Обзор четырёх популярных NLP-моделей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-21 12:04

Одна из задач языкового моделирования – предсказать следующее слово, опираясь на знание предыдущего текста. Это нужно для исправления опечаток, автодополнения, чат-ботов и т. д. В интернете можно найти много разрозненной информации о моделях обработки естественного языка. Мы собрали четвёрку популярных NLP-моделей в одном месте и сравнили их, опираясь на документацию и научные источники.
1. Рекуррентная нейросетевая языковая модель (RNNLM)
Возникшая в 2001 г. идея привела к рождению одной из первых embedding-моделей.
Embeddings
В языковом моделировании отдельные слова и группы слов сопоставляются векторам – некоторым численным представлениям с сохранением семантической связи. Сжатое векторное представление слова называют эмбеддингом.
Модель принимает на вход векторные представления n предыдущих слов и может «понимать» семантику предложения. Обучение модели базируется на алгоритме непрерывного мешка слов. Контекстные (соседние) слова подаются на вход нейронной сети, которая предсказывает центральное слово.
Мешок слов
Мешок слов – это модель представления текста в виде вектора (набора слов). Каждому слову в тексте сопоставляется число его вхождений.
Сжатые векторы объединяются, передаются в скрытый слой, где срабатывает softmax функция активации, определяющая, какие сигналы пройдут дальше (если эта тема вызывает трудности, прочитайте наше Наглядное введение в нейросети).
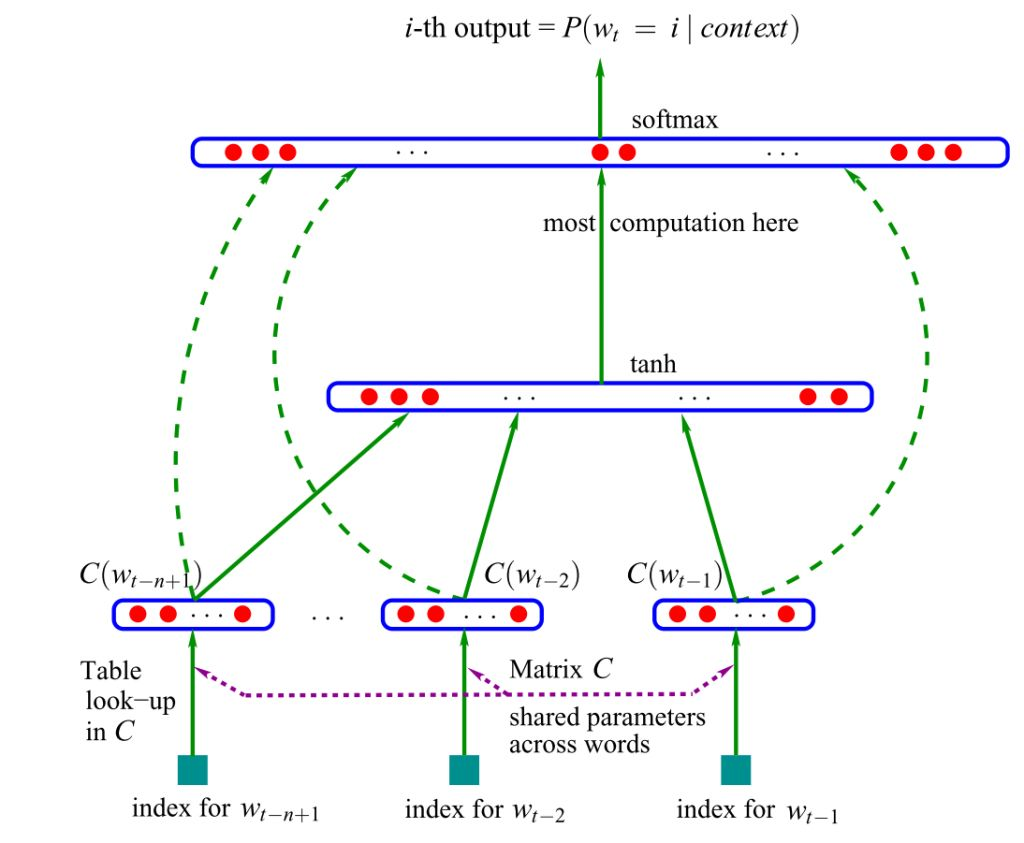
Оригинальная версия основывалась на нейросетях прямого распространения – сигнал шёл строго от входного слоя к выходному. Позднее была предложена альтернатива в виде рекуррентных нейронных сетей (RNN) – именно на «ванильной» RNN, а не на управляемых рекуррентных блоках (GRUs) или на долгой краткосрочной памяти (LSTM).
Рекуррентные нейронные сети (RNN)
Нейронные сети с направленными связями между элементами. Выход нейрона может снова подаваться на вход. Такая структура позволяет иметь подобие «памяти» и обрабатывать последовательности данных, например, тексты естественного языка.
