Глубокая генеративная модель trifecta: три прогресса, которые работают в направлении использования крупномасштабной мощности
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-16 11:33
компьютерная лингвистика, системы технического зрения, алгоритмы распознавания речи, распознавание образов, алгоритмы машинного обучения, реализация нейронной сети

Рисунок 1: краткая эволюция глубинных генеративных моделей с течением времени, измеряемая размером модели (число параметров) и научным воздействием (число цитирований на сегодняшний день). Рассматриваются три популярных глубоких генеративных типа моделей: Авторегрессионные модели (нейронные языковые модели или NLMs) в синем цвете, вариационные автоэнкодеры (VAEs) в зеленом цвете и генеративные состязательные сети (GANs) в оранжевом цвете. Трансформатор и Берт показаны как ссылки. Три новые генеративные модели, которые мы вводим в этом посте, расширяют масштабные возможности в каждой из этих категорий (правая сторона диаграммы).
Одним из основных стремлений в области искусственного интеллекта является разработка алгоритмов и методов, которые наделяют компьютеры способностью синтезировать наблюдаемые данные в нашем мире. Каждый раз, когда исследователи строят модель для имитации этой способности, эта модель называется генеративной моделью. Если глубинные нейронные сети участвуют в этой модели, то модель является глубокой генеративной моделью (DGM). Как отрасль самоконтролируемых методов обучения в области глубокого обучения, DGMs специально сосредоточены на характеристике процессов генерации данных.
В этом посте описываются три проекта, которые имеют общую тему: Совершенствование или применение СГД в эпоху крупномасштабных наборов данных и подготовки кадров. В этом посте мы сначала рассмотрим историю эволюции DGMs, а затем представим новые достижения в DGMs, сделанные исследователями из Microsoft Research в сотрудничестве с членами из Университета Буффало и Университета Дьюка . Генеративные модели, представленные здесь и подробно описанные в соответствующих статьях, каждый из них подпадает под другую категорию популярной глубокой генеративной модели. Optimus-первый крупномасштабный вариационный автоэнкодер (VAE) языковая модель, показывающая возможность СГД следовать тенденции использования предварительно подготовленных языковых моделей. FQ-GAN решает проблемы масштабируемости с генерацией изображений в генеративных состязательных сетях (GANs). Наконец, мы представляем превалирующий, первый предварительно обученный универсальный агент для навигации по зрению и языку . Давайте рассмотрим краткий обзор DGMs, прежде чем погрузиться в наши новые достижения.
Три типа генеративных моделей и общий трюк
Генеративные модели имеют давнюю историю в традиционном машинном обучении, и они часто отличаются от другого основного подхода, дискриминативных моделей . Можно узнать, чем они отличаются от истории двух братьев и сестер . В этой истории у братьев и сестер есть разные специальные способности: у одного есть возможность узнать все очень глубоко, в то время как другой может узнать только различия между тем, что он видит. Эти братья и сестры представляют собой генеративную модель, которая характеризует фактические распределения с внутренним механизмом, и дискриминативную модель, которая строит границы принятия решений между классами.
С ростом глубокого обучения, новое семейство методов, называемых глубокими генеративными моделями (DGMs), формируется за счет комбинации генеративных моделей и глубоких нейронных сетей. Поскольку нейронные сети, используемые в качестве генеративных моделей, имеют ряд параметров, меньших, чем объем данных, на которых они обучаются, существует трюк, который может выполнять DGMs. В отличном посте блога от OpenAI этот трюк раскрывается: "... модели вынуждены обнаруживать и эффективно интернализировать сущность данных для того, чтобы генерировать ее.” Чтобы узнать больше о DGMs, ознакомьтесь с последними лекциями в Стэнфордском университете, Калифорнийский университет в Беркли, Колумбийский университет и Нью-Йоркский университет .
