
С помощью этого руководства мы с помощью Keras, TensorFlow и глубокого обучения научимся на собранном вручную датасете из рентгеновских снимков автоматически определять COVID-19.
Как и многие другие, я искренне беспокоюсь относительно COVID-19. Я заметил, что постоянно анализирую своё состояние и гадаю, подхвачу ли болезнь и когда это произойдёт. И чем больше я об этом беспокоюсь, тем больше это превращается в болезненную игру разума, в которой симптоматика сочетается с ипохондрией:
- Я проснулся утром, чувствуя некоторую болезненность и слабость.
- Когда я выполз из кровати, то обнаружил у себя насморк (хотя уже известно, что насморк не является симптомом COVID-19).
- К тому времени, как я добрёл до ванной, чтобы взять бумажный платок, я уже кашлял.
Сначала я не обращал на это особого внимания — у меня аллергия на пыльцу, а из-за тёплой погоды на восточном побережье США весна в этом году выдалась ранняя. Скорее всего, это аллергические симптомы. Но в течение дня моё состояние не улучшалось. Я сижу и пишу это руководство с градусником во рту. Смотрю вниз и вижу 37,4 °С. Моя нормальная температура тела чуть ниже, чем у других, на уровне 36,3 °С. Всё, что выше 37,2 °С, для меня уже небольшой жар.
Кашель и небольшой жар? Это может быть COVID-19… или просто моя аллергия. Выяснить без тестирования невозможно, и именно это «незнание» делает ситуацию столь пугающей на человеческом уровне.
Несмотря на мои страхи, я пытаюсь мыслить рационально. Мне немного за 30, я в прекрасной форме, а мой иммунитет силён. Посажу себя на карантин (на всякий случай), отдохну и со всем справлюсь. COVID-19 не пугает меня с точки зрения личного здоровья (по крайней мере, я себе это твержу).
Итак, я беспокоюсь о своих пожилых родственниках, включая всех, у кого уже выявлено заболевание, а также тех, кто находится в домах престарелых и больницах. Эти люди уязвимы, и будет ужасно, если они умрут из-за COVID-19.
Вместо того, чтобы ничего не делать и позволять своему недугу держать меня дома (будь то аллергия, COVID-19 или мои страхи), я решил делать то, что могу: напишу код, проведу эксперименты и на практических примерах научу других, как использовать компьютерное зрение и глубокое обучение.
Сразу скажу, что это не самая научная статья, написанная мной. Она вообще не научная. Использованные методы и датасеты не стоят того, чтобы их публиковать. Но они служат начальной точкой для тех, кто хочет хоть чем-то помочь.
Я беспокоюсь за вас и за это сообщество. Я хочу помочь чем могу: эта статья — мой способ мысленно справиться с тяжёлым временем, одновременно помогая другим в схожей ситуации.
Из этого руководства вы узнаете:
- Как собрать opensource-датасет рентгеновских снимков пациентов, у которых выявлена COVID-19.
- Как собрать образцы «нормальных» (без признаков инфекции) рентгеновских снимков здоровых людей.
- Как научить свёрточную нейросеть автоматически определять COVID-19 на рентгеновских снимках из созданного датасета.
- Как оценить результаты с точки зрения обучения.
Примечание: Я уже намекнул на это, но теперь скажу прямо. Описанные здесь методики служат только образовательным целям. Это не строгое научное исследование, оно не будет опубликовано в журналах. Эта статья для читателей, которых интересует компьютерное зрение и глубокое обучение, которые хотят учиться на практике, а также для тех, кто вдохновляется текущими событиями. Прошу вас всё это учитывать.
В первой части руководства мы обсудим, как можно обнаружить COVID-19 на рентгеновских снимках лёгких. Затем обсудим сам датасет. А потом я покажу, как обучить модель с помощью Keras и TensorFlow прогнозировать COVID-19 на наших изображениях.
Пояснение
Эта статья об автоматическом обнаружении COVID-19 написана только для образовательных целей. Она не описывает надёжную и точную систему диагностики COVID-19, не была проверена ни с профессиональной, ни с академической точки зрения.
Моя цель — вдохновить вас и показать, как изучение компьютерного зрения и глубокого обучения с последующим применением этих знаний в медицинской сфере может оказать большое влияние на мир.
Представьте: вам не нужно медицинское образование, чтобы повлиять на медицину. Специалисты-практики по глубокому обучению сегодня тесно сотрудничают с врачами и прочими медиками в решении сложных проблем, спасают жизни и делают мир лучше.
