Моем датасет: руководство по очистке данных в Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-27 12:02

Ни одна модель машинного обучения не выдаст осмысленных результатов, если вы предоставите ей сырые данные. После формирования выборки данных их необходимо очистить.
Очистка данных – это процесс обнаружения и исправления (или удаления) поврежденных или неточных записей из набора записей, таблицы или базы данных. Процесс включает в себя выявление неполных, неправильных, неточных или несущественных данных, а затем замену, изменение или удаление «загрязненных» данных.
Определение очень длинное и не очень понятное :(
Чтобы детально во всем разобраться, мы разбили это определение на составные части и создали пошаговый гайд по очистке данных на Python. Здесь мы разберем методы поиска и исправления:
- отсутствующих данных;
- нетипичных данных – выбросов;
- неинформативных данных – дубликатов;
- несогласованных данных – одних и тех же данных, представленных в разных регистрах или форматах.
Для работы с данными мы использовали Jupyter Notebook и библиотеку Pandas.
***
Базой для наших экспериментов послужит набор данных по ценам на жилье в России, найденный на Kaggle. Мы не станем очищать всю базу целиком, но разберем на ее основе главные методы и операции.
Прежде чем переходить к процессу очистки, всегда нужно представлять исходный датасет. Давайте быстро взглянем на сами данные:
# импорт пакетов import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import matplotlib.mlab as mlab import matplotlib plt.style.use('ggplot') from matplotlib.pyplot import figure %matplotlib inline matplotlib.rcParams['figure.figsize'] = (12,8) pd.options.mode.chained_assignment = None # чтение данных df = pd.read_csv('sberbank.csv') # shape and data types of the data print(df.shape) print(df.dtypes) # отбор числовых колонок df_numeric = df.select_dtypes(include=[np.number]) numeric_cols = df_numeric.columns.values print(numeric_cols) # отбор нечисловых колонок df_non_numeric = df.select_dtypes(exclude=[np.number]) non_numeric_cols = df_non_numeric.columns.values print(non_numeric_cols) Этот код покажет нам, что набор данных состоит из 30471 строки и 292 столбцов. Мы увидим, являются ли эти столбцы числовыми или категориальными признаками.
Теперь мы можем пробежаться по чек-листу «грязных» типов данных и очистить их один за другим.

***
1. Отсутствующие данные
Работа с отсутствующими значениями – одна из самых сложных, но и самых распространенных проблем очистки. Большинство моделей не предполагают пропусков.
1.1. Как обнаружить?
Рассмотрим три метода обнаружения отсутствующих данных в наборе.
1.1.1. Тепловая карта пропущенных значений
Когда признаков в наборе не очень много, визуализируйте пропущенные значения с помощью тепловой карты.
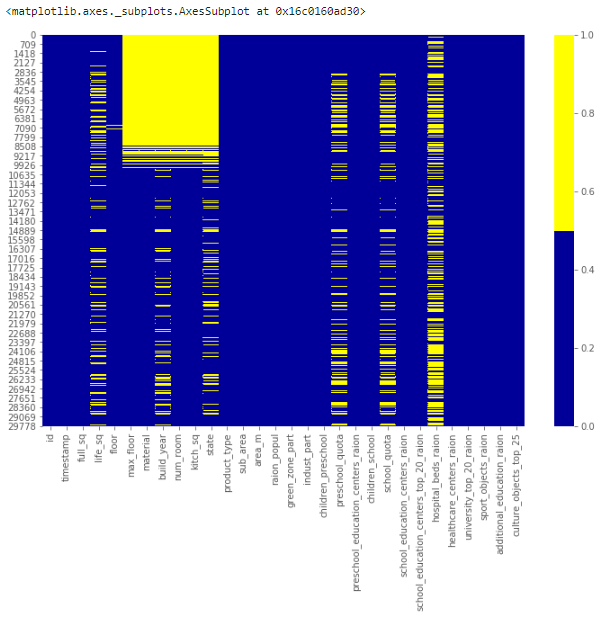
cols = df.columns[:30] # первые 30 колонок # определяем цвета # желтый - пропущенные данные, синий - не пропущенные colours = ['#000099', '#ffff00'] sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours)) Приведенная ниже карта демонстрирует паттерн пропущенных значений для первых 30 признаков набора. По горизонтальной оси расположены признаки, по вертикальной – количество записей/строк. Желтый цвет соответствует пропускам данных.