Математически, для набора данных примеров {xi|xi ? РD, я = 1, … , Н} как образцы из истинного распределения данных q(x), целью DGM является построение глубоких нейронных сетей с параметрами ? ? РP, чтобы описать распределение p?(x) так что параметры ? смогите быть натренировано обеспечить p?(x) совпадение q(x) лучший. Все DGM имеют одну и ту же базовую установку и вышеупомянутый трюк DGM, но они отличаются тем, как они подходят к проблеме. Существует три популярных типа моделей в соответствии с таксономией OpenAI: VAEs , GANs и авторегрессионные модели . Каждый из них подробно описан в следующей таблице:
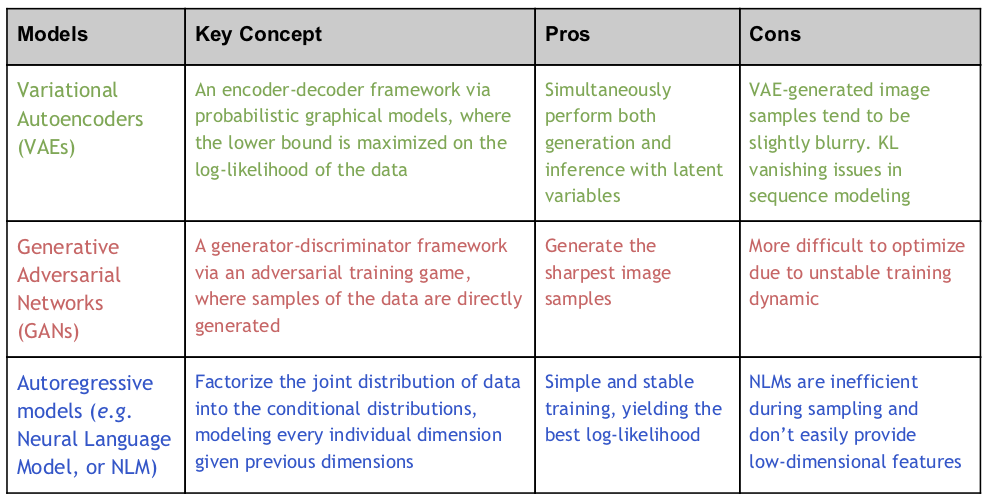
Переход от мелкомасштабных к крупномасштабным глубоким генеративным моделям во всех трех категориях
Благодаря многочисленным усилиям по разработке их теоретических принципов на протяжении многих лет, СГД в настоящее время относительно хорошо поняты в небольших масштабах. Трюк DGM, упомянутый выше, обещает, что модели прекрасно работают в мягких условиях: П< Н*Д. Это было подтверждено во многих ранних работах в малом масштабе. Однако в последние годы были отмечены огромные достижения и сильные эмпирические результаты благодаря предварительной подготовке больших моделей на массивных данных (в контексте приведенного выше уравнения,Нрезко увеличивается).
Исследователи из OpenAI считают, что генеративные модели являются одним из наиболее перспективных подходов для потенциального достижения цели наделения компьютеров пониманием нашего мира. В соответствии с этим они разработали генеративную предварительную подготовку (GPT) в 2018 году, авторегрессионную нейронную языковую модель (NLM), обученную на разнообразном корпусе немаркированного текста, с последующей дискриминационной тонкой настройкой по каждой конкретной задаче, показывающей значительно улучшенную производительность по нескольким задачам понимания языка. В 2019 году они дополнительно масштабировали эту идею до 1,5 млрд параметров и разработали ГПТ-2, что показывает почти человеческую производительность в языковой генерации. С большим количеством вычислений Megatron и Turing-NLG наследуют ту же идею и масштабируют ее до 8,3 миллиарда и 17 миллиардов соответственно.
Вышеизложенное направление исследований показывает, что NLM добился огромного прогресса (П резко увеличивается в уравнении выше). Тем не менее, как авторегрессионная модель, NLM является лишь одним из трех типов DGMs. Есть еще два других типа DGMs (VAE и GAN), которые могут быть значительно улучшены для крупномасштабного использования. В эту захватывающую эпоху большие модели обучаются на больших наборах данных с массивными вычислениями, что привело к возникновению новой парадигмы обучения: самоконтролируемая предварительная подготовка с тонкой настройкой конкретных задач. DGMs были изучены меньше в этой обстановке, и мы не уверены, что трюки DGMs все еще могут хорошо работать в этой обстановке для промышленной практики. Это поднимает ряд исследовательских вопросов, которые мы рассмотрим в отношении каждого проекта ниже:
- Возможность: насколько хороши DGMs на самом деле с предварительной подготовкой?
