Finding Users Who Act Alike: Transfer Learning for Expanding Advertiser Audiences
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-16 15:35
Авторы статьи предлагают решение задачи Lookalike — задача поиска похожей аудитории.

Контекст
Рекламодатель при настройке таргетинга своего объявления может задать seed множество пользователей (например, множество пользователей, которые уже кликали на его объявления), и запустить объявление на пользователей, которые похожи на seed.
Один из самых простых способов решить поставленную задачу это сведение к задаче бинарной классификации.
При такой постановке задачи для каждой seed аудитории обучается отдельный классификатор обученный на фичах пользователей.
Позитивные примеры - seed. Негативные примеры - случайные пользователи или пользователи, которые видели объявление, но не кликнули.
Основные проблемы данного подхода состоят в том, что
- он плохо работает в случае небольшого seed’а,
- обучение отдельного классификатора для каждой аудитории может быть довольно затратно.
В статье предлагают решение лишенное перечисленных недостатков.
Как решают?
Решение состоит из двух компонент:
- Обучение эмбеддингов пользователей и объектов на данных об активности пользователя на сайте
- Locality Sensitive Hashing — случайное разбиение пространства эмбеддингов на регионы и подсчет числа seed пользователей в каждом регионе. Расширение seed’a начинается с густонаселенных регионов.
Предложенное решение не требует обучения отдельных классификаторов для каждой аудитории.
Рассмотрим подробнее каждую из компонент решения.
Эмбеддинги пользователей
Авторы статьи предлагают способ построения эмбеддингов для пользователей и объектов используя информацию о пользовательской активности на сайте (что пользователь смотрел, на что кликали и так далее).
Данные для обучения
Пользователь представлен в виде набора dense и sparse фичей. Кроме того, с пользователем связан список sparse фичей переменной длины (например, список интересов пользователя).
Пин представлен в виде набора категорий (topics). Если с пином связано больше одной категории, то пин используется для обучения несколько раз.
Модель
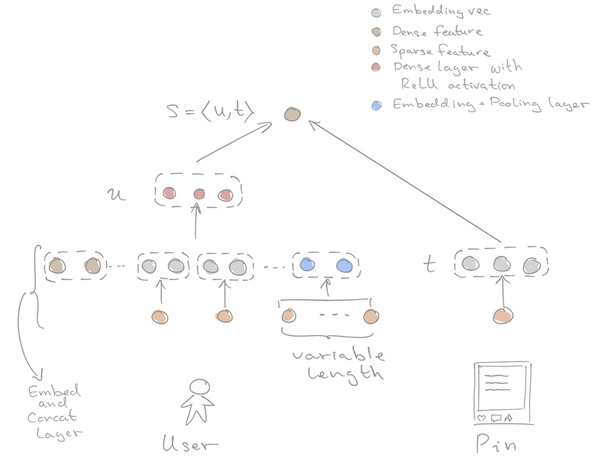
Модель обучается на истории активности пользователей. Если пользователь u взаимодействовал с топиком t, то пара (u, t) будет позитивным примером.
На каждый позитивный пример генерируется несколько негативных примеров.
Важной особенностью данного метода является то, что эмбеддинги строятся из фичей, а не из object_id (user_id, topic_id) как, например, в word2vec, поэтому даже для нового пользователя/пина можно легко получить эмбеддинг, следовательно модель не нужно часто переобучать.
Обученные эмбеддинги можно использовать для решения задачи расширения аудитории.
Расширение аудитории
Seed множество пользователей можно рассматривать как множество эмбеддингов.
Существующие решения
Для поиска похожих пользователей можно усреднить вектора seed пользователей и ранжировать кандидатов по похожести на полученный центроид, но это плохой способ, так как seed чаще всего состоит из кластеров пользователей, и центроид будет далеко от всех кластеров.
Еще один вариант расширения seed состоит в том, чтобы для каждого пользователя-кандидата посчитать суммарную похожесть на пользователей из seed’a. После чего кандидатов можно отранжировать по полученным значнениям.
Но если seed очень большой, то расчитывать похожести может быть очень долго.
Предлагаемое решение
В статье решают описанные выше проблемы с помощью представления seed множества эмбеддингов в виде вектора фиксированной длинны.
В основе предлагаемого решения лежит LSH (Locality Sensitive Hashing).
Для того чтобы представить seed множество в виде вектора, сначала пространство эмбеддингов разбивается на непересекающиеся регионы с помощью n случайных гиперплоскостей, затем для каждого из 2^n регионов считаем, сколько в него попало пользователей из seed множества.
Получаем вектор размера 2^n, который описывает seed.
Полученный вектор можно использовать для расширения аудитории. В статье рассматривают два метода: Simple voting и Density voting
Simple voting
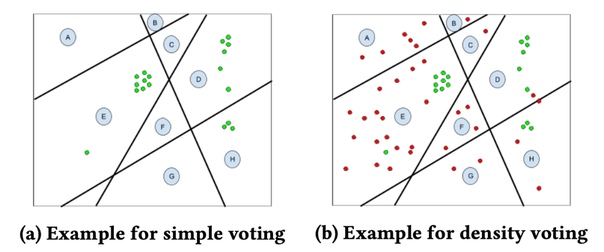
Интуиция: расширение аудитории нужно начинать с тех регионов, в которых оказалось больше всего пользователей из seed множества.
Имея разбиение на регионы и seed множество s, пользователю-кандидату u можно поставить в соответствие число score(u, s) — количество пользователей из s, которые находятся в том же регионе что и пользователь u. Для расширения аудитории, кандидатов нужно отсортировать по убыванию скоров.
Недостатком данного метода является то, что он игнорирует распределение non-seed пользователей. Так, например, среди non-seed пользователей скорее всего намного больше пользователей, которые интересуются рецептами еды, чем пользователей, которые интересуются Data Science. В результате, в расширенную аудиторию пападет больше пользователей интересующихся рецептами, что может быть нежелательно.
Метод Density Voting решает данную проблему.
Density voting
Скоры score(u,s) нормализуются на общее число пользователей, которые находятся в одном регионе с пользователем u.
Таким образом, используя случайное разбиение пространства на регионы мы можем решить задачу расширения аудитории.
Для того чтобы результат был более устойчивым авторы предлагают выполнять случайное разбиение и считать скоры несколько раз, и итоговый скор для пользователя — это сумма скоров по всем разбиениям.
За этим решением скрывается следующая интуиция: если пользователь сильно похож на seed пользователей, то почти при любом случайном разбиении пространства эмбеддингов у него будет большой скор.
Преимущества предложенного решения
- Обученная модель построения эмбеддингов универсальна и может быть использована для решения разных задач.
- Нет необходимости в обучении отдельных классификаторов для каждой seed аудитории, так как эмбеддинги пользователей и случайные разбиения зафиксированы.
Мое мнение
- В статье кратко описана вся end-to-end система работы lookalike’a в Pinterest, основанная на предложенном решении. Довольно интересно почитать и о решение инженерных задач связанных с внедрением предложенного решения в продакшн окружение.
- На мой взгляд, метод построения эмбеддингов можно улучшить если в качестве фичей пина использовать не только связанные с ним топики, но и другие контентные фичи.
- Немного странным выглядит выбор критерия останова при обучении эмбеддингов.
Телеграм: t.me/ainewsline
Источник: m.vk.com