Как управлять мамонтом: генерируем нужные тексты с помощью моделей Plug and Play
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-13 18:00
Бум нейросетей и глубинного обучения подстегнул развитие систем автоматической обработки языка (Natural Language Processing). За последние 5-6 лет машинные переводчики, вопросно-ответные системы, автозамена и спеллчекеры стали ощутимо умнее. Новый качественный скачок случился после выхода нейросетевой архитектуры Transformer (Vaswani et al., 2017). Модели-трансформеры, такие как BERT от Google, оказались очень хороши в задачах обработки языка.

Допиши за меня
Нейросети научились порождать правдоподобные тексты, дописывая за человеком. Например, если мы напишем The food is awful (Еда ужасна), нейросетевая модель сгенерирует правдоподобное завершение предложения (сгенерировано из предварительно обученной модели GPT-2-medium):
The food is awful. The staff are rude and lazy. The food is disgusting — even by my standards. (Еда ужасна. Персонал грубый и ленивый. Еда отвратительна даже по моим стандартам)
Языковые модели способны выявлять и запоминать информацию о грамматике и типичных речевых паттернах, но нет простого способа заставить их генерировать текст с определенными свойствами или по конкретной тематике. К примеру, если мы хотим сгенерировать текст с тем же началом: Еда ужасна, но затем продолжить в положительном смысле или постепенно сменить тему создаваемого текста на тему политики.
Мышь на голове у мамонта
Исследователи во всем мире предлагают способы генерации текста с заданием условий. Интересный метод предложен Uber AI в статье Plug and Play Language Models: A Simple Approach to Controlled Text Generation (далее по тексту просто «статья»). Ниже приведен пример, сгенерированный моделью из статьи. Модель настроили так, чтобы она завершила предложение позитивно:
The food is awful, but there is also the music, the story and the magic! The «Avenged Sevenfold» is a masterfully performed rock musical that will have a strong presence all over the world.
(Еда ужасна, но еще здесь есть музыка, сюжет, магическая атмосфера. «Avenged Sevenfold» [реальная американская рок-группа] — мастерски исполненный рок-мюзикл, который получит признание по всему миру)
Plug and Play Language Model (PPLM) позволяет пользователю подключать одну или несколько моделей для каждого из желаемых параметров (позитив или негатив, тематика и т.п.) в большую предобученную языковую модель (LM). Ключевая особенность подхода заключается в том, что он использует LM как есть — никакого обучения или настройки не требуется. Это позволяет исследователям использовать лучшие языковые модели.
Модели классификаторов могут быть в 100 000 раз меньше, чем основная модель (LM), и при этом эффективно управлять ими — как мышь, сидящая на голове мамонта и говорящая ему, куда идти.
Как работает PPLM
Алгоритм PPLM производит прямой и обратный обход нейронной сети, состоящей из двух подсетей — базовой предобученной языковой модели (LM) и модели классификатора по заданному пользователем атрибуту (attribute model):
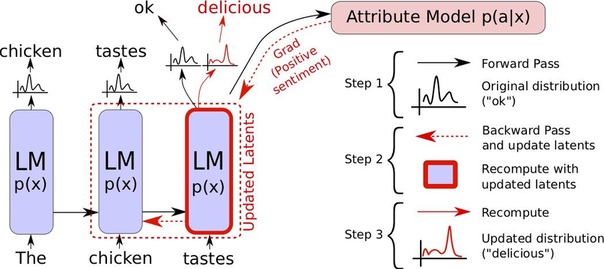