- Проблема: требуются ли изменения, чтобы заставить существующие методы работать в этом режиме?
- Применение: может ли DGMs помочь предварительной подготовке в отличие от этого?
Optimus: возможности в языковом моделировании
Центральный вопрос, рассматриваемый в этой статье, называется "Optimus: организация предложений с помощью предварительно подготовленного моделирования латентного пространства": что произойдет, если мы увеличим VAE и используем его в качестве новой предварительно подготовленной языковой модели (PLM)? Для решения этого вопроса нами была создана первая крупномасштабная глубинная латентная вариативная модель для естественного языка, которая предварительно обучается с использованием задач автоэнкодирования на уровне предложений (вариативных) на большом текстовом массиве.
Предварительно обученные языковые модели внесли существенный вклад в решение различных задач обработки естественного языка. PLM часто обучаются предсказывать слова на основе их контекста в массивных текстовых данных, и изученные модели могут быть точно настроены для адаптации к различным нижестоящим задачам. PLMs обычно может играть две различные роли: универсальный кодер , такой как BERT и Roberta, и мощный декодер, такой как GPT-2 и Megatron . Иногда обе задачи могут выполняться в одной унифицированной среде, например в UniLM, BART и T5. Эти модели не имеют явного моделирования структур в компактном латентном пространстве, что затрудняет управление генерацией и представлением естественного языка из семантики уровня предложения.
При эффективном обучении вариационный автоэнкодер (Ваэ) может быть как мощная генеративная модель, так и эффективная структура обучения представлению для естественного языка. Представляя предложения в низкоразмерном латентном пространстве, VAEs позволяют легко манипулировать предложениями, используя соответствующие компактные векторные представления (например, гладкую регуляризацию признаков, заданную предыдущими распределениями) и управляемую генерацию предложений с интерпретируемыми латентными векторными операторами. Несмотря на привлекательные теоретические преимущества, текущий язык VAEs часто строится с неглубокими сетевыми архитектурами, такими как двухслойные LSTMs. Это ограничивает возможности модели и приводит к неоптимальной производительности. Когда дается большое количество данных, уловки DGM могут сломаться, если используется неглубокий VAE.
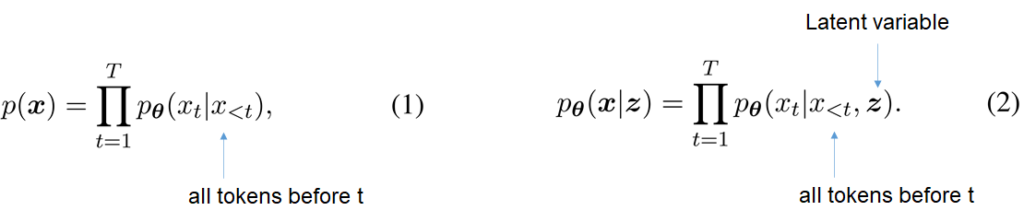
Для длинного предложения Т, икс = [ x i ..., x T], авторегрессионный NLM генерирует текущий токен xt обусловленный предыдущими лексемами слова икс<т как показано в уравнении 1 выше, существует ограниченная способность для генерации руководствоваться семантикой более высокого уровня. GPT-2, пожалуй, самый известный экземпляр NLM, предварительно обученный на больших объемах текста. В отличие от этого, Ваэ генерирует xt обусловлены оба предыдущих лексемы слова икс<т и скрытая переменная зет, как показано в уравнении 2 выше. Латентное состояние зет определяет семантику высокого уровня (то есть” контур") предложения, такого как время, темы или настроение, направляя последовательный процесс декодирования для заполнения деталей контура. Декодер ? совмещено с шифратором ?. VAEs изучают параметры, максимизируя нижнюю границу вероятности логарифмирования данных.
