Алгоритм Дейкстры для поиска кратчайшего пути в Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-03-27 15:18

Что делает алгоритм Дейкстры
Алгоритм Дейкстры находит кратчайший путь между двумя вершинами графа. Следовательно, если математические задачи моделируется при помощи графа, используя алгоритм Дейкстры, можно найти кратчайший путь между вершинами.
Создание графа для алгоритмы Дейкстры
Важно понимать, граф представляет собой множество узлов (nodes), соединенных ребрами (edges).
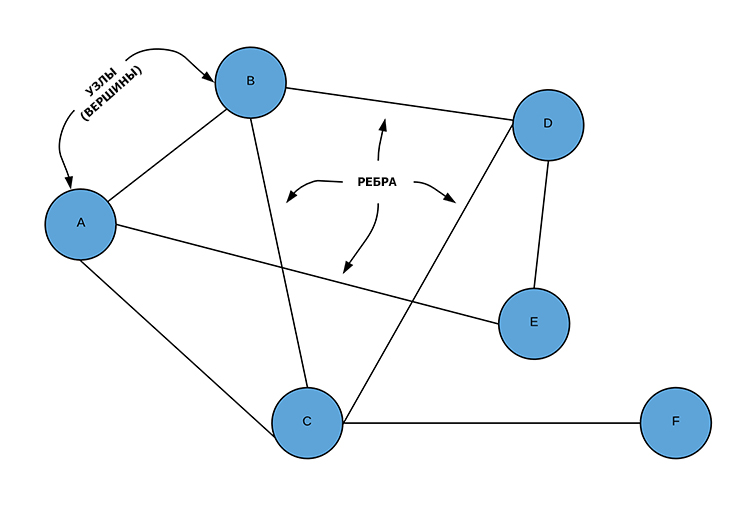
Узел — это просто какой-то объект, а ребро — это связь между двумя узлами. Выше представлен неориентированный граф, то есть без четких направлений, и здешние ребра являются двунаправленными. Существуют также ориентированные графы, у ребер которых есть конкретно указанное направление.
Как узлы, так и ребра могут быть носителями информации. К примеру, граф выше представляет собой систему зданий, которые соединены между собой туннелями. В узлах может находиться информация о названии здания (например, строка «Библиотека»), в то время, как ребро может содержать информацию о длине туннеля.
Теория и практика. Быстрая проверка задач и подсказки к ошибкам на русском языке. Работает в любом современном браузере.
Графам можно найти удачное применение в огромном количестве востребованных областей: веб-страницы (узлы) с ссылками на другие страницы (ребра), маршрутизация пакетов в сетях, социальные сети, приложения для создания карт улиц, моделирование молекулярных связей, различные области математики, лингвистика, социология. В общем и целом, это может быть любая система, в которой оперируют связанные между собой объекты.
Реализация графов в Python
Данный этап немного выходит за рамки темы, рассматриваемой в статье, поэтому мы не будем вдаваться в подробности. Два самых популярных способа реализации графа — через матрицу смежности или через список смежности. У каждого метода есть свои преимущества и недостатки. Сначала рассмотрим реализацию через матрицу смежности, так как его проще представить визуально и понять на интуитивном уровне. Позже станет яснее, отчего определение базовой реализации оказывает сильное влияние на время выполнения. Любая реализация может задействовать алгоритм Дейкстры, а пока важно различать API, или абстракции (методы), которые могут взаимодействовать с графом. Кратко осветим реализацию матрицы смежности на примере кода Python. Для ознакомления с реализацией списка смежности хорошим стартом станет данная статья.
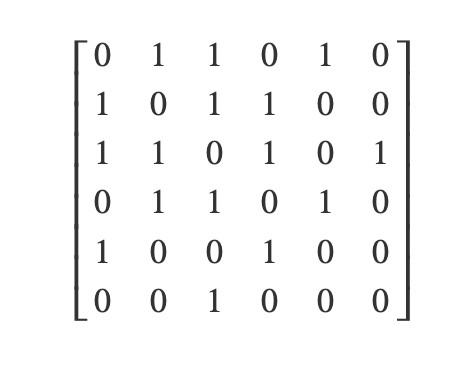
Ниже представлена матрица смежности для предыдущего графа. Каждый ряд представляет один узел графа, как и каждый столбец. В данном случае ряд 0 и столбец 0 представляют узел «А»; ряд 1 и столбец 1 — узел «B», ряд 2 и столбец 2 — узел «C» и так далее, принцип понятен. Каждый локальный элемент {ряд, столбец} представляет ребро. Таким образом, каждый ряд показывает связь между одним узлом и всеми прочими узлами. Элемент «0» указывает на отсутствие ребра, в то время как «1» указывает на присутствие ребра, связывающего row_node и column_node в направлении row_node ? column_node. Поскольку граф в примере является неориентированным, данная матрица равна его транспонированию (то есть матрица симметричная), поскольку каждая связь двунаправленная. Вы могли заметить, что главная диагональ матрицы представлена только нулями, а все оттого, что ни один узел не связан сам с собой. Таким образом, пространственная сложность данного представления нерасчетлива.
Теперь разберемся с кодом. Обратите внимание, что здесь задействовано немного экстра-данных — так как нам было нужно, чтобы реальные объекты узлов содержали определенную информацию, в классе Graph был реализован массив объектов узлов, индексы которых соответствуют номеру их ряда (столбца) в матрице смежности. В Graph также был добавлен вспомогательный метод, который позволяет использовать либо номера индекса узла, либо объект узда в качестве аргументов для методов класса Graph. Данные классы нельзя считать примерами элегантности, однако они хорошо выполняют свою работу, излишне не усложняя процесс:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | classNode: def__init__(self,data,indexloc=None): self.data=data self.index=indexloc classGraph: @classmethod defcreate_from_nodes(self,nodes): returnGraph(len(nodes),len(nodes),nodes) def__init__(self,row,col,nodes=None): # установка матрица смежности self.adj_mat=[[0]*col for_inrange(row)] self.nodes=nodes foriinrange(len(self.nodes)): self.nodes[i].index=i # Связывает node1 с node2 # Обратите внимание, что ряд - источник, а столбец - назначение # Обновлен для поддержки взвешенных ребер (поддержка алгоритма Дейкстры) defconnect_dir(self,node1,node2,weight=1): node1,node2=self.get_index_from_node(node1),self.get_index_from_node(node2) self.adj_mat[node1][node2]=weight # Опциональный весовой аргумент для поддержки алгоритма Дейкстры defconnect(self,node1,node2,weight=1): self.connect_dir(node1,node2,weight) self.connect_dir(node2,node1,weight) # Получает ряд узла, отметить ненулевые объекты с их узлами в массиве self.nodes # Выбирает любые ненулевые элементы, оставляя массив узлов # которые являются connections_to (для ориентированного графа) # Возвращает значение: массив кортежей (узел, вес) defconnections_from(self,node): node=self.get_index_from_node(node) return[(self.nodes[col_num],self.adj_mat[node][col_num])forcol_num inrange(len(self.adj_mat[node]))ifself.adj_mat[node][col_num]!=0] # Проводит матрицу к столбцу узлов # Проводит любые ненулевые элементы узлу данного индекса ряда # Выбирает только ненулевые элементы # Обратите внимание, что для неориентированного графа # используется connections_to ИЛИ connections_from # Возвращает значение: массив кортежей (узел, вес) defconnections_to(self,node): node=self.get_index_from_node(node) column=[row[node]forrow inself.adj_mat] return[(self.nodes[row_num],column[row_num])forrow_num inrange(len(column))ifcolumn[row_num]!