Надеюсь, моё руководство вдохновит вас на это.
Но учитывая всё сказанное, исследователи, кураторы журналов и система рецензирования уже перегружены работами, в которых описываются модели прогнозирования COVID-19 сомнительного качества. Пожалуйста, не отправляйте код и модель из этой статьи в журнал или какое-то научное издание — вы лишь увеличите хаос.
Более того, если вы хотите на основе этой статьи (или любой другой публикации о COVID-19) проводить исследование, то придерживайтесь TRIPOD-руководства по описанию прогнозирующих моделей. Как вы понимаете, применение искусственного интеллекта в медицинской сфере может иметь очень серьёзные последствия. Публикуйте и применяйте подобные модели только в том случае, если вы специалист-медик или если вас подробно консультировали такие специалисты.
Как можно обнаружить COVID-19 на рентгеновских снимках?
Пройти проверку на COVID-19 сейчас сложно — тестов не хватает, а быстро произвести их невозможно, что только усиливает панику. А в условиях паники появляются мерзавцы, которые стараются нажиться на других и продают фальшивые тесты на COVID-19, находя себе доверчивых жертв в соцсетях и мессенджерах. Учитывая ограниченное количество тестов, нам нужно полагаться на другие способы диагностики. Я решил изучать рентгеновские снимки, потому что врачи часто используют их и результаты компьютерной томографии для диагностирования пневмонии, лёгочных воспалений, абсцессов и увеличенных лимфоузлов. Поскольку вирус атакует клетки эпителия, которые выстилают респираторный тракт, мы можем с помощью рентгеновских снимков изучить состояние лёгких человека. А поскольку рентгеновские аппараты есть почти везде, то с помощью снимков можно обнаруживать COVID-19 без тестовых наборов.
К недостаткам метода можно отнести потребность в специалистах-рентгенологах, а также значительную длительность обработки. А время особенно дорого, когда по всему миру болеют люди. И для экономии времени врачей нужно создать систему автоматического анализа.
Примечание: есть более свежие публикации, в которых предполагается, что для диагностирования COVID-19 лучше использовать компьютерную томографию. Но мы будем работать только с рентгеновскими снимками. Кроме того, я не медик, и предполагаю, что есть другие, более надёжные методы определения COVID-19, помимо тестовых наборов.
Датасет снимков пациентов с COVID-19
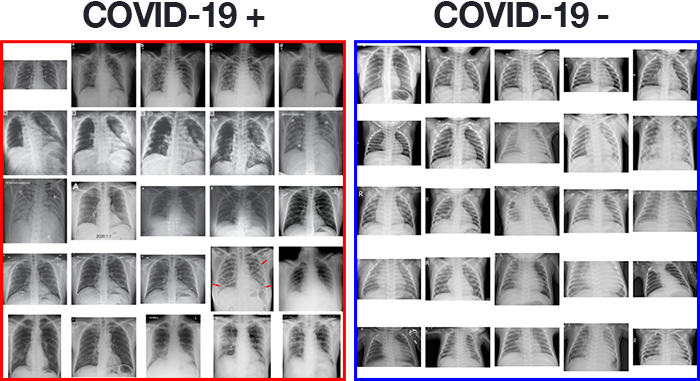
Использованный здесь датасет снимков пациентов с COVID-19 был собран под контролем доктора Джозефа Коэна, аспиранта Монреальского университета. Несколько дней назад Коэн начал собирать рентгеновские снимки больных COVID-19 и выкладывать их в GitHub-репозитории. Там вы найдёте примеры не только этой болезни, но также MERS, SARS и ARDS. Для создания датасета я:
- Отпарсил файл metadata.csv из репозитория.
- Выбрал все строки:
Всего получилось 25 снимков с положительными результатами на COVID-19 (Иллюстрация 2, слева).
Теперь выберем снимки здоровых людей.
Для этого я взял датасет рентгеновских снимков лёгких Kaggle’s (пневмония) и выбрал 25 снимков здоровых людей (Иллюстрация 2, справа). У этого датасета есть ряд недостатков, в том числе плохо или ошибочно заполненные метки, но он годится как начальная точка для проверки гипотезы детектора COVID-19.
В результате я получил 50 снимков: 25 больных COVID-19 и 25 здоровых. Скачать датасет можете по ссылке. Кроме того, я добавил Python-скрипты, с помощью которых сгенерировал датасет, но в этой статье я их не рассматривал.