![Рис. 2а: оптимальная архитектура, переменная x перемещается через кодер (состоящий из pf BERT и H[CLS]), затем перемещается через переменную Z, затем в декодер (состоящий из переменной H и GPT-2) и, наконец, в переменную x. рис.2b: память: переменная Z перемещается в квадратный блок памяти размером 3 на 4. первый столбец из 3 квадратов-белый. Остальные-синие. Под первым синим столбцом X0, вторым XT минус 1, третьим X с подстрочным индексом T. вложение: переменная Z перемещается через латентное плюс слово плюс позиционное.](https://www.microsoft.com/en-us/research/uploads/prod/2020/04/Generative-Models-Fig-2-300x152.png)
Рисунок 2: а) оптимальная архитектура, состоящая из кодера и декодера, и Б) скрытая векторная инъекция.
Архитектура Optimus показана на рис. 2а.чтобы помочь обучению, мы инициализируем кодер с помощью BERT и инициализируем декодер с помощью GPT-2. Выходной признак токена [CLS] используется для получения скрытой переменной зет. Чтобы облегчить зет при декодировании GPT-2 без повторного обучения весов с нуля мы изучаем две схемы, иллюстрированные на рис. 2Б. в первой схеме, зет играет роль дополнительного вектора памяти для декодера, чтобы присутствовать. Во второй схеме, зет добавляется на нижний слой встраивания декодер и непосредственно используется в каждом шаге декодирования. Эмпирически мы обнаружили, что первая, основанная на памяти схема работает лучше. Чтобы предотвратить печально известную проблему исчезновения KL, мы используем циклический график отжига и методы размерного порога. Как новый тип PLM, предложенный Optimus показывает интересные результаты, демонстрируя свои уникальные преимущества по сравнению с существующими PLMs:
- Языковое моделирование-мы рассматриваем четыре набора данных , включая Penn Treebank , SNLI , Yahoo и Yelp corpora, и уточняем PLM для одной эпохи на каждом. Optimus достигает меньшего недоумения, чем GPT-2 на трех из четырех наборов данных, из-за знания, закодированного в латентном априорном распределении. По сравнению со всеми существующими малыми VAEs, Optimus показывает гораздо лучшую производительность обучения представления, измеренную взаимной информацией и активными единицами . Это означает, что предварительная подготовка сама по себе является эффективным подходом к решению проблемы исчезновения KLM.
- Управляемая генерация языка-благодаря скрытой переменной Optimus имеет уникальное преимущество для управления генерацией предложений с семантического уровня (GPT-2 для этого неосуществимо). Он предоставляет новые способы, которыми можно играть с генерацией языка. На рисунке 3 (ниже) мы проиллюстрируем эту идею, используя некоторые простые латентные векторные манипуляции в двух сценариях: 1) передача уровня предложения через арифметическую операцию латентных векторов: z? = z1 * (1 – ?) + z2 * ? и 2) интерполяция предложений: zD = zB – zA + zC, где ? ? [0,1]. Для более сложной скрытой манипуляции пространством мы рассматриваем генерацию диалогового ответа, генерацию стилизованного ответа и генерацию условного предложения с меткой. Оптимус демонстрирует превосходство над существующими методами по всем этим задачам.
- Понимание языка с низким ресурсом- Optimus изучает более гладкое пространство и более разделенные шаблоны объектов, чем BERT (рисунок 4a и 4b ниже). Это позволяет Optimus обеспечить лучшую производительность классификации и более быструю адаптацию, чем BERT, при использовании в качестве функционального подхода (магистральная сеть замораживается и обновляется только классификатор), поскольку это позволяет Optimus поддерживать и использовать латентную структуру, изученную в ходе предварительного обучения. На рис. 4c показаны результаты с различным числом помеченных образцов для каждого класса в этом наборе данных Yelp review, Optimus показывает гораздо лучшие результаты в сценариях с низким уровнем вычислений (настройки на основе функций). Аналогичное сравнение наблюдается и на клей-бенчмарке.
