Transformer нейросеть распознает текст на изображениях
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-22 17:19

Transformer-OCR — нейросетевая модель, которую обучили распознавать надписи на изображениях. Модель обходит существующие state-of-the-art методы на 5 датасетах. Для датасета с изображениями вывесок с закрученным текстом CUTE модель обходит предыдущие подходы на 9.7% в точности предсказания.
Описание проблемы
Распознавание текста на изображении сцены — это комплексная задача из-за разнообразия форм, шрифтов, цветов и заднего фона текста. Большинство существующих алгоритмов нормализуют входное изображение и рассматривают задачу как предсказание последовательности. Ограничением такого подхода является нормализация изображения. Она приводит к ошибкам из-за искажения перспективы сцены. Чтобы обойти это ограничение, исследователи предлагают Transformer-OCR. Модель использует декодер из трансформера, чтобы декодировать сверточное внимание. Нейросеть использует сверточные карты признаков, как эмбеддинги слов на входе в трансформер. Такой дизайн модели позволяет использовать преимущество механизма внимания в трансформере.
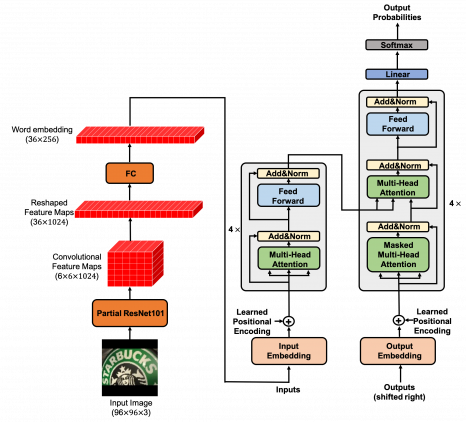
Архитектура модели
Transformer-OCR состоит из двух модулей:
- Модуль для извлечения карт признаков из входного изображения;
- Модуль с трансформером, который принимает на вход карты признаков, по аналогии с входными эмбеддингами слов
Блок с извлечением признаков состоит из первых четырех слоев ResNet-101. В свою очередь, трансформер состоит из энкодера и декодера, в каждом из которых по 4 идентичных слоя.
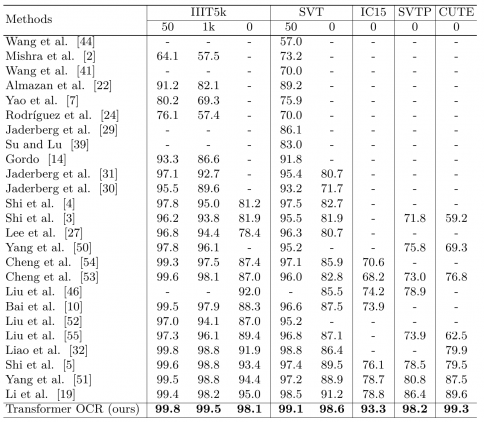
Оценка работы модели
Исследователи сравнили работу модели с state-of-the-art предыдущими подходами для распознавания текста на изображении, которые основывались на архитектуре Transformer. В качестве тестовых данных использовали 5 датасетов: IIIT5k, SVT, IC15, SVTP и CUTE. Предложенная модель обходит все существующие Transformer-модели на этой задаче. Исследователи отмечают, что это связано с тем, что предыдущие подходы не используют энкодер трансформера для кодирования сверточных карт признаков. Они предполагают, что кодировщик в трансформере является ключевым для кодирования пространственных признаков.
Телеграм: t.me/ainewsline
Источник: neurohive.io