Структура проекта
Скачайте код и данные. Вытащите оттуда файлы, и вы получите такую структуру директорий:
$ tree --dirsfirst --filelimit 10 . ??? dataset ? ??? covid [25 entries] ? ??? normal [25 entries] ??? build_covid_dataset.py ??? sample_kaggle_dataset.py ??? train_covid19.py ??? plot.png ??? covid19.model Три директории, пять файлов. Датасет лежит в директории dataset/ и разделён на два класса — covid/ и normal/. Ниже мы рассмотрим скрипт train_covid19.py, который обучает наш детектор COVID-19.
Реализация обучающего скрипта
Перейдём к тонкой настройке свёрточной нейросети, которая будет автоматически диагностировать COVID-19 с помощью Keras, TensorFlow и глубокого обучения.
Откройте файл train_covid19.py и вставьте такой код:
# import the necessary packages from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.applications import VGG16 from tensorflow.keras.layers import AveragePooling2D from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import Adam from tensorflow.keras.utils import to_categorical from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from imutils import paths import matplotlib.pyplot as plt import numpy as np import argparse import cv2 import os Этот скрипт использует возможности TensorFlow 2.0 и библиотек Keras посредством выбора импортирований tensorflow.keras. Также мы используем:
- scikit-learn, это де факто Python-библиотека для машинного обучения,
- matplotlib для построения графиков,
- OpenCV для загрузки и предварительной обработки изображений в датасете.
Чтобы узнать, как установить TensorFlow 2.0 (в том числе scikit-learn, OpenCV and matplotlib), почитайте мои руководства для Ubuntu или macOS. Теперь распарсим аргументы для командной строки и инициализируем гиперпараметры:
# construct the argument parser and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required=True, help="path to input dataset") ap.add_argument("-p", "--plot", type=str, default="plot.png", help="path to output loss/accuracy plot") ap.add_argument("-m", "--model", type=str, default="covid19.model", help="path to output loss/accuracy plot") args = vars(ap.parse_args()) # initialize the initial learning rate, number of epochs to train for, # and batch size INIT_LR = 1e-3 EPOCHS = 25 BS = 8 Наши три аргумента для командной строки (строки 24-31) включают в себя:
--dataset: путь ко входному датасету.--plot: опциональный путь к выходному графику истории обучения. По умолчанию график называется plot.png, если в командной строке не задано другое имя.--model: опциональный путь к нашей выходной модели определения COVID-19. По умолчанию она называется covid19.model.
Теперь инициализируем начальную частоту обучения, количество эпох обучения и гиперпараметры размера пакета (строки 35-37).
Далее загрузим и предварительно обработаем рентгеновские снимки:
# grab the list of images in our dataset directory, then initialize # the list of data (i.e., images) and class images print("[INFO] loading images...") imagePaths = list(paths.list_images(args["dataset"])) data = [] labels = [] # loop over the image paths for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the image, swap color channels, and resize it to be a fixed # 224x224 pixels while ignoring aspect ratio image = cv2.imread(imagePath) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = cv2.resize(image, (224, 224)) # update the data and labels lists, respectively data.append(image) labels.append(label) # convert the data and labels to NumPy arrays while scaling the pixel # intensities to the range [0, 1] data = np.array(data) / 255.0 labels = np.array(labels) Для загрузки данных мы берём все пути к изображениям в директории --dataset (строка 42), а затем для каждого imagePath:
- Извлекаем из пути (строка 49) метку класса (covid или normal).
- Загружаем изображение, преобразуем в RGB-каналы и уменьшаем до размера 224х224 пикселя, чтобы подать свёрточной нейросети (строки 53-55).
- Обновляем списки данных и меток (строки 58 и 59).
Затем масштабируем пиксельную интенсивность в диапазон
[0, 1] и преобразуем данные и метки в формат массива NumPy (строки 63 и 64).Далее мы выполним one-hot-кодирование наших меток и разделим датасет на обучающий и тестовый наборы:
# perform one-hot encoding on the labels lb = LabelBinarizer() labels = lb.fit_transform(labels) labels = to_categorical(labels); print(labels) # partition the data into training and testing splits using 80% of # the data for training and the remaining 20% for testing (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42) # initialize the training data augmentation object trainAug = ImageDataGenerator( rotation_range=15, fill_mode="nearest") Унитарное кодирование меток выполняется в строках 67-69: данные будут представлены в таком формате:
[[0. 1.] [0. 1.] [0. 1.] ... [1. 0.] [1. 0.] [1. 0.]] Каждая закодированная таким образом метка состоит из двухэлементного массива, в котором один из элементов является «горячим» (1), а второй «нет» (0). В строках 73 и 74 датасет делится на две части: 80 % для обучения, 20 % для тестирования.
