Как измерить культуру: гуманитарии и Big Data
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-27 22:10
За свою историю человечество породило бесчисленное количество текстов, картин, скульптур, музыкальных произведений, фильмов, комиксов, фотографий... По мере оцифровки этой гигантской культурной сокровищницы всё более заманчивой становится идея применить для ее исследования методы Data Science. Технологии работы с большими данными уже давно помогают находить закономерности в работе банков и поисковиков, транспортных систем и буровых установок, органов госуправления и экологических систем. Данные называют «новой нефтью» — и владеющие ими компании, такие как Google или Facebook, сегодня сказочно богаты. Но может ли анализ данных помочь ответить на вопросы о том, как устроена и как развивается человеческая культура? Специально для «Ножа» о попытках ученых «измерить культуру» рассказывает Даниил Скоринкин — главный редактор издания «Системный Блокъ», посвященного цифровым гуманитарным исследованиям и цифровой трансформации общества.
Филология
Применять точные методы филологи начали давно — задолго до появления компьютеров. Еще в конце XIX века на волне научного позитивизма ученые при помощи статистики устанавливали хронологию текстов Платона, вычисляли критерии, по которым различаются стили произведений Гомера и других античных памятников, пытались определить автора спорных произведений — например, пьес, приписываемых Уильяму Шекспиру. Тогда же зародилось
количественное стиховедение
— статистический анализ метрики стиха.
В XX веке было минимум две волны интереса к точным методам в филологии. Первая развивалась в 1910–1920-е годы и была связана с возникновением русского формализма — всемирно известной литературоведческой школы, провозгласившей тогда ставку на научность и объективность исследования литературы.
Выдающийся филолог-формалист Борис Томашевский, который по образованию был инженером-электриком и долгое время работал в статистике, исследовал с ее помощью ритмику Пушкина — с особым вниманием к «Евгению Онегину». Тогда же другой филолог, Михаил Лопатто, произвел на материале пушкинской прозы первый в своем роде «анализ тональности» — то есть подсчитал долю эмоционально окрашенных слов. Сегодня это стандартная технология в компьютерной лингвистике.
А известный революционер-народоволец, участник покушения на Александра II и по совместительству ученый-энциклопедист Николай Морозов в 1915 году придумал статистический метод определения плагиата, который во многом предвосхищает современные компьютерные техники определения авторства. Для этого Морозов вручную высчитывал частоту употребления разных предлогов в русских классических текстах, включая такие объемные, как «Капитанская дочка». Оппонировал Морозову знаменитый математик Андрей Марков, создатель цепей Маркова, на которых работают многие сегодняшние интеллектуальные технологии.
Титаническую работу по приближению филологии к естественным наукам проделал Борис Ярхо. Он считал, что филология является частью «науки о жизни» и может быть устроена по образцу биологии.
Идеи Ярхо во многом предвосхитили современные теории «культурной эволюции», которые предполагают естественный отбор произведений искусства и наследование признаков в культуре. В 1920–1930-е годы Ярхо неоднократно анализировал художественные произведения и целые жанры с применением математической статистики, проявляя при этом чудеса работоспособности — например, он обработал больше 150 пьес на трех языках. Результатом стала подробная «Методология точного литературоведения», описанием которой Ярхо занимался в последние годы своей жизни, но так и не закончил свой труд. К сожалению, эта работа, как и большая часть наследия Ярхо, не была опубликована до 2006 года, а сам филолог больше полувека после смерти оставался практически неизвестен даже в научных кругах.
Вторая волна интереса к точному литературоведению пришла уже после войны. Появились ЭВМ, стала популярна кибернетика, случились первые опыты машинного перевода и компьютерного анализа оцифрованных текстов, в лингвистике был бум формальных синтаксических моделей… На этом фоне литературоведы вновь задумались о том, как сделать свою науку более точной и объективной. В 1967 году выдающийся советский филолог и семиотик Юрий Лотман написал статью «Литературоведение должно быть наукой», где обрисовал новый тип ученого-филолога — он должен был сочетать в себе литературоведа, лингвиста и математика. Из архивов были подняты забытые работы Бориса Ярхо и формалистов, а благодаря исследованиям Михаила Гаспарова в количественном стиховедении произошел новый расцвет.