Сначала выполняется прямой проход через языковую модель LM для генерации слова и вычисления вероятности соответствия этого слова требуемому классу (атрибуту) с использованием модели классификатора. Далее, обратный проход обновляет внутренние скрытые представления LM на основе градиентов логарифмических вероятностей требуемого класса (подробнее об этом тут), чтобы увеличить вероятность соответствия сгенерированного текста заданному атрибуту.
После обновления генерируется новое распределение по словарю из распределения, полученного из обновленных переменных, и выбирается один токен или слово. Этот процесс повторяется на каждом шаге, причем скрытые слои основной нейросети, представляющие прошлое состояние (для преобразователей: ключи и значения), постоянно изменяются на каждом временном шаге.
Чтобы гарантировать, что полученная языковая модель возвращает не бессмыслицу, а примерно такие же разумные результаты, как и исходная языковая модель (в данном примере, GPT-2) применяются два подхода:
- Минимизация дивергенции Кульбака-Лейблера (KL) между выходным распределением модифицированной и немодифицированной языковой модели.
- Получение вероятности распределения для следующего слова с помощью смешанного распределения модифицированной и немодифицированной языковой модели (post-norm fusion (введено в Stahlberg et al. (2018)).
Управление PPLM можно настроить: сила дополнительной модели с заданным нами атрибутом может быть увеличена или уменьшена, и при нулевой силе восстанавливается исходная языковая модель.
Расскажи про космос
Посмотрим , что можно получить из PPLM, применяя разные модели классификации.
Исследователи Uber AI в качестве дополнительно модели использовали мешок слов (BoW) для различных тем, где вероятность темы определяется суммой вероятностей каждого слова в мешке. Например, BoW, представляющий тему Space, может содержать слова, такие как «планета», «галактика», «пространство» и «вселенная». В таблице ниже показаны примеры PPLM-BoW по теме [Space] с несколькими вариантами префиксов (начал предложений). В каждом примере получили связный текст, имеющий отношение к теме.

Результаты для тем [Military], [Politics], [Computers] и [Science], начинающихся с одного и того же префикса, показаны ниже. Самый первый пример — генерация без заданной темы.

Помимо этого были получены примеры с неестественными префиксами, которые не имеют никакого отношения к заданной теме. Например, исследователи задали начало предложения «The chicken», а в качестве темы — [Politics]. В результате, даже при таком варианте PPLM смог управлять генерацией текста и подстроить его под заданную тему.

Хорошая и плохая курица
Когда необходимо управлять тональностью текста (т.е. сделать его положительно или отрицательно окрашенным), исследователи из Uber AI предлагают вместо BoW использовать дискриминатор, обученный на наборе данных, размеченном по тональности (эмоциональной окраске). Количество параметров в дискриминационных моделях PPLM-Discrim может быть 5000 или меньше. 5000 — это ничтожно мало по сравнению с количеством параметров в основной модели (LM), и обучать такую модель гораздо легче и быстрее.
В следующих примерах использовали дискриминатор тональности с 5000 параметрами (1025 параметров на класс (— —, —, 0, +, + +)), обученный на наборе данных SST-5, чтобы управлять тональностью генерируемых текстов. Positive — от модели требуется текст с положительной эмоциональной окраской; Negative — с отрицательной окраской.

Детоксикация языка
Модели, обученные на большом количестве текстов в Интернете, могут отражать предвзятость и токсичность, присутствующие в исходных данных. Например, GPT-2 может высказывать расистские суждения, если подобрать провоцирующее на это начало предложения. Этот риск ограничивает сферы применения языковых моделей.
К счастью, PPLM можно легко адаптировать для детоксикации языка, подключив классификатор токсичности в качестве модели атрибута и обновив латентность с отрицательным градиентом. Исследователи из Uber AI провели тест, в котором добровольные оценщики отметили токсичность пятисот образцов текста, сгенерированных PPLM с детоксификацией, и сравнили их с базовой моделью GPT-2. В среднем доля токсичной речи снизилась с 63,6% до 4,6%.
Если вам интересно узнать больше о работе, здесь и здесь представлен код. Также, можно поиграть с интерактивной демонстрацией.
Источники
- Controlling Text Generation with Plug and Play Language Models.
- Статья Plug and Play Language Models: A Simple Approach To Controlled Text Generation.
- PPLM
Телеграм: t.me/ainewsline
Источник: m.vk.com