=0] defprint_adj_mat(self): forrow inself.adj_mat: print(row) defnode(self,index): returnself.nodes[index] defremove_conn(self,node1,node2): self.remove_conn_dir(node1,node2) self.remove_conn_dir(node2,node1) # Убирает связь в направленной манере (nod1 к node2) # Может принять номер индекса ИЛИ объект узла defremove_conn_dir(self,node1,node2): node1,node2=self.get_index_from_node(node1),self.get_index_from_node(node2) self.adj_mat[node1][node2]=0 # Может пройти от node1 к node2 defcan_traverse_dir(self,node1,node2): node1,node2=self.get_index_from_node(node1),self.get_index_from_node(node2) returnself.adj_mat[node1][node2]!=0 defhas_conn(self,node1,node2): returnself.can_traverse_dir(node1,node2)orself.can_traverse_dir(node2,node1) defadd_node(self,node): self.nodes.append(node) node.index=len(self.nodes)-1 forrow inself.adj_mat: row.append(0) self.adj_mat.append([0]*(len(self.adj_mat)+1)) # Получает вес, представленный перемещением от n1 # к n2. Принимает номера индексов ИЛИ объекты узлов defget_weight(self,n1,n2): node1,node2=self.get_index_from_node(n1),self.get_index_from_node(n2) returnself.adj_mat[node1][node2] # Разрешает проводить узлы ИЛИ индексы узлов defget_index_from_node(self,node): ifnotisinstance(node,Node)andnotisinstance(node,int): raiseValueError("node must be an integer or a Node object") ifisinstance(node,int): returnnode else: returnnode.index |
Здесь классы Node и Graph будут использованы для описания данного примера графа. Поместим вышеуказанный граф в код и посмотрим, получится ли в итоге верная матрица смежности:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | a=Node("A") b=Node("B") c=Node("C") d=Node("D") e=Node("E") f=Node("F") graph=Graph.create_from_nodes([a,b,c,d,e,f]) graph.connect(a,b) graph.connect(a,c) graph.connect(a,e) graph.connect(b,c) graph.connect(b,d) graph.connect(c,d) graph.connect(c,f) graph.connect(d,e) graph.print_adj_mat() |
Матрицы смежности, полученная в выводе (из graph.print_adj_mat()) после запуска кода, такая же, как и та, что была рассчитана ранее:
Shell
1 2 3 4 5 6 | [0,1,1,0,1,0] [1,0,1,1,0,0] [1,1,0,1,0,1] [0,1,1,0,1,0] [1,0,0,1,0,0] [0,0,1,0,0,0] |
При желании добавить расстояние ребрам графа нужно просто заменить единицы в данной матрице смежности на значения нужного расстояния. На данный момент класс Graph поддерживает данную функциональность, доказательством чему является код ниже. Для ясности демонстрации были добавлены произвольные значения длины:
Python
1 2 3 4 5 6 7 8 9 10 11 12 | w_graph=Graph.create_from_nodes([a,b,c,d,e,f]) w_graph.connect(a,b,5) w_graph.connect(a,c,10) w_graph.connect(a,e,2) w_graph.connect(b,c,2) w_graph.connect(b,d,4) w_graph.connect(c,d,7) w_graph.connect(c,f,10) w_graph.connect(d,e,3) w_graph.print_adj_mat() |
В результате выводится следующая матрица смежности:
Shell
1 2 3 4 5 6 | [0,5,10,0,2,0] [5,0,2,4,0,0] [10,2,0,7,0,10] [0,4,7,0,3,0] [2,0,0,3,0,0] [0,0,10,0,0,0] |
Визуально данный граф будет представлен следующим образом:
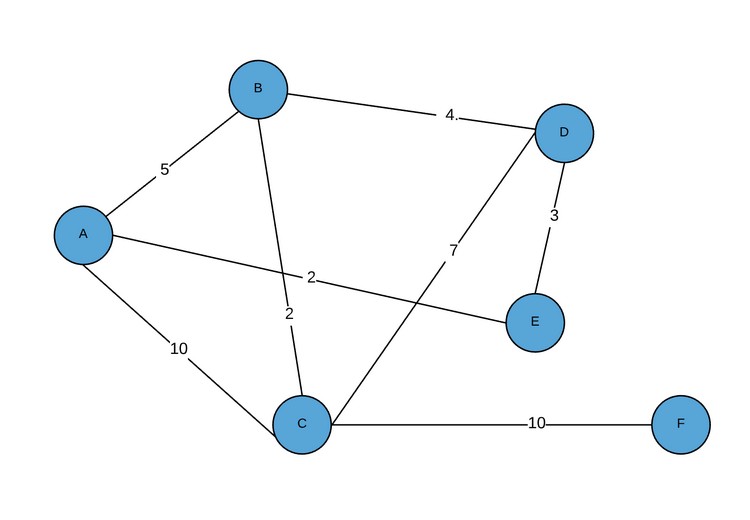
Для того чтобы ребра содержали больше информации, нужно чтобы матрица содержала объекты ребер вместо простых целых чисел.
Алгоритм Дейкстры
Перед непосредственным составлением кода, осветим ключевые моменты темы:
- Главное условие: отрицательных длин ребер не бывает.
- Алгоритм Дейкстры изначально создавался для поиска кратчайшего пути между двумя конкретными узлами. Однако сегодня он также широко используется для поиска кратчайших путей между узлом источника и всеми остальными узлами. В статье будет рассмотрен второй вариант. Для осуществления первого случая понадобится просто остановить алгоритм сразу после того, как узел назначения будет добавлен в набор
seen. По ходу дела все станет намного понятнее.
Окей, примемся за дело. Нам нужно найти исходным узлом и всеми другими узлами (или узлом назначения), однако проверять КАЖДУЮ возможную комбинацию отправления-назначения не хочется. При наличии крупного графа на это потребуется огромное количество времени, и большая часть проверенных путей в конечном итоге окажется ненужной. По этой причине, пойдем напролом и задействуем жадный подход. Наслаждайтесь моментом, ведь это тот редкий случай, когда жадность будет вознаграждена.
Итак, что мы понимаем под жадным алгоритмом? По сути, это значит, что принятые решения будут обусловлены самым оптимальным выбором на данный конкретный момент времени. Метод подойдет далеко не для каждого случая. К примеру, при реализации шахматного бота фокус точно не пройдет — зачем брать враждебного ферзя, если через ход это обернется шахом со стороны противника. Для таких ситуаций больше подойдет minimax. В рассматриваемом сейчас случае жадный алгоритм действительно является наилучшим вариантом, который значительно сокращает число проверок, что нужно совершить без потери точности. Как?
Скажем, мы находимся в исходном узле. Предположим, что начальное предварительное расстояние от узла источника до каждого другого узла в графе является бесконечностью (перепроверим позже). Известно, что по умолчанию расстояние от узла источника до этого же узла источника минимально (0), ведь отрицательных длин ребер быть не может. Наш исходный узел осматривает все соседние узлы и обновляет предварительное расстояние от узла источника до длины ребра от узла источника до конкретного соседнего элемента (плюс 0). Обратите внимание, что НУЖНО проверить каждого ближайшего соседа, этого никак не пропустить. Затем алгоритм делает тот самый жадный выбор для следующей оценки узла, который находится на ближайшем расстоянии к источнику. У нас исходный узел отмечен как visited, поэтому к нему можно не возвращаться и сразу перейти к следующему узлу.
Теперь задумаемся, где мы сейчас находимся в плане логики, так как это важно для реализации. Узел, что сейчас оценивается (ближайший к источнику) больше НИКОГДА не будет оцениваться вновь в плане кратчайшего пути от исходного узла. Его предварительное расстояние теперь стало точным расстоянием. Хотя вполне возможно, что пути от исходного узла к данному узлу могут проходить через иные маршруты, можно с уверенностью сказать, что они будут затратнее, нежели текущий путь. Он был выбран ввиду того, что был кратчайшим по сравнению с любым другим узлом, связанным с источником. Следовательно, любой другой путь будет длиннее, чем текущее расстояние от исходного узла до рассматриваемого узла.