Для обобщения модели мы выполним расширение данных (data augmentation), задав случайный поворот изображений на 15 градусов по часовой стрелке или против неё. Объект генерирования расширения инициализируется в строках 77-79.
Теперь инициализируем модель VGGNet подготовим её к тонкой настройке:
# load the VGG16 network, ensuring the head FC layer sets are left # off baseModel = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3))) # construct the head of the model that will be placed on top of the # the base model headModel = baseModel.output headModel = AveragePooling2D(pool_size=(4, 4))(headModel) headModel = Flatten(name="flatten")(headModel) headModel = Dense(64, activation="relu")(headModel) headModel = Dropout(0.5)(headModel) headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become # the actual model we will train) model = Model(inputs=baseModel.input, outputs=headModel) # loop over all layers in the base model and freeze them so they will # *not* be updated during the first training process for layer in baseModel.layers: layer.trainable = False В строках 83 и 84 создаётся экземпляр нейросети VGG16 с весами, заранее полученными на ImageNet, без полносвязного слоя.
Далее мы создадим полносвязный слой, состоящий из слоёв POOL => FC = SOFTMAX (строки 88-93), и поместим его наверх VGG16 (строка 97).
Теперь заморозим CONV-веса, чтобы только обучался только полносвязный слой (строки 101-102). На этом тонкая настройка завершается.
Теперь мы готовы скомпилировать и обучить нашу модель глубокого обучения:
# compile our model print("[INFO] compiling model...") opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS) model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"]) # train the head of the network print("[INFO] training head...") H = model.fit_generator( trainAug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS) В строках 106-108 компилируется сеть с затуханием скорости обучения и оптимизатором Adam. Учитывая, что это задача двухклассовой классификации, мы воспользуемся loss-функцией бинарной перекрёстной энтропии (binary_crossentropy), а не категориальной перекрёстной энтропии (categorical crossentropy). Для запуска обучения мы вызовем Keras-метод fit_generator и передадим ему наши рентгеновские снимки посредством объекта расширения данных (строки 112-117).
Теперь оценим работу модели:
# make predictions on the testing set print("[INFO] evaluating network...") predIdxs = model.predict(testX, batch_size=BS) # for each image in the testing set we need to find the index of the # label with corresponding largest predicted probability predIdxs = np.argmax(predIdxs, axis=1) # show a nicely formatted classification report print(classification_report(testY.argmax(axis=1), predIdxs, target_names=lb.classes_)) Для этого сначала выполним прогнозирование на основе тестового набора и получим прогнозные индексы (строки 121-125). Затем сгенерируем и выведем с помощью вспомогательной утилиты scikit-learn отчёт о классификации (строки 128 и 129).
Теперь вычислим матрицу неточностей (confusion matrix) для будущей статистической оценки:
# compute the confusion matrix and and use it to derive the raw # accuracy, sensitivity, and specificity cm = confusion_matrix(testY.argmax(axis=1), predIdxs) total = sum(sum(cm)) acc = (cm[0, 0] + cm[1, 1]) / total sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1]) specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1]) # show the confusion matrix, accuracy, sensitivity, and specificity print(cm) print("acc: {:.4f}".format(acc)) print("sensitivity: {:.4f}".format(sensitivity)) print("specificity: {:.4f}".format(specificity)) Здесь мы:
- генерируем матрицу неточностей (строка 133),
- используем эту матрицу для определения точности, чувствительности и специфичности (строки 135-137), а затем выводим все эти метрики (строки 141-143).
Затем для последующего анализа выводим в виде графика в файле историю изменения точности и потерь:
# plot the training loss and accuracy N = EPOCHS plt.style.use("ggplot") plt.figure() plt.plot(np.arange(0, N), H.history["loss"], label="train_loss") plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss") plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc") plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc") plt.title("Training Loss and Accuracy on COVID-19 Dataset") plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend(loc="lower left") plt.savefig(args["plot"]) И в завершение сериализуем модель классификатора tf.keras на диск:
# serialize the model to disk print("[INFO] saving COVID-19 detector model...") model.save(args["model"], save_format="h5") Обучаем наш детектор с помощью Keras и TensorFlow
После реализации скрипта train_covid19.py можем обучить автоматический детектор.