В конце 1980-х — начале 1990-х с массовым распространением компьютеров и переходом большого количества текстов в цифровую форму поднялась очередная волна количественных подходов в литературоведении. Сегодня цифровые литературоведы уже не подвижники-одиночки вроде Бориса Ярхо, а большое международное сообщество исследователей. Они применяют количественные подходы к изучению эволюции художественных произведений, математическому моделированию литературных жанров и стилей, к задачам определения авторства.
Много ярких исследований такого рода осуществила литературная лаборатория Стэнфордского университета. Например, они разными способами измеряли эволюцию британского романа в XVIII–XIX веках; при этом брали не отдельные канонические произведения, а многотысячные коллекции текстов — это позволило получить представление о литературном процессе в целом. Так, на корпусе из трех тысяч текстов исследователи показали, как на протяжении XIX века британский роман из морализаторского становится более конкретным, в нем появляется всё больше действия и экшена. В произведениях сокращается доля слов, связанных с моральной оценкой и нравоучительством. При этом в романах всё чаще упоминаются конкретные физические объекты вроде частей тела, а также глаголы действия (сделал, пошел, сказал), локативные предлоги (в, на, под, над), прилагательные, обозначающие конкретные физические свойства (размер, вес, материал), обозначения цветов.
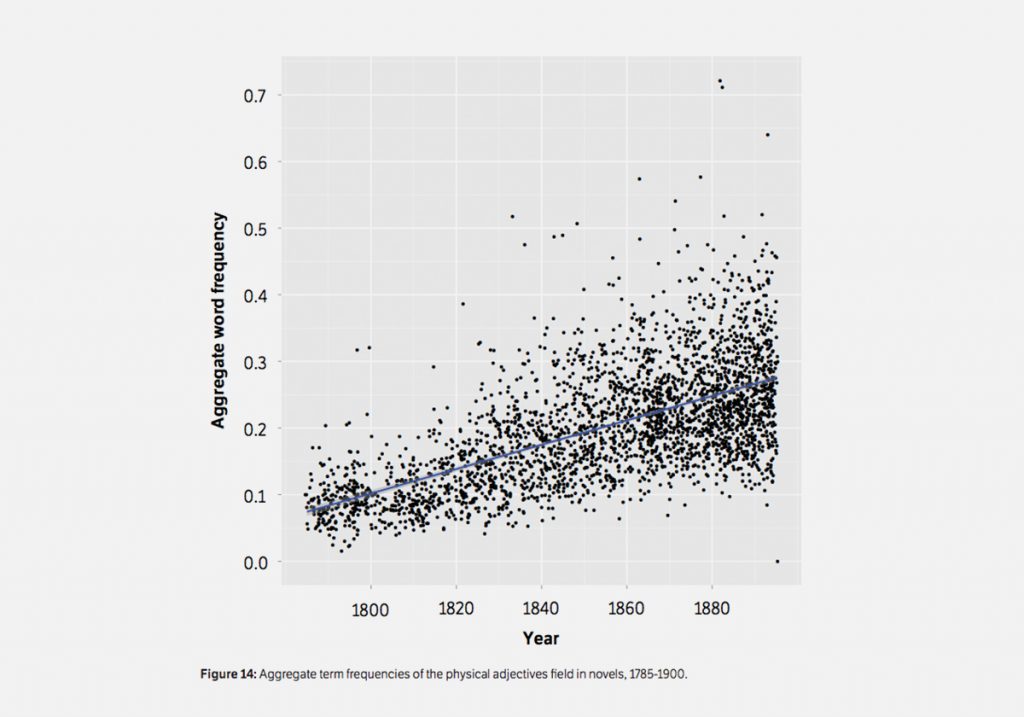
Исследователи связывают это с изменением пространства, в котором обитают персонажи романов. В начале XIX века это чаще всего деревня, поместье (вспомним классические романы Джейн Остин), в котором обитает небольшое сообщество — семья или несколько семей, как правило, аристократия. В этом ограниченном кругу все знакомы друг с другом, действие происходит в одном месте. Сюжет вращается вокруг поведения и взаимоотношений персонажей, большую роль играет описание этикета и социальных норм. Развитие событий в таких романах не предполагает большой доли «экшена», перемещений в пространстве. Если место действия — деревня, нет ни нужды, ни возможности описывать, к примеру, сложный маршрут героя из пункта А в пункт Б и его приключения по дороге.