При использовании графика из примера в случае установки исходного узла как А, мы бы назначили предварительные расстояния для узлов B, C и E. Поскольку у E было кратчайшее расстояние от A, после этого был посещен узел E. И теперь, хотя наверняка есть несколько других способов добраться из А до Е, они будут затратнее, нежели текущее расстояние А ? Е. Другие маршруты должны проходить через B или С, а в результате проверки стало ясно, что они дальше от A, чем E. Жадный выбор был сделан, а это ограничивает общее количество проверок, которые нам нужно сделать, и при этом точность не теряется. Неплохо.
Продолжим логическую цепочку с использованием графа из примера. Просто повторим для E действия, сделанные для A. Обновляются все ближайшие соседние элементы к E с предварительным расстоянием, равным length(A у E) + edge_length(E к соседнему элементу). Это верно в том случае, ЕСЛИ данное расстояние меньше, чем текущее предварительное расстояние, или же предварительное расстояние еще не было установлено.
Обратите внимание: Для достижения данной функциональности здесь просто инициализируются все предварительные расстояния до бесконечности.
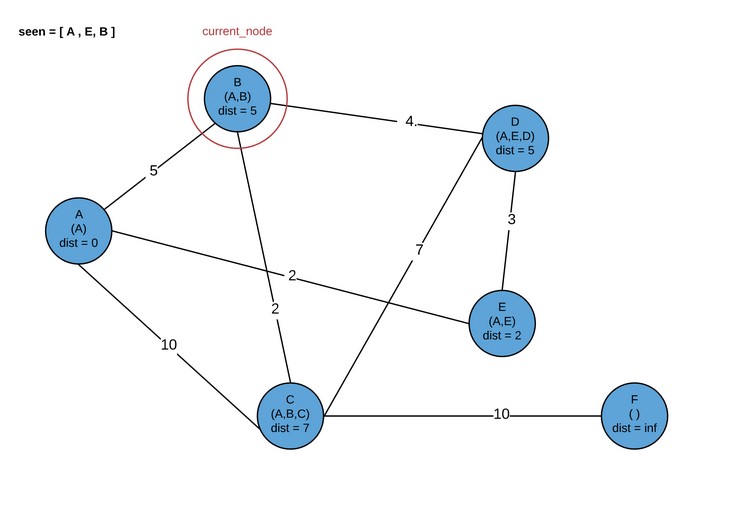
Далее делается жадный выбор касательно того, какой узел должен оцениваться следующим. Выбирается один узел из графа с наименьшим предварительным расстоянием, и добавляется E к набору seen nodes. Теперь он повторно оцениваться не будет. У данного нового узла та же гарантия, что что и E — его предварительное расстояние от A является определенным минимальным расстоянием от A. Чтобы понять это, давайте оценим возможности (хотя они могут не соответствовать графу примера, для ясности используем те же названия). Если следующий узел является соседом E, но не A, то он будет выбран, потому что его временное расстояние все еще короче, чем любого другого прямого соседа A. По этой причине нет другого возможного кратчайшего пути, только через E. Если следующий выбранный узел будет непосредственным соседом A, то есть вероятность, что этот узел обеспечит более короткий путь к некоторым из соседей E, чем сам E.
Обзор кода алгоритма Дейкстры на Python
Давайте более четко и формально рассмотрим процесс реализации алгоритма Дейкстры.
ИНИЦИАЛИЗАЦИЯ
- Установите
provisional_distanceдля всех узлов от исходного узла до бесконечности. - Определите пустой набор
seen_nodes. Данный набор гарантирует, что узел, у которого уже есть кратчайший путь, не будет повторно рассмотрен, а также то, что не будут рассматриваться пути через узел, у которого более короткий путь к источнику, чем текущий путь. Помните, что узлы входят вseen_nodesтолько после доказательства того, что в наличии есть абсолютное кратчайшее расстояние (а не только предварительное расстояние). Набор используется для получения времени поискаO(1)вместо многократного выполнения поиска через массивO(n). - Установите
provisional_distanceдля исходного узла со значением 0, и массив, представляющий перескоки для простого включения самого исходного кода. Это будет полезно позже, когда мы проследим выбранный для графа путь для расчета минимального расстояния.
ПРОЦЕДУРА ИТЕРАЦИИ
- Пока (while) все узлы увидеть (
seen) не удалось. Или, в случае поиска одного узла назначения, пока не удалось увидеть (seen) данный узел назначения. - Установите
current_nodeдля узла c самым малым предварительным расстояниемprovisional_distanceво всем графе. Обратите внимание, что для первой итерации это будет исходный узелsource_node, так как предварительное расстояниеprovisional_distanceустановлено на 0. - Добавьте текущий узел
current_nodeк набору просмотренных узловseen_nodes. - Обновите
provisional_distanceкаждого соседнего элементаcurrent_nodeдо (абсолютного) расстояния отcurrent_nodeдоsource_nodeвдобавок к длине ребра отcurrent_nodeк данному соседнему элементу, ЕСЛИ данное значение меньше, чем текущее значение соседнегоprovisional_distance. Если у соседнего элемента еще не было набора предварительного расстояния, помните, что он инициализирован до бесконечности, и по этой причине должен быть больше, чем данная сумма. При обновленииprovisional_distanceтакже обновляются «перескоки», которые были сделаны для получения расстояния, задействуя конкатенацию перескоковcurrent_nodeк исходному узлу с самимcurrent_node. - Завершение цикла while.
Алгоритм Дейкстры через схемы и изображения
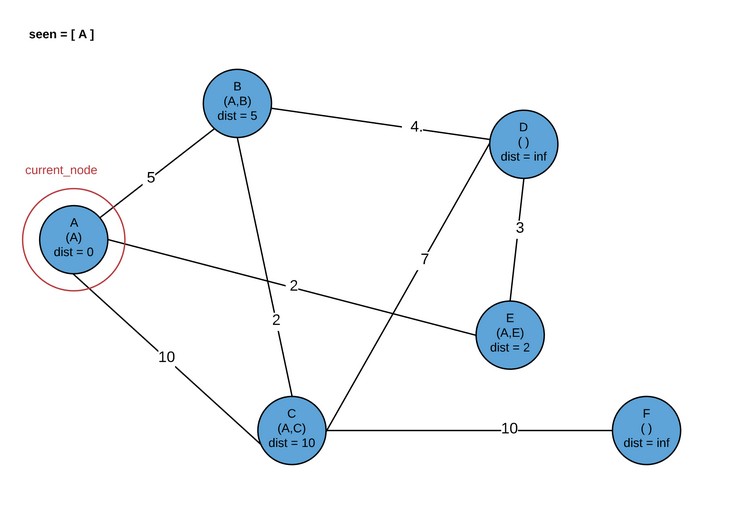
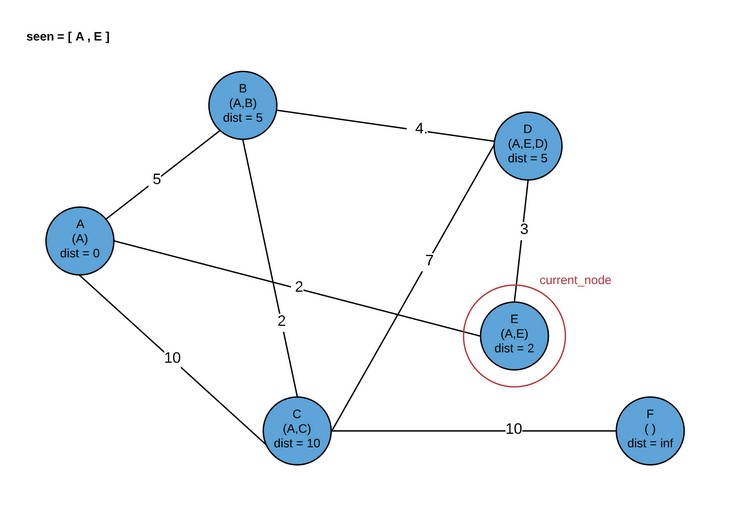
Обратите внимание, что в дальнейшем можно посетить либо D, либо B. Сейчас мы посетим B.
