Data Science, финансы и доброта.
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-04-30 15:03
1. Машинное обучение и финансы
Machine Learning - подмножество науки о данных (Data Science) и более глобальной области – Artificial Intelligence.
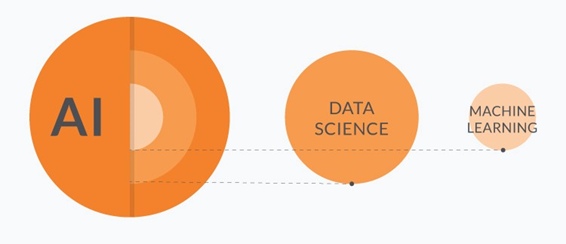
ML использует различные статистические модели, чтобы снискать озарение, опираясь на накопленную информацию, и сделать необходимые прогнозы или выводы.
Курс Data Science от SF Education: http://bit.ly/2CEL845
Самое интересное в методах ML это то, что машина учится на собственном опыте, точно также, как мы с Вами. Проще говоря, для решения задачи с помощью методов машинного обучения необходимо выбрать некоторую модель и «накормить» ее данными. Затем модель автоматически будет корректировать свои параметры для улучшения результатов. Чем больше информации Вы дадите системе, тем точнее будет ее работа.
Примечание. Вообще-то, это не совсем так. Не во всех алгоритмах Machine Learning происходит обучение, но доля таких методов очень велика!
Именно поэтому алгоритмы машинного обучения очень популярны в финансовой индустрии: финансовый сектор может предоставить петабайты информации о транзакциях, клиентах, счетах, денежных переводах и так далее. А главное, результат обработки этой информации есть где применить, и финансовые компании (банки, инвестиционные фонды и проч.) активно это делают!
Какие возможности может дать ML финансовым учреждениям?
- Автоматизация процессов
Многие последовательные действия сотрудников можно автоматизировать, тем самым повысив производительность. Это позволяет компаниям оптимизировать затраты, улучшать качество обслуживания клиентов и расширять спектр услуг.
Примеры технологий:
· Chatbots
· Call-центр
· Автоматизация делопроизводства.
- Безопасность
Алгоритмы машинного обучения отлично подходят для выявления мошенничества.
Например, банки используют эту технологию для мониторинга транзакций в режиме реального времени. Алгоритм проверяет каждое действие, предпринимаемое владельцем карты, и оценивает, является ли попытка действия характерной для данного конкретного пользователя. Если система идентифицирует подозрительное поведение учетной записи, то она может запросить у пользователя дополнительную идентификацию для подтверждения транзакций. Такой подход позволяет не просто обнаружить неправомерные действия, но и предотвратить мошенничество.
- Алгоритмический трейдинг
Машинное обучение помогает принимать более взвешенные решения. Математическая модель отслеживает новости и результаты торгов в режиме реального времени и выявляет закономерности, которые могут заставить цены акций повышаться или понижаться. Возможность анализировать одновременно множество источников информации и «смотреть» на данные в связке делает алгоритмы ML незаменимым инструментом для игроков биржи.
2. Погружение в аналитику
Давайте немного глубже погрузимся в мир аналитики и поподробнее посмотрим на методы и алгоритмы, которые не просто можно, а нужно применять для Ваших компаний. И чем скорее, тем лучше!
А/В тестирование
A / B-тестирование или сплит-тестирование – это особый метод сравнения двух версий какого-то эксперимента за определенный период времени. Это может быть интерфейс сайта, различные варианты акции, сравнение рекламных кампаний, UI веб-приложений – все что угодно.
Сравниваются два варианта (A и B). Они схожи по смыслу, но имеют некие отличия, которые могут повлиять на поведение и решение пользователей. Например, у Вас есть действующий сайт компании, и Вы решаете, что нужно бы его обновить для привлечения большей аудитории. Вариант А – версия, которая есть сейчас, а версия B имеет аспект, который был изменен (например, добавили уведомление о получении скидки на услуги компании после прохождения небольшого теста).
В итоге, одни пользователи будут видеть исходную версию (А), а другие – измененную (В). Через некоторый промежуток времени (срок проведения тестирования зависит от многих факторов, например, от конверсии, посещаемости и предмета тестирования) можно сравнить результаты и определить, влияют ли внесенные изменения на количество заказов или нет. Анализ можно основывать на данных, полученных с помощью сервисов веб-статистики – это удобно.
После того, как вы узнаете, был ли ваш тест успешным или нет, вы можете интегрировать выигрышную версию и перейти к следующему тесту уже с другими параметрами анализа.
А/В тестирование является очень мощным способом анализа маркетинга и в финансовой отрасли в том числе: тематические строки электронных писем, заголовки, копия сайта, призывы к действию, формы, графика, реклама и так далее. Финансовая индустрия не одними денежными потоками жива – целые отделы аналитиков, дизайнеров, программистов и маркетологов трудятся на успех и процветание своих компаний. Поэтому A/B тестирование точно найдет применение и в Вашей работе тоже!
Основные преимущества А/В тестирования заключаются в его эффективности и невысокой стоимости эксперимента. Если, конечно, Ваш сайт посещает не 3 человека в день, да и те – боты Гугла… Основные цели, которые позволяет достичь A/B-тест в финансовом маркетинге (да и любом другом):
· Увеличение конверсии. В основном это связано с ростом доли посетителей сайта (можно подсчитывать тех, кто заполняют контактную форму сайта или подписываются на рассылку новостей компании); с увеличением заказов (при предоставлении скидки за подписку, например) и так далее.
· Снижение отказов. A / B-тест позволяет понять, почему посетители не переходят дальше начальной страницы или куда заходят чаще всего.