Но в XIX веке Британия переживает быструю индустриализацию и урбанизацию. Одновременно меняется литературное пространство. Городской роман второй половины XIX века (скажем, произведения Чарльза Диккенса) устроен принципиально иначе. Здесь нет прежних классовых границ, герои могут относиться и к низшим слоям общества, да и сами социальные слои в городе перемешиваются гораздо активнее. Эти тексты наполнены действиями, перемещениями и событиями. Количественные методы помогают увидеть эту эволюцию романа на масштабном материале.
Другое исследование связано с «громкостью» романа. Определяя долю слов, связанных с громкой, тихой и нейтральной речью, ученые обнаружили, что по мере перехода от романтических и готических текстов к реализму британский роман «затихает», нейтрализуется. В нем меньше кричат, восклицают и плачут — и больше просто «говорят», «спрашивают» и «отвечают».
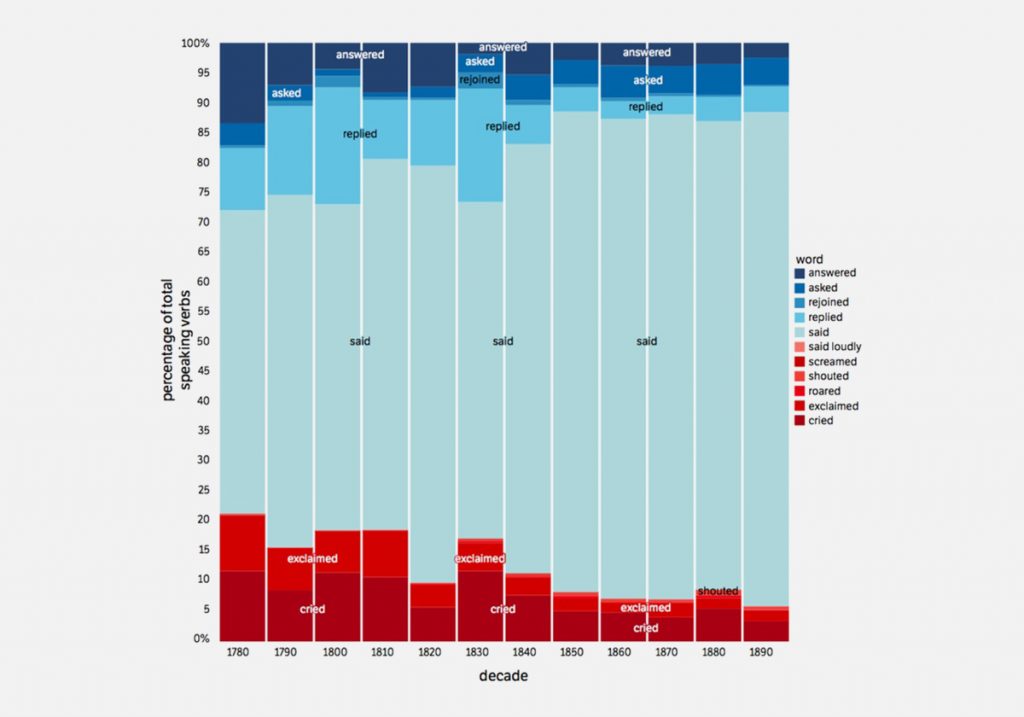
Исследователи вновь связывают эти перемены с изменениями в общественном пространстве Великобритании. В этот период в английской философии и психологии происходит сдвиг от «страстей» к более нейтральным «эмоциям» и «настроениям». Из романов постепенно исчезают экзотика, приключения в духе Вальтера Скотта и прочие яркие неожиданности. Романный мир становится менее драматическим, более социальным, фокусируется на повседневности. Неудивительно, что это сопровождается снижением громкости.
Кроме того, стэнфордские литературоведы попытались с помощью статистики понять, почему одни произведения «выстрелили» и стали классикой, а другие были прочитаны единицами и забыты.
