Предсказание спроса с точки зрения бизнеса
Предсказание спроса — один из ключевых инструментов для функционирования процессов в компаниях из FMCG, QSR (рестораны быстрого питания) и ритейла. На примере ритейла при повышении точности прогнозирования значительно повышается эффективность таких процессов, как:
- финансовое планирование и целеполагание;
- управление ассортиментом;
- ценообразование и планирование промо;
- оптимизация товарных запасов на всех узлах логистической цепи;
- открытие новых точек.
Глубокий анализ данных позволяет получить дополнительную информацию для поддержки принятия решений:
- найти различия в структуре спроса между торговыми точками и объединить их в кластеры со схожей структурой;
- понять, какие потребности являются ключевыми для покупателя, и сформировать дерево принятия решений;
- выделить товары, по которым будет формироваться восприятие бренда, и товары, которые могут генерировать дополнительную прибыль;
- определить эффективные и неэффективные промо-механики;
- учитывать такие кросс-эффекты, как каннибализация и гало.
Предсказания можно осуществлять в различных разрезах, что дает возможность рассчитать ключевые бизнес-показатели:
- розничный товарооборот и валовую прибыль;
- трафик торговой точки;
- средний чек.
Внедрение системы предсказания спроса на базе машинного обучения позволяет сделать первый шаг к построению рекомендательной системы в областях ассортиментного, ценового и промо-планирования за счет скорости расчета прогнозов при возможности задавать различные входные параметры.
Например, на этапе планирования акции менеджер может смоделировать множество сценариев с различными механиками промо и выбрать тот, который будет максимально удовлетворять поставленным KPI.
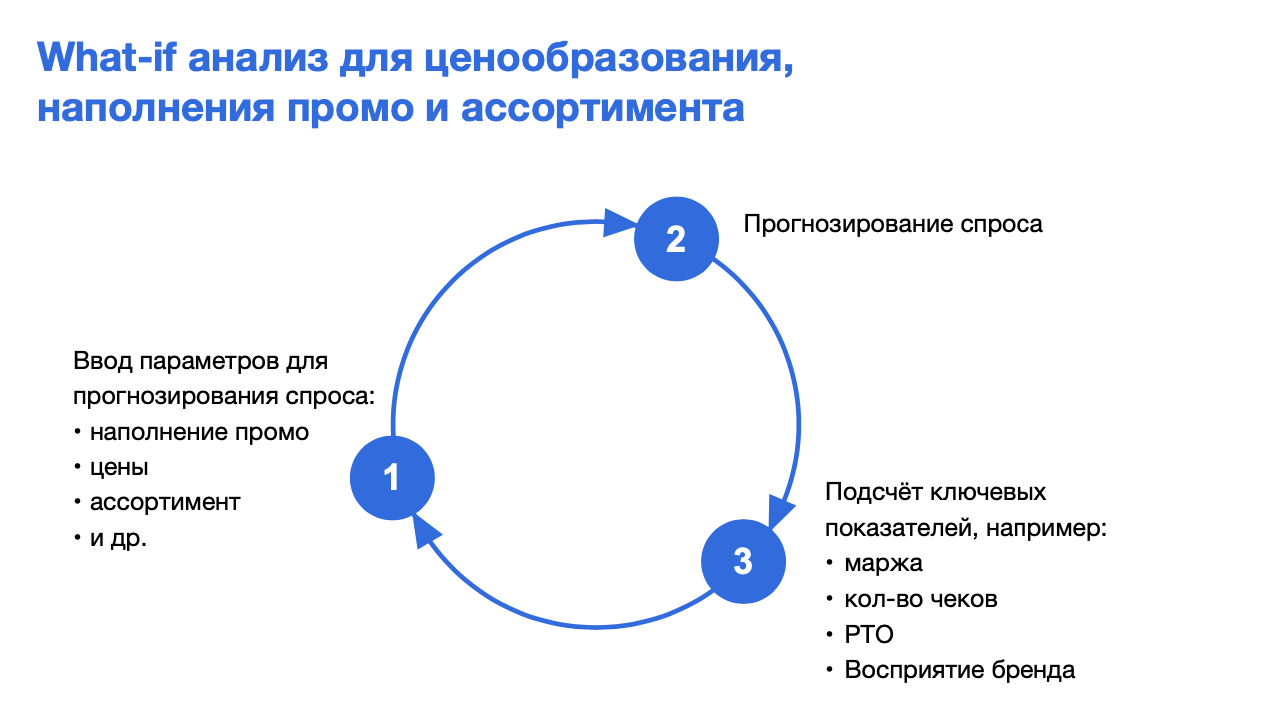
Как работает машинное обучение для предсказания спроса
Для этой задачи используется метод машинного обучения «с учителем». Собираются данные, которые позволяют максимально подробно описать поведение спроса. На их основе формируется набор признаков, который подается на вход в модель машинного обучения. Модель извлекает закономерности между признаками и спросом, которые в дальнейшем используются для формирования прогноза спроса.