Заметно, например, что признак life_sq имеет довольно много пустых строк, а признак floor – напротив, всего парочку – около 7000 строки.
1.1.2. Процентный список пропущенных данных
Если в наборе много признаков и визуализация занимает много времени, можно составить список долей отсутствующих записей для каждого признака.
for col in df.columns: pct_missing = np.mean(df[col].isnull()) print('{} - {}%'.format(col, round(pct_missing*100))) Такой список для тех же 30 первых признаков выглядит следующим образом:
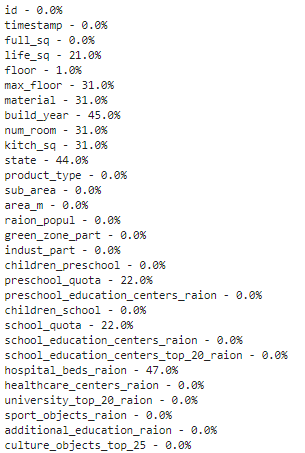
У признака life_sq отсутствует 21% значений, а у floor – только 1%.
Этот список является полезным резюме, которое может отлично дополнить визуализацию тепловой карты.
1.1.3. Гистограмма пропущенных данных
Еще одна хорошая техника визуализации для наборов с большим количеством признаков – построение гистограммы для числа отсутствующих значений в записи.
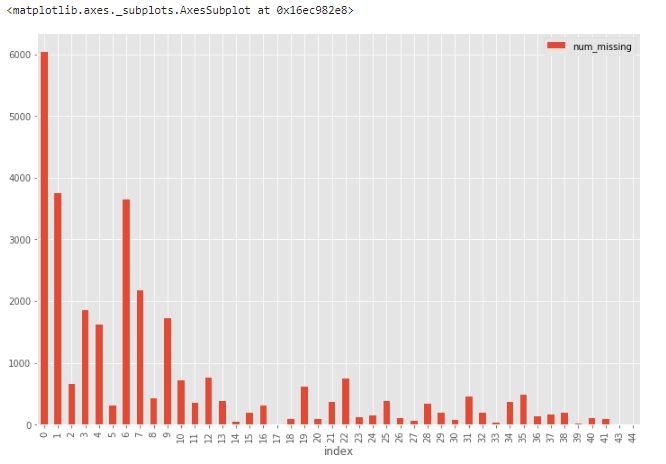
# сначала создаем индикатор для признаков с пропущенными данными for col in df.columns: missing = df[col].isnull() num_missing = np.sum(missing) if num_missing > 0: print('created missing indicator for: {}'.format(col)) df['{}_ismissing'.format(col)] = missing # затем на основе индикатора строим гистограмму ismissing_cols = [col for col in df.columns if 'ismissing' in col] df['num_missing'] = df[ismissing_cols].sum(axis=1) df['num_missing'].value_counts().reset_index().sort_values(by='index').plot.bar(x='index', y='num_missing') Отсюда понятно, что из 30 тыс. записей более 6 тыс. строк не имеют ни одного пропущенного значения, а еще около 4 тыс.– всего одно. Такие строки можно использовать в качестве «эталонных» для проверки различных гипотез по дополнению данных.
1.2. Что делать с пропущенными значениями?
Не существует общих решений для проблемы отсутствующих данных. Для каждого конкретного набора приходится искать наиболее подходящие методы или их комбинации.
Разберем четыре самых распространенных техники. Они помогут в простых ситуациях, но, скорее всего, придется проявить творческий подход и поискать нетривиальные решения, например, промоделировать пропуски.
1.2.1. Отбрасывание записей
Первая техника в статистике называется методом удаления по списку и заключается в простом отбрасывании записи, содержащей пропущенные значения. Это решение подходит только в том случае, если недостающие данные не являются информативными.
Для отбрасывания можно использовать и другие критерии. Например, из гистограммы, построенной в предыдущем разделе, мы узнали, что лишь небольшое количество строк содержат более 35 пропусков. Мы можем создать новый набор данных df_less_missing_rows, в котором отбросим эти строки.
# отбрасываем строки с большим количеством пропусков ind_missing = df[df['num_missing'] > 35].index df_less_missing_rows = df.drop(ind_missing, axis=0) 1.2.2. Отбрасывание признаков
Как и предыдущая техника, отбрасывание признаков может применяться только для неинформативных признаков.
