Нейросеть учится распознавать объекты на изображении сквозь препятствия
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-21 16:24

Исследователи обучили нейросеть восстанавливать изображение от перекрывающих объектов: стекло окна, ограда и капли дождя. Модель принимает на вход видеозапись сцены, которую снимали на движущуюся камеру. На выходе модель генерирует изображение сцены без препятствия. В качестве архитектуры сети использовали глубокую сверточную нейросеть.
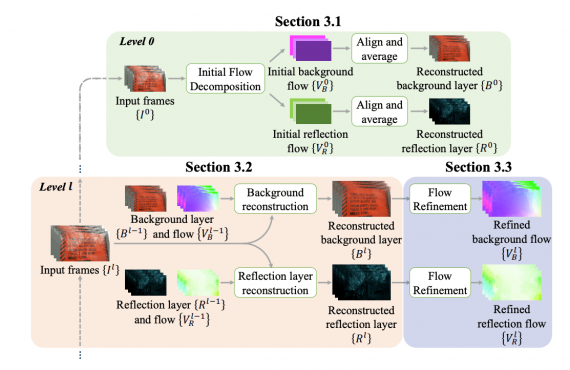
Что внутри модели
На вход модели поступает последовательность из кадров. Задача нейросети — разделить каждый кадр на два слоя: чистый задний фон и перекрывающий передний фон. Перекрывающим передним фоном могут быть ограда, капли дождя или окклюзия.
Чтобы отделять слои, исследователи используют подход от грубого до точного (coarse-to-fine). На первом этапе модель выдает грубую оценку заднего и переднего фонов. Чтобы уточнить предсказание, исследователи используют PWC-Net архитектуру. Фреймворк прогрессивно реконструирует задний фон и перекрывающий передний фон, пока не достигнет максимальной точности.
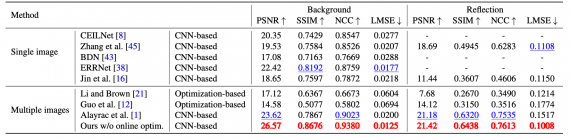
Оценка работы модели
Исследователи сравнили предложенный подход с state-of-the-art методами. В качестве датасета использовали синтетический набор данных, который состоит из 100 последовательностей. Каждая последовательность состоит из 5 кадров. Ниже видно, что предложенный подход выдает сравнимые с state-of-the-art результаты.
Телеграм: t.me/ainewsline
Источник: neurohive.io