Например, можно взять исторические продажи, объединить данные в тройки «товар — магазин — день» и научить модель находить потенциально полезные для прогнозирования сигналы.
Модель не ограничена количеством признаков, но для качественных предсказаний необходимы такие данные:
- продажи и остатки;
- справочники и описания товаров и магазинов;
- данные по изменению цен;
- календарь и описание промо.
Разумный минимум глубины данных — от полутора лет. Данные за год нужны для обучения модели, так как в продажах существуют годовые и циклические закономерности, которые необходимо выявить для повышения качества модели. Остальные данные (отрезки в несколько месяцев) нужно оставить для внутренних экспериментов и тестирования модели и точности ее прогноза.
Какие данные необходимы?
| Критический минимум данных: | Минимум данных: |
|
|
|
|
|
|
При прогнозировании возможно учитывать и внешние данные:
- информацию о конкурентах;
- трафик (сколько людей ходит по улице возле магазина);
- погоду.
Но часто значимость внешних данных сильно переоценена.
Например, при очевидном влиянии погоды на продажи, не существует точного прогноза отрезком дольше двух недель, а если брать средние показатели за 10 лет, то нужно учитывать наличие аномальных случаев жары или холода. Поэтому лучше извлекать максимум пользы из внутренних данных, и тогда модель сама будет вовремя интерпретировать сигналы и улучшать прогноз.
Оценка качества и экономический эффект от прогнозирования
При оценке качества прогнозов принято использовать две ключевые метрики:
- WAPE (взвешенная абсолютная процентная ошибка) — показывает ширину разброса наших прогнозов, учитывая веса товаров в общих продажах;
- BIAS (смещение) — показывает смещение ошибок прогноза в положительную или отрицательную сторону.
При оценке качества прогноза ставится общая цель на уменьшение WAPE и задаются ограничения на BIAS в зависимости от прогнозируемой категории. Например, для скоропортящихся продуктов смещение BIAS в положительную сторону критично, так как это приводит к риску списания товара.
Повышение точности предсказания спроса оказывает прямое влияние на экономический эффект в управлении товарными запасами. Для его оценки сравниваются два модельных сценария — со старым и новым прогнозом. Затем оценивается сокращение влияющих на выручку и валовую прибыль негативных эффектов, вызванных перепрогнозом и недопрогнозом конкретных связок «товар — магазин — период».

Интерпретируемость прогнозов
Распространена ситуация, когда бизнес-пользователи не принимают результаты модели, несмотря на кажущееся повышение качества предсказания. Отсутствие доверия вызвано тем, что предсказания строятся в «черном ящике» и их сложно интерпретировать с точки зрения бизнес-смысла.
Для интерпретации модели прогнозов можно использовать разные параметры, которые учитываются моделью. Например, это могут быть эластичность по цене, каннибализация, гало-эффект и многие другие.
Эластичность по цене
Учебники по экономике показывают красивую гиперболическую зависимость спроса от цены. На самом деле эта зависимость выглядит скачкообразно. В модель изначально не заложены требования к зависимости спроса от цены, но бизнес-пользователю это интересно.