В процентном списке, построенном ранее, мы увидели, что признак hospital_beds_raion имеет высокий процент недостающих значений – 47%. Мы можем полностью отказаться от этого признака:
cols_to_drop = ['hospital_beds_raion'] df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1) 1.2.3. Внесение недостающих значений
Для численных признаков можно воспользоваться методом принудительного заполнения пропусков. Например, на место пропуска можно записать среднее или медианное значение, полученное из остальных записей.
Для категориальных признаков можно использовать в качестве заполнителя наиболее часто встречающееся значение.
Возьмем для примера признак life_sq и заменим все недостающие значения медианой этого признака:
med = df['life_sq'].median() print(med) df['life_sq'] = df['life_sq'].fillna(med) Одну и ту же стратегию принудительного заполнения можно применить сразу для всех числовых признаков:
# impute the missing values and create the missing value indicator variables for each numeric column. df_numeric = df.select_dtypes(include=[np.number]) numeric_cols = df_numeric.columns.values for col in numeric_cols: missing = df[col].isnull() num_missing = np.sum(missing) if num_missing > 0: # only do the imputation for the columns that have missing values. print('imputing missing values for: {}'.format(col)) df['{}_ismissing'.format(col)] = missing med = df[col].median() df[col] = df[col].fillna(med) К счастью, в нашем наборе не нашлось пропусков в категориальных признаках. Но это не мешает нам продемонстрировать использование той же стратегии:
df_non_numeric = df.select_dtypes(exclude=[np.number]) non_numeric_cols = df_non_numeric.columns.values for col in non_numeric_cols: missing = df[col].isnull() num_missing = np.sum(missing) if num_missing > 0: # only do the imputation for the columns that have missing values. print('imputing missing values for: {}'.format(col)) df['{}_ismissing'.format(col)] = missing top = df[col].describe()['top'] # impute with the most frequent value. df[col] = df[col].fillna(top) 1.2.4. Замена недостающих значений
Можно использовать некоторый дефолтный плейсхолдер для пропусков, например, новую категорию _MISSING_ для категориальных признаков или число -999 для числовых.
Таким образом, мы сохраняем данные о пропущенных значениях, что тоже может быть ценной информацией.
# категориальные признаки df['sub_area'] = df['sub_area'].fillna('_MISSING_') # численные признаки df['life_sq'] = df['life_sq'].fillna(-999) ***
2. Нетипичные данные (выбросы)
Выбросы – это данные, которые существенно отличаются от других наблюдений. Они могут соответствовать реальным отклонениям, но могут быть и просто ошибками.
2.1. Как обнаружить выбросы?
Для численных и категориальных признаков используются разные методы изучения распределения, позволяющие обнаружить выбросы.
2.1.1. Гистограмма/коробчатая диаграмма
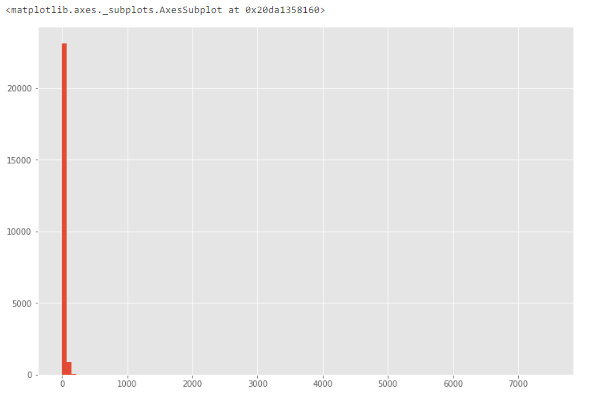
Если признак численный, можно построить гистограмму или коробчатую диаграмму (ящик с усами). Посмотрим на примере уже знакомого нам признака life_sq.
df['life_sq'].hist(bins=100) Из-за возможных выбросов данные выглядят сильно искаженными.
Чтобы изучить особенность поближе, построим коробчатую диаграмму.
df.boxplot(column=['life_sq']) Видим, что есть выброс со значением более 7000.