Для этого ученые позаимствовали из теории информации меру
«избыточности»
текста — насколько любое слово в тексте можно предсказать по предыдущему слову. Оказалось, что язык произведений, вошедших в литературный канон (Джейн Остин, Вальтер Скотт, Чарльз Диккенс и другие), гораздо менее предсказуем (то есть менее избыточен), чем язык тысяч романов, не прошедших литературный естественный отбор.
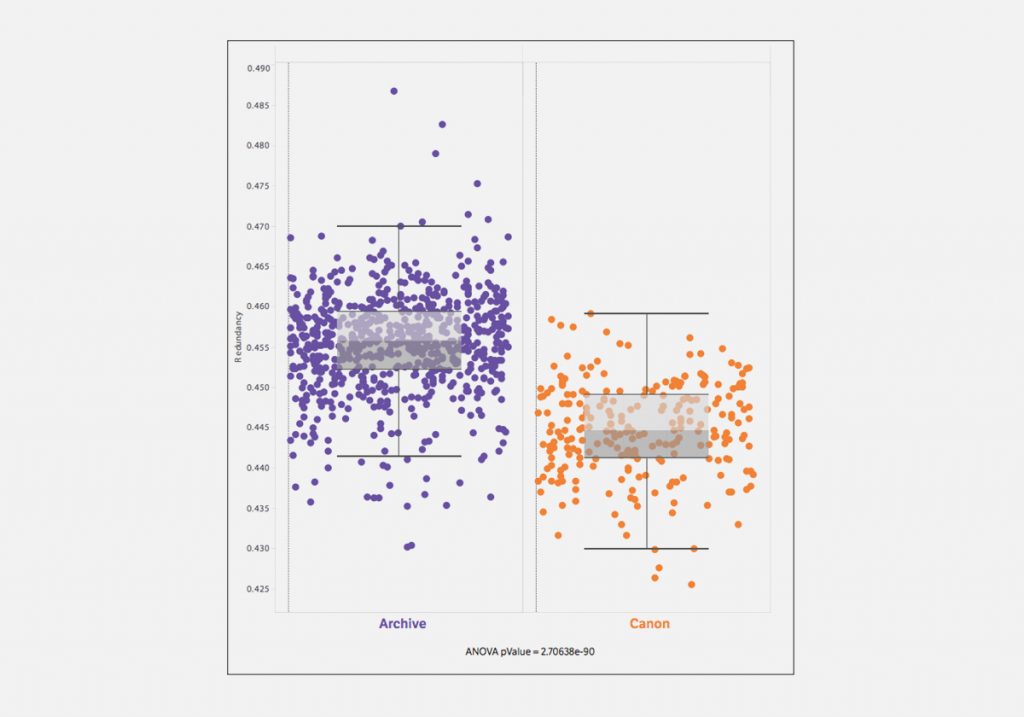
Получается, что романы Джейн Остин и Вальтера Скотта были намного неожиданнее для читателя — и потому прошли отбор в вечность. Кстати, при этом классика отличается меньшим словесным разнообразием, чем забытые периферийные тексты, то есть выдающиеся писатели еще и умели не переусложнять свои произведения окрошкой из разнообразной лексики. Вместо этого мастера комбинировали сравнительно небольшие наборы слов неожиданным образом — и приходили к успеху.
История
Анализ больших массивов неструктурированных данных может дать новое знание и исторической науке. Например, недавно цифровые историки вместе со специалистами по computer science проанализировали 45 тысяч стенограмм Национальной конституционной ассамблеи 1789–1790 годов. Они хотели изучить механизмы работы новорожденной парламентской демократии и понять, чем отличались пламенные ораторы вроде Робеспьера от менее ярких персонажей.
Национальная конституционная ассамблея — это первый парламент Франции после начала Великой французской революции. Из нее родились все последующие французские парламенты, а они, в свою очередь, стали моделью для большинства парламентских демократий, существующих по сей день. Даже привычное нам деление на «правых» и «левых» происходит оттуда: радикалы сидели слева, консерваторы-монархисты — справа.
