Как очистка данных от ошибок разметки помогает увеличить точность модели
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-17 15:04

Разработчики из Deepomatic добавили в свою платформу инструмент для поиска ошибок разметки в данных. В популярных датасетах с изображениями VOC и COCO процент неточно размеченных данных превысил 20%. Исправление ошибок вручную привело к увеличению качества модели на 5% для state-of-the-art архитектур.
Процесс поиска и исправления ошибок
Исследователи взяли три популярных датасета из компьютерного зрения: VOC 2012, COCO 2017 и Self Driving Car Udacity. На этих датасетах обучили 6 нейросетевых моделей. Затем в датасетах нашли ошибочную разметку через платформу Deepomatic и вручную исправили ошибки. На обновленных датасетах заново обучили те же нейросетевые архитектуры и сравнили работу моделей с теми, что были обучены на оригинальных датасетах. В среднем ошибку моделей удалось сократить на 5%. Для датасета Udacity ошибку удалось сократить в среднем на 8.3%. Во всех случаях в качестве метрики оценки моделей использовалась метрика mAP.
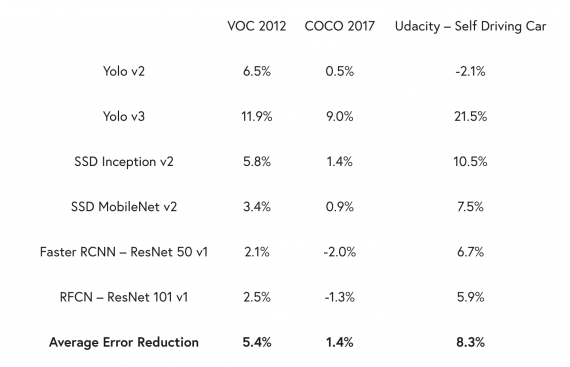
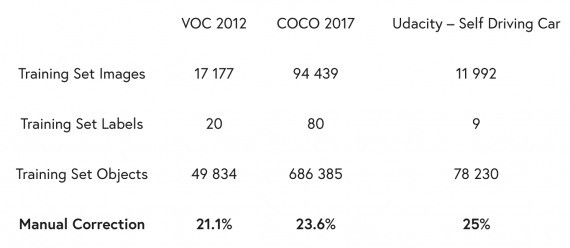
Deepomatic — это коммерческий продукт, который дополнили функцией поиска ошибочно размеченных границ объектов на изображениях. Видно, что процент ошибок для трех датасетов варьируется от 21 до 25.
Телеграм: t.me/ainewsline
Источник: neurohive.io