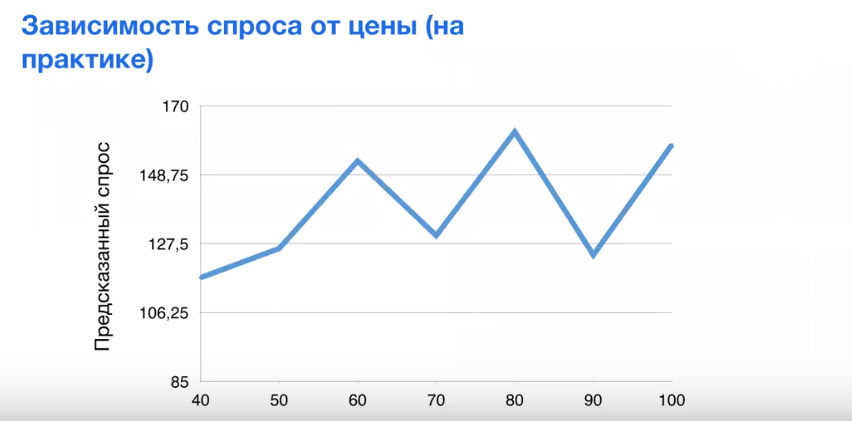
Для этого следует заложить ограничения монотонности по признакам: задать алгоритму условие, при котором он будет искать зависимость спроса по цене.
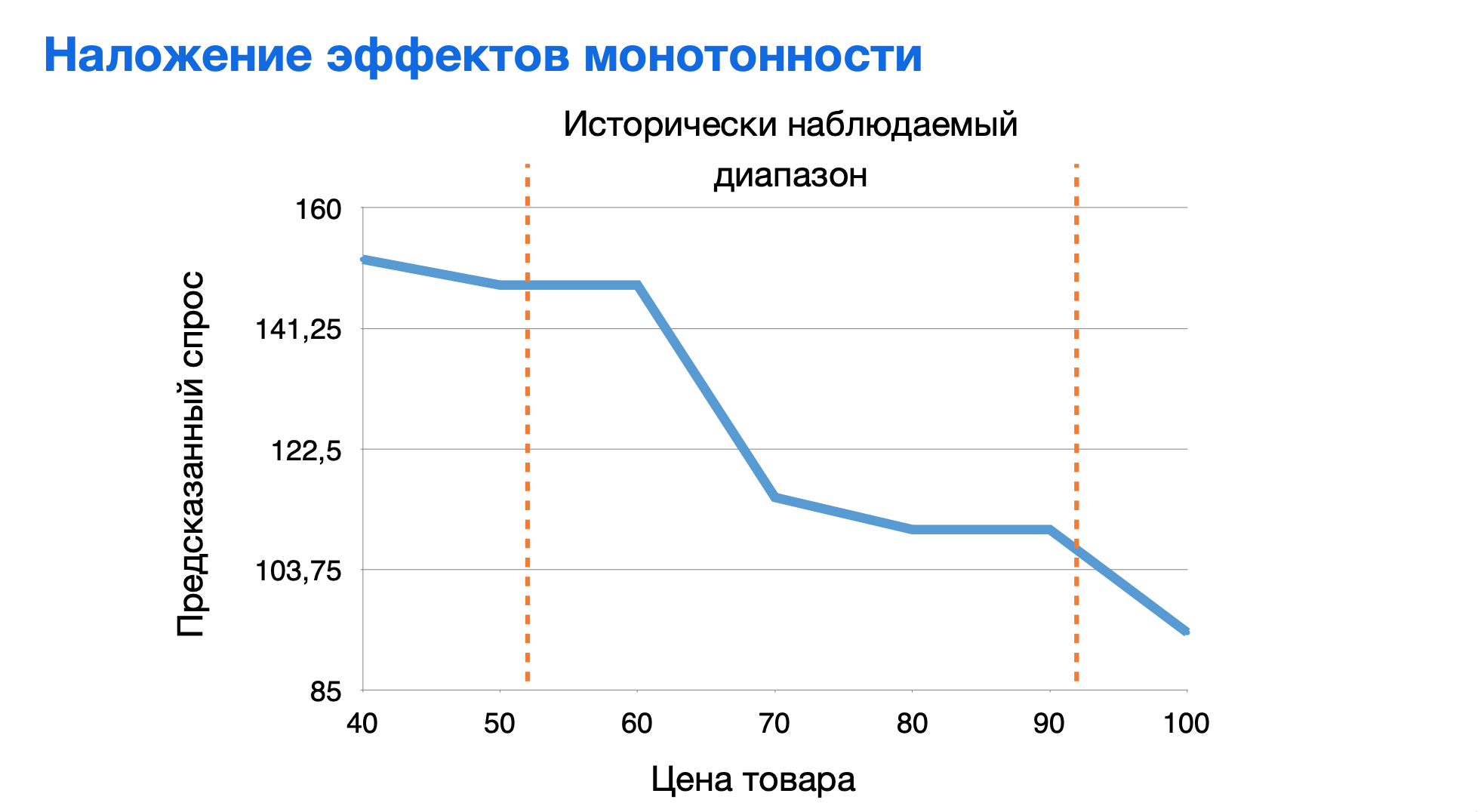
Без потери качества соблюдается монотонность по цене и результат, который выдает модель, совпадает с внутренними ожиданиями пользователя.
Каннибализация
Это сокращение спроса одного товара за счет возросшего спроса на другой товар в аналогичной категории.
Отслеживание каннибализации следует отдельно закладывать в модель, так как для нее не очевидны зависимости спроса двух схожих товаров.
Объем работы зависит от количества товаров. При малом количестве товаров можно настроить матрицу каннибализации вручную. Это требует временных затрат, но результат будет ощутим.
При большом количестве товаров универсального хорошего решения нет. Можно анализировать пользовательские сценарии принятия решений или смотреть различные корреляции товаров по историческим данным.
| Малое количество товаров: | Большое количество товаров: |
|
|
|
|
|
Организация процесса работы
- Работа Data Science команды — итерационный R&D-процесс.Тестируются гипотезы. Модели постоянно улучшаются.
- Отлаженный процесс выпуска новых функций и их проверки. Следует понимать, какие признаки дали эффект.
- Важна инфраструктура работы с данными. Необходимо приводить данные в порядок. Очищать, объединять, форматировать и так далее.
Поддержка моделей