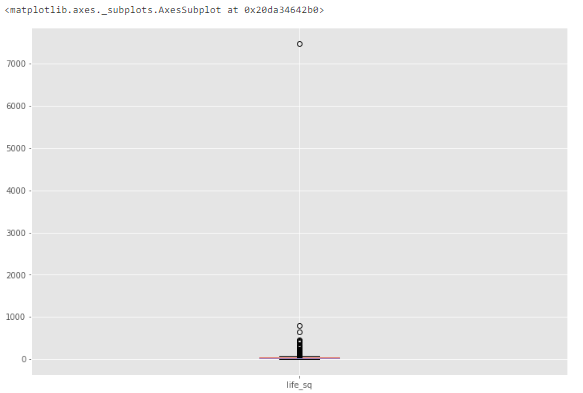
2.1.2. Описательная статистика
Отклонения численных признаков могут быть слишком четкими, чтобы не визуализироваться коробчатой диаграммой. Вместо этого можно проанализировать их описательную статистику.
Например, для признака life_sq видно, что максимальное значение равно 7478, в то время как 75% квартиль равен только 43. Значение 7478 – выброс.
df['life_sq'].describe() 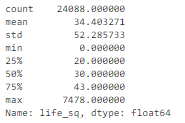
2.1.3. Столбчатая диаграмма
Для категориальных признаков можно построить столбчатую диаграмму – для визуализации данных о категориях и их распределении.
Например, распределение признака ecology вполне равномерно и допустимо. Но если существует категория только с одним значением "другое", то это будет выброс.
df['ecology'].value_counts().plot.bar() 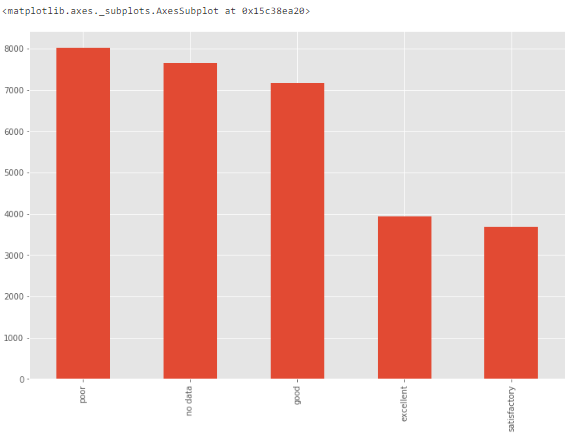
2.1.4. Другие методы
Для обнаружения выбросов можно использовать другие методы, например, построение точечной диаграммы, z-оценку или кластеризацию. В этом руководстве они не рассматриваются.
2.2. Что делать?
Выбросы довольно просто обнаружить, но выбор способа их устранения слишком существенно зависит от специфики набора данных и целей проекта. Их обработка во многом похожа на обработку пропущенных данных, которую мы разбирали в предыдущем разделе. Можно удалить записи или признаки с выбросами, либо скорректировать их, либо оставить без изменений.
***

Переходим к более простой части очистки данных – удалению мусора.
Вся информация, поступающая в модель, должна служить целям проекта. Если она не добавляет никакой ценности, от нее следует избавиться.
Три основных типа «ненужных» данных:
- неинформативные признаки с большим количеством одинаковых значений,
- нерелевантные признаки,
- дубликаты записей.
Рассмотрим работу с каждым типом отдельно.
3. Неинформативные признаки
Если признак имеет слишком много строк с одинаковыми значениями, он не несет полезной информации для проекта.
3.1. Как обнаружить?
Составим список признаков, у которых более 95% строк содержат одно и то же значение.
num_rows = len(df.index) low_information_cols = [] # for col in df.columns: cnts = df[col].value_counts(dropna=False) top_pct = (cnts/num_rows).iloc[0] if top_pct > 0.95: low_information_cols.append(col) print('{0}: {1:.5f}%'.format(col, top_pct*100)) print(cnts) print() Теперь можно последовательно перебрать их и определить, несут ли они полезную информацию.
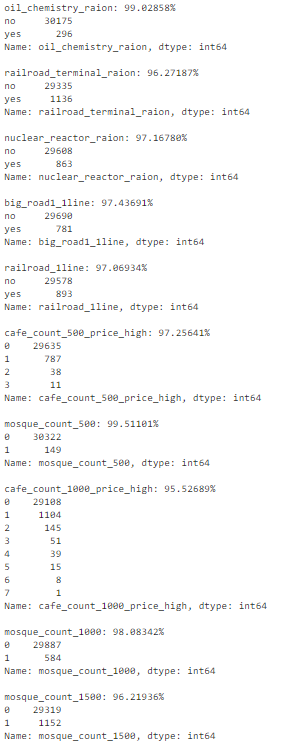
3.2. Что делать?