Готовые модели
У Google есть предварительно обученные open-source модели для большинства языков (английская версия). Модель использует три скрытых слоя нейронной сети прямого распространения, обучена на корпусе English Google News 200B и генерирует 128-мерный эмбеддинг.
Преимущества
- Простота. Модель быстро обучается и генерирует эмбеддинги, что достаточно для большинства простых приложений.
- Предварительно обученные версии доступны на многих языках.
Недостатки
- Не учитывает долгосрочные зависимости.
- Простота ограничивает возможности использования.
- Новые embeddings модели намного мощнее.
Источник: Yoshua Bengio, R?jean Ducharme, Pascal Vincent, Christian Jauvin, A Neural Probabilistic Language Model (2003), Journal of Machine Learning Research
2. Word2vec
В 2013 году Томас Миколов (Tomas Mikolov) из Google предложил более эффективную модель обучения векторных представлений слов – Word2vec. Метод основывался на предположении, что слова, которые часто находятся в одинаковых контекстах, имеют схожие значения. Изменения были просты – устранение скрытого слоя и аппроксимация (упрощение) цели – но стали поворотной точкой в развитии языковых моделей NLP.
Вместо алгоритма непрерывного мешка слов модель Word2Vec использует Skip-gram (словосочетание с пропуском). Цель этой модели прямо противоположная предыдущей модели – предсказать окружающие слова на основе центрального.
Skip-Gram
Формируется «контекстное окно» – последовательность из k слов в тексте. Одно из этих слов пропускается, и нейросеть пытается его предсказать. Таким образом, слова, которые часто встречаются в похожем контексте, будут иметь похожие векторы.
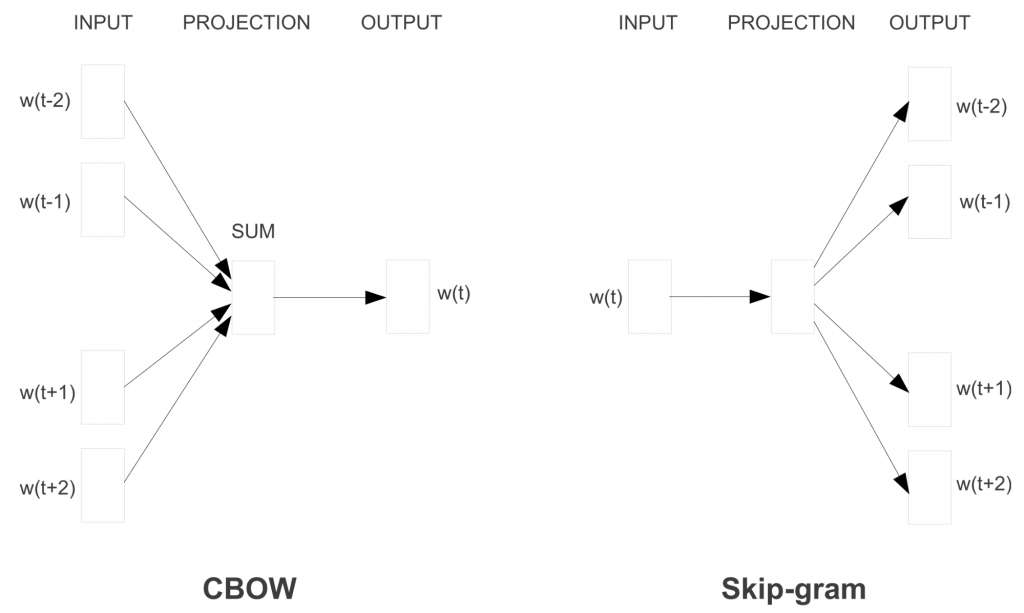
Чтобы сделать обучение эффективнее, используется негативное семплирование (Negative Sampling): модели предоставляются слова, которые не являются контекстными соседями.
Negative Sampling
Многие слова в текстах не встречаются вместе, поэтому модель выполняет много лишних вычислений. Подсчёт softmax — вычислительно дорогая операция. Подход Negative Sampling позволяет максимизировать вероятность встречи нужного слова в контексте, который является для него типичным, и минимизировать – в редком/нетипичном контексте.
Векторная магия
Модель Word2vec поразила исследователей своей «интерпретируемостью». Обучение на больших корпусах текстов позволяет определять глубокие отношения между формами слов, например, гендерные. Если из вектора, соответствующего слову Мужчина (Man) вычесть вектор Женщина (Woman), результат будет очень похож на разность векторов Король (King) и Королева (Queen).