Скачайте исходный код, датасет и предварительно обученную модель. Откройте терминал и выполните команду для обучения детектора:
$ python train_covid19.py --dataset dataset [INFO] loading images... [INFO] compiling model... [INFO] training head... Epoch 1/25 5/5 [==============================] - 20s 4s/step - loss: 0.7169 - accuracy: 0.6000 - val_loss: 0.6590 - val_accuracy: 0.5000 Epoch 2/25 5/5 [==============================] - 0s 86ms/step - loss: 0.8088 - accuracy: 0.4250 - val_loss: 0.6112 - val_accuracy: 0.9000 Epoch 3/25 5/5 [==============================] - 0s 99ms/step - loss: 0.6809 - accuracy: 0.5500 - val_loss: 0.6054 - val_accuracy: 0.5000 Epoch 4/25 5/5 [==============================] - 1s 100ms/step - loss: 0.6723 - accuracy: 0.6000 - val_loss: 0.5771 - val_accuracy: 0.6000 ... Epoch 22/25 5/5 [==============================] - 0s 99ms/step - loss: 0.3271 - accuracy: 0.9250 - val_loss: 0.2902 - val_accuracy: 0.9000 Epoch 23/25 5/5 [==============================] - 0s 99ms/step - loss: 0.3634 - accuracy: 0.9250 - val_loss: 0.2690 - val_accuracy: 0.9000 Epoch 24/25 5/5 [==============================] - 27s 5s/step - loss: 0.3175 - accuracy: 0.9250 - val_loss: 0.2395 - val_accuracy: 0.9000 Epoch 25/25 5/5 [==============================] - 1s 101ms/step - loss: 0.3655 - accuracy: 0.8250 - val_loss: 0.2522 - val_accuracy: 0.9000 [INFO] evaluating network... precision recall f1-score support covid 0.83 1.00 0.91 5 normal 1.00 0.80 0.89 5 accuracy 0.90 10 macro avg 0.92 0.90 0.90 10 weighted avg 0.92 0.90 0.90 10 [[5 0] [1 4]] acc: 0.9000 sensitivity: 1.0000 specificity: 0.8000 [INFO] saving COVID-19 detector model... Автоматическое диагностирование по рентгеновским снимкам
Примечание: в этой части мы никак не «решаем» задачу определения COVID-19. Она написана в контексте текущей ситуации и только ради образовательных целей. Это пример практического применения компьютерного зрения и глубокого обучения, чтобы вы освоились с разными метриками, в том числе обычную точность, чувствительность и специфичность (и компромиссы, которые нужно учитывать при работе с медицинскими данными). Повторюсь, мы не решаем задачу определения COVID-19.
Итак, наш автоматический детектор показал точность ~90-92 % на образцах одних лишь рентгеновских снимков. Другой информации для обучения модели не использовалось, в том числе географического местоположения, плотности населения и т. д.
Мы также получили чувствительность 100 % и специфичность 80 %, что означает:
- Из пациентов, имеющих COVID-19 (истинно положительные случаи), с помощью модели мы смогли точно идентифицировать как «COVID-19-положительных» в 100 % случаев.
- Из пациентов, не имеющих COVID-19 (истинно отрицательные случаи), с помощью модели мы смогли точно идентифицировать как «COVID-19-отрицательных» только в 80 % случаев.
Как показывает график истории обучения, нейросеть не переобучена, несмотря на очень небольшой размер обучающих данных:
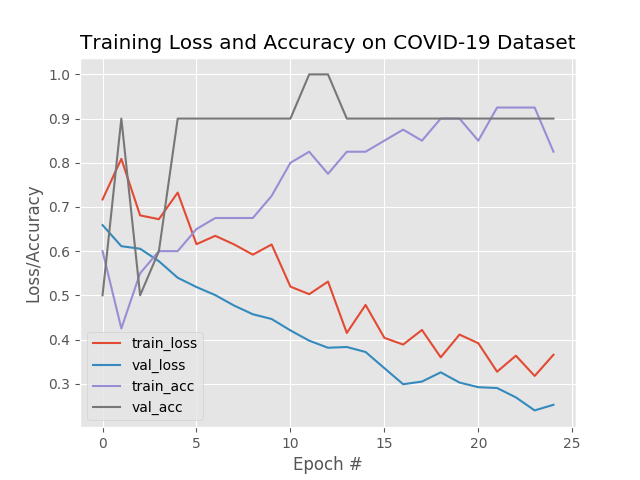
Прекрасно, что мы добились точности в 100 % при обнаружении COVID-19. Однако смущает ситуация с истинно отрицательными случаями: мы не хотим отнести к «COVID-19-отрицательным» тех, кто на самом деле «COVID-19-положительные».