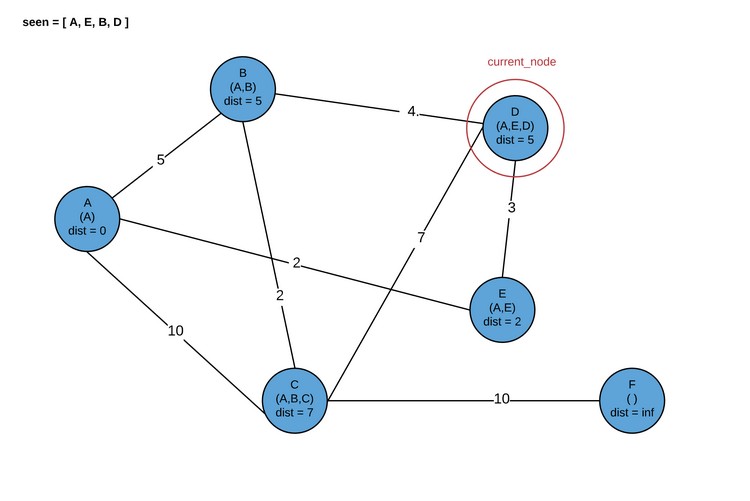
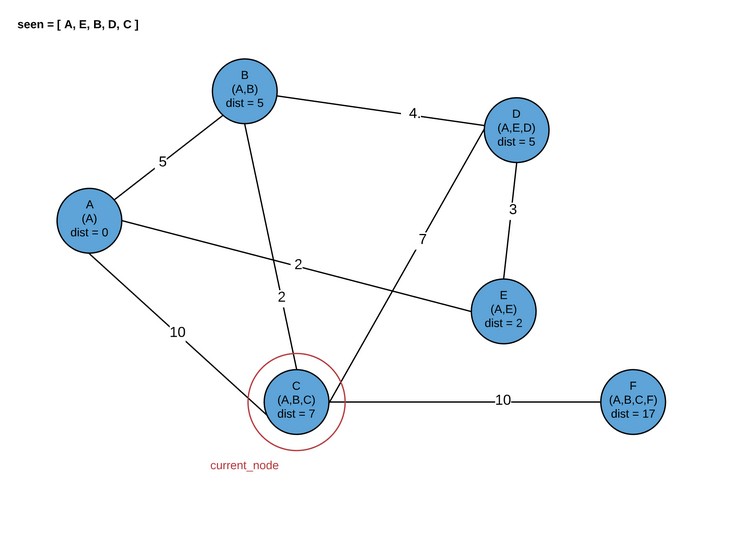
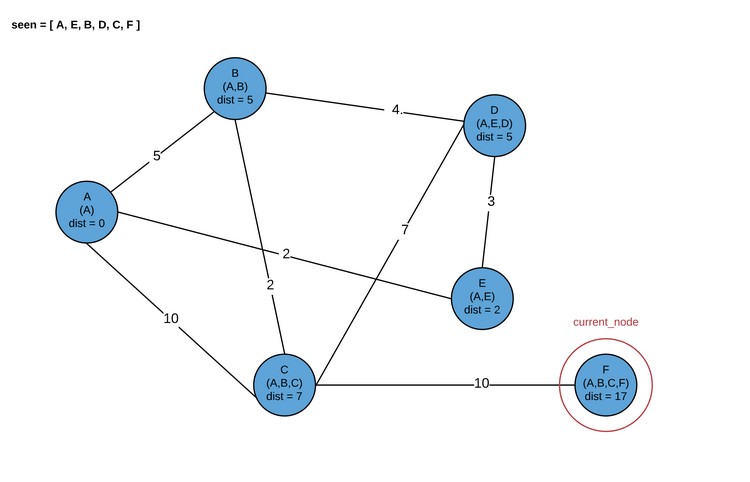
Здесь программа завершается. В результате мы получаем кратчайшие пути для каждого узла графа.
Python код для алгоритма Дейкстры
Посмотрим, как будет выглядеть реализация алгоритма Дейстры в Python. Это экземпляр метода внутри раннее используемого класса Graph, который задействует преимущества других методов и структуры:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | defdijkstra(self,node): # Получает индекс узла (или поддерживает передачу int) nodenum=self.get_index_from_node(node) # Заставляет массив отслеживать расстояние от одного до любого узла # в self.nodes. Инициализирует до бесконечности для всех узлов, кроме # начального узла, сохраняет "путь", связанный с расстоянием. # Индекс 0 = расстояние, индекс 1 = перескоки узла dist=[None]*len(self.nodes) foriinrange(len(dist)): dist[i]=[float("inf")] dist[i].append([self.nodes[nodenum]]) dist[nodenum][0]=0 # Добавляет в очередь все узлы графа # Отмечает целые числа в очереди, соответствующие индексам узла # локаций в массиве self.nodes queue=[iforiinrange(len(self.nodes))] # Набор увиденных на данный момент номеров seen=set() whilelen(queue)>0: # Получает узел в очереди, который еще не был рассмотрен # и который находится на кратчайшем расстоянии от источника min_dist=float("inf") min_node=None forninqueue: ifdist[n][0]<min_dist andnnotinseen: min_dist=dist[n][0] min_node=n # Добавляет мин. расстояние узла до увиденного, убирает очередь queue.remove(min_node) seen.add(min_node) # Получает все следующие перескоки connections=self.connections_from(min_node) # Для каждой связи обновляет путь и полное расстояние от # исходного узла, если полное расстояние меньше # чем текущее расстояние в массиве dist for(node,weight)inconnections: tot_dist=weight+min_dist iftot_dist<dist[node.index][0]: dist[node.index][0]=tot_dist dist[node.index][1]=list(dist[min_node][1]) dist[node.index][1].append(node) returndist |
При использовании данного метода можно протестировать нашу картинку:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | a=Node("A") b=Node("B") c=Node("C") d=Node("D") e=Node("E") f=Node("F") w_graph=Graph.create_from_nodes([a,b,c,d,e,f]) w_graph.connect(a,b,5) w_graph.connect(a,c,10) w_graph.connect(a,e,2) w_graph.connect(b,c,2) w_graph.connect(b,d,4) w_graph.connect(c,d,7) w_graph.connect(c,f,10) w_graph.connect(d,e,3) print([(weight,[n.data forninnode])for(weight,node)inw_graph.dijkstra(a)]) |
Для получения читабельного для людей вывода нужно отметить объекты узла в их data. Результат станет следующим:
Shell
1 | [(0,[‘A’]),(5,[‘A’,‘B’]),(7,[‘A’,‘B’,‘C’]),(5,[‘A’,‘E’,‘D’]),(2,[‘A’,‘E’]),(17,[‘A’,‘B’,‘C’,‘F’])] |
Здесь каждый кортеж — (total_distance, [hop_path]). Это совпадает с рассматриваемой картинкой.
Быстрый способ реализации алгоритма Дейкстры в Python
На данный момент тем, кто заинтересован только в функциональности, хватит предоставленного материала. Однако, тем, кому важна скорость стоит продолжить чтение.
Остановимся на одном довольно важном моменте. В каждой итерации нам нужно найти узел с кратчайшим предварительным расстоянием, что требуется для следующего жадного решения. Сейчас осматривается list, вызывая queue (используя данные значения в dist) с целью получения желаемого. У данного queue может быть максимальная длина n, что является числом узлов. Итерация по этому списку является операцией O(n), которую мы выполняем в каждой итерации цикла while. Так как цикл while продолжается до тех пор, пока не будет просмотрен (seen) каждый узел, сейчас операция O(n) совершается n раз. Наш алгоритм — O(n2). Это не очень хорошо, но и это не все.