- Модели необходимо регулярно обучать заново. Проверить, как часто следует это делать, можно экспериментально. Далее соблюдаем найденный интервал без потери качества прогноза.
- Необходимо следить за качеством данных и качеством предсказаний. Используем тесты и смотрим сигналы с прогнозов.
- Зачастую требуется развитие моделей. У всех появляются новые желания. Также необходимо оптимизировать метрики качества и модели.
Выводы
- Машинное обучение дает существенный прирост в качестве прогнозирования спроса.
- Надо быть готовым тратить много усилий на формализацию того, что такое хороший и плохой прогноз в каждом конкретном бизнесе.
- Модели должны не только качественно прогнозировать, но и быть интерпретируемыми бизнес-пользователями.
Как получить максимум?
- Необходимы данные глубиной от 1,5 лет. Также есть критический минимум данных — это справочник товаров, исторические продажи, исторические цены и промо.
- Требуется постоянная корректировка метрик. Нельзя зацикливаться на одном текущем понимании метрики. Следует улучшать алгоритм в сторону метрики, а метрику — в сторону идеального направления.
- Необходимо работать с обратной связью. Непрерывно собирать гипотезы от бизнес-пользователей, менеджеров и технических специалистов.
- Нужно грамотно организовывать работу на проекте. Приводить данные в порядок. Тестировать гипотезы. Оценивать, какие признаки дают эффект, и постоянно улучшать модели.
Фото на обложке: Shutterstock / ZoneCreative