· Увеличить объем трафика. Путем последовательного тестирования с поэтапным внесением изменений можно создать продукт, полностью отвечающий всем требованиям клиентов. Это увеличит лояльность старых пользователей и привлечет новых.
· Увеличение прибыли. Привлечение новых клиентов обеспечит приток дополнительной прибыли.
Data Mining
Если переводить словосочетание Data Mining дословно, то “раскопка данных”. Часто можно встретить синоним “интеллектуальный анализ данных”.
Data Mining – набор методов выявления закономерностей и шаблонов в больших и несвязанным между собой (на первый взгляд) наборах данных. Это, пожалуй, одна из основных прелестей Data Science: найденные закономерности часто неочевидны. Представьте себе ощущение, когда ты раскопал какую-то крутую штуку, о которой знаешь только ты, и это знание принесет компании несметное богатство… Блаженство, не иначе…
Методы Data Mining основываются на разработках таких наук, как прикладная статистика, распознавание образов, искусственный интеллект, теории баз данных и так далее. Такое многообразие инструментария делает “интеллектуальный анализ данных” многогранным инструментом, используемым в различных областях.
Наиболее широкий набор алгоритмов и методов используется в области исследования финансовых рынков. В него входят различные методы прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка.
Проверка гипотез
Проверка гипотезы - это математическая модель для проверки некого утверждения, некой идеи или гипотезы. Расчеты выполняются для случайных выборок, чтобы получить максимально объективную информацию о характеристиках всей совокупности. Конечно, на практике не получается использовать совсем случайные выборки, но стараются планировать эксперимент так, чтобы минимизировать «предвзятость». Простой пример: если мы будем опрашивать 70-летних мужчин, любят ли кататься на скейтах, а потом сделаем громкое заявление, что «На скейтах никто не катается теперь!» - будем ли мы правы? Конечно нет, потому что наша выборка была слишком узкой для данного опроса.
Примечание. Если среди читателей есть 70-ти летние мужчины на скейте – не принимайте близко к сердцу!
Итак, как это работает?
Мы можем задаваться самыми разными вопросами и искать на них ответы с помощью проверки гипотез. Были бы исходные данные для расчетов… Например: верно ли, что акции компании X растут в цене в среднем более чем на 7% за какой-то период?
Существуют разные методологии для проверки гипотез, но в основе лежат два основных шага:
Шаг 1: Определить нулевую и альтернативную гипотезы
Основная гипотеза – та, которую Вы заведомо считаете верной. Ее еще называют нулевой гипотезой H0.
Альтернативной гипотезой H1 называется гипотеза, противоречащая H0. Для нашего примера:
H0: акции компании X растут в цене в среднем более чем на 7% за какой-то период
H1: акции компании X растут в цене в среднем менее чем на 7% за какой-то период
Шаг 2: Вычисление статистики критерия и вычисление p-value
После постановки задачи исходные данные используются для вычисления статистики критерия. Эта величина как бы «отражает» исходные данные против нулевой гипотезы. Таким образом, по ее значению можно делать выводы о верности нулевой гипотезы.
Всем стандартным статистикам отвечают уже известные из теории распределения вероятностей. Рассчитанное нами значение статистики сопоставляется с нужным распределением для получения так называемого p-value.
Говоря простым языком, p-value – вероятность отвергнуть гипотезу H0, если она окажется верна. Чтобы было наглядно: при постановке задачи мы определяем критическую область (на рисунке – заштрихованная часть). Это те «хвосты» распределения, где наша основная гипотеза будет отвергнута. Расчет p-value, как раз и выдает площадь таких «хвостов». В большинстве компьютерных программ это уже давно делается автоматически, и Вам не придется с этим возиться.
На практике уровень значимости обычно берется 5%, т.е. вероятность отклонить основную гипотезу, если она будет верна – 5%. В финансовом моделировании ситуация такая же.
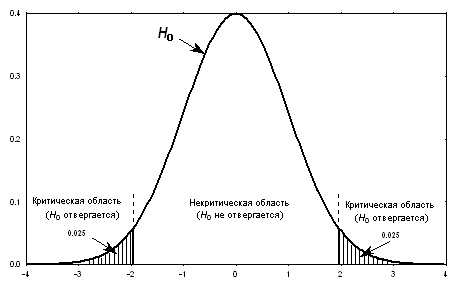
Далее все просто – если полученное значение p-value мало – нулевая гипотеза отвергается (мы попали в ситуацию, когда реальные данные как бы «говорят против» нашей нулевой гипотезы); если велико – не отвергается. После этого шага можно либо продолжать формулировать гипотезу (в нашем примере: проверим, может акции компании X растут в среднем более чем на 3% за период?), либо закончить исследование.
Заключение
Мы лишь поверхностно рассмотрели некоторые моменты такой интересной сферы как аналитика и Data Science, связав их с финансовым сектором. На самом деле, все это намного интересней и глубже – если Вы хотите этим заниматься, то Вас впереди ждет еще целый мир, полный интересных открытий и достижений! Каждый день Вы будете узнавать что-то новое и получать от этого неподдельное удовольствие. Наверно, Вы сможете назвать себя настоящим Data Scientist-ом, когда с утра вместе с чашкой кофе или вечером перед сном Вы будете не листать ленту новостей, а читать, что новенького произошло за день в профессиональном комьюнити: какое исследование провел тот парень из Google, какие изменения внесли в Вашу любимую библиотеку или какой конкурс запустили на Kaggle. Data Science – любовь. А Data Science + финансы… ну, это уже совсем серьезно…
Телеграм: t.me/ainewsline
Источник: m.vk.com