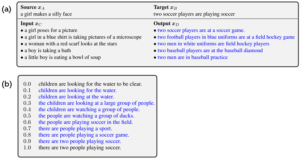
Рисунок 3: а) передача предложений; б) интерполяция предложений. Синий цвет обозначает сгенерированные предложения.
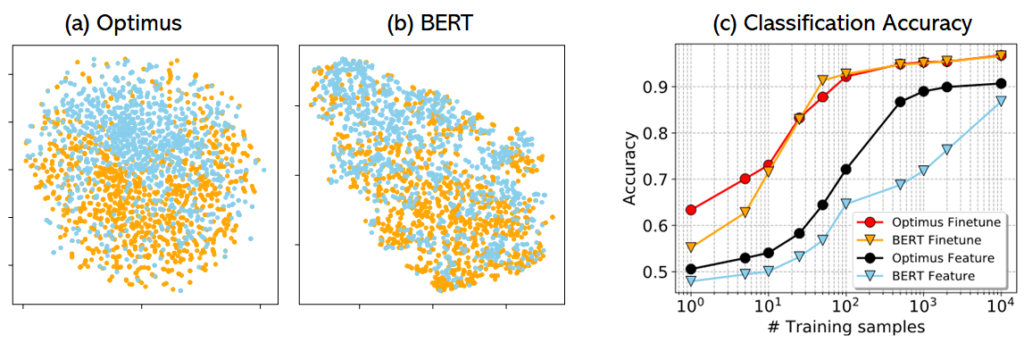
Рисунок 4: (А) и (Б) визуализация пространства признаков с использованием tSNE для Optimus и BERT, соответственно. Предложения с различными метками отображаются в разных цветах. c) результаты с различными маркировочными данными
Пожалуйста, проверьте нашу статью для получения дополнительных результатов, и играть с Optimus на Github
FQ - GAN: проблемы в создании изображений
GAN-популярная модель для генерации изображений. Он состоит из двух сетей-генератора для непосредственного синтеза поддельных образцов, имитирующих реальные образцы, и дискриминатора для различения реальных образцов (x) и поддельные образцы (x^). Эти две сети обучаются в состязательном порядке, чтобы поддельное распределение данных могло соответствовать реальному распределению данных.
Сопоставление признаков-это принципиальный метод, который переводит задачу сопоставления распределения данных GANs в задачу сопоставления распределения в пространстве признаков дискриминатора. Это требует, чтобы статистика признаков (моменты первого или второго порядка), оцененная из совокупности как поддельных, так и реальных выборок, была сходной. На практике эти статистические данные объектов оцениваются с помощью мини-пакетов в непрерывном пространстве объектов. Поскольку набор данных становится намного больше и сложнее (например, с более высоким разрешением), качество оценки на основе мини-пакетов становится плохим, поскольку дисперсия оценки велика для фиксированного размера пакета. Эта проблема является особенно серьезной для GANs, так как индуцированное поддельное выборочное распределение генератора всегда изменяется при обучении, что создает новую проблему в масштабировании GANs для крупномасштабных настроек.
Для решения этой проблемы мы предлагаем квантование признаков (FQ) для дискриминатора, в нашей статье “квантование признаков улучшает обучение GAN”, которое представляет изображения в квантованном пространстве, а не в непрерывном пространстве. Нейросетевая архитектура FQ-GAN показана на рис. 5а.шаг FQ вводится в дискриминатор стандартных GANs. Он ограничивает непрерывные объекты заданным набором значений, в частности центроидами объектов из словаря.
Поскольку как истинные, так и ложные образцы могут выбирать свои представления только из ограниченных элементов словаря, FQ-GAN косвенно выполняет сопоставление объектов. Это можно проиллюстрировать с помощью примера визуализации на рис. 5b, где показаны истинные объекты (h) и поддельные функции h~ квантованы в те же центроиды (ближайшие центроиды представлены в том же цвете в этом примере). Мы используем обновления скользящей средней для реализации развивающегося словаря Е , что гарантирует, что словарь содержит набор центроидов, которые согласуются с последними функциями в обучении.