Авторы исследования применили к парламентским стенограммам методы тематического моделирования — автоматического выделения содержательных тем в коллекции текстов. На основе этих методов они разработали два статистических показателя, по которым можно сравнивать речи парламентариев:
- новизна — насколько нова тематика данного выступления по сравнению со всем, что уже было сказано в парламенте до того;
- недолговечность, преходящесть — насколько тема данного выступления воспроизводится в речах, произнесенных после него, то есть насколько оратору удалось повлиять на повестку парламента.
Исследование показало, что большей новизной обладали представители левого радикального крыла (в числе рекордсменов и Робеспьер). У консерваторов-монархистов новизна выступлений заметно ниже. То есть консерваторы выполняли во французском парламенте свою прямую функцию — «консервировали» политическую повестку в одном русле. Благодаря такой последовательности их речи были куда более «долговечными»: консервативные идеи поддерживались другими монархистами и не исчезали из обсуждений. Таким образом, методы анализа данных оказались способны различить политические спектры.
Несмотря на старания консерваторов, радикальные политики доминировали в первом парламенте революционной Франции. Национальная конституционная ассамблея фонтанировала новыми идеями, которые быстро сменяли друг друга. Поэтому в большинстве выступлений сочетались высокая новизна и недолговечность поднятой темы. Однако ученые обнаружили и исключения, когда новое прочно закреплялось в повестке. Чтобы найти такие кейсы, авторы статьи ввели третий показатель —
резонанс
, своеобразный баланс новизны и долговечности. Высокий резонанс означает, что поднятые в речи вопросы обладают определенной новизной, но при этом тема не была забыта, а многократно обсуждалась в последующих речах.
Как выяснилось, именно высокий резонанс — свойство ключевых фигур Национальной конституционной ассамблеи, причем как радикалов (Робеспьер, Петион де Вильнёв), так и консерваторов-монархистов (Жан-Сифрен Мори).
За счет высокой долговечности тем консерваторы могли иметь не менее высокие показатели резонанса, несмотря на пониженную новизну их речей.
В отличие от филологов, историки гораздо меньше сфокусированы на текстах — для них это лишь один из множества источников.
Другой важный для историка ресурс — это изображения.
Ученые еще только начинают обрабатывать визуальную часть исторических архивов при помощи методов анализа данных, но интересные проекты на стыке компьютерного зрения и истории уже существуют.
Один из них — голландский проект SIAMESE. Его авторы применили свёрточные нейронные сети, которые лежат в основе всех современных систем компьютерного зрения (распознавание лиц, перенос стиля, беспилотные автомобили), чтобы проанализировать изображения из газет. В базу ввели 426 777 изображений из двух влиятельных голландских газет Algemeen Handelsblad и NRC Handelsblad за период с 1945 по 1995 год. Нейросети, натренированные на гигантской, но исключительно современной базе размеченных изображений ImageNet, оказались не слишком хороши в распознавании конкретных объектов. Зато они помогают исследователям группировать похожие изображения. Это дает большой простор, например, для исследования разных типов рекламы: ученые смогли проанализировать, как американскую рекламу адаптировали под голландскую аудиторию во время послевоенной «американизации» массовой культуры Нидерландов.

Искусство
Инструменты анализа данных можно применять и в искусствоведении. Недавно команда исследователей при помощи алгоритмов компьютерного зрения проанализировала 137 000 картин из коллекции WikiArt. На основе цветовых параметров вычислили два показателя для каждого полотна. Первый отражал визуальную
сложность
изображения: учитывалось количество объектов на картинке, число сложных форм и границ. Второй показывал
энтропию
— уровень непредсказуемости каждого пикселя по отношению к соседним. Этот параметр в чем-то схож с понятием избыточности текста, которое применяли стэнфордские литературоведы. Высокой энтропией и низкой сложностью будет обладать, например, полотно с градиентной заливкой.
Авторы исследования взяли свои метрики не с потолка — они вдохновлялись наработками искусствоведов докомпьютерной эпохи. Сложность связана со шкалой «линейное — живописное» Генриха Вёльфлина, энтропия — с разграничением гаптического (осязательного) и оптического у Алоиза Ригля. Создав цифровые аналоги этих искусствоведческих измерителей, ученые смогли провести массовый анализ художественного творчества.