Мы меньше все хотим отпустить домой больных пациентов, к семьям и друзьям, способствуя дальнейшему распространению болезни.
Также нужно быть очень осторожными с долей ложноположительных случаев: мы не хотим ошибочно посчитать кого-то больным и посадить его на карантин с другими больными, чтобы он от них заразился.
Поиск баланса между чувствительностью и специфичностью — крайне сложная задача, особенно когда речь идёт о медицине, и особенно когда речь идёт о быстро распространяющихся инфекционных заболеваниях.
Говоря о медицинском компьютерном зрении и глубоком обучении всегда нужно помнить, что работа наших прогнозных моделей может иметь очень серьёзные последствия: ошибочные диагнозы могут стоить жизней.
Повторюсь, результаты в этой статье представлены только с образовательной целью. Это не журнальная публикация, эти данные не удовлетворяют критериям TRIPOD по публикациям прогнозных моделей.
Ограничения, улучшения и дальнейшая работа

Одним из главных ограничений описанного в этом руководстве метода являются данные.
У нас нет достаточно количества (надёжных) данных для обучения детекторов COVID-19.
В больницах уже много историй болезни с этим вирусом, но учитывая конфиденциальность и права человека, становится ещё сложнее быстро собрать качественный датасет из медицинских изображений. Я считаю, что в следующие 12-18 месяцев у нас будет больше качественных данных. Но пока приходится пользоваться тем, что есть.
Я постарался (учитывая своё физическое и умственное состояние) в условиях ограниченного времени и ресурсов написать это руководство для тех, кого интересует применение компьютерного зрения и глубокого обучения. Но напомню, что я не профессиональный медик.
Чтобы использовать детектор COVID-19 в реальной жизни, он должен пройти жёсткое тестирование настоящими врачами, работающими рука об руку со специалистами по глубокому обучению. Описанный мной метод для этого не годится.
Более того, нужно быть осторожными с тем, чему именно «учится» модель.
Как я писал в руководстве по Grad-CAM, есть вероятность, что модель научится паттернам, которые не релевантны COVID-19, а всего лишь сможет различать две выборки данных (то есть положительные и отрицательные диагнозы). Результаты нашего детектора нужно будет строго тестировать и проверять врачам. И наконец, будущие (и более совершенные) детекторы будут мультимодальными.
Сейчас мы используем только визуальные данные (рентгеновские снимки). А более качественные детекторы должны использовать и другие данные: жизненные показатели пациентов, плотность населения, географическое местоположение и т.д. Одних лишь визуальных данных обычно недостаточно для подобных задач.
По этим причинам я хочу снова подчеркнуть: это руководство играет лишь роль обучающего материала — его нельзя рассматривать как надёжный детектор COVID-19.
Если вы считаете, что у вас или у кого-то из близких COVID-19, то следуйте рекомендациям представителей вашей системы здравоохранения.
Надеюсь, это руководство было для вас полезным. Также надеюсь, что оно станет для кого-то отправной точкой в поиске методики использования компьютерного зрения и глубокого обучения для автоматического определения COVID-19.
Итоги
Из этого руководства вы узнали, как можно использовать Keras, TensorFlow и глубокое обучение для создания автоматического детектора COVID-19 на датасете из рентгеновских снимков.
Сегодня (ещё) не существует качественных и проверенных датасетов изображений по этой болезни, поэтому приходится работать с репозиторием Джозефа Коэна:
- Мы взяли 25 изображений из его датасета, ограничившись заднепередней проекцией положительно диагностированных случаев.
- Затем взяли 25 снимков здоровых людей из датасета Kaggle Chest X-Ray Images (Pneumonia).
Затем с помощью Keras и TensorFlow мы обучили детектор COVID-19, который показал точность 90-92 % на нашей тестовой выборке, с чувствительностью 100 % и специфичностью 80 % (на нашем маленьком датасете).
Помните, что описанный здесь детектор предназначен только для образовательных целей (см. Примечание в тексте). Я хотел вдохновить других людей на использование глубокого обучения, показать, что в сочетании с компьютерным зрением оно может оказать большое влияние на нашу жизнь.
Надеюсь, вам понравилось.