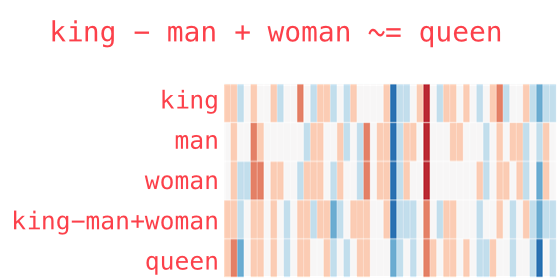
Одно время такое отношения между словами и их векторами казалось почти магией. Ещё несколько забавных примеров векторной арифметики вы можете найти в статье Во что превращается жизнь без любви. Несмотря на огромный вклад, который модель внесла в NLP, сейчас она почти не используется – на смену пришли достойные наследники.
Готовые модели
Предварительно обученная модель легко доступна в интернете. В Python-проект её можно импортировать с помощью библиотеки gensim.
Преимущества
- Простая архитектура: feed-forward, 1 вход, 1 скрытый слой, 1 выход.
- Модель быстро обучается и генерирует эмбеддинги (даже ваши собственные).
- Эмбеддинги наделены смыслом, спорные моменты поддаются расшифровке.
- Методология может быть распространена на множество других областей/проблем (например, Lda2vec).
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Совместная встречаемость игнорируется. Модель не учитывает то, что слово может иметь различное значение в зависимости от контекста использования. Это основная причина, по которой GloVe обычно предпочтительнее Word2Vec.
- Не очень хорошо обрабатывает неизвестные и редкие слова.
Источник: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space (2013), International Conference on Learning Representations
3. GloVe (Global Vectors)
GloVe тесно ассоциируется с Word2Vec: алгоритмы появились примерно в одно и то же время и опираются на интерпретируемость векторов слов. Модель GloVe пытается решить проблему эффективного использования статистики совпадений. GloVe минимизирует разницу между произведением векторов слов и логарифмом вероятности их совместного появления с помощью стохастического градиентного спуска. Полученные представления отражают важные линейные подструктуры векторного пространства слов: получается связать вместе разные спутники одной планеты или почтовый код города с его названием.
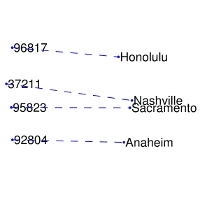
В Word2Vec частота совместной встречаемости слов не имеет большого значения, она лишь помогает генерировать дополнительные обучающие выборки. GloVe учитывает совместную встречаемость, а не полагается только на контекстную статистику. Векторы слов группируются вместе на основе их глобальной схожести.
Готовые модели
Эмбеддинги GloVe легко доступны на веб-сайте Стэнфордского университета.
Преимущества
- Простая архитектура без нейронной сети.
- Модель быстрая, и этого может быть достаточно для простых приложений.
- GloVe улучшает Word2Vec. Она добавляет частоту встречаемости слов и опережает Word2Vec на большинстве бенчмарков.
- Осмысленные эмбеддинги.
Недостатки
- Хотя матрица совместной встречаемости предоставляет глобальную информацию, GloVe остаётся обученной на уровне слов и даёт немного данных о предложении и контексте, в котором слово используется.
- Плохо обрабатывает неизвестные и редкие слова.
Источник: Jeffrey Pennington, Richard Socher, and Christopher D. Manning, GloVe: Global Vectors for Word Representation (2014), Empirical Methods in Natural Language Processing
4. fastText
Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в развитии моделей естественного языка. В её разработке принял участие Томас Миколов, уже знакомый нам по Word2Vec. Для векторизации слов используются одновременно и skip-gram, и негативное семплирование, и алгоритм непрерывного мешка.
К основной модели Word2Vec добавлена модель символьных n-грамм. Каждое слово представляется композицией нескольких последовательностей символов определённой длины. Например, слово they в зависимости от гиперпараметров может состоять из "th", "he", "ey", "the", "hey". По сути, вектор слова – это сумма всех его n-грамм.
Результаты работы классификатора хорошо подходят для слов с небольшой частотой встречаемости, так как они разделяются на n-граммы. В отличие от Word2Vec и Glove, модель способна генерировать эмбеддинги для неизвестных слов.
Готовые модели
В сети доступна подготовленная модель для 157 языков (в том числе русского).
Преимущества
- Относительно простая архитектура: feed-forward, 1 вход, 1 скрытый слой, один выход (хотя n-граммы добавляют сложность в генерацию эмбеддингов).
- Благодаря n-граммам неплохо работает на редких и устаревших словах.
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Игнорируется совместная встречаемость, то есть модель не учитывает различное значение слова в разных контекстах (поэтому GloVe может быть предпочтительнее).
Источник: Armand Joulin, Edouard Grave, Piotr Bojanowski and Tomas Mikolov, Bag of Tricks for Efficient Text Classification (2016), European Chapter of the Association for Computational Linguistics
***
Все четыре модели имеют много общего, но каждая из них должна использоваться в подходящем контексте. К сожалению, этот момент часто игнорируется, что приводит к получению неоптимальных результатов.
Если вам интересна тема обработки естественного языка, у нас есть ещё пара материалов:
- Обработка естественного языка: с чего начать и что изучать дальше
- NLP – это весело! Обработка естественного языка на Python
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io