Если взглянуть на реализацию матрицы смежности в Graph, можно заметить, что для нахождения связи нам пришлось осмотреть весь ряд (размера n). Это еще одна операция O(n) в цикле while. Как это исправить? Во-первых, можно использовать кучу для получения минимального предварительного расстояния в O(lg(n)) времени вместо O(n) времени (при бинарной куче — отметьте, что куча Фибоначчи способна на это в O(1)). Во-вторых, можно реализовать граф при помощи списка смежности, где у каждого узла есть список связанных узлов. Получается, что осматривать все узлы на наличие существующей связи не потребуется. Это показывает, почему важно понимать то, как мы представляем структуры данных. В случае реализаци кучи при помощи представления матрицы смежности асимптомическое время выполнения запуска алгоритма изменено не будет. (На заметку: Если вам не знакома нотация big-O, можете просмотреть данную статью).
Кучи в Python
Такая структура данных, как куча, обычно используется для реализации очереди с приоритетом. По сути, они эффективны во время ситуаций, когда нужно быстро получить элемент с наивысшим приоритетом. В нашем случае элемент с высоким приоритетом — это наименьшее предварительное расстояние (provisional distance) от оставшихся нерассмотренных узлов. Вместо того, чтобы каждый раз осматривать весь массив в поисках наименьшего предварительного расстояния (provisional distance), можно использовать находящуюся там кучу, что готова передать узел с наименьшим предварительным расстоянием (provisional distance). Как только расстояние будет извлечено из кучи, она быстро перестоится, будучи готовой к передаче нового значения в тот момент, когда оно будет нужно. Довольно неплохо! Для практики можете попробовать реализовать очень быструю Фибоначчиеву кучу. А далее мы попробуем реализовать Binary MinHeap, что поможет разрешить наши задачи.
По сути бинарная куча является полным бинарным деревом, что обладает свойством кучи. Что это значит?
Полное бинарное дерево — это структура в виде дерева данных, где у КАЖДОГО родителя узла есть ровно два дочерних узла. Если дочерних узлов недостаточно, чтобы в последнем ряду родительских узлов было по 2 дочерних узла, дочерние узлы будут заполняться слева направо.
Как это будет выглядеть?
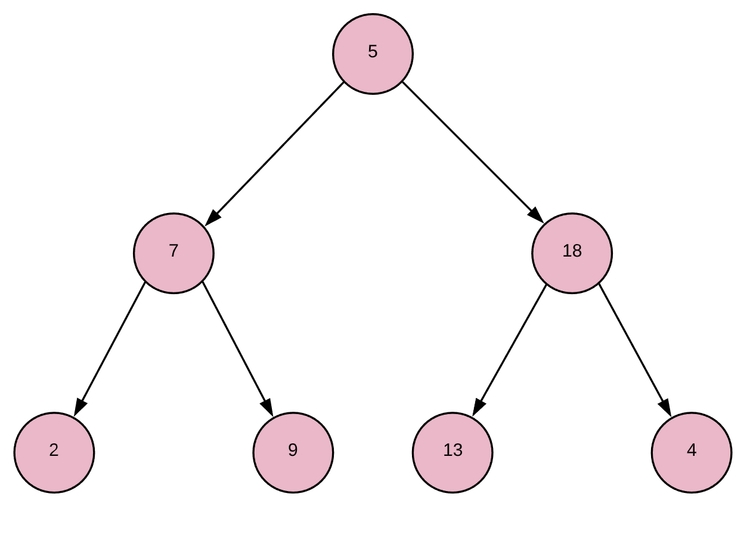
Свойство кучи (для минимальной кучи) Каждый родитель ДОЛЖЕН быть меньше или равен обоим дочерним элементам.
Применив данный принцип к указанному выше полному бинарному дереву, мы получим следующий результат:
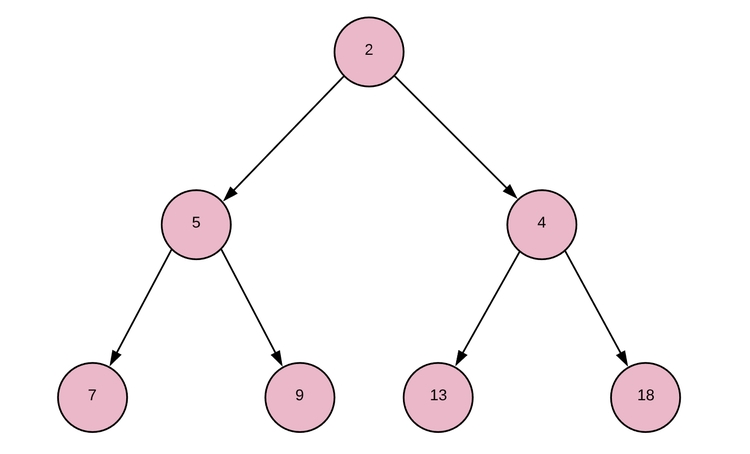
Здесь представлен базовый массив [2, 5, 4, 7, 9, 13, 18]. Как видите, сортировка сделана наполовину, но в данном случае нам и не нужна полная сортировка. Через минуту данный базовый массив станет намного понятнее.
Теперь у нас есть представление о том, что из себя представлят куча. Напишем код и посмотрим, как используются дополнительные методы для реализации требуемых пользователю действий.
Так как бинарная куча является специальной реализацией бинарного дерева, начнем с создания класса BinaryTree, у которого будет наследовать рассматриваемая куча. Для реализации бинарного дерева нужно создать базовую структуру данных в виде массива, после чего структура дерева будет рассчитана через индексы узлов внутри массива. К примеру, у начального бинарного дерева (первое изображение полного бинарного дерева) базовый массив будет [5, 7, 18, 2, 9, 13, 4]. Мы обозначим связи между узлами при определении индекса узла в базовом массиве. Известно, что у каждого родителя ровно два дочерних элемента. Нулевой индекс является корнем в основе, индекс 1 — левый ребенок, а индекс 2 — правый ребенок. Если обобщить, левый ребенок индекса i будет обладать индексом 2*i + 1, а правый — 2*i + 2. У узла индекса i родительский индекс — floor((i-1) / 2).
Итак, класс BinaryTree будет выглядеть следующим образом:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | classBinaryTree: def__init__(self,nodes=[]): self.nodes=nodes defroot(self): returnself.nodes[0] defiparent(self,i): return(i-1)//2 defileft(self,i): return2*i+1 defiright(self,i): return2*i+2 defleft(self,i): returnself.node_at_index(self.ileft(i)) defright(self,i): returnself.node_at_index(self.iright(i)) defparent(self,i): returnself.node_at_index(self.iparent(i)) defnode_at_index(self,i): returnself.nodes[i] defsize(self): returnlen(self.nodes) |
Теперь MinHeap может наследовать BinaryTree и задействовать требуемую функциональность. Теперь BinaryTree можно будет вновь использовать в иных контекстах.
Окей, мы практически у финала. Сейчас нужно будет идентифицировать способности класса, который должны быть у класса MinHeap, а затем реализовать их. Необходимо, чтобы куча могла:
- Измениться, вместо неупорядученного бинарного дерева став минимальной кучей. Это делается через конкретизацию кучи;
- Получите минимальное значение, а затем реструктурироваться для сохранения своих свойств. Это будет использоваться при посещении следующего узла;
- Обновить (уменьшить) значение узла, сохранив свойство кучи. Это будет использоваться при обновлении предварительных расстояний.