Рисунок 5: (a) архитектура FQ-GAN: наш FQ добавлен как новый слой в дискриминаторе стандартных GANs. и (b) поиск словаря как неявного сопоставления объектов. Точки одного цвета представляют собой непрерывные объекты, которые квантованы в один и тот же центроид (представленный большими кругами). Истинные объекты (квадрат) и поддельные объекты (треугольник) вынуждены совместно использовать один и тот же центроид после FQ.
Предложенная методика FQ может быть легко подключена к существующим моделям GAN, с небольшими вычислительными затратами в обучении. Обширные экспериментальные результаты показывают, что предложенный FQ-GAN может улучшить качество формирования изображений базовых методов с большим запасом по различным задачам, включая три репрезентативные модели GAN по девяти критериям:
- BigGAN для генерации изображений . BigGAN, представленный Google DeepMind в 2018 году, является, пожалуй, самой большой моделью GAN,мы сравниваем FQ-GAN с BigGAN на трех наборах данных (с увеличением числа классов или изображений): CIFAR 10 , CIFAR 100 и ImageNet . FQ-GAN последовательно превосходит BigGAN более чем на 10% в отношении значений FID (несходство статистики признаков между истинными и поддельными данными). Наш метод также улучшает двойные вспомогательные классификаторы GAN, последний вариант, появляющийся в NeurIPS 2019, который особенно благоприятствует мелкозернистым наборам данных изображений.
- StyleGAN для синтеза лица. StyleGAN, представленный NVIDIA в декабре 2018 года, может генерировать высококачественные изображения, которые выглядят как портреты лиц человеческих лиц (подумайте о глубокой подделке ). Он построен на прогрессивных GANs, но дает исследователям больше контроля над конкретными визуальными особенностями. Мы используем набор данных FFHQ, с разрешением изображения в диапазоне от 32 до 1024. Результаты показывают, что FQ-GAN сходится быстрее и дает лучшую конечную производительность.
- U-GAT-это приложение для бесконтрольного преобразования изображений в изображения. U-GAT-это современный метод передачи стиля изображения, который появился на ICLR 2020 . На пяти контрольных наборах данных мы видим, что FQ в значительной степени улучшает производительность и показывает лучшую оценку восприятия человека.
Если вы хотите улучшить свои GANs с помощью FQ, ознакомьтесь с нашей бумагой и кодом на GitHub.
Распространенный: приложения для навигации по зрению и языку
При дальнейшем понимании образов и языка на семантическом уровне естественным следующим шагом является наделение агента способностью предпринимать действия для выполнения задачи с мультимодальными входными данными. Обучение навигации в визуальной среде, следуя инструкциям на естественном языке, является одной из основных задач на пути к этой цели. В идеале, мы хотели бы обучить универсальный агент один раз и позволить ему быстро адаптироваться к различным нижестоящим задачам.
С этой целью мы предлагаем превалирующий, первый агент, который следует парадигме предварительной подготовки и тонкой настройки. Мы представляем нашу предварительную выборку данных в виде триплета (изображение-текст-действие) и предварительно обучаем модель с двумя целями: моделирование маскированного языка и прогнозирование действий (как показано на рисунке 6a ниже). Поскольку не ставится никаких конечных целей последующего обучения, такой подход к самостоятельному обучению часто требует большого количества обучающих выборок для выявления внутренней сущности данных изображения-текста, чтобы хорошо обобщить их на новых задачах.
В нашем исследовании, подробно описано в нашей статье “к изучению универсального агента для видения и язык навигации через предпродажную подготовку”, мы обнаружили, что наибольший обучающий набор данных, Р2Р, содержит только 104,000 образцы, порядок величины меньше, чем предварительная подготовка данных обычно используется в языке или видение и язык предпродажную подготовку. Это приводит к тому, что предварительная подготовка может быть ухудшена из-за недостаточных учебных данных, в то время как сбор таких образцов с человеческими аннотациями является дорогостоящим.