Если после анализа причин получения повторяющихся значений вы пришли к выводу, что признак не несет полезной информации, используйте drop().
4. Нерелевантные признаки
Нерелевантные признаки обнаруживаются ручным отбором и оценкой значимости. Например, признак, регистрирующий температуру воздуха в Торонто точно не имеет никакого отношения к прогнозированию цен на российское жилье. Если признак не имеет значения для проекта, его нужно исключить.
5. Дубликаты записей
Если значения признаков (всех или большинства) в двух разных записях совпадают, эти записи называются дубликатами.
5.1. Как обнаружить повторяющиеся записи?
Способ обнаружения дубликатов зависит от того, что именно мы считаем дубликатами. Например, в наборе данных есть уникальный идентификатор id. Если две записи имеют одинаковый id, мы считаем, что это одна и та же запись. Удалим все неуникальные записи:
# отбрасываем неуникальные строки df_dedupped = df.drop('id', axis=1).drop_duplicates() # сравниваем формы старого и нового наборов print(df.shape) print(df_dedupped.shape) Получаем в результате 10 отброшенных дубликатов:

Другой распространенный способ вычисления дубликатов: по набору ключевых признаков. Например, неуникальными можно считать записи с одной и той же площадью жилья, ценой и годом постройки.
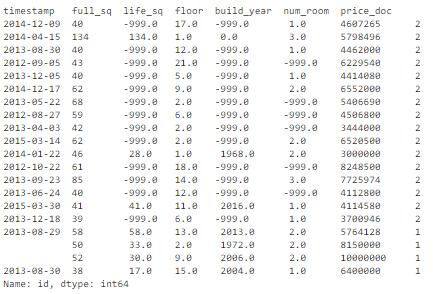
Найдем в нашем наборе дубликаты по группе критических признаков – full_sq, life_sq, floor, build_year, num_room, price_doc:
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc'] df.fillna(-999).groupby(key)['id'].count().sort_values(ascending=False).head(20) Получаем в результате 16 дублирующихся записей:
5.2. Что делать с дубликатами?
Очевидно, что повторяющиеся записи нам не нужны, значит, их нужно исключить из набора.
Вот так выглядит удаление дубликатов, основанное на наборе ключевых признаков:
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc'] df_dedupped2 = df.drop_duplicates(subset=key) print(df.shape) print(df_dedupped2.shape) В результате новый набор df_dedupped2 стал короче на 16 записей.

***
Большая проблема очистки данных – разные форматы записей. Для корректной работы модели важно, чтобы набор данных соответствовал определенным стандартам – необходимо тщательное исследование с учетом специфики самих данных. Мы рассмотрим четыре самых распространенных несогласованности:
- Разные регистры символов.
- Разные форматы данных (например, даты).
- Опечатки в значениях категориальных признаков.
- Адреса.
6. Разные регистры символов
Непоследовательное использование разных регистров в категориальных значениях является очень распространенной ошибкой, которая может существенно повлиять на анализ данных.
6.1. Как обнаружить?
Давайте посмотрим на признак sub_area:
df['sub_area'].value_counts(dropna=False) В нем содержатся названия населенных пунктов. Все выглядит вполне стандартизированным:

Но если в какой-то записи вместо Poselenie Sosenskoe окажется poselenie sosenskoe, они будут расценены как два разных значения.
6.2. Что делать?
Эта проблема легко решается принудительным изменением регистра:
# пусть все будет в нижнем регистре df['sub_area_lower'] = df['sub_area'].str.lower() df['sub_area_lower'].value_counts(dropna=False) 
7. Разные форматы данных
Ряд данных в наборе находится не в том формате, с которым нам было бы удобно работать. Например, даты, записанные в виде строки, следует преобразовать в формат DateTime.
7.1. Как обнаружить?
Признак timestamp представляет собой строку, хотя является датой:
df 
7.2. Что же делать?
Чтобы было проще анализировать транзакции по годам и месяцам, значения признака timestamp следует преобразовать в удобный формат:
df['timestamp_dt'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d') df['year'] = df['timestamp_dt'].dt.year df['month'] = df['timestamp_dt'].dt.month df['weekday'] = df['timestamp_dt'].dt.weekday print(df['year'].value_counts(dropna=False)) print() print(df['month'].value_counts(dropna=False)) 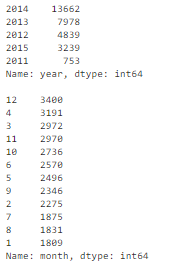
Взгляните также на публикацию How To Manipulate Date And Time In Python Like A Boss.