Для осуществления данных условий начнем с создания блока, который сыграет важную роль при реализации первых двух функций. Напишем метод под названием min_heapify_subtree. Данный метод будет рассматривать всю кучу как heapified (то есть при этом поддерживая свойство кучи), кроме единственного узла 3-го поддерева. Мы будем рекурсивно накапливать это поддерево, идентифицируя его индекс родительского узла в точке i и давая возможность правильно размещенному узлу найти верную позицию в куче. Для этого проверяем, меньше ли дочерние узлы, чем родительский. Если да, заменяем наименьший дочерний узел с родительским. Затем рекурсивно вызываем метод по индексу замененного родителя (который теперь является дочерним), чтобы убедиться, что он помещен в позицию для поддержки свойства кучи. Вот псевдокод:
Shell
1 2 3 4 5 6 7 8 9 10 11 12 13 | FUNCTIONmin_heapify_subtree(i) index_of_min=i IFleft_child exists ANDleft_child<node[index_of_min] index_of_min=left_child_index ENDIF IFright_child exists ANDright_child<node[index_of_min] index_of_min=right_child_index ENDIF IFindex_of_min!=i swap(nodes[i],nodes[index_of_min]) min_heapify_subtree(index_of_min) ENDIF END |
В худшем случае метод начинается с индекса 0 и рекурсивно распространит корневой узел вплоть до нижнего листа. Поскольку здесь куча является бинарным деревом, у нас есть уровни lg(n), где n — общее количество узлов. Поскольку каждая рекурсия метода выполняет фиксированное количество операций, то есть O(1), классификация времени выполнения min_heapify_subtree — O(lg (n)).
Для превращения совершенно случайного массива в правильную кучу, просто нужно вызвать min_heapify_subtree на каждом узле, начиная с нижних листьев. Задействуем метод min_heapify:
Shell
1 2 3 4 5 | FUNCTIONmin_heapify FORindex from last_index tofirst_index min_heapify_subtree(index) ENDFOR END |
Данный метод выполняет метод O(lg(n)) n раз, поэтому его время выполнения будет O(n*lg(n)).
Нам нужно извлечь минимальное значение из кучи. Значение можно принять время за O(1), потому что оно всегда будет корневым узлом минимальной кучи (т.е. индекс 0 базового массива), но просто прочитать недостаточно. Требуется удаление, А ТАКЖЕ подтверждение того, что куча остается нагроможденной. Для этого удаляем корневой узел и заменяем его последним листом, а затем min_heapify_subtree индексом 0, чтобы обеспечить сохранение свойства кучи:
Shell
1 2 3 4 5 6 7 8 9 10 11 12 13 | FUNCTIONpop min_node=nodes[0] IFheap_size>1 nodes[0]=nodes[nodes.length-1] nodes.pop()//remove the last element from our nodes array min_heapify_subtree(0) ELSEIFheap_size==1 nodes.pop() ELSE returnNIL//the heap isempty,so returnNIL value ENDIF returnmin_node END |
Метод выполняется за постоянное время, за исключением min_heapify_subtree. Можно сказать, что этот метод также O(lg (n)).
Отлично! На последнем этапе нужно будет добиться получения возможности обновления значний кучи (уменьшать их, поскольку обновляются предварительные расстояния (provisional distance) до более низких значений), сохраняя свойство кучи.
Итак, создадим метод под названием decrease_key, который принимает значение индекса обновляемого узла и новое значение. Мы хотим обновить значение этого узла, а затем добавить его туда, где он должен будет находиться, если станет меньше родителя. Таким образом, пока он не станет меньше родительского узла, поменяем его на родительский узел:
Shell
1 2 3 4 5 6 7 8 9 | FUNCTIONdecrease_key(index,value) nodes[index]=value parent_node_index=parent_index(index) WHILEindex!=0ANDnodes[parent_node_index]>nodes[index] swap(nodes[i],nodes[parent_node_index]) index=parent_node_index parent_node_index=parent_index(index) ENDWHILE END |
Окей, посмотрим, как все вышеперечисленное будет выглядеть в виде кода на Python:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | classMinHeap(BinaryTree): def__init__(self,nodes): BinaryTree.__init__(self,nodes) self.min_heapify() # Преобразует в кучу узлы, рассматривая, что все поддеревья уже кучи defmin_heapify_subtree(self,i): size=self.size() ileft=self.ileft(i) iright=self.iright(i) imin=i if(ileft<size andself.nodes[ileft]<self.nodes[imin]): imin=ileft if(iright<size andself.nodes[iright]<self.nodes[imin]): imin=iright if(imin!=i): self.nodes[i],self.nodes[imin]=self.nodes[imin],self.nodes[i] self.min_heapify_subtree(imin) # Преобразует в кучу массив, который ей не является defmin_heapify(self): foriinrange(len(self.nodes),-1,-1): self.min_heapify_subtree(i) defmin(self): returnself.nodes[0] defpop(self): min=self.nodes[0] ifself.size()>1: self.nodes[0]=self.nodes[-1] self.nodes.pop() self.min_heapify_subtree(0) elifself.size()==1: self.nodes.pop() else: returnNone returnmin # Обновляет значение узла, изменяя его для сохранения свойства кучи defdecrease_key(self,i,val): self.nodes[i]=val iparent=self.iparent(i) while(i!=0andself.nodes[iparent]>self.nodes[i]): self.nodes[iparent],self.nodes[i]=self.nodes[i],self.nodes[iparent] i=iparent iparent=self.iparent(i)ifi>0elseNone |
Хорошо, время для последнего шага. Теперь уже точно! Нам просто нужно выяснить, как внедрить структуру данных MinHeap в метод dijsktra в Graph, который теперь должен быть реализован с помощью списка смежности. Нужно реализовать его, полностью используя преимущества среды выполнения кучи, при этом поддерживая класс MinHeap настолько гибким, насколько это возможно. Это нужно для повторного использования в будущем.
Итак, сначала разберемся с реализацией списка смежности. Вместо матрицы, представляющей соединения между узлами, требуется, чтобы каждый узел соответствовал списку узлов, к которым он подключен. Таким образом, если мы выполняем итерацию по соединениям узла, нам не нужно проверять ВСЕ узлы, чтобы увидеть, какие из них подключены — в списке этого узла находятся только подключенные узлы.
Уже знакомый нам граф:
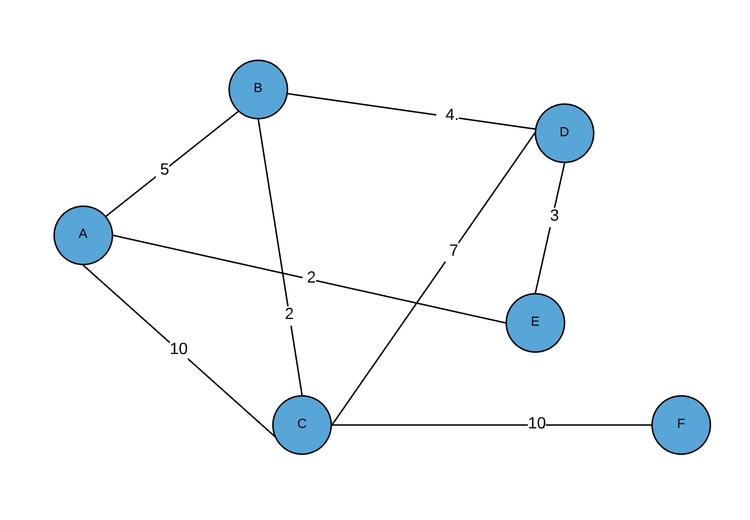
Список смежности графа будет выглядеть приблизительно следующим образом:
Shell
1 2 3 4 5 6 7 8 | [ [NodeA,[(NodeB,5),(NodeC,10),(NodeE,2)]], [NodeB,[(NodeA,5),(NodeC,2),(NodeD,4)]], [NodeC,[(NodeA,10),(NodeB,2),(NodeD,7),(NodeF,10)]], [NodeD,[(NodeB,4),(NodeC,7),(NodeE,3)]], [NodeE,[(NodeA,2),(NodeD,3)]], [NodeF,[(NodeC,10)] ] |
Как видите, для получения определенной связи узлов нам больше не нужно проверять ВСЕ прочие узлы. Оставим API относительно простым, ради ясности оставим класс простым:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | classGraph: def__init__(self,nodes): self.adj_list=[[node,[]]fornode innodes] foriinrange(len(nodes)): nodes[i].index=i defconnect_dir(self,node1,node2,weight=1): node1,node2=self.get_index_from_node(node1),self.get_index_from_node(node2) # Обратите внимание, что указанное ниже не защищает от добавления связи дважды self.adj_list[node1][1].append((node2,weight)) defconnect(self,node1,node2,weight=1): self.connect_dir(node1,node2,weight) self.connect_dir(node2,node1,weight) defconnections(self,node): node=self.get_index_from_node(node) returnself.adj_list[node][1] defget_index_from_node(self,node): ifnotisinstance(node,Node)andnotisinstance(node,int): raiseValueError("node must be an integer or a Node object") ifisinstance(node,int): returnnode else: returnnode.index |
Далее сосредоточимся на реализации кучи для достижения лучшего алгоритма, чем текущий алгоритм O(n?). Если вспомним метод dijsktra, в классе Graph матрицы смежности, то увидим, что мы перебираем всю очередь, чтобы найти минимальное предварительное расстояние provisional distance (время выполнения O(n)), используя узел с минимальным значением для установки текущего посещаемого узла. Затем перебираем все соединения узла и при необходимости сбрасываем их предварительное расстояние provisional distance (проверьте метод connections_to или connections_from; вы увидите, что его время выполнения O(n)). Эти два алгоритма O(n) сводятся к времени выполнения O(n), потому что O(2n) = O (n). Делаем это для каждого узла графа, поэтому выполняем O(n) алгоритм n раз, тем самым получая время выполнения O(n?). Вместо этого сокращаем время выполнения до O((n + e) lg (n)), где n — количество узлов, а e — количество ребер.