К счастью, мы можем прибегнуть к DGM для синтеза образцов. Сначала мы обучаем авторегрессионную модель (модель говорящего), которая может создавать языковые инструкции, обусловленные траекторией агента (последовательность действий и визуальных образов) на наборе данных R2R. Затем мы собираем большое количество кратчайших траекторий с помощью 3D-симулятора Matterport и синтезируем соответствующие им инструкции с помощью модели динамика. Это приводит к 6482 000 новых учебных образцов. Эти два набора данных сравниваются на рис. 6b. агент предварительно обучается на объединенном наборе данных.
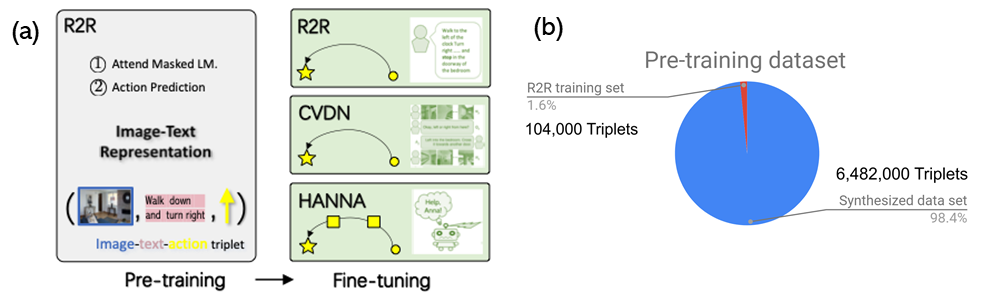
Рис. 6: а) преобладающий конвейер обучения: агент предварительно обучается на сильно дополненном наборе данных R2R и настраивается на три нижестоящие задачи; б) процентное соотношение наборов данных предварительной подготовки: 98,4% синтезированных данных и 1,6% реальных данных.
Мы настраиваем агент на три нисходящие навигационные задачи, включая R2R и две внетоменные задачи, CVDN и HANNA . Наш агент достигает самых современных на всех трех задачах. В конечном счете, превалирование показывает, что синтезированные образцы, полученные с помощью DGM, могут быть использованы для предварительной подготовки, и они улучшают обобщение. Пожалуйста, прочитайте наш документ CVPR 2020 для получения более подробной информации. Мы выпустили нашу предварительно подготовленную модель, наборы данных и код для превалирования на GitHub . Мы надеемся, что он сможет заложить прочную основу для будущих исследований в области самоконтроля предварительной подготовки для зрения и языка навигации.
Движение вперед: новые приложения, комбинирование методов и самостоятельное обучение
Из приведенных выше примеров мы увидели возможности , проблемы и приложения в процессе масштабирования как наборов данных , так и подготовки кадров для СГД. По мере дальнейшего развития этих моделей и увеличения их масштаба мы можем рассчитывать на синтез высококачественных изображений или языковых образцов. Это само по себе может найти новые приложения в различных областях, таких как синтез художественного изображения или диалог, ориентированный на решение задач. Между тем, границы этих трех типов моделей могут быть легко размыты: исследователи могут суметь объединить свои сильные стороны для дальнейшего совершенствования. Уловки DGMs, естественно, подразумевают обещание самоконтроля обучения : в то время как сети учатся кодировать процесс генерации (частично) наблюдаемых данных, они могли бы научиться понимать суть данных, производя хорошие функции, обычно полезные для многих задач.
Подтверждения
Авторы с благодарностью благодарят всю команду проекта Philly внутри Microsoft за предоставление нашей вычислительной платформы. Некоторые реализации в наших экспериментах зависят от open-source проектов на GitHub: Huggingface Transformers , BigGAN , StyleGAN , U-GAT-IT , Matterport3d Simulator , Speaker-Follower . Мы признаем всех авторов, которые сделали свой код общедоступным, что чрезвычайно ускоряет наш прогресс.
Телеграм: t.me/ainewsline
Источник: www.microsoft.com