Выяснилось, что при переходе к модерну у картин повышается энтропия и понижается сложность.
Исследователи считают, что им удалось формализовать меньшую «предметность» и более вольный стиль полотен импрессионистов, фовистов и пуантилистов по сравнению с домодернистской живописью ренессанса, неоклассицизма и романтизма.
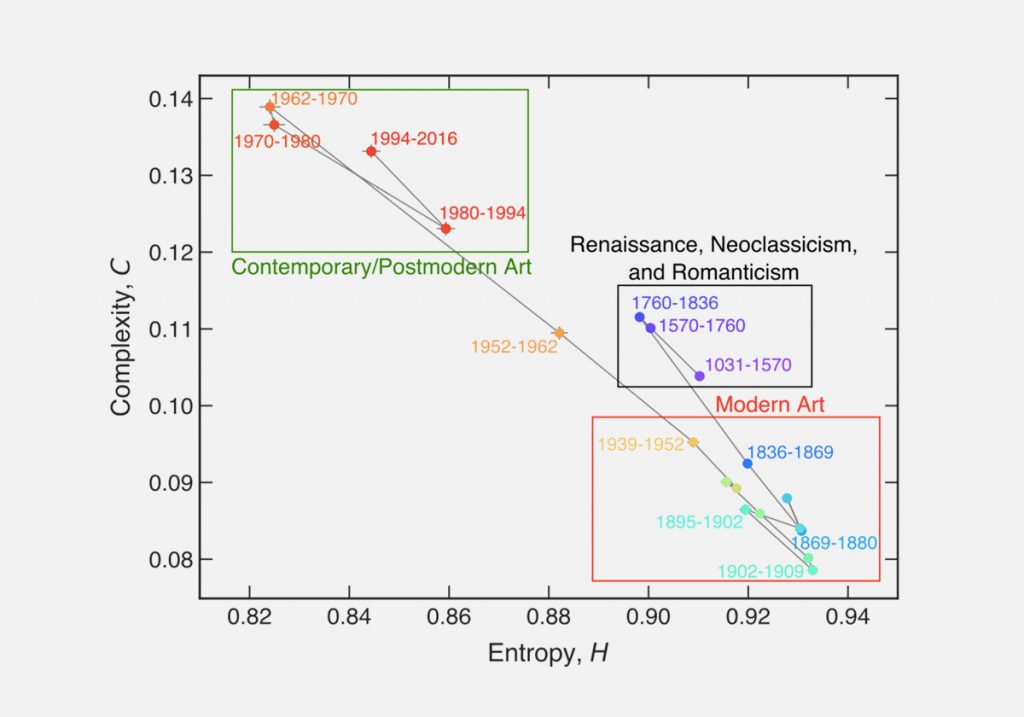
Как видим, при переходе от модерна к постмодернистскому/современному искусству сложность вновь повышается, а энтропия падает. Авторы полагают, что это отражение того, что в современном искусстве часто изображают простые обыденные предметы с конкретными очертаниями.