8. Опечатки
Опечатки в значениях категориальных признаков приводят к таким же проблемам, как и разные регистры символов.
8.1. Как обнаружить?
Для обнаружения опечаток требуется особый подход. В нашем наборе данных о недвижимости опечаток нет, поэтому для примера создадим новый набор. В нем будет признак city, а его значениями будут torontoo и tronto. В обоих случаях это опечатки, а правильное значение – toronto.
Простой способ идентификации подобных элементов – нечеткая логика или редактирование расстояния. Суть этого метода заключается в измерении количества букв (расстояния), которые нам нужно изменить, чтобы из одного слова получить другое.
Предположим, нам известно, что в признаке city должно находиться одно из четырех значений: toronto, vancouver, montreal или calgary. Мы вычисляем расстояние между всеми значениями и словом toronto (и vancouver).
Те слова, в которых содержатся опечатки, имеют меньшее расстояние с правильным словом, так как отличаются всего на пару букв.
from nltk.metrics import edit_distance df_city_ex = pd.DataFrame(data={'city': ['torontoo', 'toronto', 'tronto', 'vancouver', 'vancover', 'vancouvr', 'montreal', 'calgary']}) df_city_ex['city_distance_toronto'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'toronto')) df_city_ex['city_distance_vancouver'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'vancouver')) df_city_ex 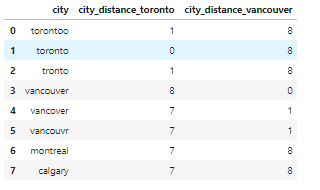
8.2. Что делать?
Мы можем установить критерии для преобразования этих опечаток в правильные значения.
Например, если расстояние некоторого значения от слова toronto не превышает 2 буквы, мы преобразуем это значение в правильное – toronto.
msk = df_city_ex['city_distance_toronto'] <= 2 df_city_ex.loc[msk, 'city'] = 'toronto' msk = df_city_ex['city_distance_vancouver'] <= 2 df_city_ex.loc[msk, 'city'] = 'vancouver' df_city_ex 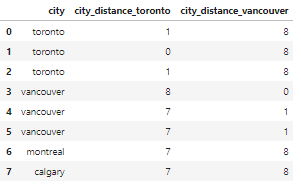
9. Адреса
Адреса – ужасная головная боль для всех аналитиков данных. Ведь мало кто следует стандартному формату, вводя свой адрес в базу данных.
9.1. Как обнаружить?
Проще предположить, что проблема разных форматов адреса точно существует. Даже если визуально вы не обнаружили беспорядка в этом признаке, все равно стоит стандартизировать их для надежности.
В нашем наборе данных по соображениям конфиденциальности отсутствует признак адреса, поэтому создадим новый набор df_add_ex:
df_add_ex = pd.DataFrame(['123 MAIN St Apartment 15', '123 Main Street Apt 12 ', '543 FirSt Av', ' 876 FIRst Ave.'], columns=['address']) df_add_ex Признак адреса здесь загрязнен:
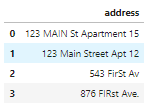
9.2. Что делать?
Минимальное форматирование включает следующие операции:
- приведение всех символов к нижнему регистру;
- удаление пробелов в начале и конце строки;
- удаление точек;
- стандартизация формулировок: замена
streetнаst,apartmentнаaptи т. д.
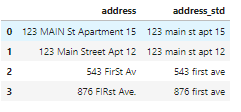
df_add_ex['address_std'] = df_add_ex['address'].str.lower() df_add_ex['address_std'] = df_add_ex['address_std'].str.strip() df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('.', '') df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('street', 'st') df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('apartment', 'apt') df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('av', 'ave') df_add_ex Теперь признак стал намного чище:
***
Мы сделали это! Это был долгий и трудный путь, но теперь все «грязные" данные очищены и готовы к анализу, а вы стали спецом по чистке данных ;)

У нас есть еще куча полезных статей по Data Science, например, среди недавних:
- 10 Data Science книг к прочтению в 2020 году
- 10 инструментов искусственного интеллекта Google, доступных каждому
- 100+ лекций экспертов Постнауки об анализе данных, ИИ, роботах, математике и сетях
Или просто посмотрите тег Data Science.
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io