В реализации списка смежности внешнему циклу while все еще нужно выполнять итерацию по всем узлам (n итераций), но чтобы получить ребра для текущего узла внутренний цикл просто должен итерировать ТОЛЬКО по ребрам для данного конкретного узла. Таким образом, внутренний цикл, повторяющийся по краям узла, будет выполняться только O(n + e) раз. Внутри данного внутреннего цикла нужно обновить предварительное расстояние для каждого из связанных узлов. Для этого будет использован метод decrease_key кучи, который мы уже рассматривали, как O(lg (n)). Таким образом, общее время выполнения будет равно O((n + e) lg (n)).
Новый алгоритм:
ИНИЦИАЛИЗАЦИЯ
- Установите
provisional_distanceвсех узлов от источника до бесконечности, за исключением нашего исходного узла, значением которого будет0. Добавьте данные к минимальной куче. - Вместо сохранения набора
seen_nodesопределите, есть ли у вас осмотренные узлы. Это будет зависеть от того, что осталось в куче. Помните, что при использованииpop()для узла, он удаляется из кучи. Следовательно, в соответствии с логикой он будет рассматриваться, как «увиденный».
ПРОЦЕДУРА ИТЕРАЦИИ
- Цикл while выполняется до тех пор, пока куча > 0: (выполняется
nраз) - Установите
current_nodeдля возвращения значенияheap.pop(). - Для
nвcurrent_node.connectionsиспользуйтеheap.decrease_key, если данная связь все еще в куче (то есть не была рассмотрена), А ТАКЖЕ если текущее значениеprovisional distanceбольше, чем предварительное расстояниеcurrent_nodeвместе с весом соседнего элемента. Данный цикл for в общем будет выполнятьсяn + eраз, а его временную сложность можно представить, какO(lg(n)). - Конец цикла while.
Есть две задачи, которые нужно решить при данной реализации:
Задача 1: Код написан таким образом, что куча работает с массивом чисел. Однако нам нужна инкапсуляция предварительного расстояния provisional distance (метрики, которая использовалась при преобразовании в кучу), перескоков И узла, которому соответствует расстояние.
Задача 2: Нужно проверить, находится ли узел внутри кучи, А ТАКЖЕ обновить его provisional distance, используя метод decrease_key, для которого требуется индекс данного узла в куче. Для сохранения своих свойств куча постоянно меняет индексы. Нужно убедиться, что данная задача не будет решена простым анализом кучи в поисках точного места узла. Данная операция O(n) будет выполняться (n + e) раз, следовательно, создание кучи и реализация списка смежности ни к чему не приведут, ведь нам нужно со всем управиться за O(1) раз.
Решение 1: Нам нужно сохранить реализацию кучи максимально гибкой. Чтобы принимать любой тип данных в качестве элементов в базовом массиве, можно просто принять необязательные анонимные функции (например, лямбда-выражения) при создании экземпляра, которые предоставляются пользователем, чтобы указать, как он должен обращаться с элементами внутри массива, если эти элементы не являются простым целым числом. Значением по умолчанию для лямбд может быть функция, которая работает, если элементы массива являются просто числами. Таким образом, если требуется простая куча с числами, пользователю не нужно вставлять лямбды. Данные настраиваемые процедуры потребуются для сравнения элементов, а также для возможности уменьшить значение элемента. Можно назвать лямбду сравнения is_less_than, и ее значение по умолчанию должно быть: a, b: a < b. Лямбда-функция для возврата обновленного узла с новым значением может называться update_node, и ее значение по умолчанию должно быть просто lambda node, newval: newval. При передаче узла и нового значения пользователю дается возможность определить лямбду, которая обновляет существующий объект ИЛИ заменяет значение, которое там находится. В контексте реализации старого Graph, поскольку узлы имели бы значения [ provisional_distance, [nodes, in, hop, path]] лямбда is_less_than могла бы выглядеть следующим образом: lambda a,b: a[0] < b[0]. Здесь можно было бы оставить значение второй лямбды по умолчанию и передать вложенный массив в decrease_key.
Тем не менее, вскоре станет ясно, что существует довольно простое решение вопроса, при котором создаются настраиваемые объекты узлы node и передаются в MinHeap. Гибкость, которая недавно упоминалась, позволит легко воплотить это элегантное решение. В частности, в приведенном ниже коде вы увидите, что лямбда is_less_than превратиться в: lambda a, b: a.prov_dist < b.prov_dist, а лямбда update_node станет: lambda node, data: node.update_data (data), что намного аккуратнее использования вложенных массивы.
Решение 2: Есть несколько способов решить данную задачу, но давайте попробуем выбрать тот, который идет рука об руку с Решением 1. Учитывая гибкость, которой мы добились в Решении 1, мы можем продолжать использовать эту стратегию для реализации дополняющего решения и здесь. Можно реализовать дополнительный массив внутри класса MinHeap, который отображает исходный порядок вставленных узлов в их текущий порядок внутри массива узлов. Назовем этот список order_mapping. Поддерживая этот список, мы можем получить любой узел из кучи за время O(1), учитывая, что мы знаем исходный порядок, в котором узел был вставлен в кучу. Таким образом, если порядок узлов, в котором создаётся куча, совпадает с номером индекса узлов Graph, теперь у нас есть отображение узла Graph до относительного местоположения этого узла в MinHeap в постоянном времени! Чтобы иметь возможность поддерживать это отображение в актуальном состоянии за время O(1), все элементы, передаваемые в MinHeap как узлы, должны каким-то образом «знать» свой исходный индекс, а MinHeap необходимо знать, как считывать исходный индекс с этих узлов. Это требуется для того чтобы он мог обновить значение order_mapping по номеру индекса свойства индекса узла index до значения текущей позиции этого узла в списке узлов MinHeap. Поскольку нам нужно разрешить использование MinHeap, тем, кто не нуждается в этом отображении, А ТАКЖЕ нам нужно, чтобы любые типы данных были узлами кучи, мы можем снова разрешить добавление лямбда-выражения пользователем. Оно сообщит MinHeap, как получить номер индекса из любого типа данных, что добавляются в кучу — его названием будет get_index.
Например, если бы данные для каждого элемента в куче были списком структуры [data, index], лямбда get_index была бы: lambda el: el [1]. Кроме того, мы можем установить для get_index значение по умолчанию None, и доверить ему принятие решений, поддерживается или нет массив order_mapping. Таким образом, если пользователь не вводит лямбду, чтобы сообщить куче, как получить индекс из элемента, куча не будет отслеживать order_mapping, что позволяет пользователю использовать кучу без этой функциональности только с базовыми типами данных, такими как целые числа. Лямбда get_index, что будет в итоге использоваться, так как будет задействован пользовательский объект узла, будет очень простой: lambda node: node.index ().
