. Однако это происходит за счет потери интерпретируемости, поскольку древовидные модели не обеспечивают простых коэффициентов, как линейные модели. PyCaret реализует SHAP (SHapley Additive exPlanations) с помощью функции
interpret_model.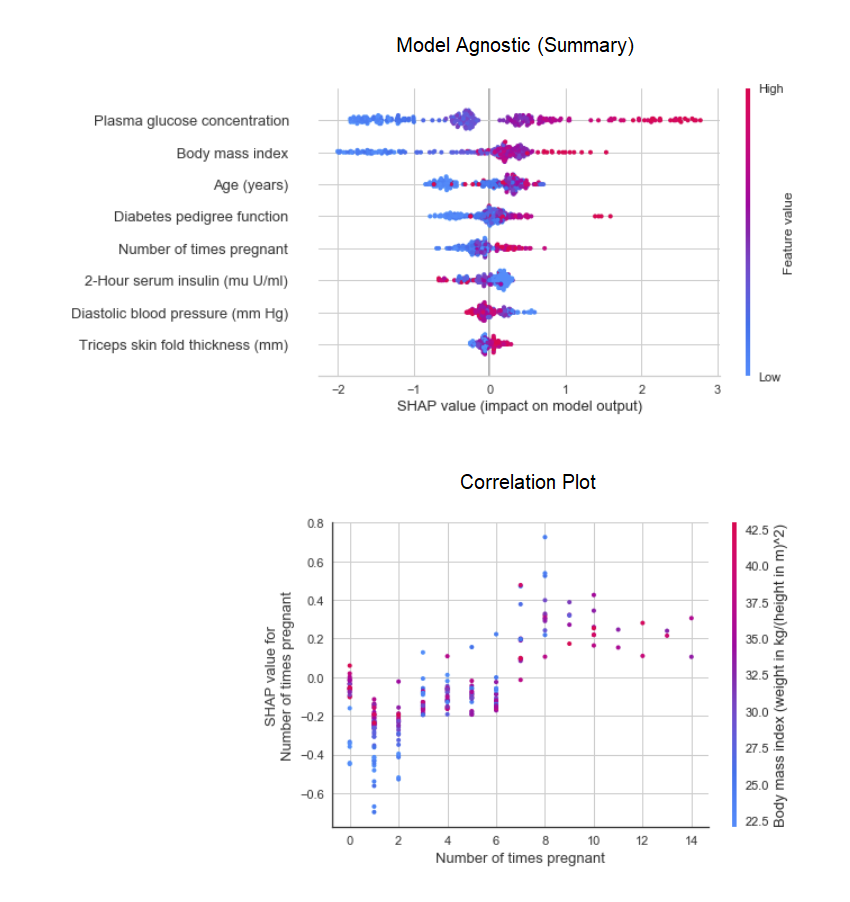

До этого момента, результаты, которые мы получали, основывались на кросс-валидации по К-блокам на обучающем датасете (по умолчанию 70%). Для того, чтобы увидеть прогнозы и производительность модели на тестовом/hold-out датасете, используется функция
predict_model.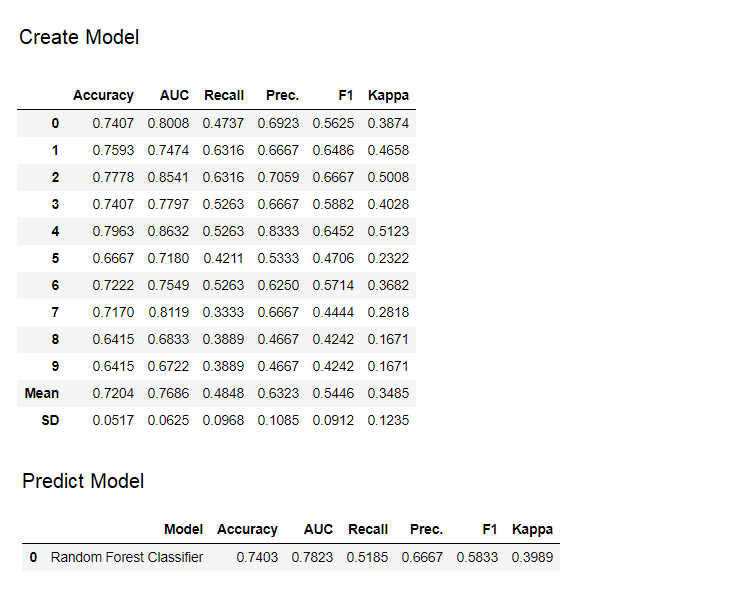
predict_model используется для составления прогноза невидимого датасета. Сейчас мы будем использовать тот же датасет, который мы использовали для обучения, в качестве прокси для нового невидимого датасета. На практике, функция predict_model будет использоваться итеративно, каждый раз на новом невидимом датасете.
predict_model может также делать предсказания для последовательной цепи моделей, которую можно создать с помощью функций stack_models и create_stacknet. Функция
predict_model также может делать предсказания непосредственно для моделей, размещенных на AWS S3 с помощью функции deploy_model. 10. Деплой моделиОдин из способов использования обученных моделей для создания прогнозов по новому датасету заключается в использовании функции
predict_model в тех же notebook /IDE, где была обучена модель. Однако формирование прогноза по новому (невидимому) датасету – это итерационный процесс. В зависимости от варианта использования частота выполнения прогнозов может варьироваться от прогнозов в реальном времени до пакетных предсказаний. Функция deploy_model в PyCaret позволяет развернуть весь пайплайн, включая обученную модель в облаке из среды notebook.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws', authentication = {'bucket' : 'pycaret-test'}) 11. Сохранить модель/сохранить эксперимент
После окончания обучения весь пайплайн, содержащий все преобразования препроцессинга и объект обученной модели, можно сохранить в бинарном pickle-файле.
# creating model adaboost = create_model('ada') # saving model save_model(adaboost, model_name = 'ada_for_deployment')

load_model и load_experiment, доступных из всех модулей PyCaret.12. Следующее руководство
В следующем руководстве мы покажем, как использовать обученную модель машинного обучения в Power BI для генерации пакетных предсказаний в реальной продакшен-среде.
Также вы можете ознакомиться с блокнотами для новичков по следующим модулям:
- Регрессия
- Кластеризация
- Поиск аномалий
- Обработка естественного текста (NLP)
- Обучение ассоциативным правилам
Что такое пайплайн разработки?
Мы активно работаем над улучшением PyCaret. Наш грядущий пайплайн разработки включает в себя новый модуль прогнозирования временных рядов, интеграцию с TensorFlow и серьезные улучшения масштабируемости PyCaret. Если вы хотите поделиться своими отзывами и помочь нам совершенствоваться, вы можете заполнить форму на сайте или оставить комментарий на нашей странице на GitHub или LinkedIn.
Хотите узнать больше о конкретном модуле?
Начиная с первого релиза в PyCaret 1.0.0 присутствуют следующие модули, доступные для использования. Перейдите по ссылкам ниже, чтобы ознакомиться с документацией и примерами работы.
Классификация Регрессия Кластеризация Поиск аномалий Обработка естественного текста (NLP) Обучение ассоциативным правилам
Важные ссылки
- Руководство пользователя/документация
- Репозиторий на GitHub
- Установить PyCaret
- Руководство по notebook
- Поддержка PyCaret