Возьмем примеры, например, из ренессанса, фовизма и hard edge painting типа такого:

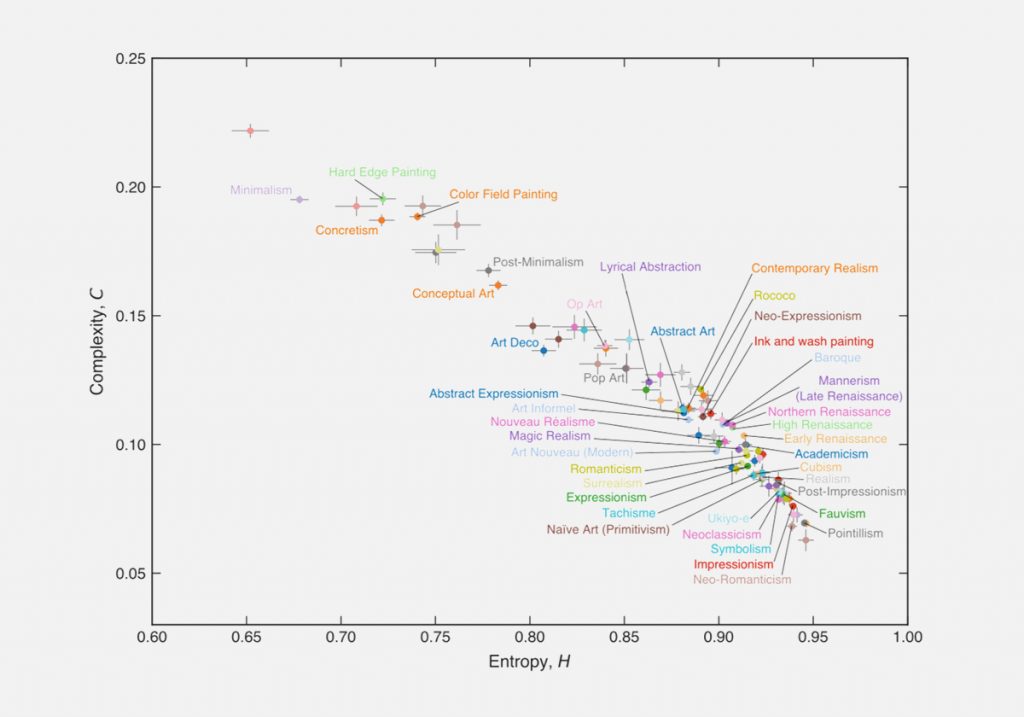
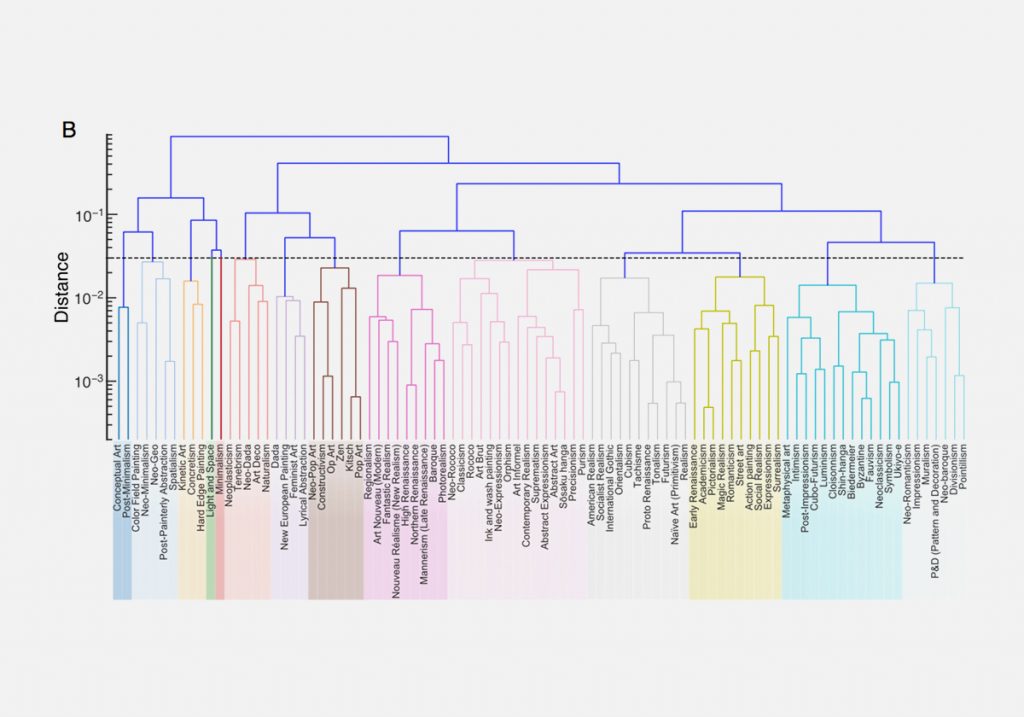
На основе тех же признаков энтропии и сложности исследователи произвели иерархическую кластеризацию художественных направлений. Так они вывели новую альтернативную классификацию направлений в искусстве, которая основывается на объективных данных о сходстве стиля картин:
Телеграм: t.me/ainewsline
Источник: knife.media