Результатом совмещения решений 1 и 2 является одно чистое решение. Создается класс DijkstraNodeDecorator для декорирования всех узлов, составляющих граф. Этот декоратор предоставит дополнительные данные о provisional distance (инициализированном в бесконечность) и hoop list (инициализированном в пустой массив). Кроме того, он будет реализован с помощью метода, который позволит объекту обновляться самому. Потом это можно использовать в лямбда-выражении для decrease_key. DijkstraNodeDecorator сможет получить доступ к индексу декорируемого узла, и мы воспользуемся этим фактом, указав куче, как получить индекс узла при помощи лямбды get_index из Решения 2.
Финальный код алгоритма Дейкстры Python:
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | classDijkstraNodeDecorator: def__init__(self,node): self.node=node self.prov_dist=float('inf') self.hops=[] defindex(self): returnself.node.index defdata(self): returnself.node.data defupdate_data(self,data): self.prov_dist=data['prov_dist'] self.hops=data['hops'] returnself |
Использоваля для декорирования узлов в реализации Graph ниже.
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | classMinHeap(BinaryTree): def__init__(self,nodes,is_less_than=lambdaa,b:a<b,get_index=None,update_node=lambdanode,newval:newval): BinaryTree.__init__(self,nodes) self.order_mapping=list(range(len(nodes))) self.is_less_than,self.get_index,self.update_node=is_less_than,get_index,update_node self.min_heapify() # Изменение в кучу узлов, предполагается, что все поддеревья уже кучи defmin_heapify_subtree(self,i): size=self.size() ileft=self.ileft(i) iright=self.iright(i) imin=i if(ileft<size andself.is_less_than(self.nodes[ileft],self.nodes[imin])): imin=ileft if(iright<size andself.is_less_than(self.nodes[iright],self.nodes[imin])): imin=iright if(imin!=i): self.nodes[i],self.nodes[imin]=self.nodes[imin],self.nodes[i] # Если есть лямбда для получения абсолютного индекса узла # обновляет массив order_mapping для указания, где находится индекс # в массиве узлов (осмотр для этого индекса будет 0(1)) ifself.get_index isnotNone: self.order_mapping[self.get_index(self.nodes[imin])]=imin self.order_mapping[self.get_index(self.nodes[i])]=i self.min_heapify_subtree(imin) # Превращает в кучу массив, который еще ей не является defmin_heapify(self): foriinrange(len(self.nodes),-1,-1): self.min_heapify_subtree(i) defmin(self): returnself.nodes[0] defpop(self): min=self.nodes[0] ifself.size()>1: self.nodes[0]=self.nodes[-1] self.nodes.pop() # Обновляет order_mapping, если можно ifself.get_index isnotNone: self.order_mapping[self.get_index(self.nodes[0])]=0 self.min_heapify_subtree(0) elifself.size()==1: self.nodes.pop() else: returnNone # Если self.get_index существует, обновляет self.order_mapping для указания, что # узел индекса больше не в куче ifself.get_index isnotNone: # Устанавливает значение None для self.order_mapping для обозначения непринадлежности к куче self.order_mapping[self.get_index(min)]=None returnmin # Обновляет значение узла и подстраивает его, если нужно, чтобы сохранить свойства кучи defdecrease_key(self,i,val): self.nodes[i]=self.update_node(self.nodes[i],val) iparent=self.iparent(i) while(i!=0andnotself.is_less_than(self.nodes[iparent],self.nodes[i])): self.nodes[iparent],self.nodes[i]=self.nodes[i],self.nodes[iparent] # Если есть лямбда для получения индекса узла # обновляет массив order_mapping для указания, где именно находится индекс # в массиве узлов (осмотр этого индекса O(1)) ifself.get_index isnotNone: self.order_mapping[self.get_index(self.nodes[iparent])]=iparent self.order_mapping[self.get_index(self.nodes[i])]=i i=iparent iparent=self.iparent(i)ifi>0elseNone defindex_of_node_at(self,i): returnself.get_index(self.nodes[i]) |
MinHeap модифицирован с лямбдой, что позволяет любому типу данных использоваться в виде узла.
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | classGraph: def__init__(self,nodes): self.adj_list=[[node,[]]fornode innodes] foriinrange(len(nodes)): nodes[i].index=i defconnect_dir(self,node1,node2,weight=1): node1,node2=self.get_index_from_node(node1),self.get_index_from_node(node2) # Отмечает, что нижеуказанное не предотвращает от добавления связи дважды self.adj_list[node1][1].append((node2,weight)) defconnect(self,node1,node2,weight=1): self.connect_dir(node1,node2,weight) self.connect_dir(node2,node1,weight) defconnections(self,node): node=self.get_index_from_node(node) returnself.adj_list[node][1] defget_index_from_node(self,node): ifnotisinstance(node,Node)andnotisinstance(node,int): raiseValueError("node must be an integer or a Node object") ifisinstance(node,int): returnnode else: returnnode.index defdijkstra(self,src): src_index=self.get_index_from_node(src) # Указывает узлы к DijkstraNodeDecorators # Это инициализирует все предварительные расстояния до бесконечности dnodes=[DijkstraNodeDecorator(node_edges[0])fornode_edges inself.adj_list] # Устанавливает предварительное расстояние исходного узла до 0 и его массив перескоков к его узлу dnodes[src_index].prov_dist=0 dnodes[src_index].hops.append(dnodes[src_index].node) # Устанавливает все методы настройки кучи is_less_than=lambdaa,b:a.prov_dist<b.prov_dist get_index=lambdanode:node.index() update_node=lambdanode,data:node.update_data(data) # Подтверждает работу кучи с DijkstraNodeDecorators с узлами heap=MinHeap(dnodes,is_less_than,get_index,update_node) min_dist_list=[] whileheap.size()>0: # Получает узел кучи, что еще не просматривался ('seen') # и находится на минимальном расстоянии от исходного узла min_decorated_node=heap.pop() min_dist=min_decorated_node.prov_dist hops=min_decorated_node.hops min_dist_list.append([min_dist,hops]) # Получает все следующие перескоки. Это больше не O(n^2) операция connections=self.connections(min_decorated_node.node) # Для каждой связи обновляет ее путь и полное расстояние от # исходного узла, если общее расстояние меньше, чем текущее расстояние # в массиве dist for(inode,weight)inconnections: node=self.adj_list[inode][0] heap_location=heap.order_mapping[inode] if(heap_location isnotNone): tot_dist=weight+min_dist iftot_dist<heap.nodes[heap_location].prov_dist: hops_cpy=list(hops) hops_cpy.append(node) data={'prov_dist':tot_dist,'hops':hops_cpy} heap.decrease_key(heap_location,data) returnmin_dist_list |
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | a=Node('a') b=Node('b') c=Node('c') d=Node('d') e=Node('e') f=Node('f') g=Graph([a,b,c,d,e,f]) g.connect(a,b,5) g.connect(a,c,10) g.connect(a,e,2) g.connect(b,c,2) g.connect(b,d,4) g.connect(c,d,7) g.connect(c,f,10) g.connect(d,e,3) print([(weight,[n.data forninnode])for(weight,node)ing.dijkstra(a)]) |
Результат вывода финального кода:
Shell
1 | [(0,[‘a’]),(2,[‘a’,‘e’]),(5,[‘a’,‘e’,‘d’]),(5,[‘a’,‘b’]),(7,[‘a’,‘b’,‘c’]),(17,[‘a’,‘b’,‘c’,‘f’])] |
Как видите, вывод такой же, как и в прошлом варианте реализации алгоритма. Сам код выглядит теперь намного аккуратнее. Кроме того, сейчас нам удалось добиться реализации алгоритма Дейкстры за время O((n + e)lg(n)).
Телеграм: t.me/ainewsline
Источник: python-scripts.com